
This content is exclusive to Data Pie. Data Pie is the official WeChat public account of the Tsinghua University Big Data Industry Alliance, which regularly publishes information on Tsinghua’s big data lecture series and shares lecture transcripts. Feel free to share.
If other institutions or media wish to reprint, please contact [email protected] to apply for authorization.
In the past year, the “RONG” series forums have successfully held multiple sessions. The term “RONG” has become a link connecting various departments within Tsinghua University and external resources. Now, the new round of ideological collision brought by “RONG 2.0” has begun. The RONG series forums aim to promote mutual understanding and communication among different departments and disciplines within and outside the university around big data research topics, to enhance the collaboration of research forces and improve the utilization rate of research resources, allowing industrial resources to connect with research resources, understand the current state of industrial applications, respond to industrial challenges, and ultimately achieve the goal of promoting Tsinghua’s big data research to “reach the sky and stand firm”.
On November 26, 2015, RONG 2.0 welcomed the first forum of this series – the special session on “Image Processing and Big Data Technology”. The forum was co-hosted by the School of Data Science and the Remote Sensing Big Data Research Center. More than 150 researchers from related fields inside and outside the university participated in the forum.
Below is the key content of the event; click “Read Original” to watch the on-site video.

This lecture was given by Professor Zhang Changshui from the Department of Automation at Tsinghua University on November 26, 2015, at the RONG v2.0 – Image Processing and Big Data Technology Forum, titled “Machine Learning and Image Recognition“.

Zhang Changshui: My topic is “Machine Learning and Image Recognition”. I mainly work on machine learning. I wonder if the audience is interested in machine learning.

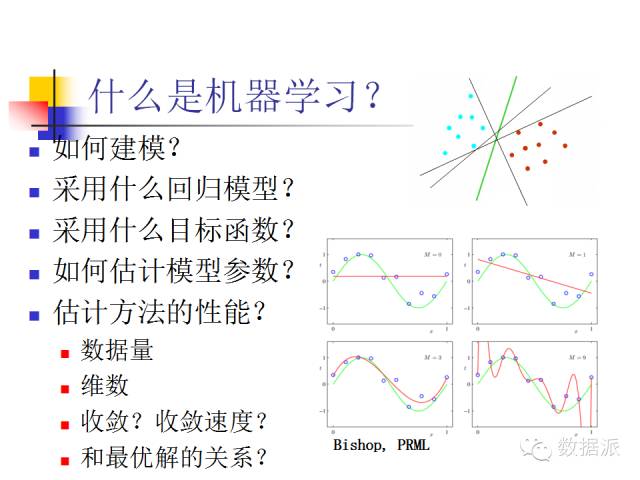
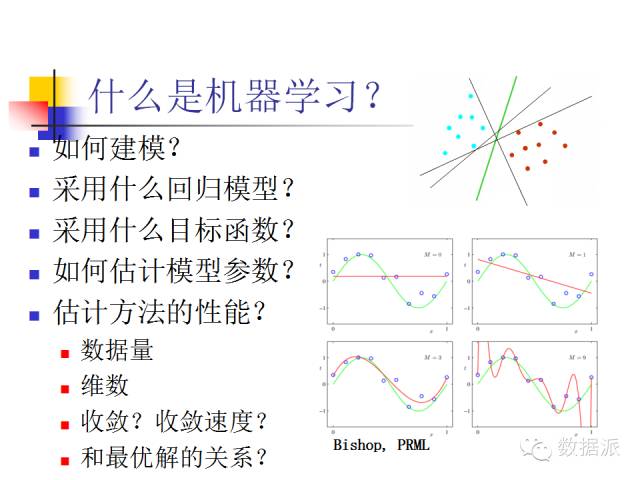
What is machine learning? Here are two examples: one is classification and the other is regression. Classification is a fundamental problem. For example, in the right image, when we know there are two classes of objects represented by different colors, what kind of algorithm can we use to separate these two classes of objects in vector space, and do it better?
What does machine learning care about? Machine learning cares about how to build models. Taking regression problems as an example, what kind of regression model should we use, what should our objective function look like, how do we estimate the parameters of this model, and what is the performance of the estimation method we use? The performance of the estimation may relate to the amount of data, the dimensions involved, how fast it converges, and how it relates to the optimal solution. Just now, Professor Xu Wei talked about the difficulties we encounter in actual modeling, including whether fruit fly gene data labeled by different people can be shared. Similar issues have relevant research in the field of machine learning; we consider such tasks as knowledge transfer, model transfer, or parameter transfer. We treat it as a machine learning problem, where there will be data sharing, model sharing, and parameter sharing. When our sharing methods differ, the modeling will also differ, the optimization methods will differ, and the performance will also differ. Therefore, machine learning is a particularly broad and fundamental research direction with a wide range of application fields.
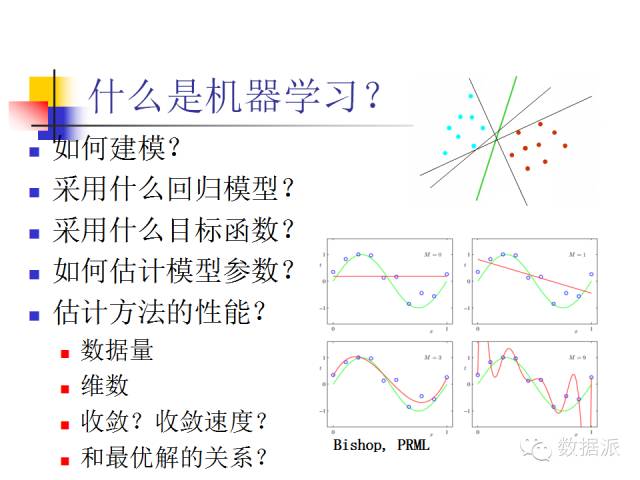
Generally speaking, machine learning is a fundamental area of research, and many methods in pattern recognition and data mining come from machine learning. Pattern recognition and data mining can be applied in language, text, image, and video recognition. The applications listed here are common ones, but they also include applications in other disciplines such as biology, medicine, and materials science. Machine learning is a fundamental research tool, or rather, theory and method. Therefore, in the era of big data, machine learning is one of the core methods. Such a method can find its place in any major application field.
Since today’s topic is about image graphics, let’s talk about image recognition. Research on object recognition in the visual field has a history of several decades, but until a few years ago, there were not many influential image recognition products, one being OCR, another being fingerprint recognition, and the last being face detection.


