

LlamaIndex is an LLM (Large Language Model) application development framework that many developers prefer to use for developing RAG (Retrieval-Augmented Generation) applications. During the development of RAG applications, we often need to evaluate relevant data to better adjust and optimize the applications. With the development of RAG technology, more excellent evaluation tools have emerged, which can help us conveniently and accurately evaluate RAG applications. Today, I will introduce some RAG evaluation tools that can be integrated with LlamaIndex and analyze them comparatively.
What Are RAG Evaluation Tools
RAG evaluation tools are methods or frameworks used to test and evaluate retrieval-based text generation systems. The evaluation content includes the accuracy of retrieval, the quality of generated content, and relevance, with evaluation metrics including precision, recall, consistency, and rationality. They can help developers better understand and optimize RAG applications, making them more suitable for practical use. Compared to manual evaluation, RAG evaluation tools are more objective, accurate, and efficient, and can conduct large-scale evaluations through automation, allowing applications to iterate and optimize faster. In fact, some applications are already doing this by integrating RAG evaluation tools into the CI/CD process for automated evaluation and optimization of systems.
Entity Terms
In RAG applications, there are some commonly used entities that evaluation tools mainly utilize for evaluation. However, the names of these entities may vary among numerous RAG evaluation tools. Therefore, before introducing specific evaluation tools, let’s first look at the definitions of these entities:
-
Question: Refers to the question input by the user. RAG applications retrieve relevant document contexts through questions. In some evaluation tools, this entity may also be referred to as
InputorQuery. -
Context: Refers to the retrieved document context. After RAG applications retrieve relevant documents, they submit these contexts along with the user’s question to the LLM to generate answers. Some evaluation tools may refer to it as
Retrieval Context. -
Answer: Refers to the generated answer. After RAG applications submit the question and context to the LLM, the LLM generates an answer based on this information. The naming of this entity is quite varied, including:
Actual Output,Response, etc. -
Ground Truth: Refers to the correct answer manually annotated. This entity can be used to analyze the generated answer to obtain evaluation results. Some evaluation tools may refer to it as
Expected Output.
In the introduction of the evaluation tools below, these entity terms will also be used for better understanding and comparison.
Preparation Work
Test Document
We will uniformly use the well-known Marvel movie The Avengers related plot as the test document. The document content is mainly sourced from the The Avengers[1] entry on Wikipedia, mainly including plot information about the four Avengers movies.
Dataset
Based on the test document, we need to create Question and Ground Truth data to facilitate our evaluation work. Below is the dataset we defined:
questions = [
"What mysterious item did Loki use to try to conquer Earth?",
"Which two Avengers members created Ultron?",
"How did Thanos carry out his plan to exterminate half of the universe's life?",
"What method did the Avengers use to reverse Thanos's actions?",
"Which Avengers member sacrificed themselves to defeat Thanos?",
]
ground_truth = [
"Tesseract",
"Tony Stark (Iron Man) and Bruce Banner (Hulk)",
"Using six Infinity Stones",
"Collecting stones through time travel",
"Tony Stark (Iron Man)",
]
Retrieval Engine
Next, we will use LlamaIndex[2] to create a standard RAG retrieval engine. The subsequent evaluation tools will use this retrieval engine to generate Answer and Context:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
vectore_index = VectorStoreIndex.from_documents(documents)
query_engine = vector_index.as_query_engine(similiarity_top_k=2)
-
We first load the documents from the
datadirectory. -
Then use
VectorStoreIndexto create a document vector index. -
Finally, convert the document vector index into a query engine and set the similarity threshold to 2.
TruLens
First, let’s take a look at TruLens[3], a software tool designed to evaluate and improve LLM applications.
