Machine Heart Column
This article will be serialized in 3 parts, introducing 17 classic models that have achieved SOTA in speech recognition tasks.
-
Part 1: NNLM, RNNLM, LSTM-RNNLM, Bi-LSTM, Bi-RNN+Attention, GPT-1
-
Part 2: BERT, Transformer-XL, EeSen, FSMN, CLDNN, Highway LSTM
-
Part 3: Attention-lvcsr, Residual LSTM, CTC/Attention, Transformer-Transducer, Conformer
You are reading Part 1 of this series. Visit SOTA! Model Resource Station (sota.jiqizhixin.com) to access the implementation code, pre-trained models, and APIs included in this article.
| Model | SOTA! Model Resource Station Status | Source Paper |
|---|---|---|
| NNLM | https://sota.jiqizhixin.com/project/nnlm | A Neural Probabilistic Language Model |
| RNNLM |
https://sota.jiqizhixin.com/project/rnnlm-2 |
Recurrent Neural Network Based Language Model |
| LSTM-RNNLM |
https://sota.jiqizhixin.com/project/lstm-rnnlm |
LSTM Neural Networks for Language Modeling |
| Bi-LSTM |
https://sota.jiqizhixin.com/project/bi-lstm-7 Number of Implementations: 3 Supported Frameworks: TensorFlow, PyTorch |
Hybrid Speech Recognition with Deep Bidirectional LSTM |
| Bi-RNN+Attention | https://sota.jiqizhixin.com/project/bi-rnn-attention-2 | Attention is All You Need |
| GPT-1 |
https://sota.jiqizhixin.com/project/gpt-1 Number of Implementations: 2 Supported Frameworks: TensorFlow, PyTorch |
Improving Language Understanding by Generative Pre-Training |
Speech recognition refers to the process of converting speech signals into text. Specifically, it involves inputting a segment of speech signal and finding a sequence of characters (composed of words or letters) that matches the speech signal to the highest degree. This degree of matching is generally represented by probability. A speech recognition system typically consists of several components: signal processing, decoder, and text output. The signal processing module extracts the most important features from the speech according to the auditory perception characteristics of the human ear, converting the speech signal into a feature vector sequence. Common acoustic features used in current speech recognition systems include Linear Predictive Coding (LPC), Mel-frequency Cepstrum Coefficients (MFCC), and Mel-scale Filter Bank (FBank). The decoder converts the input feature vector sequence into a character sequence based on the Acoustic Model (AM) and Language Model (LM). The decoder calculates the acoustic model score and language model score for the given feature vector sequence and several hypothesis word sequences, outputting the word sequence with the highest overall score as the recognition result. Among them, the acoustic model represents knowledge regarding the variables of acoustics, phonetics, environment, as well as differences in speaker gender and accent, mainly predicting the probability of generating features X from the pronunciation of word W. The training data for the acoustic model consists of labeled sound features (with corresponding text content); the language model represents knowledge of a sequence of characters, mainly predicting the probability of a certain word or sequence of words. The training data for the language model consists of grammatically correct sentences (plain text). From the perspective of language models, in recent years, with the development of deep learning, neural network language models (NLMs) have gradually become mainstream methods due to their ability to map word vectors into low-dimensional continuous space, exhibiting better generalization performance. The earliest neural language model was based on feedforward neural networks (FNNs), which initially achieved modeling of long text sequences in low-dimensional continuous space, but the length of text that could be processed was limited by the input length of the network. Later, recurrent neural networks (RNNs) represented language models that utilized cyclic structures theoretically to model sequences of infinite length, greatly improving performance. Language models based on Long Short-Term Memory Recurrent Neural Networks (LSTM-RNNs) addressed the gradient vanishing problem of RNNs when modeling long historical sequences, achieving good results across various tasks. In recent years, language models based on Transformers have demonstrated stronger modeling capabilities for long texts under the influence of self-attention mechanisms, achieving optimal performance across a series of natural language and speech tasks. The evolution of language models indicates that the core research focus is on how to enhance the model’s ability to capture information from long historical sequences, which is also a core issue that neural language models need to consider in speech recognition applications. From the perspective of acoustic models, traditional speech recognition systems generally adopt GMM-HMM-based acoustic models, where GMM is used to model the distribution of speech acoustic features, and HMM is used to model the temporal nature of speech signals. After the rise of deep learning in 2006, Deep Neural Networks (DNNs) were applied to speech acoustic modeling. In 2009, Hinton and his students applied feedforward fully connected deep neural networks to speech recognition acoustic modeling, achieving significant performance improvements on the TIMIT database with DNN-HMM acoustic models compared to traditional GMM-HMM acoustic models. The advantages of DNNs over GMMs include: 1) DNNs model the posterior probabilities of speech acoustic features without requiring distributional assumptions about the features; 2) GMMs require decorrelation processing of input features, while DNNs can utilize various forms of input features; 3) GMMs can only use single-frame speech as input, while DNNs can utilize effective contextual information by concatenating adjacent frames. In 2011, Deng Li and others proposed a CD-DNN-HMM acoustic model, achieving success in large vocabulary continuous speech recognition tasks, obtaining over a 20% relative performance improvement compared to traditional GMM-HMM systems. DNN-HMM-based speech acoustic models began to replace GMM-HMM as the mainstream acoustic model. Subsequently, many researchers invested in research on speech acoustic modeling based on deep neural networks, leading to breakthroughs in speech recognition.
This article summarizes the classic TOP models in neural speech recognition, focusing on the neural language model and neural acoustic model.
