MLNLP(Machine Learning Algorithms and Natural Language Processing) community is a well-known natural language processing community both domestically and internationally, covering NLP graduate students, university teachers, and corporate researchers.
The Vision of the Community is to promote communication and progress between the academic and industrial circles of natural language processing and machine learning, especially for the progress of beginners.
Reprinted from | RUC AI Box
Author|Gong Zheng
Institution|Renmin University of China
Research Direction|Natural Language Processing
In recent years, with the development of pre-training technology, models have achieved excellent performance in most natural language processing tasks by pre-training on massive text corpora. However, it appears that models with relatively small parameter counts still struggle to adequately store the knowledge from the pre-training corpus within their parameters. Therefore, aside from the increasingly larger pre-trained models currently being developed, another area of research focuses on how to enhance models using non-parametric external corpora/knowledge bases, such as allowing models to retrieve documents from a corpus that are beneficial for completing the current task.
The author believes that these methods of enhancing models with external knowledge can be roughly divided into two categories based on the type of knowledge provided: the first category provides models with a broad range of knowledge, which often directly or indirectly contains the answers to the current tasks, such as documents in question-answering tasks or knowledge graphs. Therefore, the performance of this category largely depends on the precision of the retrieval module, that is, whether the model can accurately locate the knowledge it needs. The second category provides examples that the model can refer to in certain aspects, such as question-answer pairs in question-answering tasks. This paper refers to this category of methods as example-augmented methods and selects eight articles for brief introduction, divided into four subcategories, including some personal insights. Any errors or deficiencies are welcome to be pointed out.
A more obvious application scenario for enhancing models using examples is in certain generation tasks where answers from examples can be directly copied. In this type of work, the model primarily references the textual content of the retrieved examples. Below are introductions to two related works in this area:
Prototype-to-Style: Dialogue Generation with Style-Aware Editing on Retrieval Memory, IEEE/ACM Transactions on Audio, Speech, and Language Processing 2021
This paper comes from the University of Cambridge, Tencent AI LAB, and the Chinese University of Hong Kong. The article mainly focuses on how to generate dialogues of a specific style, where the general idea is to use the retrieved dialogue content as a template, and then the model edits the content according to the specified style, as shown in the figure below:
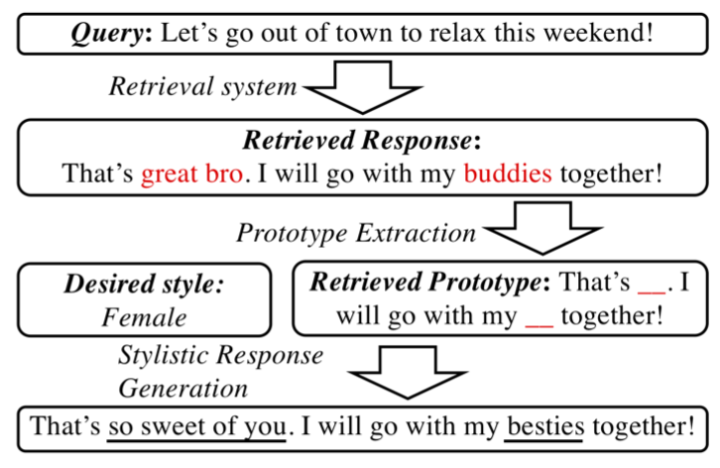
Specifically, the method introduced in this paper includes three modules: Prototype Extraction, Stylistic Response Generator, and Learning.
Prototype Extraction:This paper obtains a response template by masking style-related words in the retrieved responses. To define which words are style-related, the paper calculates the pointwise mutual information (PMI) for all vocabulary that appears in the training set and style.
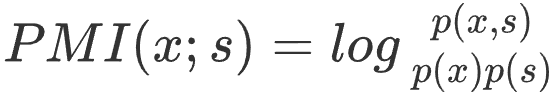
, p(x,s) represents the frequency of vocabulary x appearing in responses of style s. When PMI(x,s) exceeds a certain threshold, x is considered to be a style-related word.
