Machine Heart Column
This article will be serialized in 3 issues, introducing 18 classic models that have achieved SOTA in recommendation systems.
-
Issue 1: CNN, GRNN, CLSTM, TD-LSTM/TC-LSTM
-
Issue 2: MemNet, AT-LSTM, IAN, AF-LSTM
-
Issue 3: Bert on ABSA, ASGCN, GAN, Sentic GCN
You are reading Issue 1. Visit the SOTA! Model Resource Station (sota.jiqizhixin.com) to obtain the implementation code, pre-trained models, and APIs mentioned in this article.
| Model | SOTA! Model Resource Station Inclusion | Source Paper |
|---|---|---|
| CNN | https://sota.jiqizhixin.com/project/textcnn Number of Implementations: 6 Supported Frameworks: PyTorch, TensorFlow, etc. | Convolutional Neural Networks for Sentence Classification |
| GRNN | https://sota.jiqizhixin.com/project/grnn-2 | Document modeling with gated recurrent neural network for sentiment classification |
| CLSTM | https://sota.jiqizhixin.com/project/clstm | Cached Long Short-Term Memory Neural Networks for Document-Level Sentiment Classification |
| TD-LSTM/TC-LSTM | https://sota.jiqizhixin.com/project/td-lstm-2 Number of Implementations: 11 Supported Frameworks: PyTorch, TensorFlow, etc. | Effective LSTMs for Target-Dependent Sentiment Classification |
Sentiment analysis refers to the use of computer technology to mine and analyze emotions from text, images, audio, video, and even cross-modal data. Broadly speaking, sentiment analysis also includes the analysis of opinions, attitudes, and tendencies. Sentiment analysis is an important research area in natural language processing. It mainly involves two objects: the subject of evaluation (including products, services, organizations, individuals, topics, issues, events, etc.) and the attitudes and emotions towards that subject. Sentiment analysis has wide applications in social public opinion management, business decision-making, and precision marketing. From the perspective of data sources for sentiment analysis, it can be divided into facial emotion analysis, voice emotion analysis, body language emotion analysis, text emotion analysis, and physiological pattern emotion analysis. This article focuses on text sentiment analysis, which is an important technology used in understanding online content (unless otherwise specified, the sentiment analysis mentioned below refers to text sentiment analysis). In natural language processing, sentiment analysis is a typical text classification problem, which classifies the text that needs sentiment analysis into its corresponding categories. The mainstream methods for sentiment analysis are divided into two types: dictionary-based methods and machine learning algorithm-based methods. Dictionary-based methods mainly establish a series of sentiment dictionaries and rules to decompose text, extract keywords, calculate sentiment values, and finally use sentiment values as the basis for judging the sentiment tendency of the text. This method often ignores the word order, grammar, and syntax, treating the text merely as a collection of words, hence cannot fully express the semantic information of the text. The machine learning methods that incorporate deep learning techniques can avoid the difficulties caused by varying lengths of text through word embedding techniques; they can abstract features using deep learning to avoid a large amount of manual feature extraction work; they can simulate the relationships between words, possessing local feature abstraction and memory functions. Therefore, deep learning techniques play an increasingly important role in sentiment analysis. Currently, the deep learning neural networks used in sentiment analysis include Multilayer Perceptrons (MLP), Convolutional Neural Networks (CNN), and Long Short-Term Memory models (LSTM), with different models selecting optimal parameters through cross-validation techniques (such as the number of layers, number of nodes per layer, Dropout probability, etc.). The models for sentiment analysis are mainly categorized into three levels: Document level, Sentence level, and Aspect level. Among them, Document level treats the entire text as the analysis unit, assuming that the subject discussed in the text is a single entity and that sentiments and opinions are clear and distinct, i.e., neural, positive, or negative. Sentence level treats each sentence as a separate analysis object, and since there may be some associations between sentences, they cannot be considered to have clear opinions. Aspect level has a finer granularity of classification, where we need to extract independent evaluations of different targets and summarize them to obtain the final sentiment. This article reviews the TOP models essential for sentiment analysis. Some classic models in the field of natural language processing, such as XLNet, Bert, and various variants, are applicable in multiple domains including NLU, text generation, sentiment analysis, etc., but are not covered in this article. This article focuses solely on dedicated sentiment analysis models.
1、Document level/Sentence level
1、 CNN
This article introduces Convolutional Neural Networks (CNN), applying layers and convolutional filters to local features. Initially invented for computer vision, the CNN model has proven effective for NLP, achieving excellent results in semantic analysis, search query retrieval, sentence modeling, and other traditional NLP tasks. This article trains a simple CNN based on word vectors obtained from an unsupervised neural language model, adding a convolutional layer while initially keeping the word vectors static and only learning other parameters of the model. This simple model achieves good results on multiple benchmarks, indicating that pre-trained vectors are “universal” feature extractors that can be used for various classification tasks. Further improvements can be obtained by fine-tuning to learn task-specific vectors. Finally, the author describes a simple modification to the network structure, allowing the use of pre-trained and task-specific vectors by having multiple channels.