1. Neural Language Model
1. NNLM
This article was the first to propose using neural networks to solve the language model problem. Although it did not receive much attention at the time, it laid a solid foundation for the later application of deep learning in solving language model problems and many other NLP issues. The main contribution of this article is the construction of a language model using a multi-layer perceptron (MLP), as shown in Figure 1:
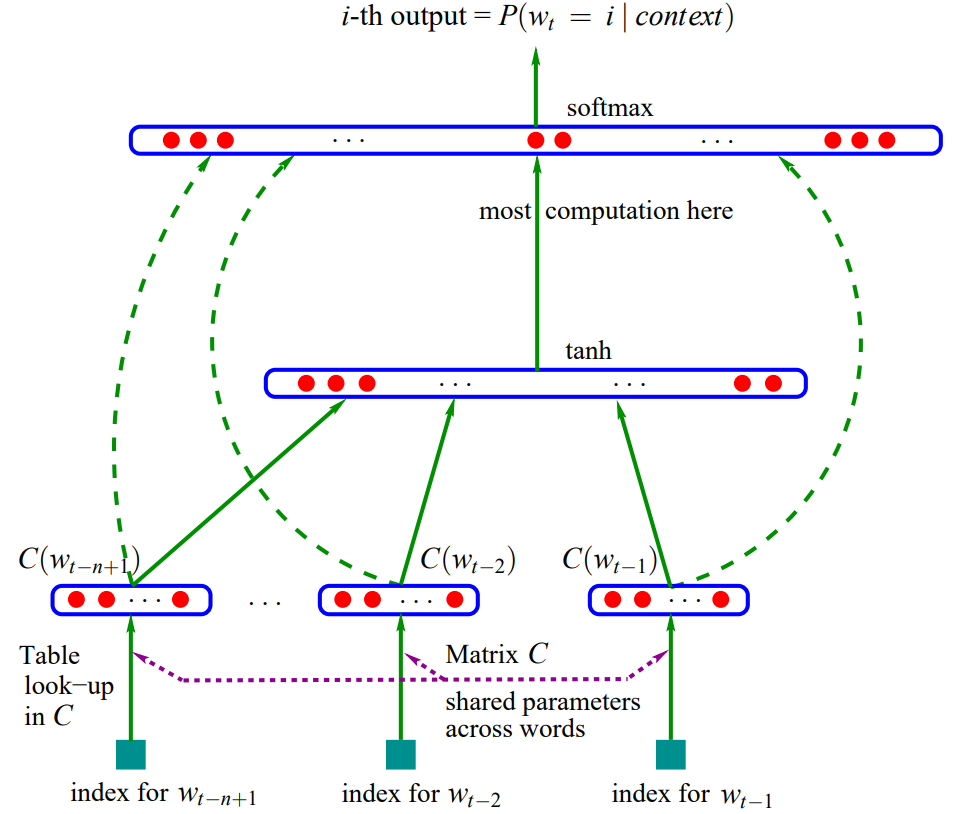
Figure 1. Neural Structure: f(i,w_t-1,…,w_t-n+1) = g(i,C(w_t-1),…,C(w_t-n+1)), where g is the neural network, and C(i) is the feature vector of the i-th word.
The NNLM model consists of three layers. The first layer is the mapping layer, which maps n words into the corresponding concatenated word embeddings, serving as the input layer of the MLP. The second layer is the hidden layer, with the activation function being tanh. The third layer is the output layer, which is a multi-classifier using softmax for classification, as the language model needs to predict the next word based on the previous n words. The highest computational load of the entire model is concentrated in the last layer, as vocabulary sizes are generally large, making the computation of the conditional probability for each word the bottleneck of the model. Specifically, the neural network uses the softmax output layer to calculate the following function, which ensures positive probabilities that sum to 1:
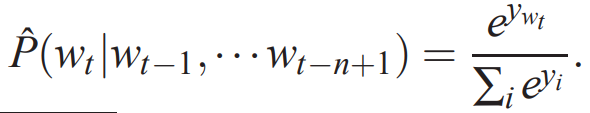
Where y_i is the unnormalized log probability for each output word i:
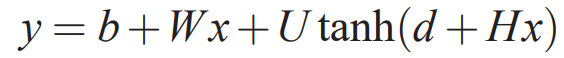
In the case of element-wise application of the hyperbolic tangent function tanh, W is chosen to be zero (no direct connection), and x is the activation vector of the word feature layer, which is a concatenation of the input word features from matrix C:
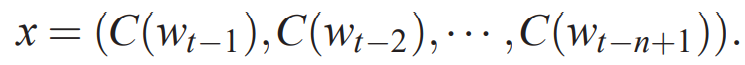
Let h be the number of hidden units, and m be the number of features associated with each word. When there is no need for a direct connection from word features to output, the matrix W is set to 0. The free parameters of the model are the output bias b (with |V| elements), the hidden layer bias d (with h elements), the weights from hidden to output U (a |V|×h matrix), the weights from word features to output W (a |V|×(n-1)m matrix), the weights of the hidden layer H (an h×(n-1)m matrix), and the word features C (a |V|×m matrix).
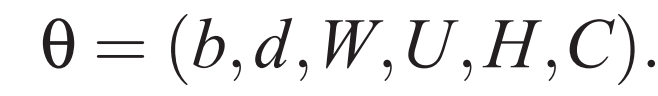
The number of free parameters is |V|(1+nm+h)+h(1+(n-1)m), with the dominant number of parameters being determined by |V|(nm + h). Theoretically, if weights W and H have weight decay while C does not, then W and H can converge to zero, while C will explode. The stochastic gradient ascent on the neural network includes the following iterative updates after presenting the t-th word of the training corpus:
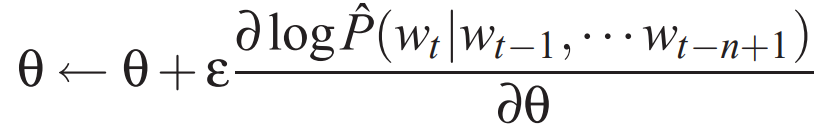
Note that after each sample, there is no need to update or access the vast majority of parameters: all words j of word features C(J) that do not appear in the input window. The effectiveness of the NNLM may not seem significant now, but it holds substantial importance for subsequent related research. The Future Work section of the paper mentions that using RNNs instead of MLPs as models could yield better results, a notion validated in Tomas Mikolov’s doctoral thesis, leading to the later RNNLM.
This article is a paper published by Sutskever I. et al. in 2014 at NeurIPS, which is the most fundamental Seq2Seq model in natural language processing, currently cited over 12,000 times. The most common Seq2Seq model is the Encoder-Decoder model. Due to the sequential nature of time series data, we typically use RNNs (Recurrent Neural Networks) in the Encoder to obtain the feature vector of the input sequence, then input this feature vector into another RNN model in the Decoder to generate each point of the target sequence sequentially. This paper uses multi-layer Long Short-Term Memory networks (LSTMs) to map the input sequence to a fixed-dimensional vector, and then uses another deep LSTM to decode the target sequence from this vector. Through EncoderRNN and DecoderRNN, we can obtain the predicted sequence, compare it with the benchmark true value sequence to calculate the error, and update parameters to continuously train the model.
