Click the blue text above to follow us.
When using OpenAI’s GPT series models, we might find that for some simple questions, such as factual questions in Chinese, the AI tends to fabricate answers. And when asked about recent news events, the AI will directly state that it does not know the situation for the next 21 years.
To address this issue, ChatGPT launched a plugin module after releasing the latest GPT-4 model, which allows it to connect to external third-party applications via plugins. However, even with third-party applications, we cannot guarantee that the required information is provided by others. Additionally, not all information and questions are suitable for public disclosure; some information may be for internal company use only.
Today we will explore how to leverage OpenAI’s large language model capabilities while operating solely on specified data to meet our needs.
1.2 Limitations of Large Language Models
To test ChatGPT’s common sense level, we asked a commonly known question: “Who was Lu Xun’s mentor when he studied medicine in Japan?” However, ChatGPT’s answers varied between Jin Island Junzan and Hashimoto Hideo, which are not the well-known Mr. Fujino.
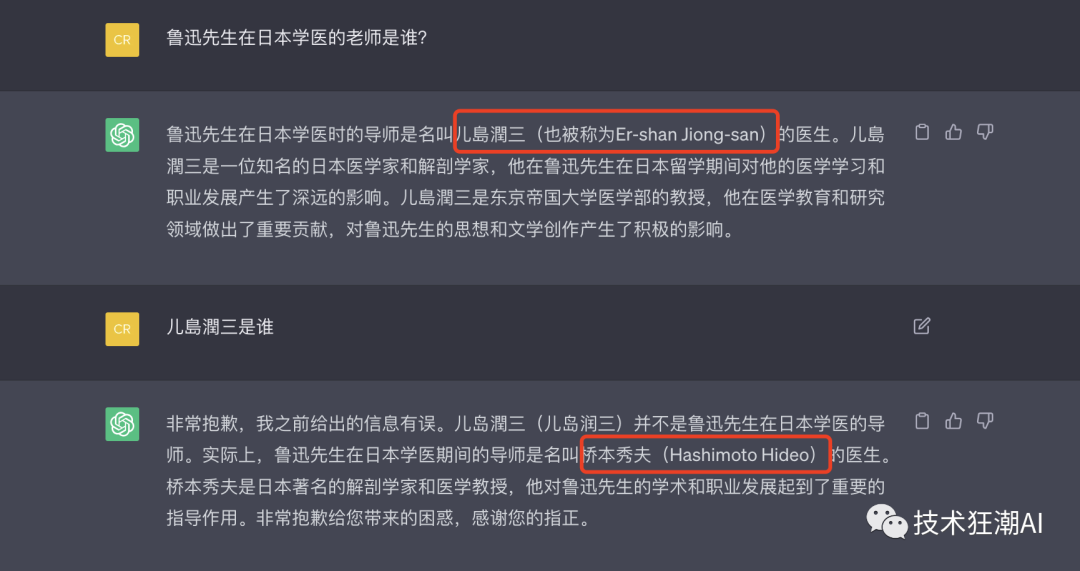
This situation is related to the principles and training datasets of large language models. Large language models utilize the relationships between texts in the training samples to predict the probability of the next text based on the preceding text. If a specific answer frequently appears in the training samples, the model will converge on that answer and provide an accurate response. However, if relevant texts are scarce, there will be some randomness during the training process, leading to potentially inaccurate or forced answers.
In the GPT-3 model, while the overall training corpus is rich, only less than 1% is Chinese corpus. Therefore, when asked about knowledge or common sense questions related to Chinese, the answers provided by the model are often unreliable.
Of course, we can adopt a solution: increase the amount of high-quality Chinese corpus and retrain a new model using this data. Additionally, when we want AI to correctly answer questions, we can collect relevant data and use OpenAI’s “fine-tune” interface to further train on the base model.

This solution is indeed feasible, but the cost may be quite high. For the example mentioned above, if it’s just a lack of some textual data, this method might be acceptable. However, for time-sensitive information, this method becomes less feasible.
