
Introduction
What is RAG
LLMs can produce misleading “hallucinations”, depend on information that may be outdated, and are inefficient when handling specific knowledge, lacking deep insights in specialized fields, while also having some deficiencies in reasoning capabilities.
It is against this backdrop that Retrieval-Augmented Generation (RAG) technology has emerged, becoming a significant trend in the AI era.
RAG retrieves relevant information from a wide document database before generating answers with the language model, significantly enhancing the accuracy and relevance of the content. RAG effectively mitigates the hallucination problem, speeds up knowledge updates, and enhances the traceability of generated content, making large language models more practical and trustworthy in real-world applications.
A typical example of RAG:
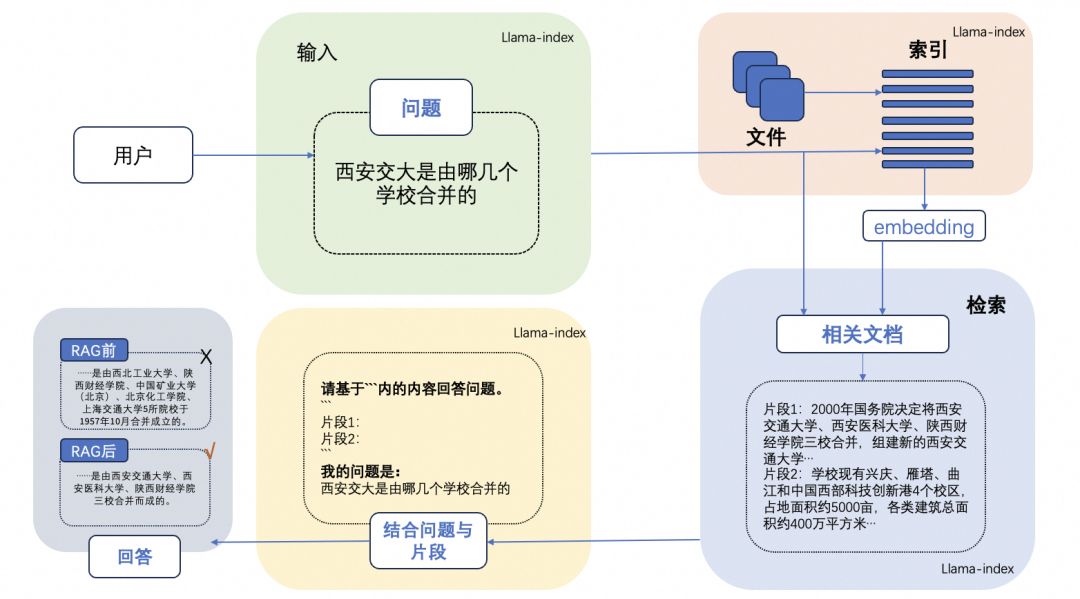
This primarily includes three basic steps:
1. Indexing — Splitting the document library into shorter chunks and building a vector index using an encoder.
2. Retrieval — Retrieving relevant document segments based on the similarity of the question and chunks.
3. Generation — Generating answers to questions based on the retrieved context.
Qwen1.5
The Qwen1.5 version has open-sourced six sizes of foundational and chat models, including 0.5B, 1.8B, 4B, 7B, 14B, and 72B, as well as quantized models. It provides not only Int4 and Int8 GPTQ models but also AWQ models and GGUF quantized models. To enhance the developer experience, the code for Qwen1.5 has been merged into Hugging Face Transformers, allowing developers to use transformers>=4.37.0 without needing trust_remote_code.
Compared to previous versions, Qwen1.5 significantly improves the consistency of chat models with human preferences and enhances their multilingual capabilities. All models provide unified context length support, supporting 32K contexts. Additionally, the quality of the foundational language models has also seen slight improvements.
The entire Qwen1.5 series possesses strong capabilities to link external systems (agent/RAG/Tool-use/Code-interpreter).
Because Qwen1.5 is the first Chinese LLM to be integrated into Transformers, we can also use LLaMaIndex’s native HuggingFaceLLM to load the model.
LLaMaIndex
LlamaIndex is a data framework for applications based on LLMs, benefiting from context enhancement. This LLM system is referred to as a RAG system, representing “Retrieval-Augmented Generation”. LlamaIndex provides the necessary abstractions to more easily ingest, build, and access private or domain-specific data, allowing this data to be securely injected into LLMs for more accurate text generation.