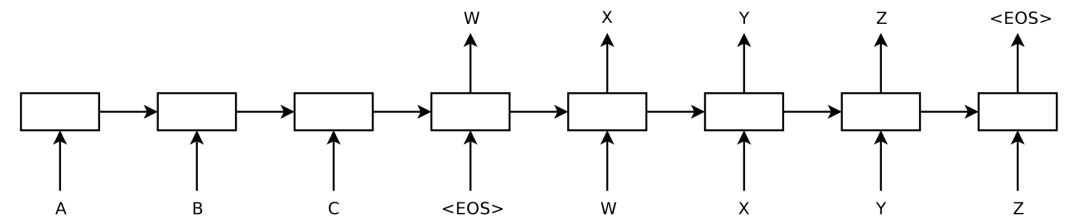 Figure 1. The model reads an input sentence “ABC” and generates “WXYZ” as the output sentence. The model stops predicting after the end-of-sequence marker at the end of the output.
Figure 1. The model reads an input sentence “ABC” and generates “WXYZ” as the output sentence. The model stops predicting after the end-of-sequence marker at the end of the output.
RNNs are a natural generalization of feedforward neural networks for sequences. Given an input sequence (x_1, … , x_t), a standard RNN computes an output sequence (y_1, … , y_T) iteratively through the following formula:
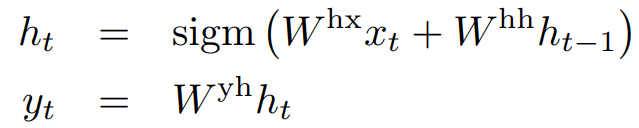
As long as the arrangement between input and output is known in advance, RNNs can easily map sequences to sequences. At the stage when this paper was published, it was still unclear how to apply RNNs to problems where the input and output sequences have different lengths and complex non-monotonic relationships. The simplest strategy for general sequence learning is to use an RNN to map the input sequence to a fixed-size vector, and then use another RNN to map this vector to the target sequence. Although this is theoretically feasible, since RNNs are provided with all relevant information, training RNNs can be challenging due to the resulting long-term dependencies. However, it is well known that Long Short-Term Memory (LSTM) can learn problems with long-distance time dependencies, so LSTMs may succeed in this case. The goal of LSTM is to estimate the conditional probability p(y1, . . , yT′ |x1, . . , xT), where (x1, . . , xT) is an input sequence, and y1, . . . , yT′ is the corresponding output sequence, which may have a different length T′ than T. LSTM calculates this conditional probability by first obtaining a fixed-dimensional representation of the input sequence (x1, …, xT) given by the last hidden state of the LSTM, and then using standard LSTM to compute the probability of y1, …, yT′, with the initial hidden state set to the representation v of (x1, …, xT):
In this equation, each p(yt|v, y_1, …, y_t-1) distribution is represented using softmax over all words in the vocabulary. Additionally, each sentence is required to end with a special end-of-sequence symbol “<EOS>”, allowing the model to define a distribution over sequences of all possible lengths.
| Item | SOTA! Platform Project Details |
|---|---|
| NNLM | Visit SOTA! Model Platform for implementation resources: https://sota.jiqizhixin.com/project/nnlm |
2. RNNLM
The design idea of the RNNLM model is relatively simple, mainly improving the feedforward neural network in NNLM, with the main structural diagram shown in Figure 2:
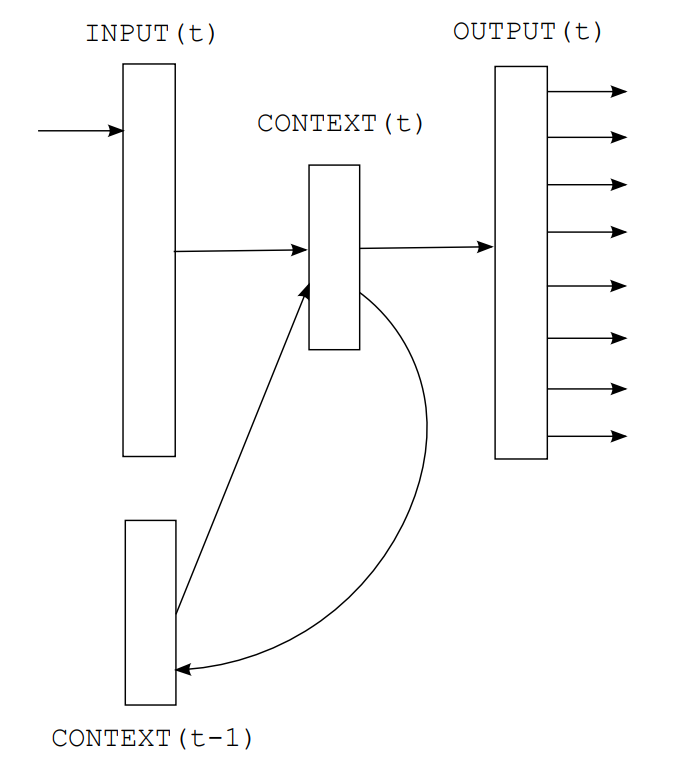
Figure 2. RNNLM Structure
One major drawback of NNLM is that the feedforward network must use a fixed-length context, which needs to be specified in advance during training. Typically, this means that the neural network can only see five to ten preceding words when predicting the next word. It is well known that humans can utilize longer contexts very successfully. Additionally, cache models provide supplementary information to neural network models, so it is natural to consider whether a model can be designed to implicitly encode temporal information for arbitrary context lengths.
| Item | SOTA! Platform Project Details |
|---|---|
| RNNLM | Visit SOTA! Model Platform for implementation resources: https://sota.jiqizhixin.com/project/rnnlm-2 |
3. LSTM-RNNLM
Feedforward networks only utilize fixed context lengths to predict the next sequence word, making training difficult. LSTM-RNNLM introduces the Long Short-Term Memory neural network architecture to address these issues: modifying the network structure to avoid the gradient vanishing problem while keeping the training algorithm unchanged. Specifically, the units of the neural network are redesigned to keep their corresponding scaling factors fixed at 1. The new unit type obtained from this design goal has limited learning ability. Further, gated units are introduced to enhance their learning capability. The resulting neural unit is shown in Figure 3.