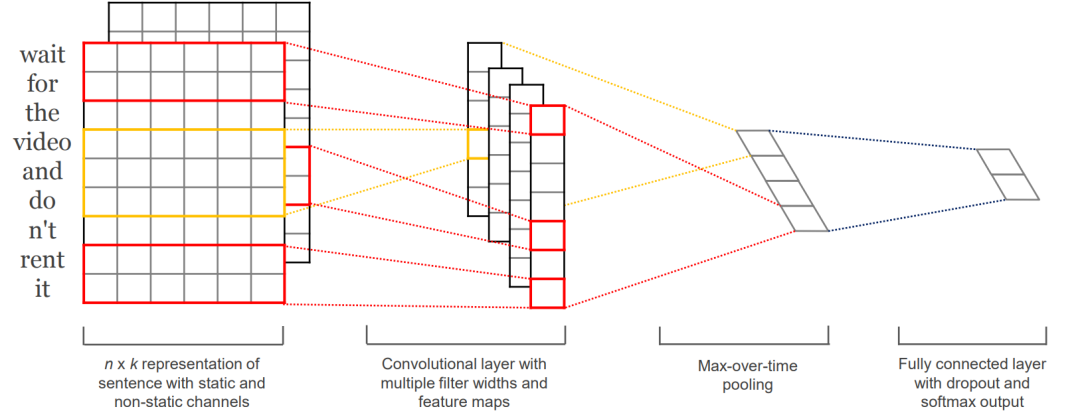 Figure 1 Model structure of a sentence with two channels
Figure 1 Model structure of a sentence with two channels
Let xi ∈ Rk be the k-dimensional word vector corresponding to the i-th word in the sentence, with a sentence length of n. The left side of Figure 1 is an n*k matrix representing the n words of a sentence, each word being a k-dimensional vector. Assuming that the number of words in the longest sentence in the text is n, sentences shorter than n are padded to m. The final word vector matrix is n * k. It is represented as:
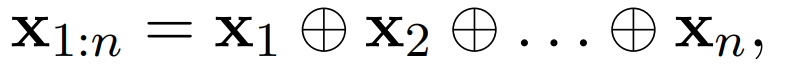
Where ⊕ is the concatenation operator. X_i:n is the concatenation of the word xi (from the i-th word to the n-th word, concatenating them). The convolution operation includes a filter w∈R^hk, which is applied to the window of word h to generate a new feature. For example, the feature c_i is generated by the window of words x_i:i+h−1:
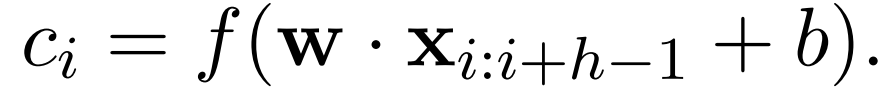
Where b∈R is a bias term, w is the weight, and f is a non-linear function. This filter is applied to the sentence {X_1:h, X_2:h+1, …, X_n-h+1:n} to generate a feature map:
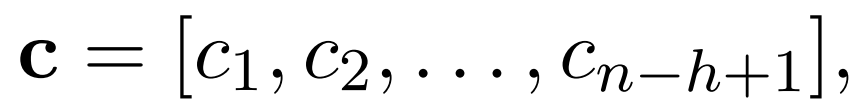
Then apply the max pooling operation on the feature map, taking the maximum value ˆc=max{c} as the corresponding feature for this specific filter. The idea is to capture the most important features for each feature map, which are the features with the highest values. This pooling scheme can handle variable sentence lengths. Additionally, this article uses dropout in the second-to-last layer to address overfitting, which is prone to occur when the model parameters are too many and the training samples are few.
| Item | SOTA! Platform Project Details Page |
|---|---|
| CNN | Visit SOTA! Model Platform for implementation resources: https://sota.jiqizhixin.com/project/textcnn |
2、 GRNN
This article introduces a neural network that learns vector-based text representations in a unified, bottom-up manner. This model first uses CNN/LSTM to learn sentence representations, using Gated RNN to adaptively encode the semantics of the sentences and their interrelations.