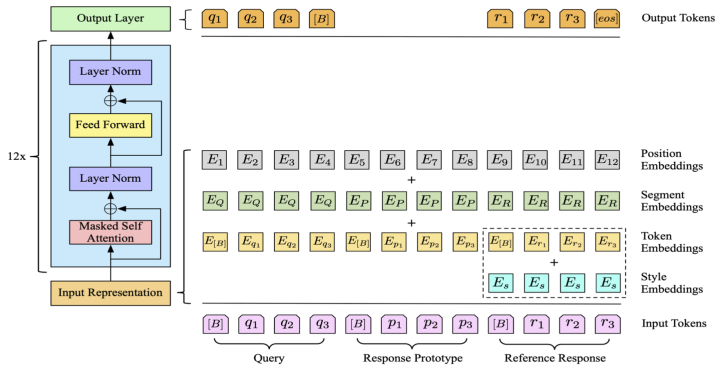
Stylistic Response Generator:This paper uses GPT2 as the generation model, concatenating the query, response prototype, and reference response with a separator as input, and adding corresponding segment embeddings to distinguish them. To learn to generate language in a specific style, the paper learns a style embedding for each style and adds it to the generated response part. The overall framework is shown in the figure below:
Learning:The training part of this paper does not involve the retrieval module but directly applies denoise operations such as stylist word mask, random mask, and random replace on the reference responses to obtain response prototypes. The advantage of this approach is that it ensures the correlation between templates and references during training while avoiding the model from copying and pasting word-for-word. Finally, the paper increases the loss weight of stylist words in the training loss and introduces the LM Loss of the query part as auxiliary loss.
Neural Machine Translation with Monolingual Translation Memory, ACL 2021
This paper comes from the Chinese University of Hong Kong and Tencent AI LAB and is an outstanding paper at ACL 2021.
Another application scenario where examples can be used as templates is machine translation. By retrieving source sentences similar to the current input, the model can completely refer to the target sentence of the retrieved example to generate the translation of the current input. However, this method usually requires a large amount of aligned corpus as the retrieval library. This paper attempts to solve this pain point by using a monolingual corpus as the retrieval library to enhance the model. The model framework diagram of this paper is as follows:
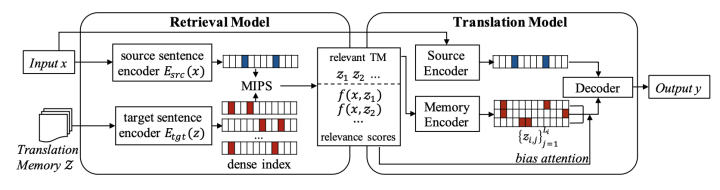 Retrieval Model:The retrieval corpus set in this paper is a monolingual corpus of the target language. The paper first employs a Dual-Encoder approach to encode the input sentence and the sentences in the retrieval library separately, then obtains similarity through dot product, and finally uses FAISS to get the M retrieval examples most related to the input sentence. To unify the training of the Retrieval Model and the subsequent Translation Model, the similarity of these M retrieval examples will be further used in the translation process. Here, the retrieval model faces a cold start problem, meaning that the randomly initialized retrieval module may retrieve examples unrelated to the input, which could lead the entire model to learn to ignore the retrieval examples when completing the translation task. Therefore, this paper also designs two sentence-level and token-level alignment tasks to assist in initializing the retrieval module.
Translation Model:The translation module uses both the input sentence and the retrieved examples during generation. Specifically, the model first encodes the input sentence through an Encoder, just like a standard Seq2Seq model, and then generates the representation of the token to be predicted in the Decoder using an autoregressive manner.