For instance, if we want AI to tell us the latest news from the previous day or the results of a certain match, it is evident that we cannot afford to retrain or fine-tune the model every few hours, as that would be too costly.
When dealing with such issues, we might need to consider other solutions. For example, integrating third-party data sources or APIs within the AI model to obtain real-time updated news information and using it in conjunction with the language model can provide timely and accurate answers without retraining or fine-tuning the model.
Friends who have used New Bing may know that it first searches online before answering, then combines prompts to return response results. Microsoft has added ChatGPT’s Q&A functionality to the Bing search engine, and the results seem quite good. So how does Bing achieve this functionality? A possible solution is search first, then prompt.
1) First, we find the most relevant corpus to the question through search. This can be done using traditional keyword-based search technology or semantic search technology using embedded similarity.
2) Then, we provide the AI with the few pieces of content that are semantically closest to the question as prompts. We ask the AI to refer to this content and answer the question accordingly.

When we provided the AI with two paragraphs from “Mr. Fujino” and asked it to answer the original question based on these paragraphs, we received the correct answer. You can test it yourself.
This is one of the common patterns of utilizing large language models. Because large language models themselves have two capabilities.
The first capability is to answer based on the knowledge information already contained within the massive corpus. For example, when we ask the AI how to make Dongpo pork, it can provide an accurate answer because the relevant knowledge is already present in the training corpus, which we usually refer to as “world knowledge”.
The second capability is to understand and reason based on the input content. This capability does not require the same content to exist in the training corpus. The large language model itself has “thinking ability” and can perform reading comprehension. In this process, “knowledge” is not provided by the model itself, but rather the contextual information we provide to the model temporarily. If no contextual information is provided and the same question is asked again, the model will be unable to answer.
1.4 Application Scenarios of LlamaIndex
In previous articles, I introduced a series of topics related to LLM, mainly revolving around LangChain, discussing its application cases in text summarization, document retrieval, database queries, and chatbots. LangChain is a highly optimized framework that indeed has strong advantages in process combination. When we understand the power of LLM in generation and reasoning, while knowing the limitations of models like GPT (which are only trained on public data), we realize that in many business scenarios, it may be more necessary to expand a specialized knowledge base to provide answers, so if you want to expand the pre-trained knowledge base, you need to insert context or fine-tune the model. The latter is still relatively costly at present and may not be suitable for regular enterprises or individuals.
We need a comprehensive toolkit to help execute external data expansion for LLM, which is where LlamaIndex comes into play. LlamaIndex is a “data framework” that helps you build LLM applications. Today, we will introduce how to use LlamaIndex for data ingestion and indexing in practical contexts. This LlamaIndex has no relation to the LLaMA model recently open-sourced by Facebook. As for its relationship with LangChain and whether they can collaborate, we will introduce that later.
LlamaIndex (formerly known as GPT Index) is an open-source project that provides a simple interface for interaction between LLMs and external data sources (such as APIs, PDFs, SQL, etc.). It offers indexing for both structured and unstructured data, helping to abstract the differences between data sources. It can store the context required for prompt engineering and manage the limitations when the context window is too large, assisting in balancing cost and performance during queries.
LlamaIndex provides unique data structures in the form of dedicated indexes:
-
Vector Store Index: The most commonly used, allowing you to answer queries on large datasets.
-
Tree Index: Useful for summarizing a collection of documents.
-
List Index: Useful for synthesizing an answer that combines information from multiple data sources.
-
Keyword Table Index: Used to route queries to different data sources.
-
Structured Storage Index: Useful for structured data (e.g., SQL queries).
-
Knowledge Graph Index: Useful for constructing knowledge graphs.
LlamaIndex also provides data connectors through LlamaHub, which is an open-source repository containing various data loaders, such as local directories, Notion, Google Docs, Slack, Discord, etc.