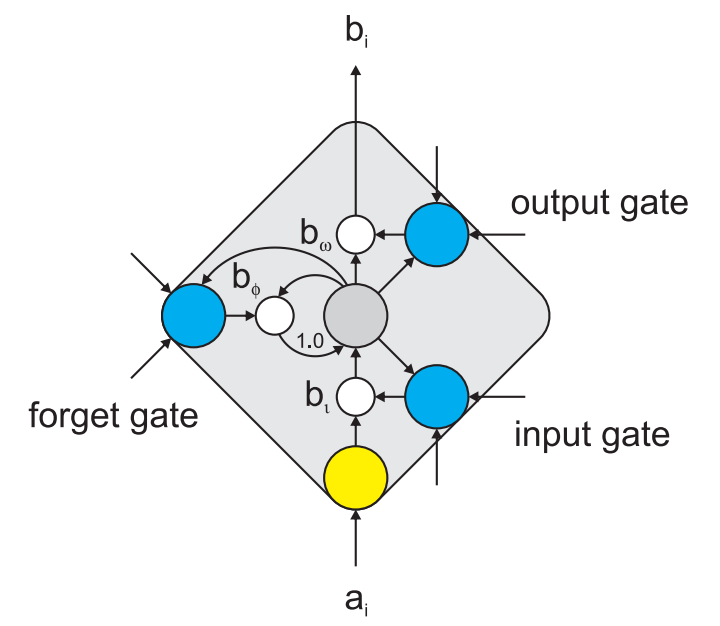 Figure 3. LSTM Memory Unit with Gated Units
Figure 3. LSTM Memory Unit with Gated Units
A standard neural network unit i consists only of input activation a_i and output activation b_i, and when using the tanh activation function, their relationship is:
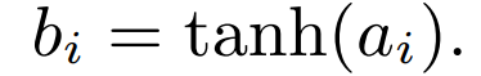
The gated unit takes the previous hidden layer, the current layer from the previous time step, and the internal activation of the LSTM unit, then processes the activated values using the logistic function, setting them as b_1, b_φ, and b_ω respectively.
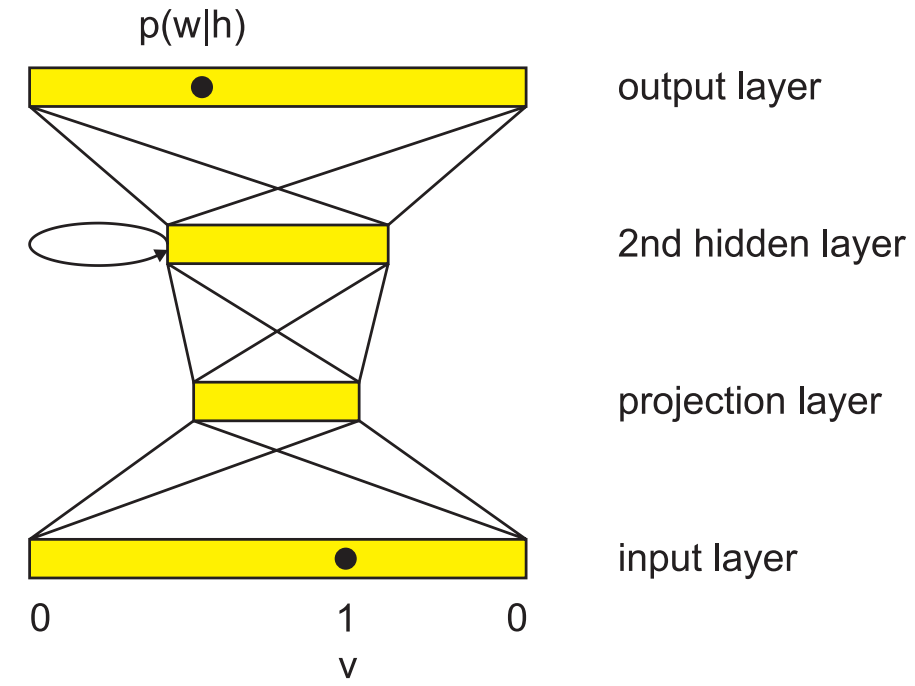
Figure 4. Neural Network LM Architecture
The final neural network language model architecture is shown in Figure 4, inserting LSTM units into the second recursive layer and combining them with different projection layers of standard neural network units. For large vocabulary language modeling, training is largely dominated by the computation of input activation a_i of the softmax output layer, which is not sparse compared to the input layer:
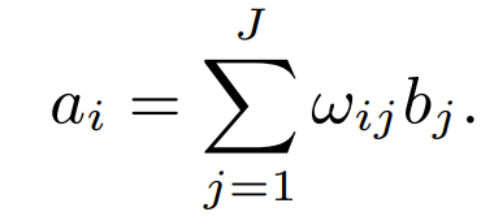
To reduce computational workload, the words are divided into a set of disjoint word categories. Then, the probability p(w_m|(w_1)^(m-1)) is decomposed as follows:
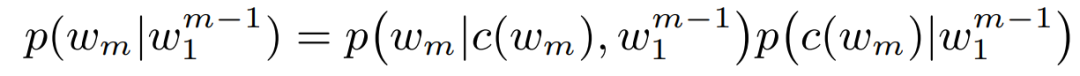
| Item | SOTA! Platform Project Details |
|---|---|
| LSTM-RNNLM | Visit SOTA! Model Platform for implementation resources: https://sota.jiqizhixin.com/project/lstm-rnnlm |
