

Xinzhiyuan Report
Source: blog.otoro.net
Reporter: Wen Qiang
【Xinzhiyuan Guide】You never know the potential of Chinese characters. Hardmaru, a researcher at Google Brain’s Tokyo branch, uses neural networks to generate Chinese characters based on strokes, creating a series of “fake characters.” Some of them do look quite authentic.

As we are all Chinese, having grown up watching and writing Chinese characters, we have forgotten how difficult it is to master them.
Indeed, the basic strokes of Chinese characters are just a few, such as dots, horizontal lines, and downward strokes. However, Chinese writing has evolved from oracle bone script, bronze script, seal script, to clerical script, each with varying degrees of difficulty in writing and recognition. Even a simple “dot” can differ in size and direction across different characters. Therefore, for character designers, it can be a daunting task.
Investigative journalist Nikhil Sonnad once published an article in QZ detailing the lengthy and arduous yet addictive process of designing a Chinese character font. One example shows how the “speech radical” varies in size and direction across different characters:
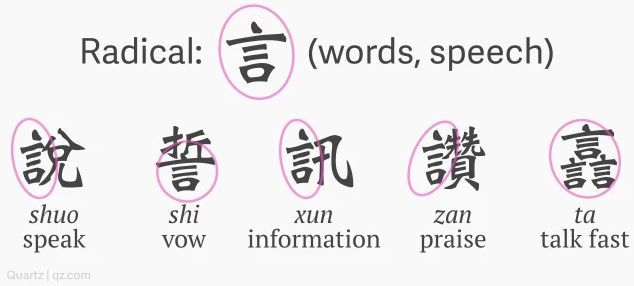
The “speech radical” varies in size and direction across different characters. Source: QZ
This is also one reason why there are so few fonts for Chinese characters compared to the myriad of fonts available for English and Arabic numerals.
Nikhil Sonnad pointed out in that article that an experienced designer can create a font covering dozens of Western languages in six months. However, designing a single Chinese font typically requires a team of several designers over two years.
Is there a good way to solve this problem?
As readers of Xinzhiyuan (ID: AI_era), some may have already guessed what we are about to say. Yes, it’s still neural networks.
Hardmaru, a researcher at Google Brain’s Tokyo branch, generates Chinese characters using neural networks, but what sets him apart is that the data provided to the neural network is “strokes,” thus the generated characters are all theoretically possible but not currently in use.

You might ask, what is the use of this? But upon closer inspection, you can see the theoretical and practical significance of what the author is doing.
The Chinese character system is essentially open. Using available elements (radicals, strokes, etc.), countless different characters can be created. Although the code currently cannot accurately position the strokes, some results from Hardmaru’s experiments look very much like real Chinese characters.

Knowing a character does not necessarily mean you can write it, but if you can write it, you definitely know how to pronounce it.
In a blog introducing his work, Hardmaru stated that he was forced to learn Chinese characters by his parents since childhood, even though most people around him spoke English. The process of learning to write Chinese characters was a constant cycle of copying and dictation, much like how LSTM outputs sequence results based on training samples.
On the other hand, he also noticed that “writing” Chinese characters and “reading” them are two very different processes. You may recognize a character (able to read or pronounce it) but not necessarily be able to write it; however, if you can write a Chinese character, you certainly know its pronunciation. Nowadays, people increasingly rely on pronunciation-based input methods to “write” Chinese characters, often forgetting how to write them when it comes time to actually pick up a pen.
To some extent, the process of machine learning is similar; it often starts with simple classification problems: determining whether an input image is a cat or a dog, whether a transaction is real or fraudulent… These tasks are very useful. However, Hardmaru believes that the more interesting task is to generate data. In Hardmaru’s view, generating data is an extension and expansion of data classification. Being able to write a Chinese character indicates a deeper understanding of it than simply recognizing it. Similarly, generating content is also key to understanding content.
Generative Adversarial Networks (GANs) perform excellently in data generation, and machine translation is a type of data generation. However, Hardmaru wants to generate vector data. He believes that many contents are better expressed in vector form, such as sketches of digital strokes, CAD designs, scientific experimental data, etc.
Fonts and strokes are also better represented in vector form. Well-designed TrueType fonts look beautiful at any size.
Using Sketch-RNN to Create a New “Xinhua Dictionary”
Next, we will introduce how Hardmaru uses RNN to generate handwritten Chinese characters in vector format, with Chinese characters saved in vector (SVG) format.
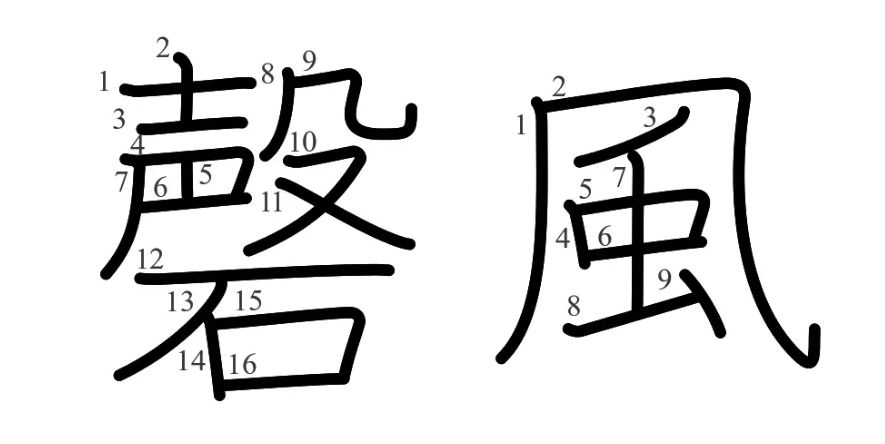
Hardmaru has implemented a network called sketch-rnn to generate “new” Chinese characters, similar to the Graves handwriting generation model framework (see below).
The training data consists of real Chinese characters and includes stroke order. Therefore, the Chinese characters generated by the neural network also appear to follow a reasonably correct stroke order.