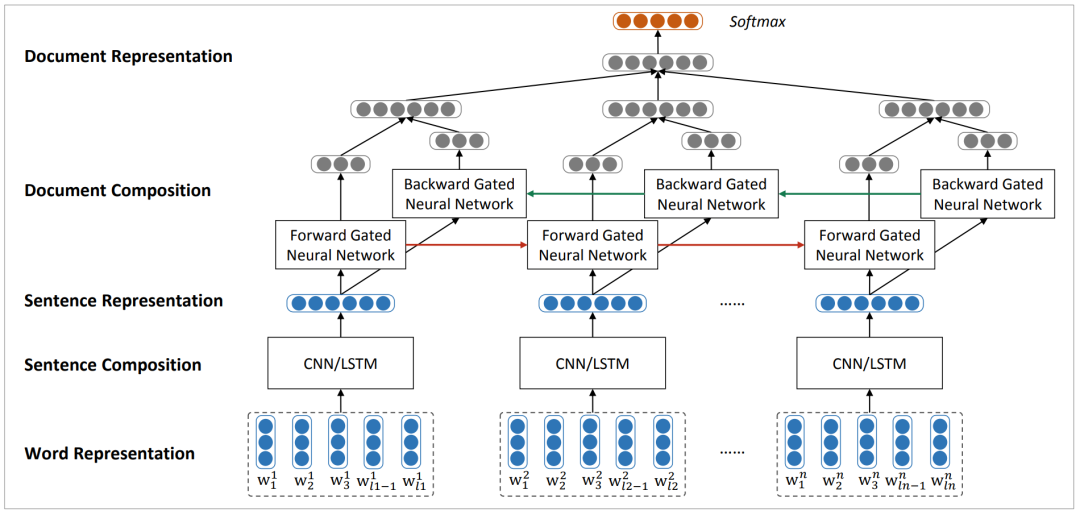 Figure 2 Neural network model for document-level sentiment classification. (w_i)^n represents the i-th word in the n-th sentence, l_n is the sentence length
Figure 2 Neural network model for document-level sentiment classification. (w_i)^n represents the i-th word in the n-th sentence, l_n is the sentence length
Word Vector Representation There are two implementation methods for word vector representation: random initialization or pre-trained methods. The author refers to the word2vec implementation scheme and uses pre-trained word vectors to retain more semantic information. Sentence Representation Both CNN and LSTM models can be used for sentence encoding. Both models can represent non-fixed-length sentences as fixed-length vectors without relying on dependency syntax analysis or constituent syntax analysis to retain information such as word order. In this article, the author uses CNN with multiple conventional filters of different widths to achieve sentence encoding. The author uses convolution kernels with widths of 1, 2, and 3 to obtain unigrams, bigrams, and trigrams, respectively. To obtain the global semantic information of the sentence, the author then connects an average pooling layer followed by a tanh activation function (to introduce non-linearity), and finally connects the vector representations of different widths of convolution kernels of the entire sentence to an Average layer to obtain the average vector representation of the sentence. The entire process is shown in Figure 3.
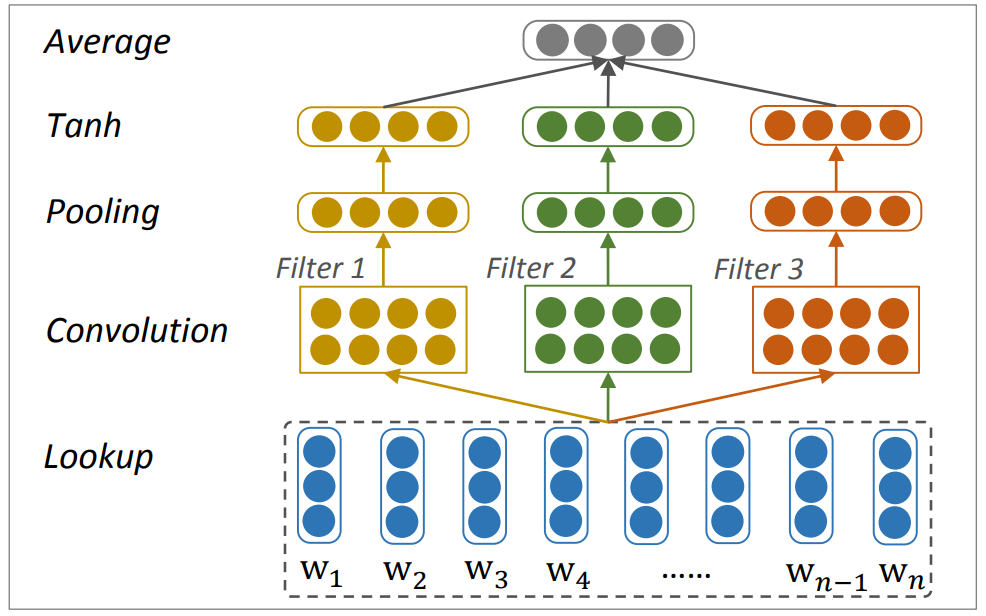 Figure 3 Sentence synthesis using Convolutional Neural Networks
Figure 3 Sentence synthesis using Convolutional Neural Networks
Document Representation A simple implementation strategy is to ignore the order between sentences and directly use the average of the sentence vectors as the vector representation of the text. Ignoring the computational efficiency issue, this method does not effectively retain the complex linguistic relationships between sentences (e.g., causal structures, antonym structures, etc.). CNN models can be used to represent documents, as these models store inter-sentence relationships through their linear layers. RNN can also be implemented, but basic RNN models have defects: gradient vanishing or gradient explosion. This issue becomes apparent in long sentences: gradients may rise or decay exponentially, making the long-distance dependency problem tricky. To solve this issue, the author modifies the basic RNN into a gated structure RNN, which is similar to LSTM or GNN, as seen in the following transformation functions:
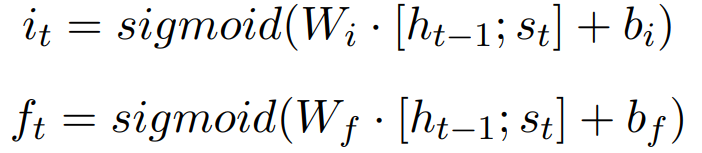
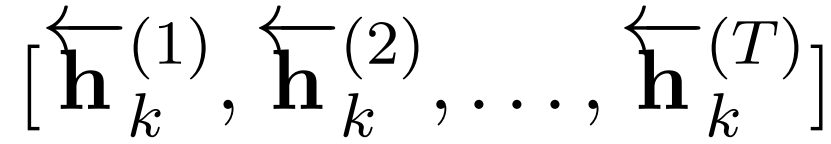
This model can be viewed as an LSTM, where its output gate is always open, as we prefer not to discard any part of the semantic information of the sentence to obtain better text representation. Figure 4 (a) shows a standard sequential approach where the last hidden vector is considered the text representation for sentiment classification. We can further extend this by using the average of hidden vectors as the text representation, which requires considering the hierarchical structure of historical semantics with different granularities. This method is shown in Figure 4 (b). Furthermore, we can use past history and subsequent evidence in the same way and utilize bidirectional gated RNN as a computational tool.