Face detection dates back to 2001, while OCR and fingerprint recognition were developed in the 1990s. Broader application research has been ongoing since the 1970s, with a focus on face detection and recognition, number and vehicle recognition.

Later, from 2001 and 2002, more extensive research on image recognition began. Researchers were thinking if there could be a unified method to recognize various objects. For instance, we expected to recognize tens of thousands of object categories. At that time, it was believed that machine learning had developed for many years and had some good methods. Could these methods be used to achieve greater advancements in image recognition? Subsequently, some individuals worked continuously for ten years on target recognition and image recognition.

The real breakthrough came with the introduction of deep learning in 2012. Prior to that, in an ImageNet object recognition competition, algorithms were allowed to provide five candidate categories for each image. As long as one of these top five categories contained the true category of the object, the image was considered recognized correctly. Before 2012, the recognition rate was gradually increasing, but suddenly that year there was a significant leap, thanks to Hilton’s team using deep learning.
However, this does not mean the problem of image recognition has been solved. In fact, the image recognition rate is still low, and many issues remain unresolved, with considerable challenges still present. Nowadays, due to the effectiveness of deep learning, many are working on image recognition, particularly in the industrial sector, which is very lively, but there are numerous technical issues involved.
I am in the Department of Automation, and my laboratory is called “Big Eye”. This is the homepage of my laboratory; you are welcome to visit and provide us with suggestions. For over a decade, we have been working on various research questions and directions in machine learning. Since machine learning must consider some applications, we have conducted some applied research, such as in the field of images.

We worked on a practical topic: traffic sign recognition. We did this under the backdrop of big data and deep learning. The National Natural Science Foundation has a project on autonomous vehicles, which require recognizing traffic signs in scenes. We collected a lot of data to achieve a single image recognition rate of 99.5%. If we combine previous and subsequent frames, the accuracy will be even higher. We tested it on autonomous vehicles during competitions, and it did not misrecognize.
 This is the situation on-site with the autonomous vehicle, where the left and right signs are framed and identified.
This is the situation on-site with the autonomous vehicle, where the left and right signs are framed and identified.