4. Bi-LSTM
Given an input sequence x = (x_1, … , x_T), a standard RNN computes the hidden vector sequence h = (h_1, … , h_T) and output vector sequence y = (y_1, … , y_T) by iterating the following equation from t = 1 to T:
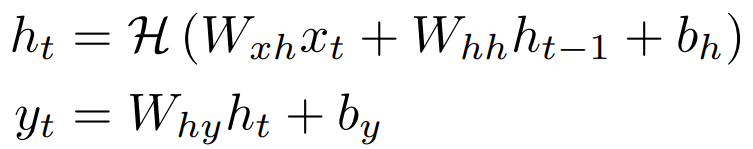
Typically, H is implemented as an element-wise application of a sigmoid function. The LSTM architecture uses specialized memory units to store information, being more advantageous in finding and utilizing long-distance context. Figure 5 shows a single LSTM memory unit. H is realized by the following composite function:
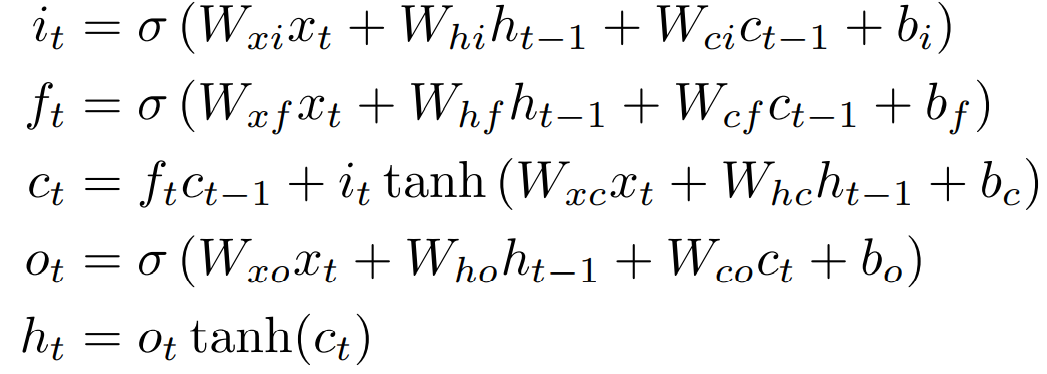
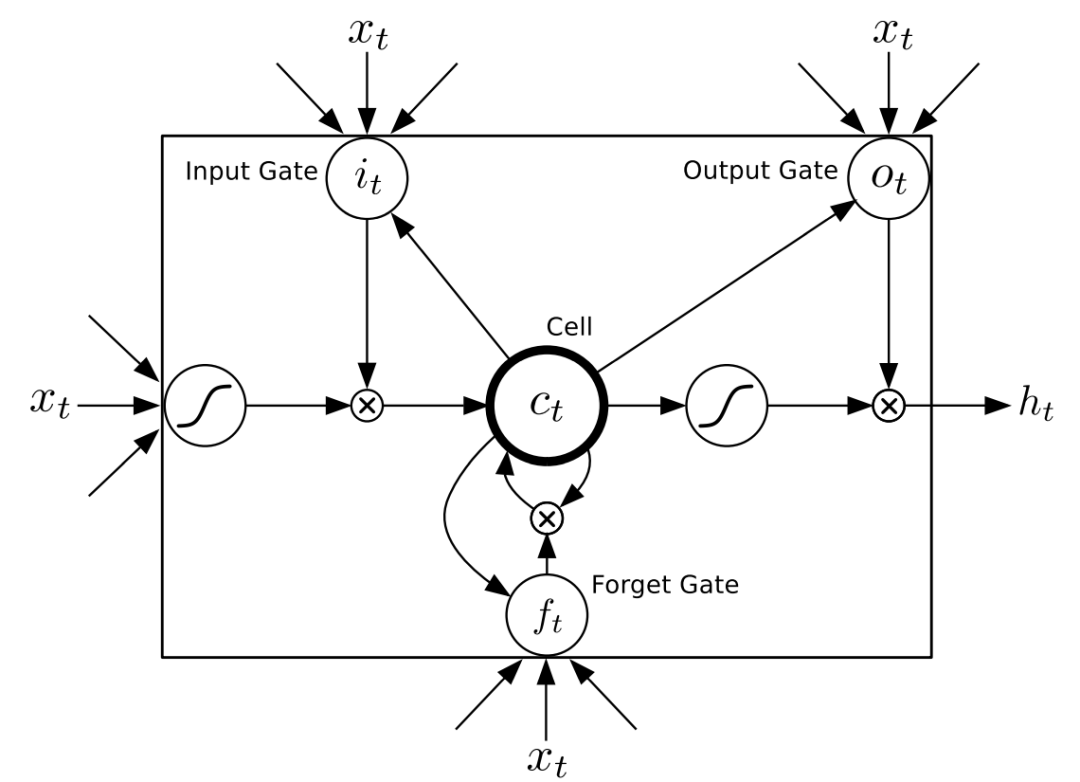
Figure 5. LSTM Memory Unit
Traditional RNNs have a significant drawback: they can only utilize previous contexts. In speech recognition, the entire corpus is transcribed at once, thus requiring consideration of future context information. Bidirectional RNNs (BRNNs) achieve this by processing data in both directions using two independent hidden layers, then feeding this data back to the same output layer. As shown in Figure 6, BRNNs compute the forward hidden sequence →h and the backward hidden sequence ←h by iterating from t=T to 1 and from t=1 to T, respectively, then updating the output layer:
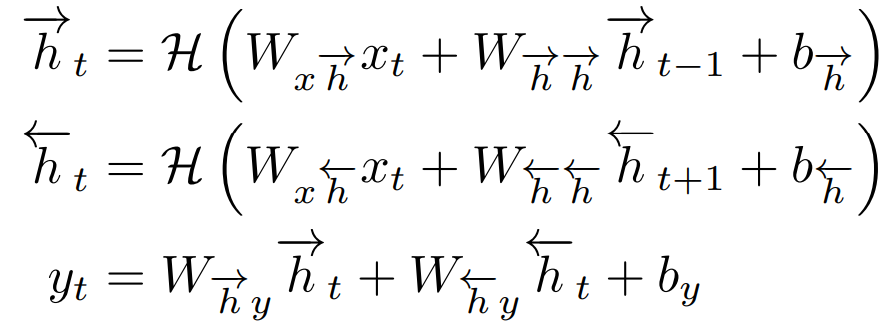
Combining BRNNs with LSTMs yields Bidirectional LSTMs, which can capture long-distance context in both input directions, as shown in Figure 6.
