↑ ClickBlue Text Follow the Jishi Platform Author丨ChaucerGSource丨Jizhi ShutongEditor丨Jishi Platform
Author丨ChaucerGSource丨Jizhi ShutongEditor丨Jishi Platform
Jishi Introduction
This article introduces Sequencer, a brand new and competitive architecture that can replace ViT, providing a fresh perspective for classification problems. Experiments show that Sequencer2D-L achieves 84.6% top-1 accuracy on ImageNet-1K with only 54M parameters. Moreover, the authors demonstrated its good transferability and robustness in dual-resolution bands. >> Join the Jishi CV technology group and stay at the forefront of computer vision

Paper link: https://arxiv.org/abs/2205.01972
In recent computer vision research, the emergence of
ViThas rapidly changed various architectural design works:ViTachieves state-of-the-art image classification performance usingSelf-Attentionfrom natural language processing, whileMLP-Mixerachieves competitive results using simple multilayer perceptrons. In contrast, some studies have shown that carefully designed convolutional neural networks (CNNs) can achieve performance comparable toViTwithout relying on these new ideas. In this context, there is growing interest in what constitutes suitableinductive biasfor computer vision.Here, the authors propose
Sequencer, a brand new and competitive architecture that can replaceViT, providing a fresh perspective for classification problems. UnlikeViT,Sequencermodels long-range dependencies usingLSTM(instead ofSelf-Attention).The authors also propose a 2D
Sequencermodule, in which a singleLSTMis decomposed intoverticalandhorizontalLSTMto improve performance.Despite its simple structure, experiments show that the performance of
Sequenceris impressive:Sequencer2D-Lachieves 84.6% top-1 accuracy on ImageNet-1K with only 54M parameters. Moreover, the authors demonstrated its good transferability and robustness in dual-resolution bands.
1 Background
The success of the Vision Transformer is believed to be due to the ability of Self-Attention to model long-range dependencies. However, it is unclear how crucial Self-Attention is for the effectiveness of Transformers in visual tasks. In fact, the MLP-Mixer, which is based solely on multilayer perceptrons (MLPs), has been proposed as an attractive alternative to ViTs.
Additionally, some studies show that carefully designed CNNs still have enough competitiveness in computer vision. Therefore, determining which architectural designs have inherent effectiveness for computer vision tasks is a major research hotspot. This paper provides a new perspective on this issue by proposing a novel and competitive alternative.
This paper introduces the Sequencer architecture, which uses LSTM (instead of Self-Attention) for sequence modeling. The macro architectural design of Sequencer follows ViTs, iteratively applying Token Mixing and Channel Mixing, but replaces Self-Attention with LSTM-based Self-Attention layers. Specifically, Sequencer uses BiLSTM as a building block. A simple BiLSTM exhibits a certain level of performance, while Sequencer can further enhance performance by using ideas similar to Vision Permutator (ViP). The key idea of ViP is to process the vertical and horizontal axes in parallel.
The authors also introduce 2 BiLSTMs for parallel processing in the up/down and left/right directions. This modification improves the efficiency and accuracy of Sequencer, as this structure reduces the length of the sequence and produces a spatially meaningful receptive field.
When pre-trained on the ImageNet-1K dataset, the performance of the new Sequencer architecture surpasses that of advanced architectures like Swin and ConvNeXt of similar scale. It also outperforms other non-attention and non-CNN architectures, such as MLP-Mixer and GFNet, making Sequencer an attractive new alternative to Self-Attention in visual tasks.
Notably, Sequencer also exhibits good domain robustness and scale stability, strongly preventing accuracy degradation even when the input resolution is doubled during inference. Moreover, the Sequencer fine-tuned on high-resolution data can achieve higher accuracy than Swin-B. In terms of peak memory, Sequencer is often more economical than ViTs and CNNs in certain situations. Although Sequencer requires more FLOPs than other models due to recursion, the higher resolution improves the relative efficiency of peak memory, enhancing the accuracy/cost trade-off in high-resolution environments. Therefore, Sequencer also possesses attractive characteristics as a practical image recognition model.