There are still many things to recognize in traffic. A car driving on the road needs to know which route to take. We also conducted recognition of road signs, achieving similar performance and results.
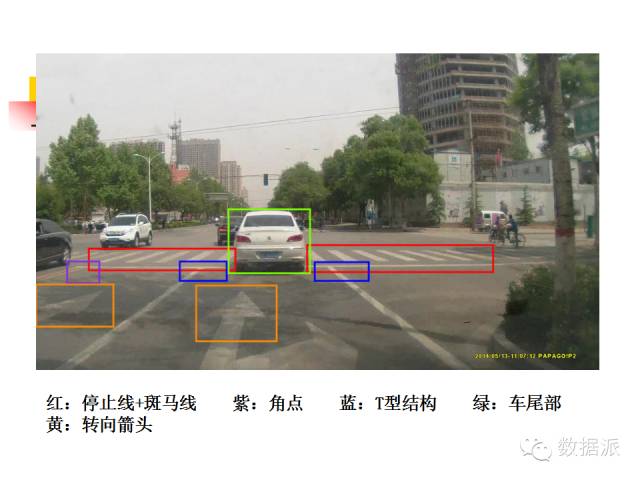
We recognize this image, and the recognition results are below. With such analysis, the vehicle knows which way to go and whether it violates traffic rules.

We also worked on hand recognition. In this image, there is an open hand. We developed an app based on this core technology, which has three versions: one for the iPad called iFinger, and another for the iPhone called iFinger For Phone. It’s a very simple game where you are given a hand gesture on the left, and your video is displayed in the center. Once you do it correctly, you pass that level. Who judges whether it’s correct? It’s the program. This program constantly detects and recognizes the hand gestures. There are four or five different gestures, which are quite challenging to implement. We have tried it, and only one person, whom we call the “Super Finger King”, can perform many complex actions; others find it difficult to do.

One of the works our lab is currently doing is called Image Captions. It describes an image with words. For example, the description for the second image is: “There is a train on the track next to the train station.” This work not only involves recognizing objects but also considers the relationships between them, and we aim to describe these relationships through text. During training, we provide images and their corresponding descriptions.

Look at the result we generated; the text description is: “A brown cow is standing on the grass.” When the algorithm provides this description, it knows which words will likely focus on what areas. Just like how humans observe an image, there is attention, and the generation of words corresponds to changes in attention.

When we have many images, the algorithm begins to learn. What does it learn? We extract some nouns, like “black cat”; the corresponding image block looks like this, indicating it has learned some concepts. For example, a verb, “Filled with”, is represented by this image.

Describing verbs, “flying”, and others: “laying” and labeling, “red”. It seems it has learned something. From this result, it seems to be an interesting endeavor, moving a step forward from the current work.
Since the theme of this conference is big data, I will mention a few examples that are more related to big data. These examples are not from our work but are current works in the field of computer vision.

One is super-resolution, which aims to do the following: given a very small image, for various reasons, we want to enlarge it. When you stretch it, it appears pixelated. People find it unattractive, so we hope to fill in the details. This is the result of using different methods to fill in; you will find one is not so good, and another is a bit better. Doing this can provide a new perspective under the background of big data.
The idea is as follows. In some specific situations, like Tiananmen Square or Notre Dame, many people take photos. Once we have many images of Tiananmen, we can use 3D reconstruction algorithms to build the entire 3D structure of Tiananmen and then apply textures. Suppose one day you take a photo at Tiananmen Square, and your camera is poor, resulting in a blurry image. You upload it online, and the algorithm can help you correspond this image with the reconstructed model of Tiananmen, filling in the unclear details.
This year at CVPR 2015, there was such work.