Retrieval Model:The retrieval corpus set in this paper is a monolingual corpus of the target language. The paper first employs a Dual-Encoder approach to encode the input sentence and the sentences in the retrieval library separately, then obtains similarity through dot product, and finally uses FAISS to get the M retrieval examples most related to the input sentence. To unify the training of the Retrieval Model and the subsequent Translation Model, the similarity of these M retrieval examples will be further used in the translation process. Here, the retrieval model faces a cold start problem, meaning that the randomly initialized retrieval module may retrieve examples unrelated to the input, which could lead the entire model to learn to ignore the retrieval examples when completing the translation task. Therefore, this paper also designs two sentence-level and token-level alignment tasks to assist in initializing the retrieval module.
Translation Model:The translation module uses both the input sentence and the retrieved examples during generation. Specifically, the model first encodes the input sentence through an Encoder, just like a standard Seq2Seq model, and then generates the representation of the token to be predicted in the Decoder using an autoregressive manner. On this basis, the paper continues to encode each retrieved example using the Encoder, concatenates the obtained representations, and feeds them to the Decoder for cross-attention, obtaining the attention score for each token of each example. These attention scores will be further weighted by the similarity obtained during retrieval. Finally, the probability distribution of the predicted token consists of two weighted parts: one part is the probability obtained by the model using the autoregressive method, and the other part is the probability of directly copying tokens from the retrieved examples, dominated by the attention scores.
On this basis, the paper continues to encode each retrieved example using the Encoder, concatenates the obtained representations, and feeds them to the Decoder for cross-attention, obtaining the attention score for each token of each example. These attention scores will be further weighted by the similarity obtained during retrieval. Finally, the probability distribution of the predicted token consists of two weighted parts: one part is the probability obtained by the model using the autoregressive method, and the other part is the probability of directly copying tokens from the retrieved examples, dominated by the attention scores.
『Retrieve Rather Than Memorize』
An important characteristic of deep learning models is their good generalization ability, meaning that the knowledge learned by the model from the training set can generalize well to the test set. The following two papers indicate that, rather than relying entirely on training to store all knowledge from the training set within the model parameters, directly retrieving helpful samples may be more efficient.
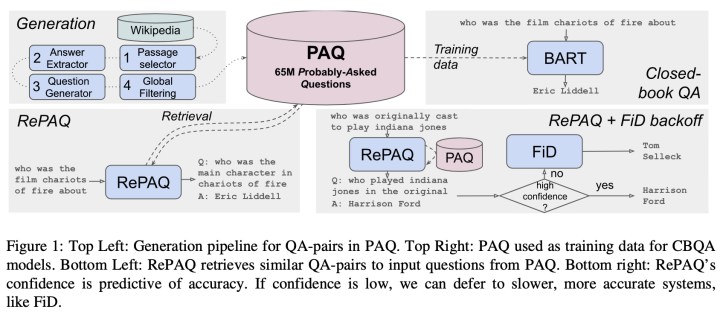
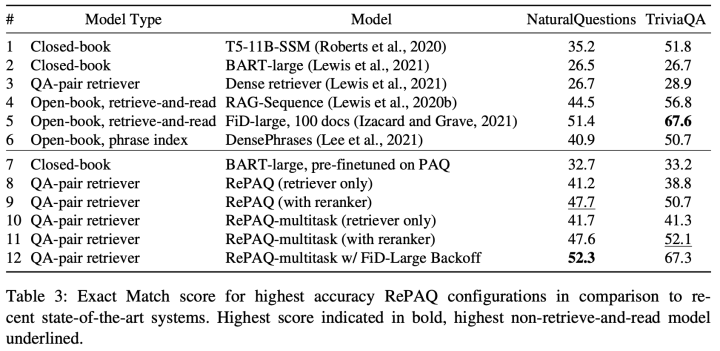
PAQ: 65 Million Probably-Asked Questions and What You Can Do With Them, TACL 2021
This paper comes from Facebook and University College London and was published in TACL 2021.