GTE Text Vector
Text representation is a core issue in the field of Natural Language Processing (NLP), playing a crucial role in many downstream tasks of NLP and information retrieval. In recent years, with the development of deep learning, especially the emergence of pre-trained language models, the effectiveness of text representation technology has significantly improved, with pre-trained language model-based text representation models clearly outperforming traditional statistical models or shallow neural network-based text representation models in academic research data and industrial applications. Here, we mainly focus on text representation based on pre-trained language models.
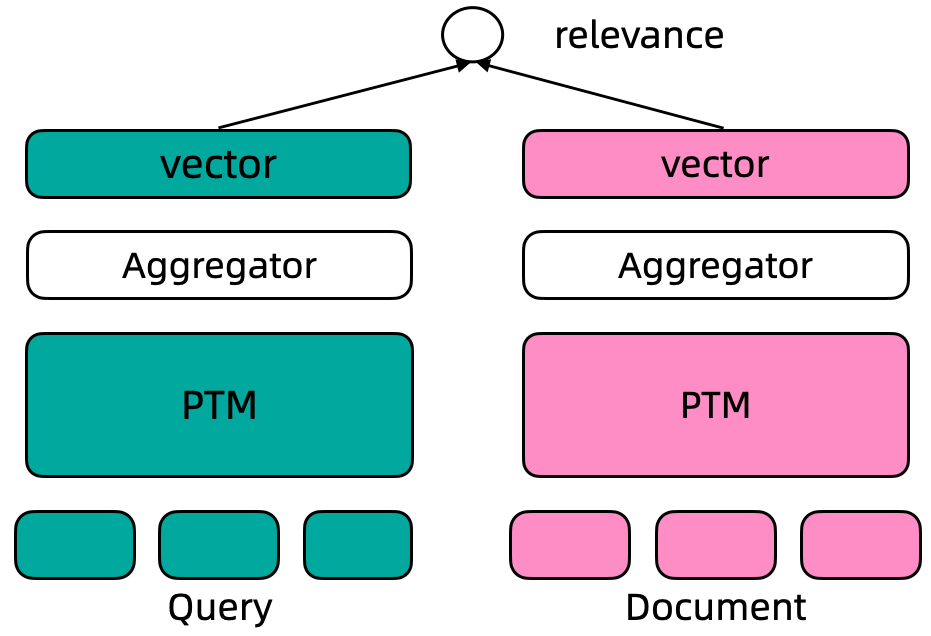
The GTE-zh model uses retromae to initialize the training model and then trains the model using a two-stage training method: the first stage utilizes a large-scale weakly supervised text pair dataset to train the model, and the second stage uses high-quality labeled text data and mined difficult negative sample data to train the model.
Best Practices from the Magic Community
Environment Configuration and Installation
-
Python 3.10 or above
-
PyTorch 1.12 or above, recommended 2.0 or above
-
It is recommended to use CUDA 11.4 or above
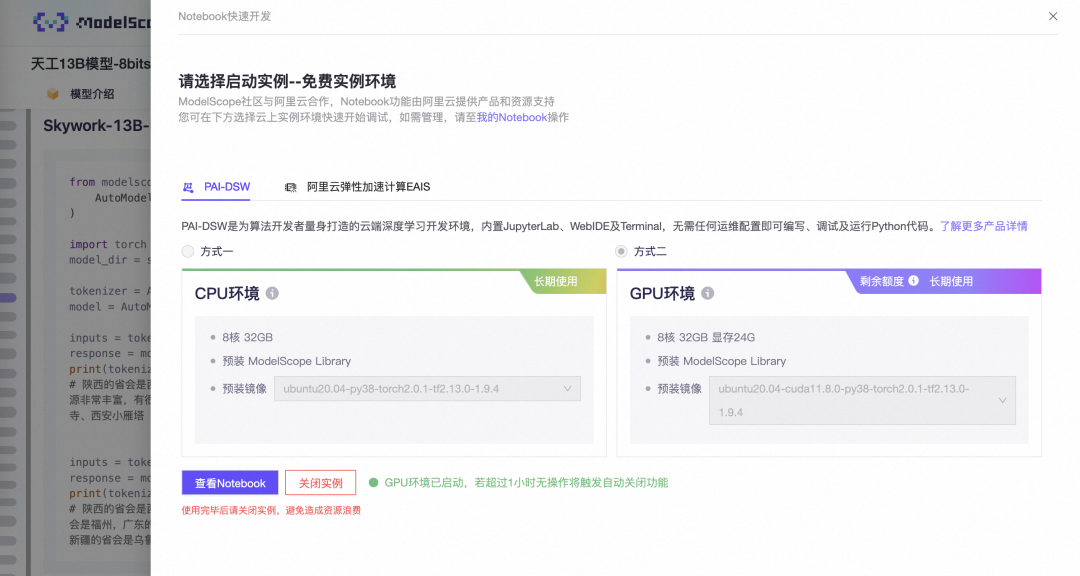
The model inference code demonstrated in this article can run under the free instance of the Magic Community PAI-DSW configuration (24G memory):
Step 1: Click the Notebook quick development button on the right side of the model and select the GPU environment
Step 2: Create a new Notebook
Install dependencies
!pip install llama-index llama-index-llms-huggingface ipywidgets!pip install transformers -Uimport loggingimport sys
logging.basicConfig(stream=sys.stdout, level=logging.INFO)logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
from IPython.display import Markdown, displayimport torchfrom llama_index.llms.huggingface import HuggingFaceLLMfrom llama_index.core.prompts import PromptTemplatefrom modelscope import snapshot_downloadfrom llama_index.core.base.embeddings.base import BaseEmbedding, Embeddingfrom abc import ABCfrom typing import Any, List, Optional, Dict, castfrom llama_index.core import ( VectorStoreIndex, ServiceContext, set_global_service_context, SimpleDirectoryReader,)Load the large language model
Since Qwen now supports Transformers, use HuggingFaceLLM to load the model, which is (Qwen1.5-4B-Chat)
# Model names qwen2_4B_CHAT = "qwen/Qwen1.5-4B-Chat"
selected_model = snapshot_download(qwen2_4B_CHAT)
SYSTEM_PROMPT = """You are a helpful AI assistant."""
query_wrapper_prompt = PromptTemplate( "[INST]<<SYS>>\n" + SYSTEM_PROMPT + "<</SYS>>\n\n{query_str}[/INST] ")