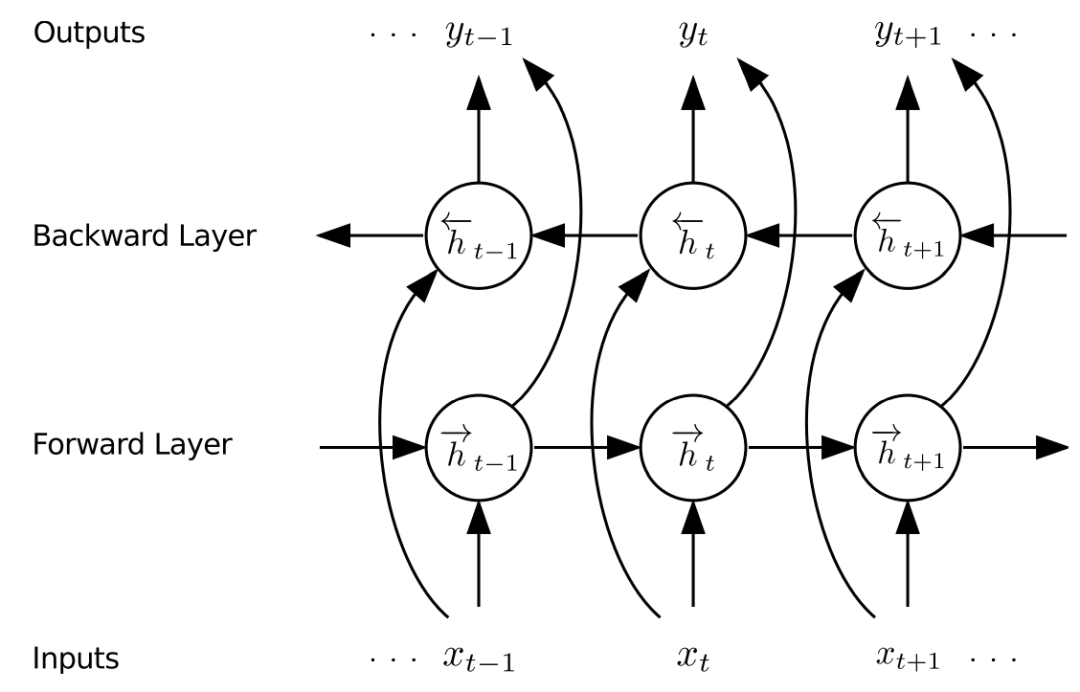
Figure 6. Bidirectional RNN
Deep RNNs can be created by stacking multiple RNN hidden layers, where the output sequence of one layer forms the input sequence of the next layer, as shown in Figure 7. Assuming all N layers in the stack use the same hidden layer function, the hidden layer vector sequences h^n from n=1 to N and t=1 to T are repeatedly computed:
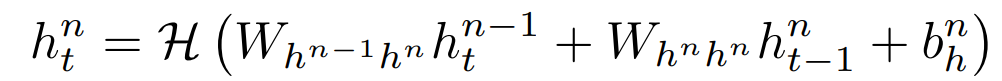
The network output y_t is:
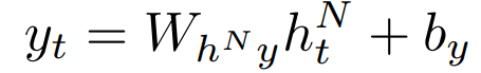
Deep Bidirectional RNNs can be realized by replacing each hidden sequence h^n with the forward and backward sequences →h^n and ←h^n, ensuring that each hidden layer receives inputs from both the forward and backward layers of the layer below. If the hidden layers use LSTMs, we obtain Deep Bidirectional LSTMs (DBLSTMs), as shown in Figure 8.
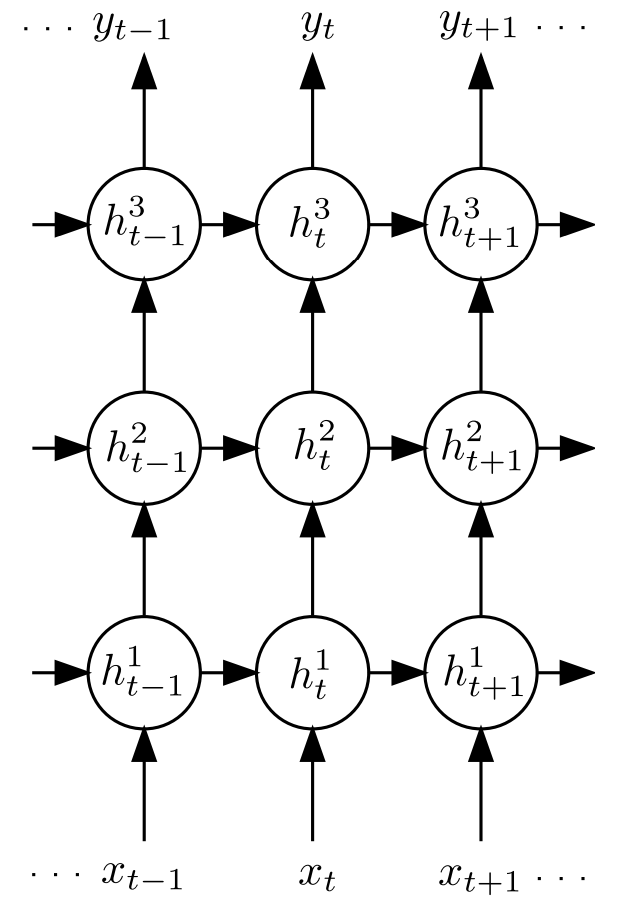 Figure 7. Deep RNN
Figure 7. Deep RNN
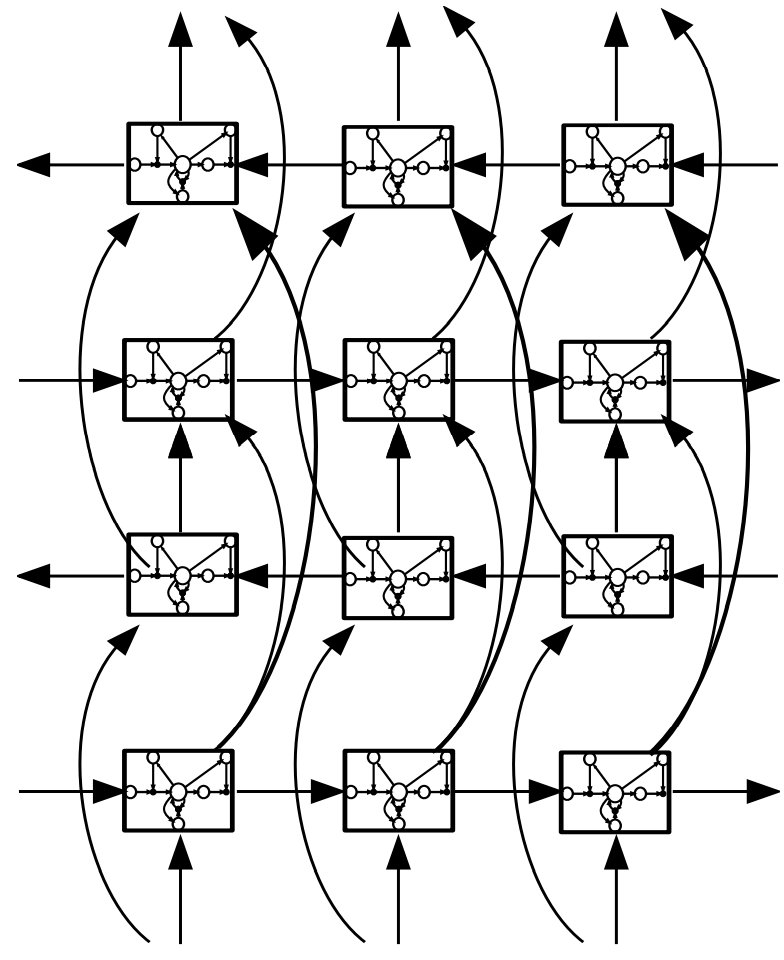 Figure 8. Deep Bidirectional Long Short-Term Memory Network (DBLSTM)
Figure 8. Deep Bidirectional Long Short-Term Memory Network (DBLSTM)
Currently, the SOTA! platform includes a total of 3 model implementation resources for Bi-LSTM, supporting popular frameworks including PyTorch and TensorFlow.