Current Open Domain QA tasks usually first retrieve from large-scale document corpora, and then based on the retrieved document content perform reading comprehension to obtain the final answer. This method requires a large amount of space and time to store and retrieve document corpora. This paper first designs a data augmentation approach, proposing a dataset containing 65M automatically generated QA pairs called Probably Asked Questions (PAQ), and then explores two aspects of the previous methods for solving ODQA tasks based on this dataset:
1. Closed-Book QA (CBQA)Through fine-tuning the model on a large number of question-answer pairs, the model learns the mapping from questions to answers, allowing it to answer questions without relying on external knowledge/corpora.
2. QA-Pair Retriever (RePAQ)By retrieving question-answer pairs instead of documents to assist the model in answering current questions, this retrieval method has advantages in memory, speed, and accuracy compared to previous retrieval paradigms.
The model structure diagram and some experimental results discussed in this paper are as follows:
The author will not go into detail about the data generation and utilization methods in this paper, focusing mainly on some experimental results. In the comparative experimental results, lines 2,7 and 3,8 show that the expansion of the corpus has a gain for both fine-tuning and retrieval, which is very intuitive. Additionally, comparing lines 3 and 4 reveals that using QA pairs as external knowledge for enhancement is far less efficient than using traditional documents as external knowledge. Finally, comparing lines 7 and 8 shows that enhancing the model by retrieving QA pairs significantly surpasses fine-tuning the model on the PAQ dataset. This seems to indicate that even though QA pairs contain less information than documents, storing the knowledge contained in a large number of QA pairs in an external non-parametric module is superior to storing it in the model parameters.
Training Data is More Valuable than You Think: A Simple and Effective Method by Retrieving from Training Data, ACL 2022
This paper comes from Microsoft and has been accepted by ACL 2022. The idea of this paper is more direct compared to the previous one, directly retrieving similar examples from the training set to assist the model in completing the current task. The methods used in this paper are also relatively simple: (1) Using BM25 as the retriever, where the model filters out the training samples themselves from the retrieval corpus during training. (2) Utilizing retrieved examples through text concatenation.
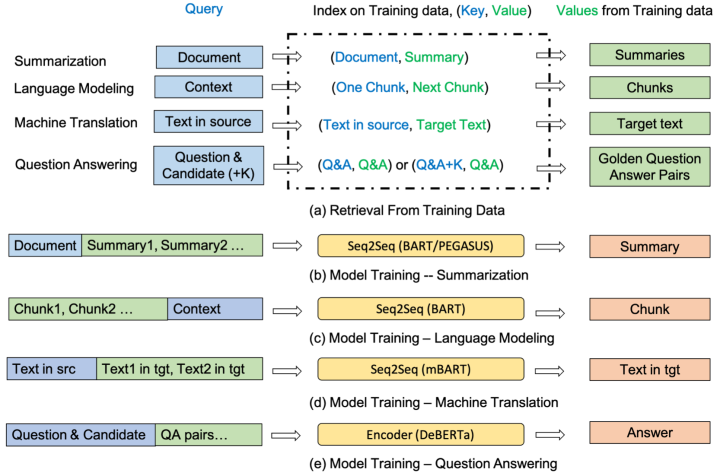 As shown in the figure above, this paper evaluated on four tasks: summarization, language modeling, machine translation, and QA, achieving certain gains based on the original model. It is noteworthy that the datasets used in the experiments are not too small, which also indicates that even during downstream task fine-tuning, models struggle to store all content from the training set in their parameters and utilize it effectively. Therefore, directly retrieving specific examples from the training set can enhance the model.
The following two works focus on the Knowledge Base Question Answering (KBQA) task, aiming to learn how similar examples solve problems, which is possibly the most sensible way to utilize examples beyond mere copying and pasting.