2 A New Paradigm
2.1 Principles of LSTM
LSTM is a special type of recurrent neural network (RNN) used for modeling long-term dependencies in sequences. A plain LSTM has an input gate that controls the storage of inputs, a forget gate that controls the forgetting of the previous cell state, and an output gate that controls the output of the current cell state. The formula for a standard LSTM is as follows:
Where σ is the logistic sigmoid function, and is the Hadamard product.
BiLSTM is beneficial for sequences with expected interdependencies. A BiLSTM consists of 2 standard LSTMs. Let be the input, and be the reverse permutation. and are the outputs obtained by processing and with the respective LSTMs. Let be the output rearranged in the original order, the output of BiLSTM is as follows:
.
Assuming and have the same hidden dimension D, which is a hyperparameter of BiLSTM. Therefore, the dimension of vector is two-dimensional.
2.2 Sequencer Architecture
1. Overview of the Architecture
This paper replaces the Self-Attention layer with LSTM: a new architecture is proposed to save memory and parameters while having the capability to learn long-range modeling.
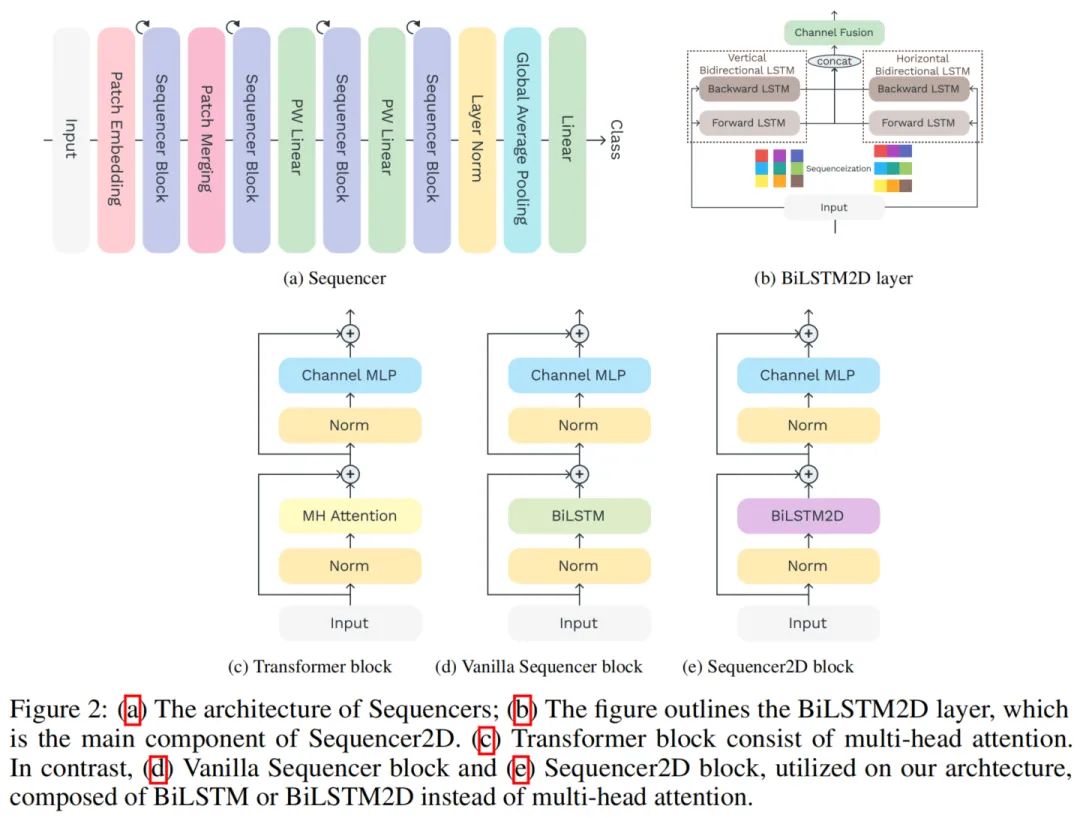
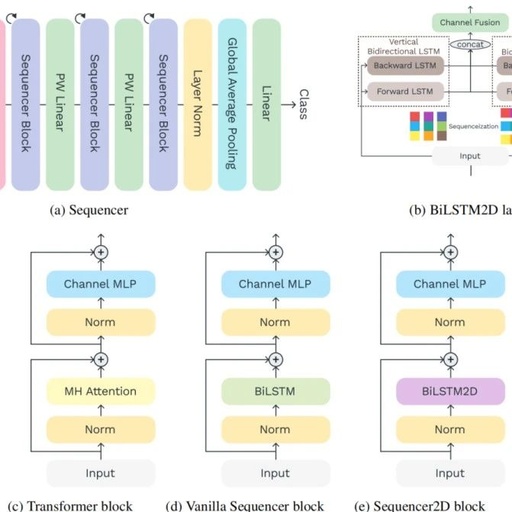
Figure 2a shows the overall structure of the Sequencer architecture. The Sequencer architecture takes non-overlapping patches as input and projects them onto feature maps. The Sequencer Block is the core component of Sequencer, consisting of the following subcomponents:
-
BiLSTM layers can economically and globally mix spatial information
-
MLP for Channel Mixing
When using a standard BiLSTM layer, the Sequencer Block is referred to as the Vanilla Sequencer block; when using BiLSTM2D layers as the Sequencer Block, it is referred to as the Sequencer2D block. The output of the last block is sent to the linear classifier through a global average pooling layer.
2. BiLSTM2D Layer
The authors propose the BiLSTM2D layer as an effective technique for mixing 2D spatial information. It consists of 2 standard BiLSTMs, one vertical BiLSTM and one horizontal BiLSTM.