llm = HuggingFaceLLM( context_window=4096, max_new_tokens=2048, generate_kwargs={"temperature": 0.0, "do_sample": False}, query_wrapper_prompt=query_wrapper_prompt, tokenizer_name=selected_model, model_name=selected_model, device_map="auto", # change these settings below depending on your GPU model_kwargs={"torch_dtype": torch.float16},)Load data: Import test data
!mkdir -p 'data/xianjiaoda/'!wget 'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/rag/xianjiaoda.md' -O 'data/xianjiaoda/xianjiaoda.md'documents = SimpleDirectoryReader("/mnt/workspace/data/xianjiaoda/").load_data()documentsBuild the Embedding class
Load the GTE model and use it to construct the Embedding class
embedding_model = "iic/nlp_gte_sentence-embedding_chinese-base"class ModelScopeEmbeddings4LlamaIndex(BaseEmbedding, ABC): embed: Any = None model_id: str = "iic/nlp_gte_sentence-embedding_chinese-base"
def __init__( self, model_id: str, **kwargs: Any, ) -> None: super().__init__(**kwargs) try: from modelscope.models import Model from modelscope.pipelines import pipeline from modelscope.utils.constant import Tasks # 使用modelscope的embedding模型(包含下载) self.embed = pipeline(Tasks.sentence_embedding, model=self.model_id)
except ImportError as e: raise ValueError( "Could not import some python packages." "Please install it with `pip install modelscope`." ) from e
def _get_query_embedding(self, query: str) -> List[float]: text = query.replace("\n", " ") inputs = {"source_sentence": [text]} return self.embed(input=inputs)['text_embedding'][0].tolist()
def _get_text_embedding(self, text: str) -> List[float]: text = text.replace("\n", " ") inputs = {"source_sentence": [text]} return self.embed(input=inputs)['text_embedding'][0].tolist()
def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]: texts = list(map(lambda x: x.replace("\n", " "), texts)) inputs = {"source_sentence": texts} return self.embed(input=inputs)['text_embedding'].tolist()
async def _aget_query_embedding(self, query: str) -> List[float]: return self._get_query_embedding(query)
Build the index
After loading the data, based on the list of document objects (or node list), build their index for easy retrieval.
embeddings = ModelScopeEmbeddings4LlamaIndex(model_id=embedding_model)service_context = ServiceContext.from_defaults(embed_model=embeddings, llm=llm)set_global_service_context(service_context)
index = VectorStoreIndex.from_documents(documents)Query and Q&A
Building a Q&A engine based on a local knowledge base
query_engine = index.as_query_engine()response = query_engine.query("Which schools merged to form Xi'an Jiaotong University?")print(response)Reference open-source link (or click Read the original text to go directly) https://github.com/modelscope/modelscope/tree/master/examples/pytorch/application