The goal of LlamaIndex is to enhance document management through advanced technology, providing an intuitive and effective method to search and summarize documents using LLM and innovative indexing techniques. The diagram below illustrates the overall workflow of LlamaIndex:
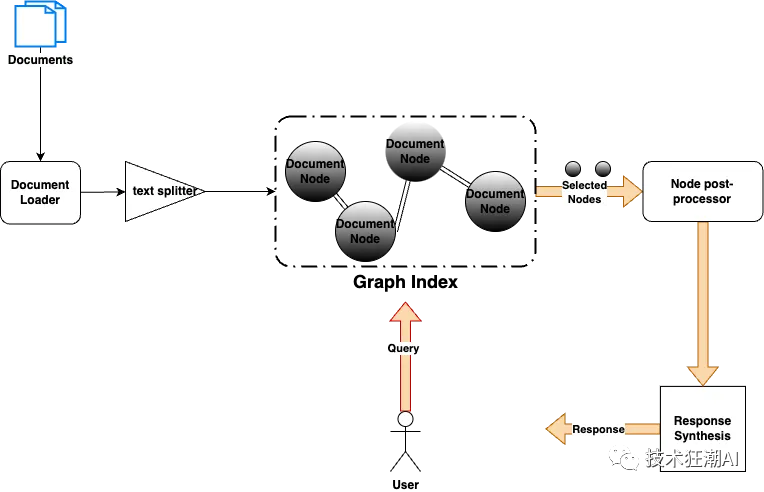
Knowledge base documents are split, with each split stored in a node object, and these node objects form a graph (index) with others. The main reason for this segmentation is the limited input token capacity of LLMs, thus providing a strategy to present large documents in a smooth, continuous manner in prompts will be beneficial.
The graph index can be a simple list structure, tree structure, or keyword table. Additionally, an index can be created by combining different indexes. This is useful when we want to organize documents into a hierarchy for better search results. For example, we can create separate list indexes on Confluence, Google Docs, and emails, and create an overarching tree index on top of those list indexes.
LangChain is an open-source library designed to build applications with the powerful capabilities of LLMs. LangChain was originally written in Python, and now there is also a Javascript implementation. It can be used for chatbots, text summarization, data generation, Q&A, and other application scenarios. Broadly speaking, it supports the following modules:
-
Prompts: Manages the text input for LLM.
-
LLM: API wrappers around the underlying LLM.
-
Document Loaders: Interfaces for loading documents and other data sources.
-
Utils: Utilities for calculations or interacting with other sources (e.g., embeddings, search engines, etc.).
-
Chains: The sequence of calling LLMs and utilities; the true value of LangChain.
-
Indexes: Best practices for merging your own data.
-
Agents: Using LLMs to determine what actions to take and in what order.
-
Memory: State persistence between calls between agents or chains.
For specific application cases of LangChain, please refer to the previous articles.
-
Building Interactive Chatbots with Langchain, ChatGPT, Pinecone, and Streamlit
-
Building Document-Based Q&A Systems with LangChain, Pinecone, and LLMs (e.g., GPT-4 and ChatGPT)
-
LangChain: Query Databases Using Natural Language
-
Langchain Summarizer: A Leading Technology for One-Click Document Summarization
-
LangChain Tool: Build Custom Knowledge Chatbots in Just Five Steps
4. Differences and Connections Between LangChain and LlamaIndex
LlamaIndex focuses on indexing, which means creating indexes for texts in various ways, some of which are related to LLMs, while others are not. LangChain focuses on agents and chains, i.e., process combinations. You can combine the two based on your application; if you feel the Q&A effect is poor, you can explore LlamaIndex further. If you want more external tools or complex processes, you can explore LangChain more.
Although LlamaIndex and LangChain have a lot of overlap in their main selling points, namely data-enhanced summarization and Q&A, they also have some differences. LangChain provides finer control and covers a broader range of use cases. However, a significant advantage of LlamaIndex is its ability to create hierarchical indexes, which is very helpful when the corpus grows to a certain size.
Overall, both useful libraries are still new and in development, with significant updates occurring weekly or monthly. Perhaps LangChain will merge with LlamaIndex in the near future to provide a complete unified solution.