For input
is treated as a set of sequences, where is the number of tokens in the vertical direction, W is the number of sequences in the horizontal direction, and is the channel dimension. All sequences are input to the vertical BiLSTM, sharing weights and hidden dimension D:
In a similar manner, is treated as a set of sequences, all of which are input to the horizontal BiLSTM, sharing weights and hidden dimension D:
Then, is merged into , while is merged into . Finally, it is sent to the FC layer. These processes are formulated as follows:
Pseudocode is as follows:

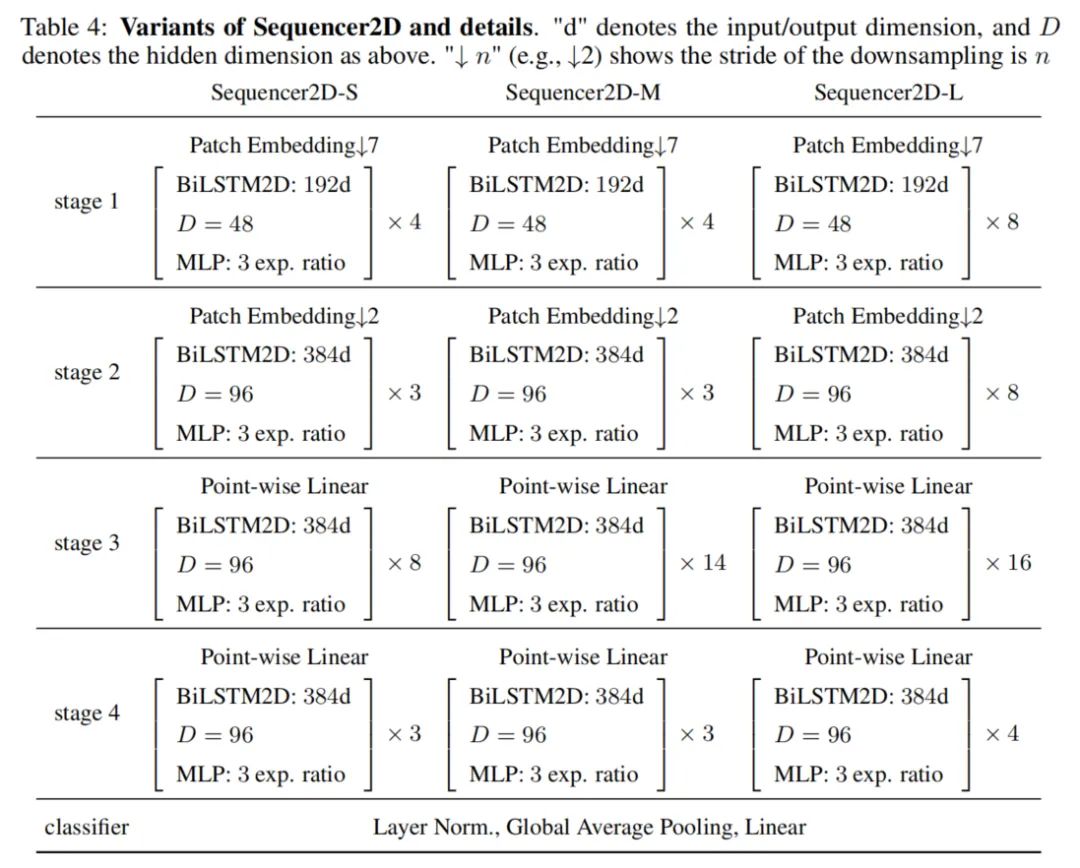
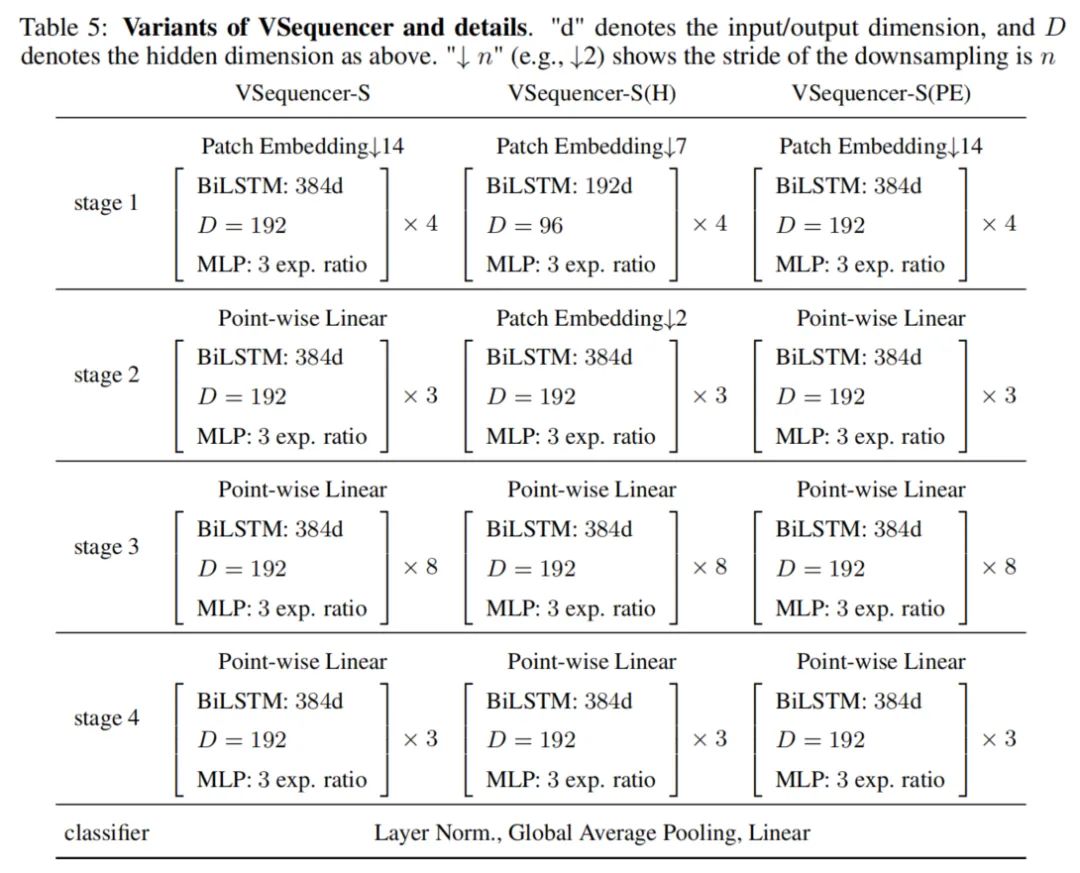
3. Architectural Variants
To compare models of different depths consisting of Sequencer 2D, this paper prepares 3 models of different depths: 18, 24, and 36. The models are named Sequencer2D-S, Sequencer2D-M, and Sequencer2D-L, respectively. The hidden dimension is set to D=C/4.