| Item | SOTA! Platform Project Details |
|---|---|
| Bi-LSTM | Visit SOTA! Model Platform for implementation resources: https://sota.jiqizhixin.com/project/bi-lstm-7 |
5. BiRNN+Attention
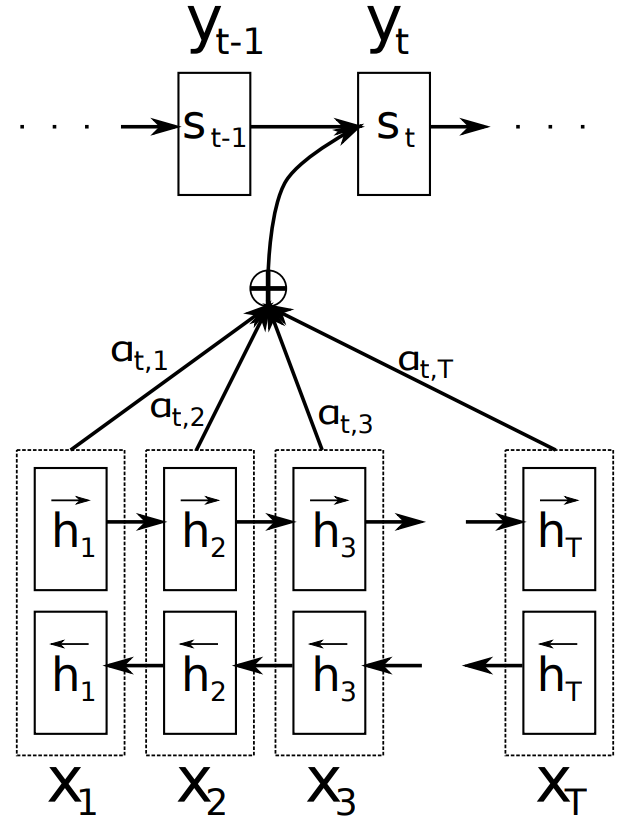
BiRNN+Attention uses a typical encoder-decoder structure, where the encoder part utilizes BiRNN, and the decoder part employs the attention mechanism. For a standard RNN model, the input (x_1,x_2,…,x_T) can yield T forward hidden layer states (h→,…,h→T) after T time steps; then, reversing the order of the input sequence words results in (x_T,…,x_2,x_1), which is passed through the RNN again to obtain the backward hidden layer states (h←1,…,h←T). Finally, to obtain the vector representation of word x_j, we simply concatenate the forward hidden state h→j with the backward hidden state h←j, for example: h_j=[h→j;h←j]. In the decoder, the author introduces the attention mechanism. The decoder outputs the target sequence as follows:
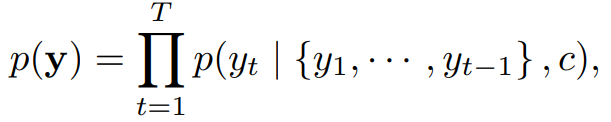
For RNN models, each conditional probability is modeled as follows:
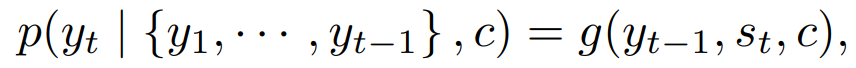
The conditional probabilities used by this model are as follows:
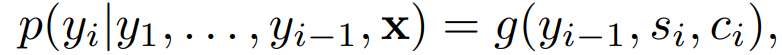
It is important to note that for each target word y_i, the context vector c_i used to calculate its conditional probability is different. This differs from traditional encoder-decoder models. c_i refers to the intermediate semantic variable, which the author calls the context variable in the paper. First, c_i depends on all hidden states from the encoder (h_1,…,h_T), and second, in the case of bidirectional recurrent neural networks, h_i contains information about the entire input sequence, but the information is more concentrated around the i-th word position in the input sequence. Finally, when translating the output word, different hidden states h_i contribute differently to the output sequence.
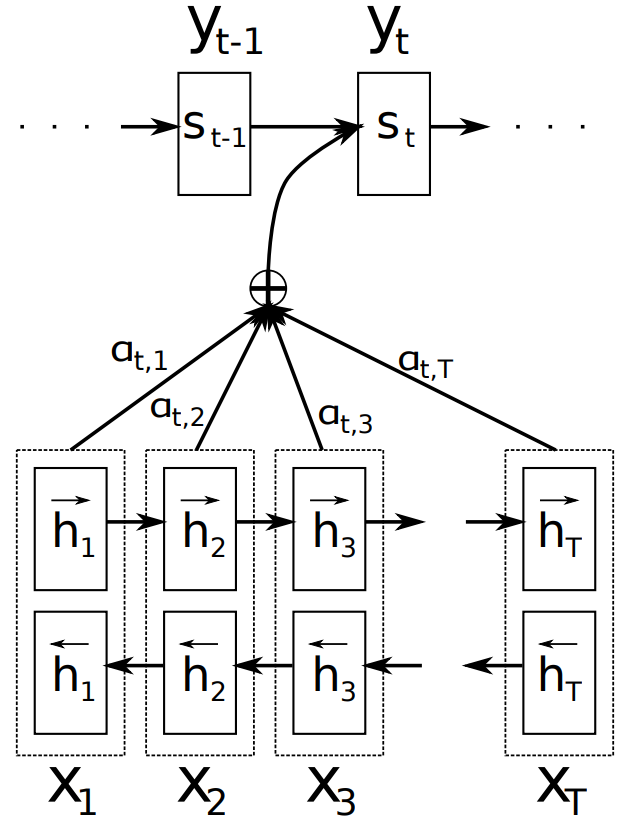 Figure 9. Model illustration, generating the t-th target word y_t based on the source sentence (x_1, x_2, …, x_T).
