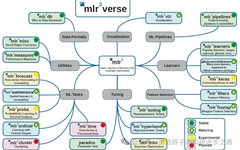
Overview of MLR3
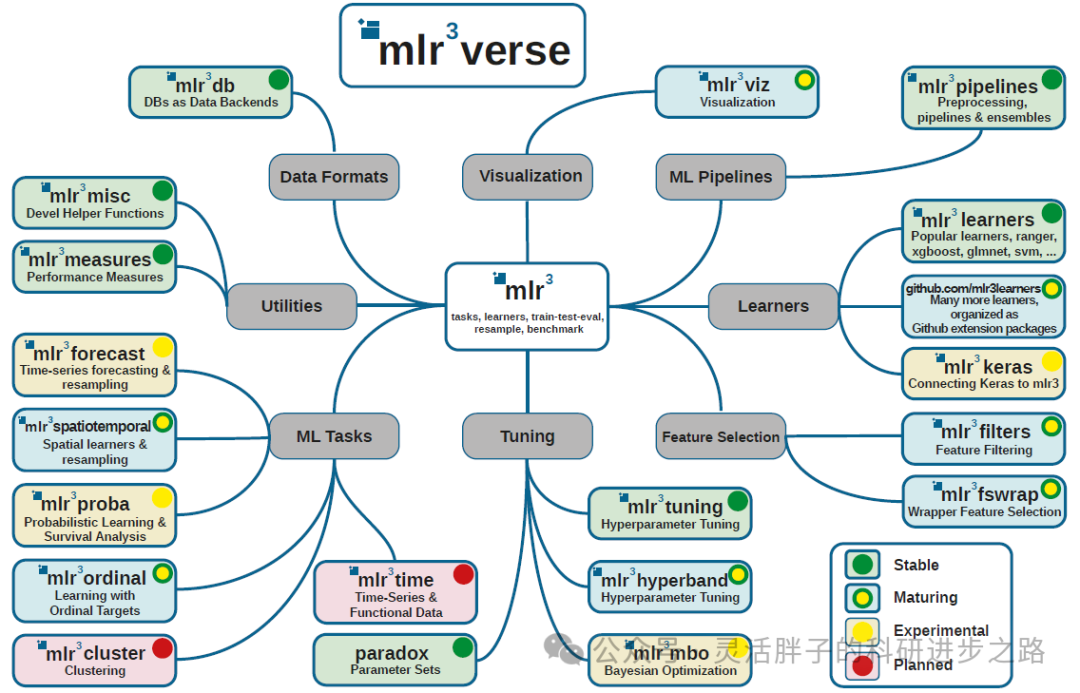
mlr3 is an object-oriented, extensible machine learning framework focused on regression, classification, survival analysis, and other machine learning tasks. It is the successor to mlr, providing efficient model building and comparison for machine learning.
Some key features of mlr3 include:
- Object-Oriented Design: Implements a clean object-oriented design using R6.
- Optimized Data Handling: Uses data.table for faster and more convenient data manipulation.
- Unified Containers and Results: Returns results in data.table format, simplifying the API.
- Defensive Programming and Type Safety: Checks user inputs with checkmate to avoid mechanisms in base R that may lose information.
- Reduced Dependency Packages: The number of dependencies for mlr3 has been significantly reduced, making it easier to maintain.
- Support for Numerous Algorithms: The mlr3verse currently includes 138 algorithms, covering commonly used binary classification and regression tasks in medicine, unsupervised clustering tasks, and survival analysis tasks. (https://mlr3extralearners.mlr-org.com/articles/learners/list_learners.html)
- MLR3 Graph Stream System: The graph stream system of mlr3 views the entire machine learning process as a graph (or stream), where each node represents an operation, such as feature engineering steps, learners, duplication, branching, merging, etc. Data flows along these nodes, forming a complete machine learning workflow.
Course Objectives
-
Compared to learning individual algorithms through R packages, an application framework allows users to quickly grasp the usage of various algorithms, facilitating benchmarking and model selection.