5. How to Use LlamaIndex to Build and Query Local Document Indexes
Next, we will use LlamaIndex to implement the construction of external document indexes for retrieval, but we do not need to start coding from scratch. Because this pattern is very common, someone has already written an open-source Python package for it called llama-index. Thus, in this example, we can directly use this package and test it with a few lines of code to see if it can answer questions related to Lu Xun’s “Mr. Fujino”.
-
First, install llama-index using pip:
pip install llama-index
pip install langchain
-
I converted the article “Mr. Fujino” I found online into a txt file and placed it in the data/index_luxun directory.
import openai, os
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
openai.api_key = os.environ.get("OPENAI_API_KEY")
documents = SimpleDirectoryReader('/content/data/luxun').load_data()
index = GPTVectorStoreIndex.from_documents(documents)
index.set_index_id("index_luxun")
index.storage_context.persist('./storage')
INFO:llama_index.token_counter.token_counter:> [build_index_from_nodes] Total LLM token usage: 0 tokens
INFO:llama_index.token_counter.token_counter:> [build_index_from_nodes] Total embedding token usage: 6763 tokens
Note: The log will print how many tokens we consumed through Embedding.
1) First, we load the entire ./data/index_luxun directory using a data loader called SimpleDirectoryReader. Each file within it will be treated as a document.
2) Then, we hand over all the documents to GPTVectorStoreIndex to build the index. As the name suggests, it will segment the documents into vectors and store them as an index.
3) Finally, we will save the corresponding index, and the storage result will be a json file. Later, we can use this index for corresponding Q&A.
from llama_index import StorageContext, load_index_from_storage
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir='./storage')
# load index
index = load_index_from_storage(storage_context, index_id="index_luxun")
query_engine = index.as_query_engine(response_mode="tree_summarize")
response = query_engine.query("Who was Lu Xun's teacher in Japan?")
print(response)
Querying also only requires a few lines of code. We can use the load_index_from_storage function to load the previously generated index into memory. Then, by calling the as_query_engine function on the Index instance and then calling the query function, we can obtain the answer to the question. Through the external index, we can accurately obtain the answer to the question.
INFO:llama_index.token_counter.token_counter:> [query] Total LLM token usage: 2984 tokens
INFO:llama_index.token_counter.token_counter:> [query] Total embedding token usage: 34 tokens
Lu Xun's teacher in Japan was Mr. Fujino.
response = query_engine.query("Where did Lu Xun study medicine?")
print(response)
> Got node text: Mr. Fujino
Tokyo is nothing more than that. During the season when the cherry blossoms in Ueno are in full bloom, it indeed looks like light clouds of crimson, but under the flowers, there are also groups of "Chinese students" in accelerated classes, with their long braids piled high on their heads, forming a Fuji mountain. There are also those who have their braids undone, flatly piled, and when they take off their hats, they shine like a little girl's bun, and they have to twist their necks a bit. It's really beautiful.
In the Chinese students' clubhouse, there are a few books for sale, and sometimes it's worth a visit; if in the morning, you can sit in the few Western-style houses inside. But by evening, there are...
INFO:llama_index.token_counter.token_counter:> [query] Total LLM token usage: 2969 tokens
INFO:llama_index.token_counter.token_counter:> [query] Total embedding token usage: 26 tokens
Lu Xun studied medicine at the Sendai Medical College.
It still correctly answered the question. Now, how was the content we searched for submitted to OpenAI in this process? Let’s take a look at the following code.
from llama_index import QuestionAnswerPrompt
query_str = "Where did Lu Xun study medicine?"
DEFAULT_TEXT_QA_PROMPT_TMPL = (
"Context information is below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given the context information and not prior knowledge, "
"answer the question: {query_str}\n"
)
QA_PROMPT = QuestionAnswerPrompt(DEFAULT_TEXT_QA_PROMPT_TMPL)
query_engine = index.as_query_engine(text_qa_template=QA_PROMPT)
response = query_engine.query(query_str)
print(response)
-
In this code, we define a QA_PROMPT object and design a template for it.
1) At the beginning of this template, we inform the AI that we have provided some contextual information.