Figure 9. Model illustration, generating the t-th target word y_t based on the source sentence (x_1, x_2, …, x_T).
Encoder (BIDIRECTIONAL RNN FOR ANNOTATING SEQUENCES A BiRNN consists of a forward and a backward RNN. The forward RNN →f reads the input sequence sequentially (from x_1 to x_Tx) and computes the forward hidden state sequence (→h_1,…, →h_Tx). The backward RNN ←f reads the sequence in reverse order (from x_Tx to x_1), generating a backward hidden state sequence (←h_1, …,←h_Tx). We obtain an annotation for each word x_j by concatenating the forward hidden state →h_j and the backward hidden state ←h_j. This way, the annotation h_j contains a summary of the preceding and following words. This series of annotations is used by the decoder and alignment model to compute the context vector. The complete model illustration can be seen in Figure 9.
| Item | SOTA! Platform Project Details |
|---|---|
| Bi-RNN+Attention | Visit SOTA! Model Platform for implementation resources: https://sota.jiqizhixin.com/project/bi-rnn-attention-2 |
6. GPT-1
BiRNN+Attention uses a typical encoder-decoder structure, where the encoder part utilizes BiRNN, and the decoder part employs the attention mechanism. For a standard RNN model, the input (x_1,x_2,…,x_T) can yield T forward hidden layer states (h→,…,h→T) after T time steps; then, reversing the order of the input sequence words results in (x_T,…,x_2,x_1), which is passed through the RNN again to obtain the backward hidden layer states (h←1,…,h←T). Finally, to obtain the vector representation of word x_j, we simply concatenate the forward hidden state h→j with the backward hidden state h←j, for example: h_j=[h→j;h←j]. The decoder introduces the attention mechanism. The decoder outputs the target sequence as follows:
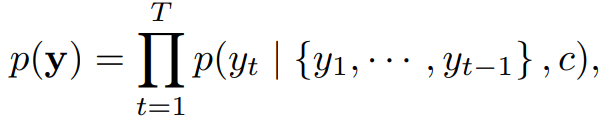
For RNN models, each conditional probability is modeled as follows:
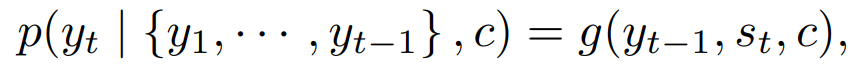
The conditional probabilities used by this model are as follows:
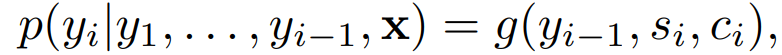
It is important to note that for each target word y_i, the context vector c_i used to calculate its conditional probability is different. This differs from traditional encoder-decoder models. c_i refers to the intermediate semantic variable, which the author calls the context variable in the paper. First, c_i depends on all hidden states from the encoder (h_1,…,h_T), and second, in the case of bidirectional recurrent neural networks, h_i contains information about the entire input sequence, but the information is more concentrated around the i-th word position in the input sequence. Finally, when translating the output word, different hidden states h_i contribute differently to the output sequence.
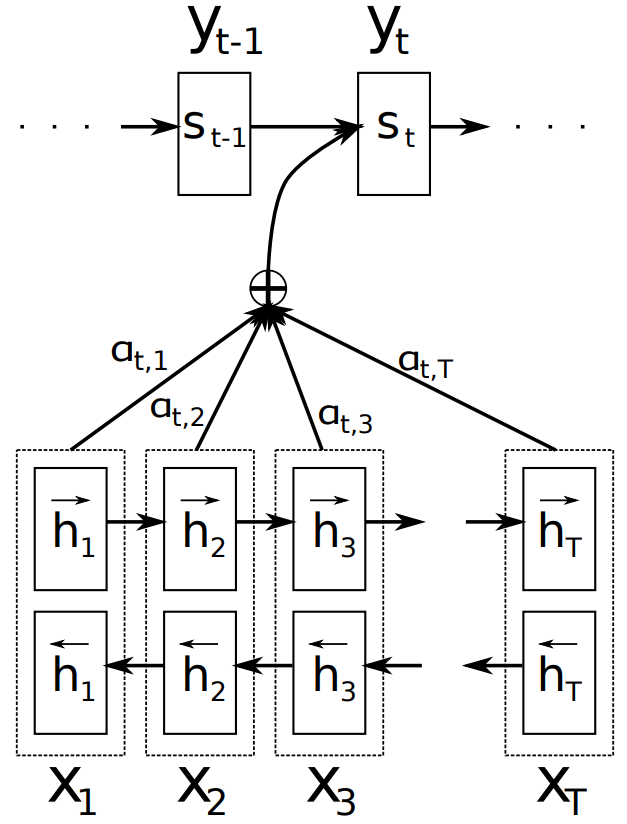 Figure 9. Model illustration, generating the t-th target word y_t based on the source sentence (x_1, x_2, …, x_T).
Figure 9. Model illustration, generating the t-th target word y_t based on the source sentence (x_1, x_2, …, x_T).
Visit SOTA! Model Resource Station (sota.jiqizhixin.com) to access the implementation code, pre-trained models, and APIs included in this article.
Web Access: Enter the new site address sota.jiqizhixin.com in the browser address bar to visit the “SOTA! Model” platform and check if new resources have been added for the models you care about.
Mobile Access:Search for the service number name “Machine Heart SOTA Model” or ID “sotaai” in the WeChat mobile app, follow the SOTA! Model service number, and you can use platform features through the bottom menu of the service number, with the latest AI technologies, development resources, and community dynamics pushed regularly.