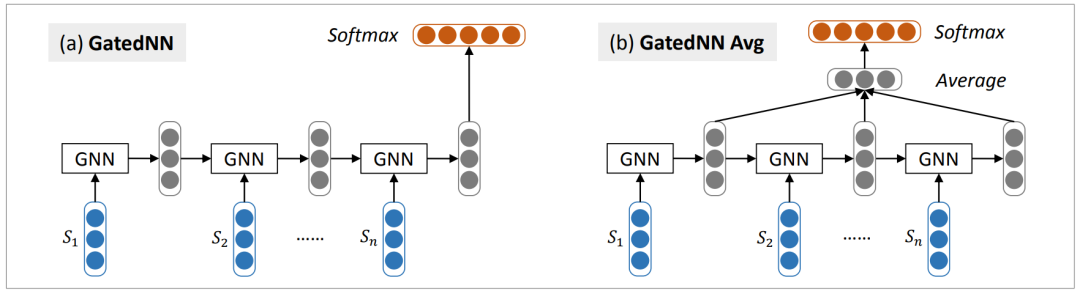 Figure 4 Text modeling using Gated Recurrent Neural Networks. GNN represents the basic computational unit of gated recurrent neural networks
Figure 4 Text modeling using Gated Recurrent Neural Networks. GNN represents the basic computational unit of gated recurrent neural networks
The combined text representation can naturally be viewed as text features for sentiment classification without the need for feature engineering. Specifically, first add a linear layer to transform the text vector into a real-valued vector of length C (the number of classes). Then, add a softmax layer to convert the real values into conditional probabilities, calculated as follows:
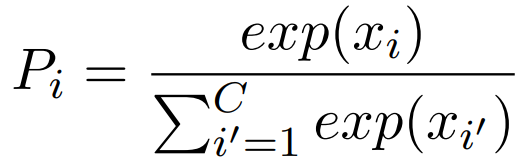
For model training, the author uses the cross-entropy error between the golden sentiment distribution P^g(d) and the predicted sentiment distribution P(d) as the loss function:
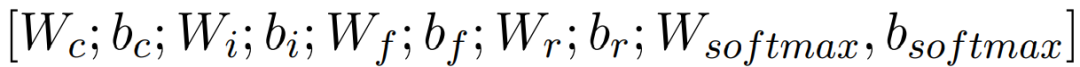
Then, use backpropagation to compute the derivative of the loss function for the entire parameter set and update the parameters using the stochastic gradient descent algorithm:
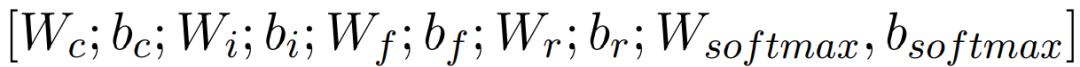
| Item | SOTA! Platform Project Details Page |
|---|---|
| GRNN | Visit SOTA! Model Platform for implementation resources: https://sota.jiqizhixin.com/project/grnn-2 |
3、 CLSTM
Neural networks have achieved great success in sentiment classification tasks as they can alleviate the pressure of feature engineering. However, due to the shortcomings of memory cells, how to model long texts for document-level sentiment classification under recurrent architectures remains to be studied. To address this issue, this article proposes a Cached Long Short-Term Memory Neural Network (CLSTM) to capture the overall semantic information in long texts. CLSTM introduces a caching mechanism that divides memory into several groups with different forgetting rates, allowing the network to better retain sentiment information within a single recurrent unit. As standard LSTM inevitably loses valuable features, this article proposes a cached long short-term memory neural network (CLSTM) to capture information over longer steps by introducing a caching mechanism. Additionally, to better control and balance historical information and incoming information, a special variant of LSTM, Coupled Input and Forget Gate LSTM (CIFG-LSTM), is used. In CIFG-LSTM, the input gate and forget gate are coupled into a unified gate, i.e., i(t)=1-f(t). The coupled gate is represented as:
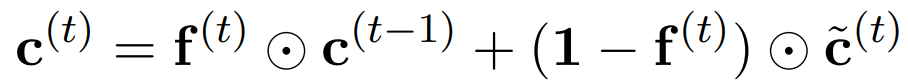 CLSTM aims to capture long-distance information through the caching mechanism, which divides memory into several groups, with different forgetting rates treated as filters allocated to different groups. Different groups capture dependencies of different scales by squashing the scale of forgetting rates. Groups with high forgetting rates are short-term memory, while those with low forgetting rates are long-term memory. Specifically, the storage units are divided into K groups {G_1, – -, G_K}. Each group includes an internal memory c_k, an output gate o_k, and a forgetting rate r_k. The forgetting rates of different groups are suppressed within different ranges. The LSTM modification is as follows:
CLSTM aims to capture long-distance information through the caching mechanism, which divides memory into several groups, with different forgetting rates treated as filters allocated to different groups. Different groups capture dependencies of different scales by squashing the scale of forgetting rates. Groups with high forgetting rates are short-term memory, while those with low forgetting rates are long-term memory. Specifically, the storage units are divided into K groups {G_1, – -, G_K}. Each group includes an internal memory c_k, an output gate o_k, and a forgetting rate r_k. The forgetting rates of different groups are suppressed within different ranges. The LSTM modification is as follows:
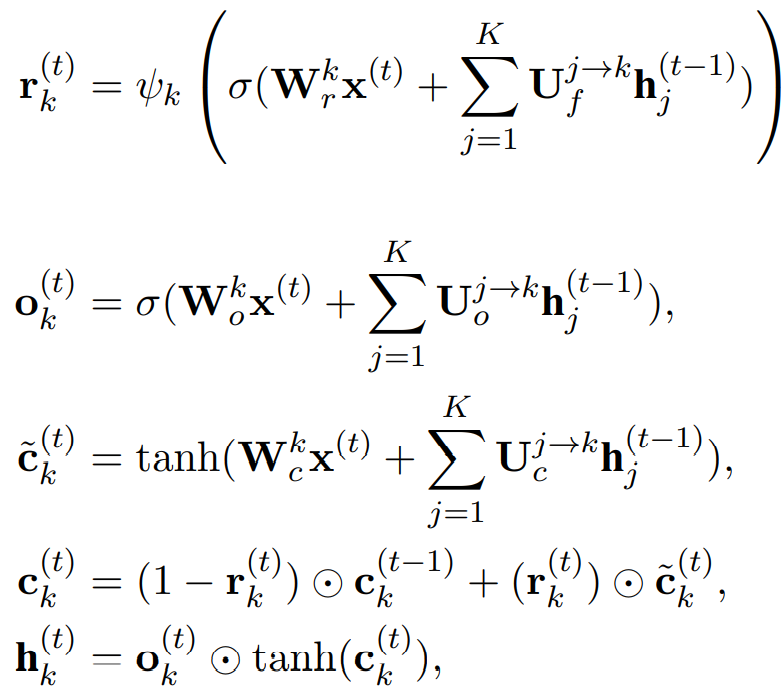
To better distinguish the different roles of each group, their forgetting rates are squashed to a clear area. The squash function ψ_k(z) can be formalized as:
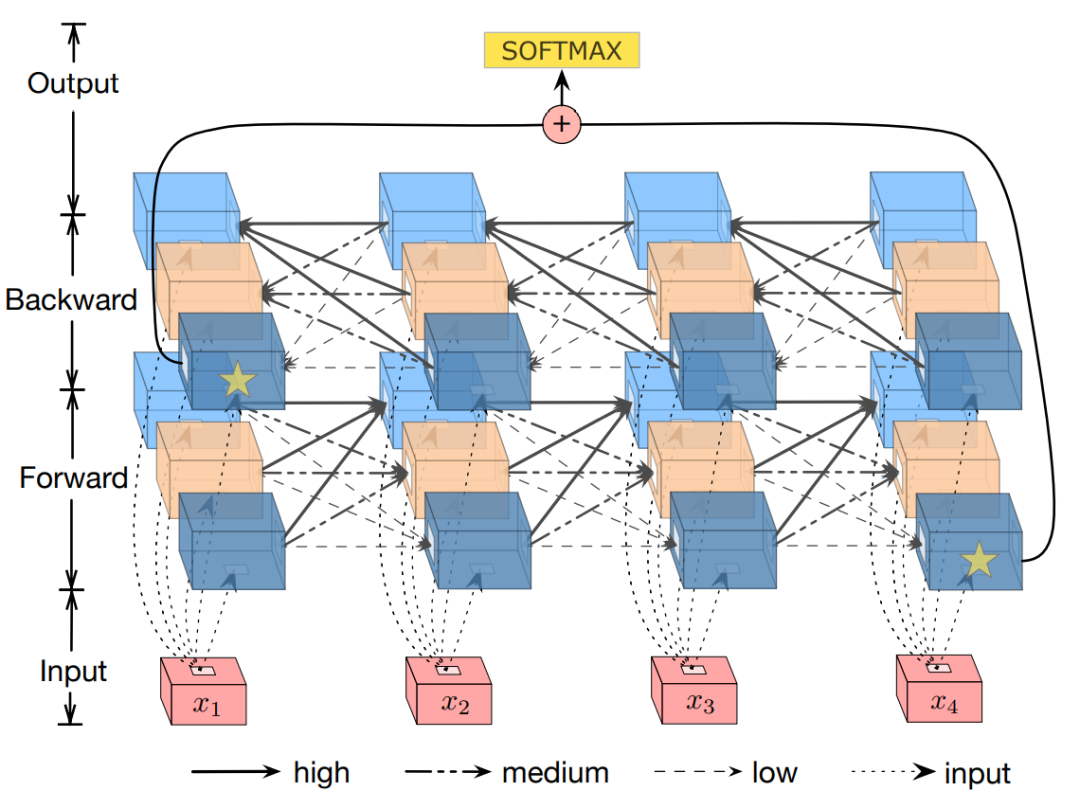 Figure 5 Model architecture. Different styles of arrows indicate different forgetting rates. Groups with stars are sent to a fully connected layer for softmax classification. Below is an example of B-CLSTM, where the text length is 4 and the number of memory groups is 3