-
Learning based on the framework helps expand downstream issues, such as the model interpretability solutions of the mlr3 framework seamlessly connecting with the subsequent DLAEX framework.

- Currently, most courses are short-term training. Moreover, writing a machine learning article requires a lot of other foundational statistics and charting skills, and there is currently no comprehensive course that addresses this issue. The goal of this course is not only to provide a solid foundation for machine learning but also to bridge the research on model interpretability, allowing students to seamlessly connect with advanced model interpretability tools like DALEX in their subsequent studies.
Instructors
1. Flexible Fatty
PhD in Oncology from a Double First-Class University, currently employed at one of the top five cancer centers in China. Research focus includes real-world studies, bioinformatics analysis, and artificial intelligence research. Has published over 10 SCI papers as the first or co-first author, with a cumulative IF of over 50. Currently collaborates with several domestic universities and hospitals. Along with a translation team, has translated the entire mlr3book into Chinese and published it on a public account.
2. Rio
Medical doctor and clinician. Has published over 10 articles in both Chinese and English. An enthusiast of R and Python. Participated in translating approximately 50,000 words of the mlr3book.
Course Directory and Schedule
Part One: Basics of R and Tidyverse
- 1. The Necessity of Learning R and Preparations (Environment Setup and Package Installation)
- 2. General Requirements for Tidy Data and Data Wrangling (tidydata)
- 3. Basics of R (1) – One-Dimensional Variables
- 4. Basics of R (2) – Two-Dimensional and High-Dimensional Variables
- 5. General Usage of Functions and Solutions for Errors
- 6. Initial Exploration of the Tidyverse Framework
Part Two: Traditional Clinical Basic Statistical Chart Making
- 1. Quick Production of Baseline Tables Between Groups and Statistical Considerations
- 2. Batch Implementation of Univariate Analysis and Statistical Considerations
- 3. Summary of Methods for Choosing Cutoff Values for Continuous Variables (including survival data)
- 4. Application and Quick Implementation of Directed Acyclic Graphs
- 5. Batch Implementation of Multivariate Analysis and Sensitivity Analysis of Adjusted Covariates
- 6. Methods for Identifying Key Factors (P-value method, machine learning methods, effect size change method, etc.)
- 7. Organization of Survival Data and Common Survival Analysis Methods (KM, COX, Survival Curve and Cumulative Risk Curve Drawing)
Part Three: Overview of MLR3 Basics
- 1. What Can MLR3 Help Us With?
- 2. Machine Learning in R
- 3. Introduction to MLR3 and DALEX Packages
- 4. Overview of DALEX Package and Model-Independent Interpretability Solutions
- 5. Installing and Loading MLR3 and DALEX, DALEXtra Packages
- 6. Basic Knowledge of MLR3 – sugar Function
- 7. Basic Knowledge of MLR3 – Graph
- 8. Principles for Solving Errors
Part Four: Initial Exploration of MLR3 Overall Process and Detailed Tasks and Learners
- 1. Tasks (Task) – Classification and Regression Tasks: Internal Test Tasks, Utilizing External Data Component Tasks, Task Attributes and Methods
- 2. Learners (learners) – Classification Attributes and Methods of Learners
- 3. Preliminary Introduction to Evaluation
- 4. Introduction to Common Learners – Logistic Regression; Linear Regression; Decision Trees; Random Forests; Support Vector Machines; XGBoost; K-Nearest Neighbors; K-Means Clustering; Neural Networks; Survival Analysis COX Regression; Deep Learning Survival Analysis (deepsurv); Deep Learning Survival Analysis (deephit); Naive Bayes
Part Five: Evaluation, Resampling, and Benchmark Testing
- 1. Several Strategies for Resampling: Leave-One-Out; Cross-Validation; Bootstrap Sampling and Subsampling Cross-Validation
- 2. Attributes and Usage of Resampling Objects
- 3. Benchmark Testing
- 4. Detailed Evaluation – Common Attributes and Methods
- 5. Nested Resampling
Part Six: Hyperparameter Tuning