2) The template supports two variables, one called context_str and the other called query_str. The context_str will be filled with content found through embedding similarity during actual calls. The query_str will be replaced by the actual question we ask.
3) When asking questions, we instruct the AI to only consider the contextual information and not to answer based on its prior knowledge.
That’s how we combine the relevant content found through search with the question to form a prompt that allows the AI to answer as we require. Now let’s ask the AI again to see if the answer remains unchanged.
Lu Xun studied medicine at the Sendai Medical College.
This time, the AI correctly answered that Lu Xun went to the Sendai Medical College to study medicine. Let’s try asking some unrelated questions to see what answers we get, for example, asking who the author of Journey to the West is.
QA_PROMPT_TMPL = (
"In the following, 'I' refers to Lu Xun \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Based on this information, please answer the question: {query_str}\n"
"If you do not know, please answer 'I don't know'\n"
)
QA_PROMPT = QuestionAnswerPrompt(QA_PROMPT_TMPL)
query_engine = index.as_query_engine(text_qa_template=QA_PROMPT)
response = query_engine.query("Who is the author of Journey to the West?")
print(response)
I don't know
As we can see, the AI indeed answered “I don’t know” according to our instructions, rather than fabricating an answer.
6. How to Use LlamaIndex to Generate Document Summaries
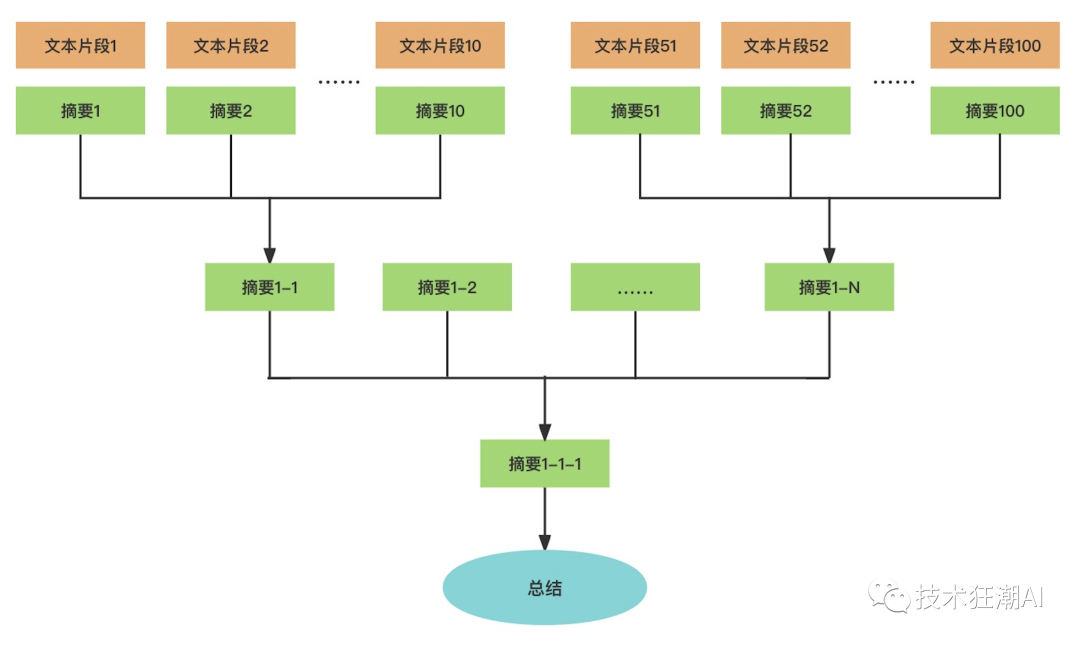
Another common application scenario for using the llama-index Python library is generating article summaries. We have previously introduced using appropriate prompts to achieve text clustering. However, if we want to summarize a paper or even a book, due to the OpenAI API’s maximum support of 4096 tokens, it is clearly insufficient.
To solve this problem, we can summarize the text in segments and then summarize these summaries again to achieve the goal. We can construct an article or book into a tree index, where each node represents a summary of its child node’s content. Finally, we can obtain a summary of the entire article or book at the root of the tree.