Figure 5 Model architecture. Different styles of arrows indicate different forgetting rates. Groups with stars are sent to a fully connected layer for softmax classification. Below is an example of B-CLSTM, where the text length is 4 and the number of memory groups is 3
The bidirectional CLSTM (B-LSTM) model utilizes additional backward information, thereby enhancing memory capacity. The author continues to introduce a bidirectional mechanism to CLSTM, allowing words in the text to gain information from the context. Formally, the output of the forward LSTM of the k-th group is:
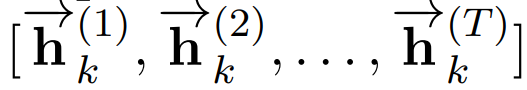
The output of the backward LSTM of the k-th group is:
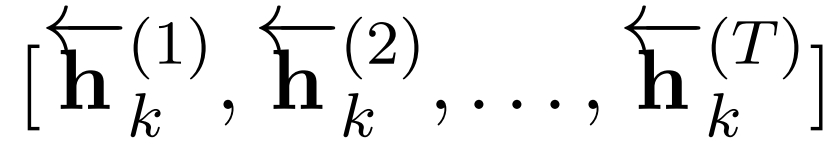
Thus, each word wt in the given text w_1:T is encoded as (h_k()^t):
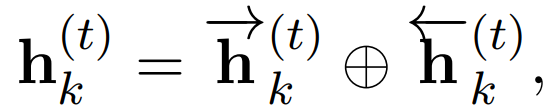
At this point, the output layer for the specific task of document-level sentiment classification has the capability to model long texts, and the model proposed in this article can be used to analyze the sentiment in documents.
| Item | SOTA! Platform Project Details Page |
|---|---|
|
CLSTM |
Visit SOTA! Model Platform for implementation resources: https://sota.jiqizhixin.com/project/clstm |
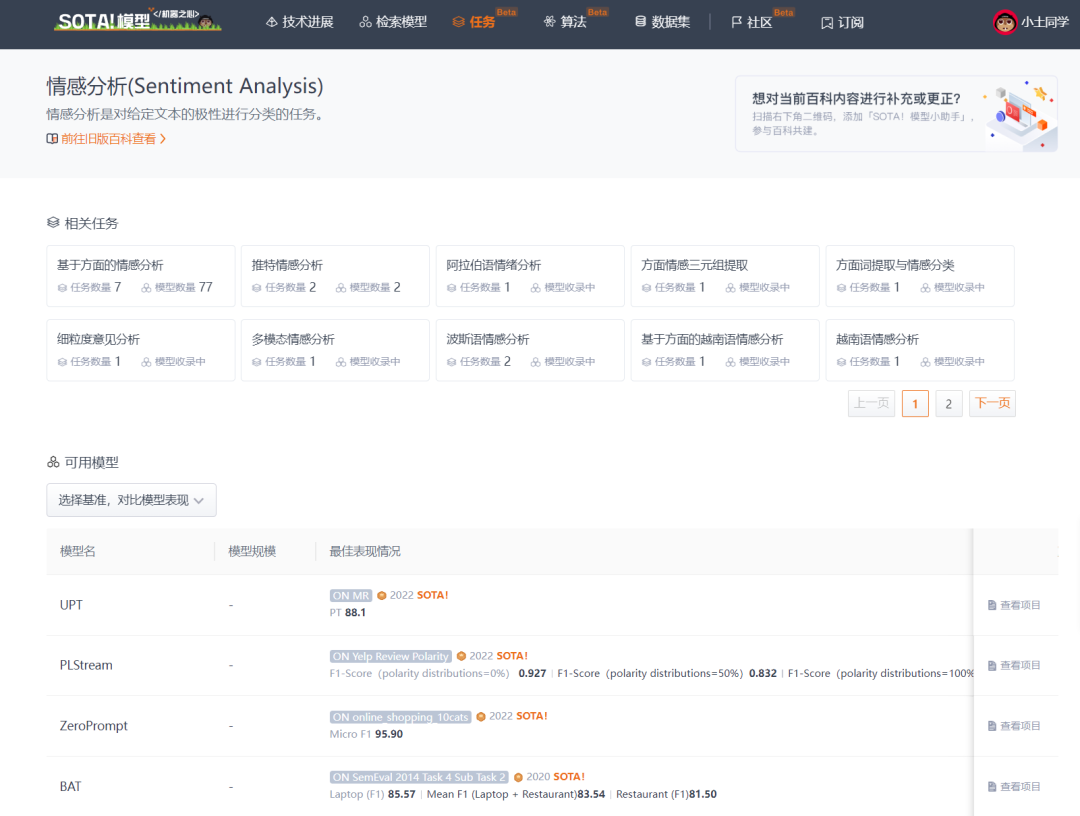
2、Aspect level
4、 TD-LSTM/TC-LSTM
This article first proposes a basic Long Short-Term Memory (LSTM) method to model the semantic representation of a sentence without considering the target word being evaluated. Then, it extends LSTM by considering the target word, resulting in the Target-Dependent Long Short-Term Memory model (TD-LSTM). TD-LSTM models the relevance between the target word and its context words, selecting the relevant parts of the context to infer the sentiment polarity directed at the target word. This model uses standard backpropagation for end-to-end training, with the loss function being the cross-entropy error for supervised sentiment classification. Finally, the TD-LSTM connected to the target is extended, merging the semantics of the target and context words.
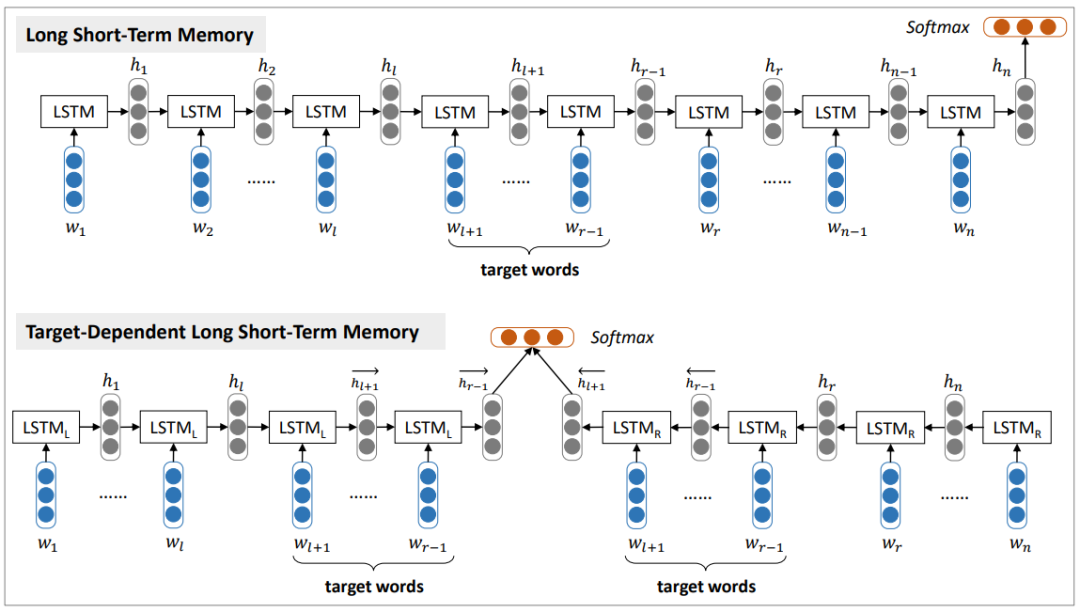 Figure 6 Basic Long Short-Term Memory (LSTM) method and its target-dependent extension TD-LSTM for target-related sentiment classification. Here, w represents the word in a sentence of length n, {w_l+1, w_l+2, …, w_r-1} is the target word, and {w_1, w_2, …, w_l} are the preceding context words, while {w_r, …, w_n−1, w_n} are the context words