Case-Based Reasoning for Natural Language Queries over Knowledge Bases, EMNLP 2021
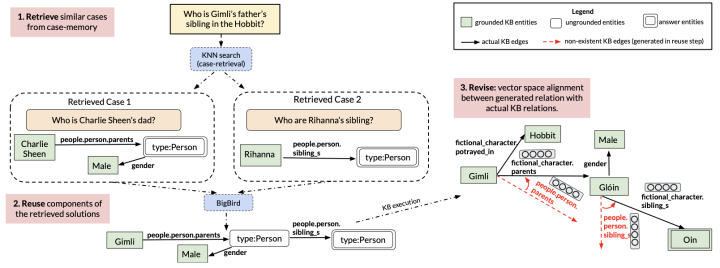
This paper comes from the University of Massachusetts Amherst and Google and was published in EMNLP 2021. This paper is aimed at supervised KBQA scenarios, where each query (question) is labeled with a corresponding logic form (which can be seen as a reasoning path), and the answer to the question can be obtained by executing the logic form labeled for the question in the Knowledge Base. This paper aims to retrieve similar cases for the current query, and then use the reasoning paths of these similar cases to generate the reasoning path for the current query to obtain the final answer. The general framework of the model in this paper is shown in the figure below:
The proposed model specifically includes three parts: Retrieve, Reuse, and Revise:
Retrieve:This paper uses the Dense Passage Retriever (DPR) approach to encode, retrieve, and train the text of the query. The desired retriever in this paper focuses more on the form of the question rather than the specific entities it contains. For example, for the question “Who is Xiao Ming’s brother?”, the paper prefers to retrieve “Who is Xiao Hong’s brother?” rather than “Who is Xiao Ming’s father?” Therefore, the retriever masks the entity parts when encoding the text.
Reuse:This paper uses a generative approach to generate the logic form for the current query. Specifically, the paper concatenates the retrieved query-logic form pairs and feeds them to a Seq2Seq model to generate the logic form of the current query in an autoregressive manner. Since the concatenated input may be particularly long, the paper uses the BigBird model to generate the logic form.
Revise:Due to uncertainty regarding whether certain generated relationship paths exist in the Knowledge Base, the paper further corrects the generated logic form. The paper first encodes the Knowledge Base using a pre-trained TransE model, and then replaces relationships that do not exist in the generated results with the most similar relationships currently in the Knowledge Base.
Knowledge Base Question Answering by Case-based Reasoning over Subgraphs, Arxiv 2022
This paper comes from the University of Massachusetts Amherst and Google and shares the same first author as the previous paper.
KBQA problems typically exist in a weakly supervised environment, where we can only obtain the question and answer but not the specific reasoning path used to obtain the answer from the Knowledge Base. This paper further addresses the weakly supervised KBQA problem based on the previous paper, mainly modifying the Reuse and Revise parts, replacing them with subgraph collection and reasoning on graphs, as shown in the framework below:
As shown in the figure above, this paper evaluated on four tasks: summarization, language modeling, machine translation, and QA, achieving certain gains based on the original model. It is noteworthy that the datasets used in the experiments are not too small, which also indicates that even during downstream task fine-tuning, models struggle to store all content from the training set in their parameters and utilize it effectively. Therefore, directly retrieving specific examples from the training set can enhance the model.
The following two works focus on the Knowledge Base Question Answering (KBQA) task, aiming to learn how similar examples solve problems, which is possibly the most sensible way to utilize examples beyond mere copying and pasting.