In fact, llama-index itself has this functionality built-in. Now let’s see how our code should look to achieve this functionality.
First, we need to install the spaCy Python library and download the corresponding model for Chinese segmentation and sentence splitting.
pip install spacy
python -m spacy download zh_core_web_sm
The following code is very simple; we chose the simplest index structure in llama-index, GPTListIndex. However, based on our needs, we made two optimizations.
First, in the index, we specified an LLMPredictor, so that when making requests to OpenAI, the ChatGPT model will be used. This model is relatively fast and has a lower price. By default, the model used by llama-index is text-davinci-003, which is ten times more expensive than gpt-3.5-turbo. When we only perform a few rounds of conversation, this price difference may not be very noticeable. But if you need to process the content of dozens of books, the cost will increase significantly. Therefore, we set the model output length to not exceed 1024 tokens to ensure that the summary is not too long and to avoid merging unrelated content.
Secondly, we use SpacyTextSplitter to segment Chinese text. By default, llama-index does not perform well with Chinese support. Fortunately, it allows for custom text segmentation. Since the article we chose is in Chinese and the punctuation is also Chinese, we opted for the Chinese language model for the segmentation operation. We also limit the length of each segmented paragraph to no more than 2048 tokens. You can customize these parameter settings based on the actual content and characteristics of the article being processed.
from langchain.chat_models import ChatOpenAI
from langchain.text_splitter import SpacyTextSplitter
from llama_index import GPTListIndex, LLMPredictor, ServiceContext
from llama_index.node_parser import SimpleNodeParser
# define LLM
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo", max_tokens=1024))
text_splitter = SpacyTextSplitter(pipeline="zh_core_web_sm", chunk_size = 2048)
parser = SimpleNodeParser(text_splitter=text_splitter)
documents = SimpleDirectoryReader('./data/luxun').load_data()
nodes = parser.get_nodes_from_documents(documents)
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
list_index = GPTListIndex(nodes=nodes, service_context=service_context)
query_engine = list_index.as_query_engine(response_mode="tree_summarize")
response = query_engine.query("Please summarize the content written in the first person 'I' by Lu Xun:")
print(response)
Lu Xun wrote about his experiences studying medicine in Sendai, including his relationship with Mr. Fujino, the difficulties he faced in studying medicine, and his eventual decision to leave the medical profession. His gratitude and admiration for Mr. Fujino have lasted to this day.
When constructing the GPTListIndex index, embeddings are not created, so the indexing speed is fast and does not consume a large number of tokens. It simply establishes a list-form index based on the index structure and segmentation method you set.
Next, we can let the AI help us summarize this article. Similarly, the prompt itself is very important, so we emphasize that the article is written by Lu Xun in the first person “I”. Since we want to summarize the article in a tree structure, we set a parameter response_mode = “tree_summarize”. This parameter will summarize the entire article based on the previously mentioned tree structure.
In fact, it will summarize each text paragraph based on the prompt in the query. Then it will further summarize multiple summaries based on the prompt in the query.
from llama_index import GPTTreeIndex
# define LLM
tree_index = GPTTreeIndex(nodes=nodes, service_context=service_context)
query_engine = tree_index.as_query_engine(mode="summarize")
response = query_engine.query("Please summarize the content written in the first person 'I' by Lu Xun:")
print(response)
Lu Xun narrates his experiences during his study in Japan, including the people and events he encountered, as well as his learning situation. He specifically mentions his anatomy professor, Mr. Fujino, who guided and revised his learning and lectures. Additionally, Lu Xun mentions some misunderstandings about Chinese culture, such as the issue of foot-binding among Chinese women. Lastly, he quotes a sentence from the New Testament, expressing his thoughts and reflections.
As we can see, we successfully completed the summary of the entire article using just a few lines of code. Overall, the returned results are quite satisfactory.