3 Experiments
3.1 ImageNet-1K
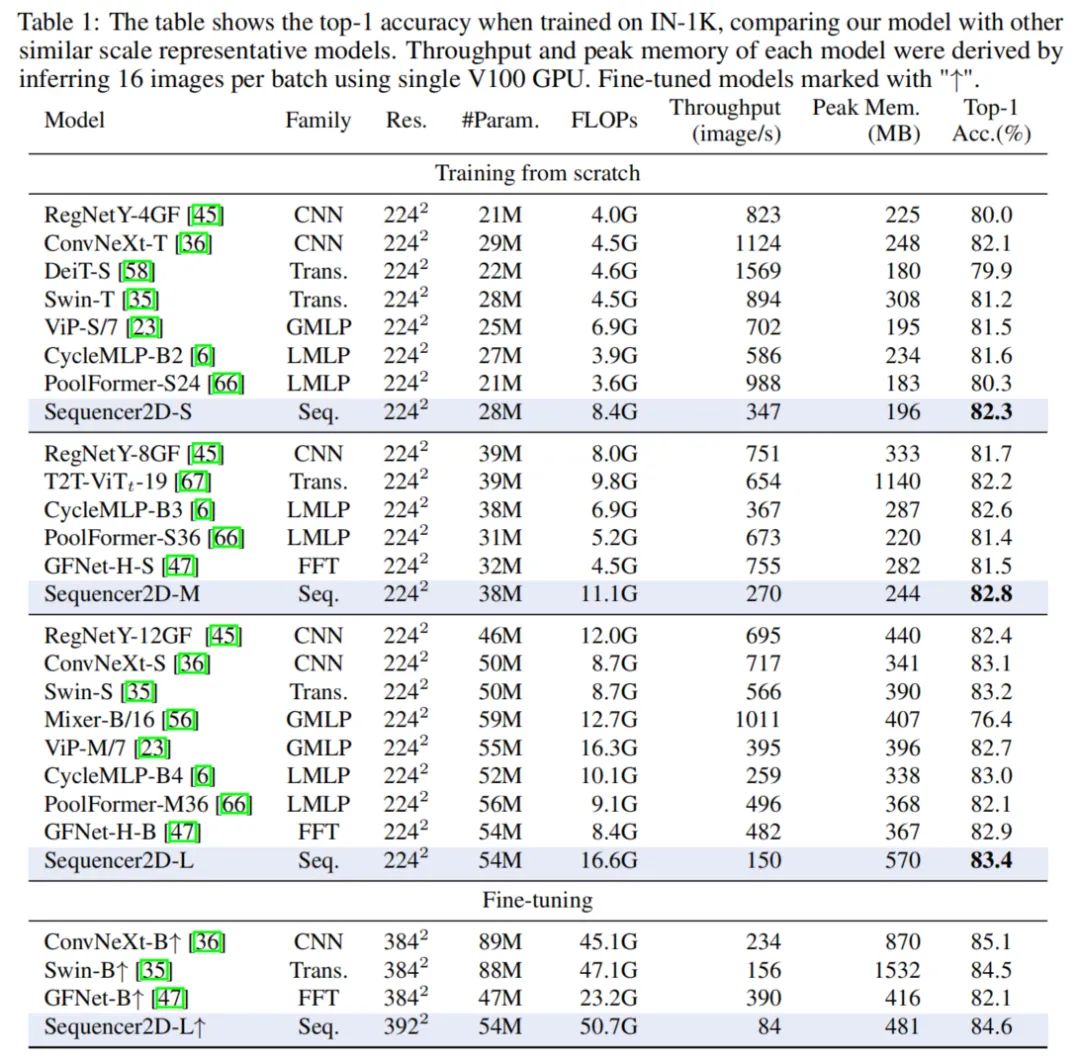
3.2 Transfer Learning
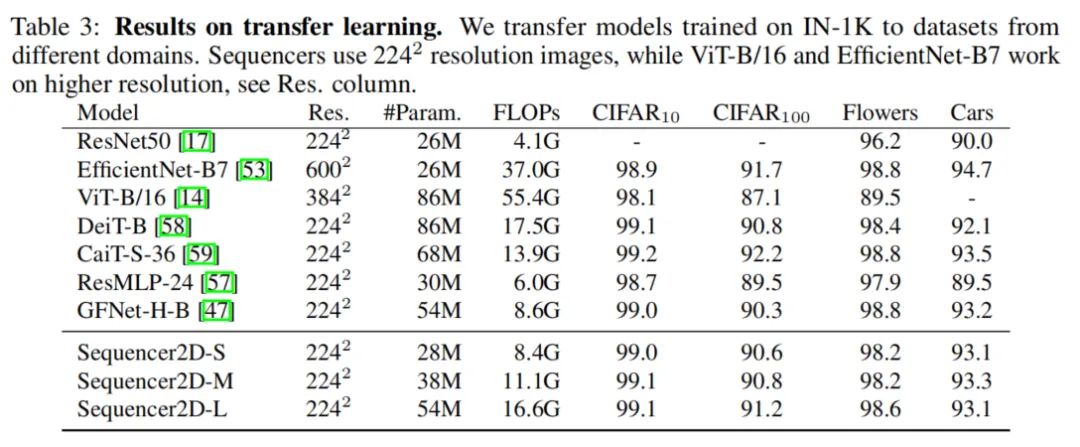
3.3 Robustness Experiments

3.4 Visualization Analysis
Generally, CNNs have localized, layer-wise expanding receptive fields, while ViTs without moving windows capture global dependencies. In contrast, it is unclear how information is processed in the author’s Sequencer. Therefore, the authors calculated the ERF of ResNet-50, DeiT-S, and Sequencer2D-S, as shown in Figure 5.

The ERFs of Sequencer2D-S form a cross shape across all layers. This trend distinguishes it from well-known models like DeiT-S and ResNet-50. More notably, in shallow layers, the ERF of Sequencer2D-S is wider than that of ResNet-50, though not as wide as DeiT. This observation confirms that the LSTM in Sequencer can model long-range dependencies as expected, and Sequencer can identify sufficiently long vertical or horizontal areas. Therefore, it can be considered that the way Sequencer recognizes images is very different from CNNs or ViTs.
References
[1]. Sequencer: Deep LSTM for Image Classification
Reply “CVPR 2022” in the official account to get the paper collection download package~