Case-Based Reasoning for Natural Language Queries over Knowledge Bases, EMNLP 2021
This paper comes from the University of Massachusetts Amherst and Google and was published in EMNLP 2021. This paper is aimed at supervised KBQA scenarios, where each query (question) is labeled with a corresponding logic form (which can be seen as a reasoning path), and the answer to the question can be obtained by executing the logic form labeled for the question in the Knowledge Base. This paper aims to retrieve similar cases for the current query, and then use the reasoning paths of these similar cases to generate the reasoning path for the current query to obtain the final answer. The general framework of the model in this paper is shown in the figure below:
The proposed model specifically includes three parts: Retrieve, Reuse, and Revise:
Retrieve:This paper uses the Dense Passage Retriever (DPR) approach to encode, retrieve, and train the text of the query. The desired retriever in this paper focuses more on the form of the question rather than the specific entities it contains. For example, for the question “Who is Xiao Ming’s brother?”, the paper prefers to retrieve “Who is Xiao Hong’s brother?” rather than “Who is Xiao Ming’s father?” Therefore, the retriever masks the entity parts when encoding the text.
Reuse:This paper uses a generative approach to generate the logic form for the current query. Specifically, the paper concatenates the retrieved query-logic form pairs and feeds them to a Seq2Seq model to generate the logic form of the current query in an autoregressive manner. Since the concatenated input may be particularly long, the paper uses the BigBird model to generate the logic form.
Revise:Due to uncertainty regarding whether certain generated relationship paths exist in the Knowledge Base, the paper further corrects the generated logic form. The paper first encodes the Knowledge Base using a pre-trained TransE model, and then replaces relationships that do not exist in the generated results with the most similar relationships currently in the Knowledge Base.
Knowledge Base Question Answering by Case-based Reasoning over Subgraphs, Arxiv 2022
This paper comes from the University of Massachusetts Amherst and Google and shares the same first author as the previous paper.
KBQA problems typically exist in a weakly supervised environment, where we can only obtain the question and answer but not the specific reasoning path used to obtain the answer from the Knowledge Base. This paper further addresses the weakly supervised KBQA problem based on the previous paper, mainly modifying the Reuse and Revise parts, replacing them with subgraph collection and reasoning on graphs, as shown in the framework below:
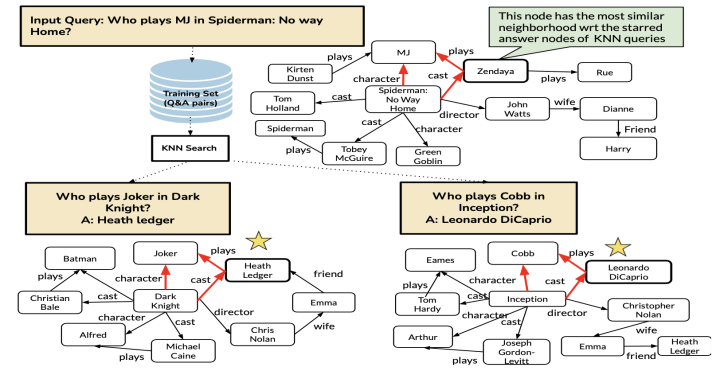 Subgraph Collection:In a weakly supervised scenario, where we can only obtain the question and answer from the retrieved cases, this paper extracts all entities from the question and answer and retrieves all paths linking the question entities and answer entities in the Knowledge Base to obtain a sub-graph, which can be seen as a less precise reasoning path. The paper then uses the relations of the subgraph obtained from the retrieved examples to extend the entities in the input query within the Knowledge Base, ultimately obtaining a subgraph of the input query in the KB.
Graph Reasoning:This paper uses GNN to encode the subgraphs, positing that within different subgraphs, the representations of answer entities should be closer to each other, and reinforces this assumption during training by pulling closer the distances between answer entities while pushing apart the distances between answer entities and other entities. During inference, the paper uses GNN to encode the subgraphs of each retrieved example and the input query, selecting the entity in the input query’s subgraph that is most similar to the answer entities of all retrieved subgraphs as the final answer to the question.
Another category of example-based methods is in-context learning, which involves feeding the model some question-answer pairs as prompts, allowing the model to “learn” to answer the current questions. The characteristic of this part of the work is that it places high demands on the model, generally only suitable for large-scale pre-trained language models, while requiring lower standards for examples, where the model refers more to the format of generating answers based on questions rather than acquiring additional knowledge from examples.