- 1. The Importance of Hyperparameter Tuning in Machine Learning
- 2. Model Tuning: Learners and Search Space; Stopping Criteria; Instantiating Tuning Objects Using ti() Function; Black Box Optimization Problems and Their Algorithms
- 3. Tuning Sugar Functions – tune(), auto_tuner()
- 4. Expanding Search Space
- 5. Simple Application of data.table Package
Part Seven: Feature Selection
- 1. Overview of Feature Selection
- 2. Filter Method: Calculating Filter Scores, Feature Importance, and Selected Features After Filtering
- 3. Embedded Method: Feature Selection After Embedding
- 4. Wrapper Method: Simple Forward Selection, Introduction to FSelectInstance Class, Different Feature Selection Algorithms, Feature Selection Incorporating Multiple Performance Metrics Optimization, AutoSelector for Automatic Feature Selection (allowing feature selection to also incorporate resampling)
Part Eight: Sequential Pipeline
- 1. Introduction to Graph Stream System
- 2. Introduction to Sequential Graph Stream Methods
- 3. Building and Using Graph Learners
- 4. Hyperparameter Tuning for Graph Learners
Part Nine: Non-Sequential Pipeline
- 1. Introduction to Non-Sequential Graph Stream Methods
- 2. Building New Learners Using Bagging
- 3. Building New Learners Using Stacking
- 4. Hyperparameter Tuning and Path Selection in Non-Sequential Graph Stream System
Part Ten: Data Preprocessing
- 1. Data Cleaning
- 2. Creating Dummy Variables
- 3. Handling Missing Values
- 4. Maintaining Structural Stability Using pl(“robustify”)
- 5. Feature Transformation
Part Eleven: Model Interpretability
- 1. Introduction to Non-Model-Dependent Interpretability DALEX Framework
- 2. Introduction to Shapley Value Principles and Their Application and Visualization
- 3. Introduction to LIME Principles and Their Application and Visualization
- 4. Introduction to Variable Importance Methodology Based on Evaluation Metrics
- 5. Preliminary Introduction to Other Methodologies
Part Twelve: Overall Process of Building and Validating Binary Classification Models Based on MLR3
- 1. Introduction to the Overall Process of Binary Classification Prediction Models
- 2. Construction of Binary Classification Predictions
- 3. External Validation of Binary Classification Prediction Models
- 4. DCA Curves, Calibration Curves, and Probability Calibration of Binary Classification Prediction Models
Part Thirteen: Overall Process of Building and Validating Survival Models Based on MLR3
- 1. Introduction to the Overall Process of Survival Prediction Models
- 2. Construction of Survival Predictions
- 3. External Validation of Survival Prediction Models
- 4. DCA Curves and Calibration Curves of Survival Prediction Models
Part Fourteen: Establishment and Evaluation of Unsupervised Clustering Systems Based on MLR3
- 1. Introduction to the Overall Process of Unsupervised Clustering Prediction Models
- 2. Construction of Unsupervised Clustering Models
- 3. Internal Validation of Unsupervised Clustering Models – Clinical and Basic Correlation
- 4. External Validation of Unsupervised Clustering Models – Optimal Model Approach
Teaching Format and Schedule
Teaching Format: Remote Online Live Teaching.
Teaching Schedule: Starts in June 2024, with a total of no less than 45 hours of classes, utilizing 4-6 hours of teaching during weekends, expected to complete all course content in 8-10 weeks.
Q&A Support: A dedicated WeChat group for the course will be established for free Q&A within one year of course content.
Video Replay: Unlimited free replays within one year.
Course Price and After-Sales Guarantee
Course Price: 4800 RMB
Please contact the teaching assistant in advance for public transfer procedures.
Organizing Company: Tianqi Zhuli (Tianjin) Productivity Promotion Co., Ltd.
After-Sales Guarantee: Unconditional full refund within two weeks after the official start of the course.
Reward Policy: Tuition can be refunded if students publish articles with an IF of 10+ using the learned content (specific requirements and processes need to be consulted with the teaching assistant).
Enrollment Consultation
Contact my teaching assistant for consultation.