Reconstructing the world in six days. The basic idea is similar. With a very large image database, many scenes can be constructed. The article states they have built the Louvre, Statue of Liberty, Arc de Triomphe, Colosseum, etc. Why six days? Because the computation took about 5.7 days.
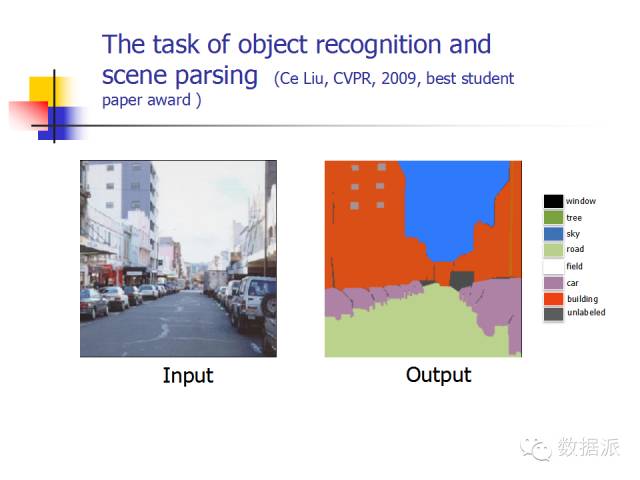
In addition to target recognition, another issue in visual research is image parsing. Given an image, the algorithm provides the meaning of each part of the image, such as “this is the sky, this is a car, this is the road”; this is very helpful for our understanding.
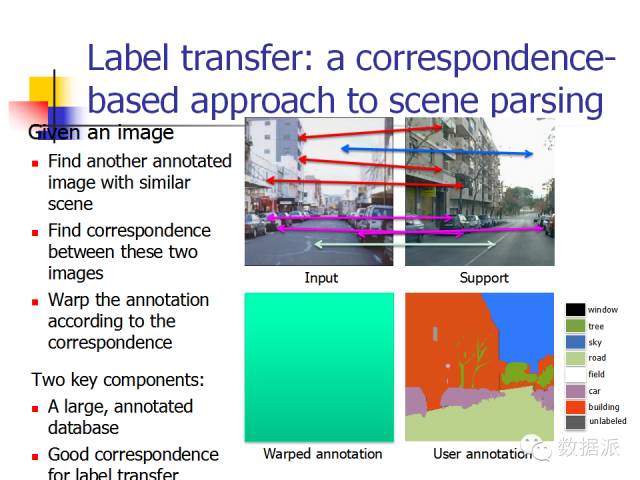

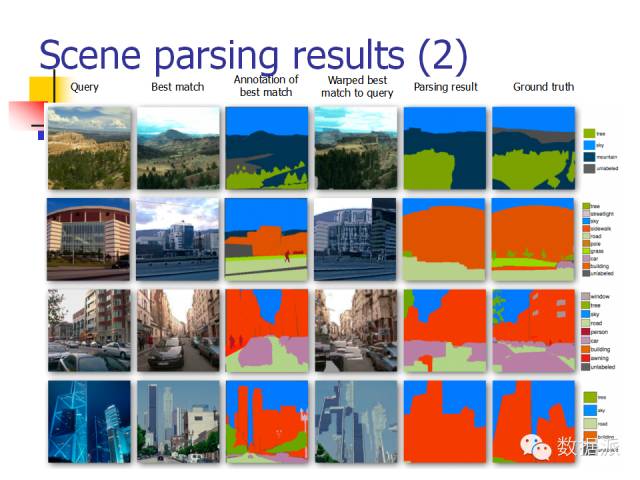
How to accomplish this task? Historically, there have been various research methods. I will introduce this work, which was awarded Best Student Paper at CVPR 2009. This work also follows the big data approach. The authors stated that we are now in the internet era, with excellent search engines like Baidu, Google, and Bing, and in addition to these, we have a large number of people on the internet who can label many images, telling us which is a car and which is a building. After obtaining an image, we first search through a large database to retrieve similar images and use a visual method to match them, thus identifying what is a car and what is a building.

Another example is a CVPR 2015 paper. The authors aimed to analyze an image database. For example, we collected images related to tomatoes. Can we structure them, for instance, sorting them from unripe to ripe, from fresh to rotten? This is very helpful for our understanding of these images.

Finally, let me take two minutes to talk about machine learning and big data. Big data presents many challenges for machine learning, including high noise levels and large data volumes. In particular, large-scale data poses even greater challenges for machine learning. The so-called large scale is reflected in three aspects of big data in machine learning: large data volume, high dimensionality, and a large parameter space during solution. Traditional methods of machine learning are not applicable to this.
In the past eight to ten years, machine learning researchers have been thinking about how to make algorithms very fast. There are many excellent works; I will not introduce them one by one.

Thank you all!
整理:刘博
校对:付睿
二校:闵黎
编辑:yimi