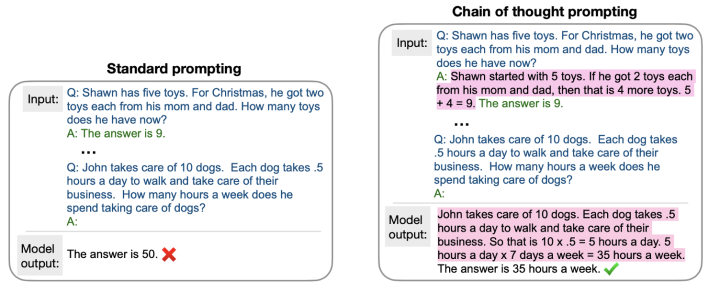
Chain of Thought Prompting Elicits Reasoning in Large Language Models, Arxiv 2022
This paper comes from Google. Based on standard prompts, this paper proposes adding explanations for the question-answer pairs for each example, aiming to allow the model to mimic the thought process of the provided examples and generate its own thought process for the current query, making the results of in-context learning more interpretable and effective. This paper refers to this approach of adding explanations to prompts as Chain of Thought Prompting, as illustrated in the figure below:
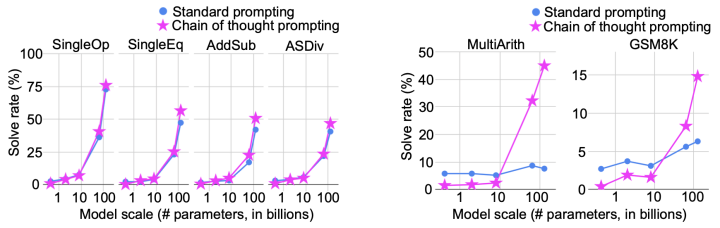
This paper conducted experiments on three types of tasks: Arithmetic, Symbolic, and Commonsense Reasoning, finding that compared to the original Standard Prompting method, Chain of Thought Prompting could better exploit the capabilities of large-scale language models. The experimental results for the arithmetic part are shown in the figure below:
It can be seen that when testing on simpler tasks on the left, both methods show exponential growth in performance as the model parameter scale increases, but when tested on more difficult datasets on the right, Chain of Thought retains greater utilization of the capabilities of large models compared to Standard Prompting.
The Unreliability of Explanations in Few-Shot In-Context Learning, Arxiv 2022
This paper comes from the University of Texas at Austin. This paper conducted experiments on the Chain of Thought method across three datasets in QA and NLI tasks, finding that in these datasets, Chain of Thought does not always yield gains, and its performance does not surpass that of Standard Prompting. The experimental results are shown in the figure below, where P-E and E-P denote placing the explanation before or after the answer in Chain of Thought.
The paper further analyzed the explanations generated by GPT3 and evaluated them from two perspectives: (1) Correctness, whether the generated explanations contradict certain conditions given in the context. (2) Consistency, whether the generated explanations can lead to the answers provided by the model. The results showed that the explanations generated by GPT3 exhibited good consistency but poor correctness, and for questions answered incorrectly, the model generally generated erroneous explanations.
Subgraph Collection:In a weakly supervised scenario, where we can only obtain the question and answer from the retrieved cases, this paper extracts all entities from the question and answer and retrieves all paths linking the question entities and answer entities in the Knowledge Base to obtain a sub-graph, which can be seen as a less precise reasoning path. The paper then uses the relations of the subgraph obtained from the retrieved examples to extend the entities in the input query within the Knowledge Base, ultimately obtaining a subgraph of the input query in the KB.