Figure 6 Basic Long Short-Term Memory (LSTM) method and its target-dependent extension TD-LSTM for target-related sentiment classification. Here, w represents the word in a sentence of length n, {w_l+1, w_l+2, …, w_r-1} is the target word, and {w_1, w_2, …, w_l} are the preceding context words, while {w_r, …, w_n−1, w_n} are the context words
As shown in Figure 6, TD-LSTM uses two LSTMs to model context information from the left and right around the target word, using the target word as a boundary. Specifically, it employs two LSTM neural networks, a left LSTM L and a right LSTM R, which model the preceding and following contexts, respectively. The input to LSTM L is the preceding context plus the target string, while the input to LSTM R is the following context plus the target string. The LSTM L runs from left to right, while LSTM R runs from right to left, as the author believes treating the target string as the last unit better utilizes the semantics of the target string. Then, the last hidden vectors of LSTM L and LSTM R are concatenated to a softmax layer for classifying the sentiment polarity labels. It is also possible to average or sum the last hidden vectors of LSTM L and LSTM R. Compared to LSTM, TD-LSTM can better combine contextual information, but when reading, humans consider not only the contextual information but also the context, i.e., the interaction between the target word and the context. Therefore, this article proposes TC-LSTM, which simply concatenates a vector representation of the target word to the input. This component explicitly utilizes the connection between the target word and the context words when constructing the sentence. The target string t is represented as {w_l+1, w_l+2…, W_r−1}, as the target can be a variable-length sequence of words, and the target vector v_target is obtained by averaging the vectors of the words contained in t. The difference between TC-LSTM and TD-LSTM is that in TC-LSTM, the input at each position is the concatenation of the word embedding and the target vector v_target. TC-LSTM can better utilize the relationship between the target word and the context words to construct the representation of the sentence.