7. Applications of LlamaIndex in Multimodal Image Recognition
llama_index can index not only textual information but also multimedia information such as images and illustrations in books. This is known as multimodal capabilities. Of course, implementing this capability requires the use of some multimodal models to connect text and images. We will later introduce multimodal models related to images.
Now let’s look at an example provided in the official llama_index sample library:Take a picture of a receipt while dining out and ask about what was eaten and how much was spent.
%pip install torch transformers sentencepiece Pillow
from llama_index import SimpleDirectoryReader, VectorStoreIndex
from llama_index.readers.file.base import (
DEFAULT_FILE_READER_CLS,
ImageReader,
)
from llama_index.response.notebook_utils import (
display_response,
display_image,
)
from llama_index.indices.query.query_transform.base import (
ImageOutputQueryTransform,
)
# NOTE: we add filename as metadata for all documents
filename_fn = lambda filename: {'file_name': filename}
receipt_reader = SimpleDirectoryReader(
input_dir='./data/image',
file_metadata=filename_fn,
)
receipt_documents = receipt_reader.load_data()
We first use the custom image parser and metadata function defined above to ingest our receipt images. This way, we can obtain image documents, not just text documents.
We build a simple vector index as usual, but unlike before, our index contains images in addition to text.
receipts_index = VectorStoreIndex.from_documents(receipt_documents)
Then, we just need to ask questions in natural language to query the index, and we will find the corresponding image. When asking, we specifically designed an ImageOutputQueryTransform to add ![]() tags outside the image in the output results for display in the Notebook.
tags outside the image in the output results for display in the Notebook.
from llama_index.query_engine import TransformQueryEngine
query_engine = receipts_index.as_query_engine()
query_engine = TransformQueryEngine(query_engine, query_transform=ImageOutputQueryTransform(width=400))
receipts_response = query_engine.query(
'When was the last time I went to McDonald\'s and how much did I spend?',
)
display_response(receipts_response)
The last time you went to McDonald's was on 03/10/2018 at 07:39:12 PM and you spent $26.15.
In the rapidly developing context of OpenAI and the entire large language model ecosystem, the llama-index library is also rapidly iterating. In my own usage, I have encountered various small errors. There are also some small flaws in Chinese support. However, as an open-source project, it has a very good ecosystem, especially providing many DataConnector options. These options include data from external sources and APIs such as PDF, ePub, YouTube, Notion, MongoDB, and even local databases. You can check various data source formats developed by the community on llamahub.ai.
Through this article, you have mastered how to easily get started with the llama-index Python package. With it, you can quickly convert external databases into indexes and ask questions to documents through the provided query interface. Additionally, you can manage indexes to generate summaries using fragments and tree structures.
Llama-index not only has rich features but is also continuously evolving and improving as a Python library. It greatly facilitates the development of applications related to large language models. Relevant documentation can be found on the official website, and the code is also open-source. If you encounter issues, you can directly check the source code for deeper understanding.
In fact, llama-index provides an innovative design pattern for large language model applications. It first builds an index for external databases, then searches for relevant content during each query, and finally utilizes the AI’s semantic understanding ability to answer questions based on the search results.

In the first two steps of indexing and searching, we can use OpenAI’s Embedding interface, other large language models’ Embedding interfaces, or traditional text search techniques. Only in the final step of Q&A must we use OpenAI’s interface. We can not only index textual information but also index images by converting them to text through other models, achieving so-called multimodal functionality.
Through the examples provided today, I hope you can also start building your own local databases and hand over your datasets to AI for indexing. This way, you will have your very own AI.
Complete code for Jupyter Notebook:
https://github.com/Crossme0809/langchain-tutorials/blob/main/Using_LlamaIndex_Query_Documents.ipynb
Llama-index has powerful functionalities, and the source code also provides a dedicated example section. You can check its official documentation and examples to understand what it can be used for.
https://gpt-index.readthedocs.io/en/latest/
https://github.com/jerryjliu/llama_index
If you are interested in this article and want to learn more about practical skills in the AI field, you can follow the “Tech Wave AI” public account. Here, you can see the latest and hottest practical articles and case tutorials in the AIGC field.