Training data samples, with different colors representing stroke order, source: KanjiVG dataset
In sketch-rnn, each stroke is modeled using stroke-like data, where each step of data includes the x and y axis offsets, as well as whether the stroke is on or off the paper. If it is on the paper, there will be a connection between the previous stroke and the current one. The neural network must provide a probability distribution for the next step. This probability distribution is not discrete but continuously distributes the x and y-axis offsets and the probability of the pen being lifted off the paper (i.e., the probability of the stroke ending). Sketch-rnn uses a mixture of Gaussian distributions to estimate the displacement of the next stroke. This method for generating strokes is called Mixture Density Networks (MDN).
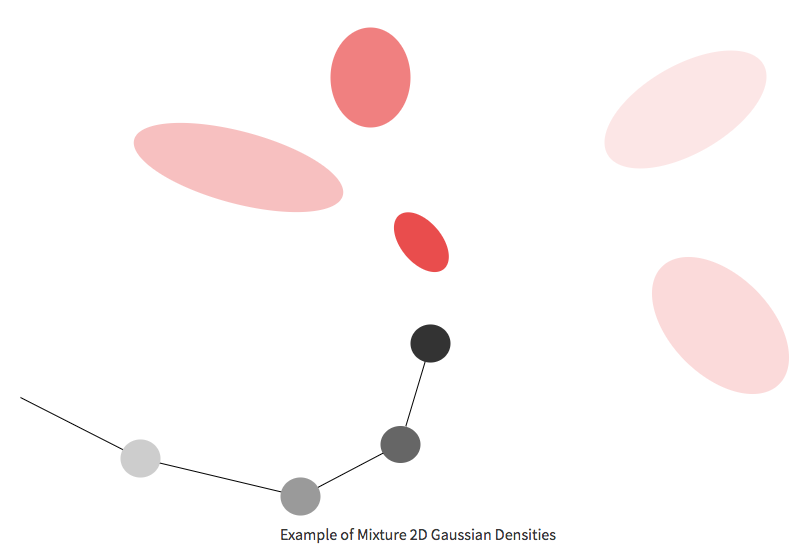
The above is an example of using mixed Gaussian density to generate Chinese character strokes. The black dots represent the lines connected during the writing process, LSTM + MDN algorithm will continuously estimate the probability distribution of the next point’s position. This distribution is modeled as a mixture of Gaussian distributions, meaning the next position is a mixture of many different positions (the red ellipses of varying shades), and each position itself is a two-dimensional joint Gaussian distribution of x and y offsets, with each offset having its own 2×2 covariance matrix.
MDN trajectory display
In addition to modeling the stroke position distribution and ending probability, it is also necessary to model the probability of writing the entire Chinese character, i.e., the end-of-character probability. However, the probability of each stroke ending has some overlap with the probability of the entire character ending, and Hardmaru spent considerable effort trying to model these two signals (stroke ending probability, character ending probability). Ultimately, he modeled the pen’s state in the neural network’s softmax layer as a set of discrete states. The pen’s states are divided into three types: stroke end, character end, and pen down. The model calculates the probability of the three states at each step.
LSTM+MDN is essentially an extension of LSTM+Softmax, and Hardmaru plans to try more powerful methods in the future. GANs (Generative Adversarial Networks) might be applicable to recurrent networks, but he expects training LSTM GANs to be very challenging.
Besides the various examples shown above, here are some interesting results that Hardmaru himself annotated:

There are also some results that are hard to describe:

You can try it yourself on this website: http://otoro.net/kanji-rnn/
Learn More
-
Sketch-rnn: https://github.com/hardmaru/sketch-rnn/
-
Blog: http://blog.otoro.net/2015/12/28/recurrent-net-dreams-up-fake-chinese-characters-in-vector-format-with-tensorflow/
-
https://github.com/tensorflow/magenta-demos/blob/master/sketch-rnn-js/README.md
【Join the Community】
Xinzhiyuan AI technology + industry community is recruiting. Welcome students interested in AI technology + industry implementation to add the assistant’s WeChat: aiera2015_3 to join the group; after passing the review, we will invite you to join the group. Please be sure to modify your group note (name – company – position; professional group review is strict, please understand).