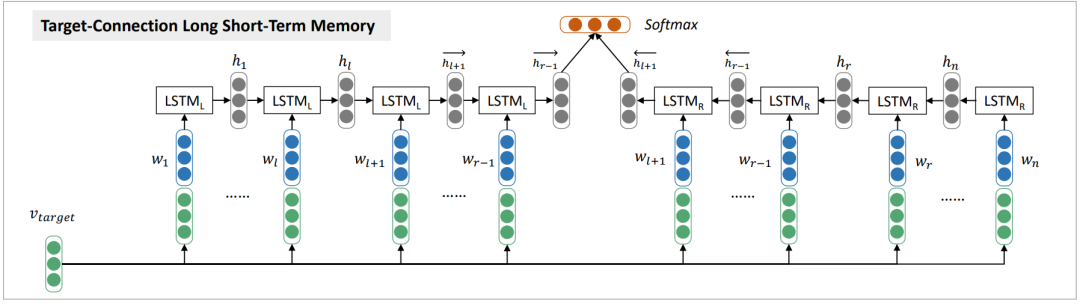 Figure 7 Target-Connected Long Short-Term Memory (TC-LSTM) model for target-dependent sentiment classification, where w represents the word in a sentence of length n, {w_l+1, w_l+2, …, w_r-1} is the target word, v_target is the target representation, {w_1, w_2, …, w_l} are the preceding context words, and {w_r, …, w_n-1, w_n} are the following context words
Figure 7 Target-Connected Long Short-Term Memory (TC-LSTM) model for target-dependent sentiment classification, where w represents the word in a sentence of length n, {w_l+1, w_l+2, …, w_r-1} is the target word, v_target is the target representation, {w_1, w_2, …, w_l} are the preceding context words, and {w_r, …, w_n-1, w_n} are the following context words
Finally, the model training cross-entropy loss function:
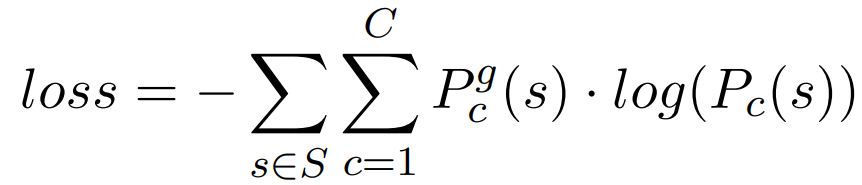
Where S is the training data, C is the number of sentiment categories, s is a sentence, Pc(s) is the probability that s belongs to class C given by the softmax layer, and (P_c)^g (s) indicates whether C is the correct sentiment category, with a value of 1 or 0. The loss function is derived for all parameters through backpropagation, and the parameters are updated using the stochastic gradient descent method.
| Item | SOTA! Platform Project Details Page |
|---|---|
|
TD-LSTM |
Visit SOTA! Model Platform for implementation resources: https://sota.jiqizhixin.com/project/td-lstm-2 |
Visit the SOTA! Model Resource Station (sota.jiqizhixin.com) to obtain the implementation code, pre-trained models, and APIs mentioned in this article.
Web Access: Enter the new site address sota.jiqizhixin.com in the browser address bar to visit the “SOTA! Model” platform and check if there are new resources for the models you are interested in.
Mobile Access: Search for the service account name “Machine Heart SOTA Model” or ID “sotaai” in the WeChat mobile app, follow the SOTA! Model service account, and use the platform features through the bottom menu bar of the service account. You will also receive regular updates on the latest AI technologies, development resources, and community dynamics.