Graph Reasoning:This paper uses GNN to encode the subgraphs, positing that within different subgraphs, the representations of answer entities should be closer to each other, and reinforces this assumption during training by pulling closer the distances between answer entities while pushing apart the distances between answer entities and other entities. During inference, the paper uses GNN to encode the subgraphs of each retrieved example and the input query, selecting the entity in the input query’s subgraph that is most similar to the answer entities of all retrieved subgraphs as the final answer to the question.
Another category of example-based methods is in-context learning, which involves feeding the model some question-answer pairs as prompts, allowing the model to “learn” to answer the current questions. The characteristic of this part of the work is that it places high demands on the model, generally only suitable for large-scale pre-trained language models, while requiring lower standards for examples, where the model refers more to the format of generating answers based on questions rather than acquiring additional knowledge from examples.
Chain of Thought Prompting Elicits Reasoning in Large Language Models, Arxiv 2022
This paper comes from Google. Based on standard prompts, this paper proposes adding explanations for the question-answer pairs for each example, aiming to allow the model to mimic the thought process of the provided examples and generate its own thought process for the current query, making the results of in-context learning more interpretable and effective. This paper refers to this approach of adding explanations to prompts as Chain of Thought Prompting, as illustrated in the figure below:
This paper conducted experiments on three types of tasks: Arithmetic, Symbolic, and Commonsense Reasoning, finding that compared to the original Standard Prompting method, Chain of Thought Prompting could better exploit the capabilities of large-scale language models. The experimental results for the arithmetic part are shown in the figure below:
It can be seen that when testing on simpler tasks on the left, both methods show exponential growth in performance as the model parameter scale increases, but when tested on more difficult datasets on the right, Chain of Thought retains greater utilization of the capabilities of large models compared to Standard Prompting.
The Unreliability of Explanations in Few-Shot In-Context Learning, Arxiv 2022
This paper comes from the University of Texas at Austin. This paper conducted experiments on the Chain of Thought method across three datasets in QA and NLI tasks, finding that in these datasets, Chain of Thought does not always yield gains, and its performance does not surpass that of Standard Prompting. The experimental results are shown in the figure below, where P-E and E-P denote placing the explanation before or after the answer in Chain of Thought.
The paper further analyzed the explanations generated by GPT3 and evaluated them from two perspectives: (1) Correctness, whether the generated explanations contradict certain conditions given in the context. (2) Consistency, whether the generated explanations can lead to the answers provided by the model. The results showed that the explanations generated by GPT3 exhibited good consistency but poor correctness, and for questions answered incorrectly, the model generally generated erroneous explanations.
 Based on this finding, the paper finally proposed using rule-based methods to estimate the correctness of the explanations generated by the model, and then designed multiple calibration methods to calibrate the explanations estimated to be incorrect, thereby making the chain of thought effect of the model superior to that of the standard prompt, such as generating multiple explanations and answers and selecting the first estimated explanation as the correct answer as the final prediction.
Technical Exchange Group Invitation
Based on this finding, the paper finally proposed using rule-based methods to estimate the correctness of the explanations generated by the model, and then designed multiple calibration methods to calibrate the explanations estimated to be incorrect, thereby making the chain of thought effect of the model superior to that of the standard prompt, such as generating multiple explanations and answers and selecting the first estimated explanation as the correct answer as the final prediction.
Technical Exchange Group Invitation

△Long press to add the assistant
Scan the QR code to add the assistant on WeChat
Please note: Name-School/Company-Research Direction
(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue Systems)
to apply to join the Natural Language Processing/Pytorch and other technical exchange groups
About Us
MLNLP Community is a grassroots academic community jointly built by scholars in natural language processing from home and abroad. It has now developed into a well-known natural language processing community both domestically and internationally, including well-known brands such as Top Conference Exchange Group, AI Selection Exchange, MLNLP Talent Exchange and AI Academic Exchange, aiming to promote progress between the academic and industrial circles of machine learning and natural language processing and the vast number of enthusiasts.
The community can provide an open communication platform for practitioners’ further study, employment, and research. Everyone is welcome to follow and join us.