△ Click the card to follow the Jishi platform for the latest CV insightsJishi InsightsDataset resource summary: 90+ deep learning open-source datasets organized, including object detection, industrial defects, image segmentation, and morePractical tutorials: Pytorch – Elastic Training Simplified Implementation (with source code) | Collection of commonly used PyTorch code snippetsCVPR 2022: Latest 132 papers from CVPR’22 organized by direction|Latest 106 papers from CVPR’22 organized by direction|A comprehensive overview of the latest 20 Oral papers from CVPR 2022
# CV Technology Community Invitation#
 △ Long press to add Jishi AssistantAdd Jishi Assistant WeChat(ID : cvmart4)
△ Long press to add Jishi AssistantAdd Jishi Assistant WeChat(ID : cvmart4)
Note: Name – School/Company – Research Direction – City (e.g., Xiaoji – Peking University – Object Detection – Shenzhen)
to apply to join JishiObject Detection/Image Segmentation/Industrial Detection/Face/Medical Imaging/3D/SLAM/Autonomous Driving/Super Resolution/Pose Estimation/ReID/GAN/Image Enhancement/OCR/Video Understandingand other technical groups
Monthly expert live sharing, real project needs docking, job referrals, algorithm competitions, insights summary, and interaction with 10,000+ visual developers from top universities and companies such as HKUST, Peking University, Tsinghua University, CAS, CMU, Tencent, Baidu~
If you find it useful, please give it a look~