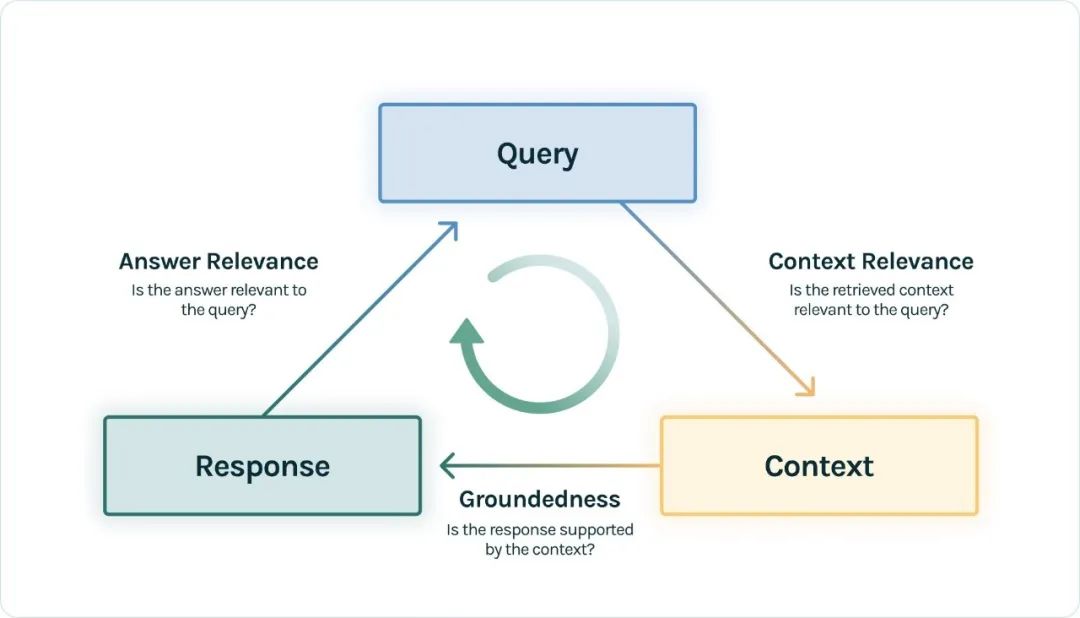
Evaluation Metrics
TruLens primarily uses the following metrics to evaluate RAG applications:
-
Answer Relevance: Measures how well the
Answeraddresses theQuestion, ensuring it is helpful and relevant. -
Context Relevance: Evaluates the relevance of the
Contextto theQuestion. This is very important as the context forms the basis of the LLM’s answer. -
Groundedness: Assesses whether the
Answeris consistent with the facts provided in theContext, ensuring no exaggeration or deviation from the given information. -
Ground Truth: Evaluates the similarity between the
AnswerandGround Truth, ensuring that the generated answer is consistent with the manually annotated answer.
Usage Example
Below is an example of using TruLens for RAG evaluation:
import numpy as np
from trulens_eval import Tru, Feedback, TruLlama
from trulens_eval.feedback.provider.openai import OpenAI
from trulens_eval.feedback import Groundedness, GroundTruthAgreement
openai = OpenAI()
golden_set = [{"query": q, "response": r} for q, r in zip(questions, ground_truth)]
ground_truth = Feedback(
GroundTruthAgreement(golden_set).agreement_measure, name="Ground Truth"
).on_input_output()
grounded = Groundedness(groundedness_provider=openai)
groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons, name="Groundedness")
.on(TruLlama.select_source_nodes().node.text)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
qa_relevance = Feedback(
openai.relevance_with_cot_reasons, name="Answer Relevance"
).on_input_output()
qs_relevance = (
Feedback(openai.qs_relevance_with_cot_reasons, name="Context Relevance")
.on_input()
.on(TruLlama.select_source_nodes().node.text)
.aggregate(np.mean)
)
tru_query_engine_recorder = TruLlama(
query_engine,
app_id="Avengers_App",
feedbacks=[
ground_truth,
groundedness,
qa_relevance,
qs_relevance,
],
)
with tru_query_engine_recorder as recording:
for question in questions:
query_engine.query(question)
tru = Tru()
tru.run_dashboard()
This code primarily uses TruLens to evaluate RAG applications. First, we define metrics such as Ground Truth, Groundedness, Answer Relevance, and Context Relevance, then use TruLlama to record the query results of the query engine, and finally use Tru to run the evaluation and display the results.
Evaluation Results
The evaluation results of TruLens can be viewed by accessing the local service through a browser. The overall score and detailed evaluation metrics will be displayed in the evaluation results, and the reasons for the metric scores can also be viewed in the evaluation results. Below are the evaluation results of TruLens:
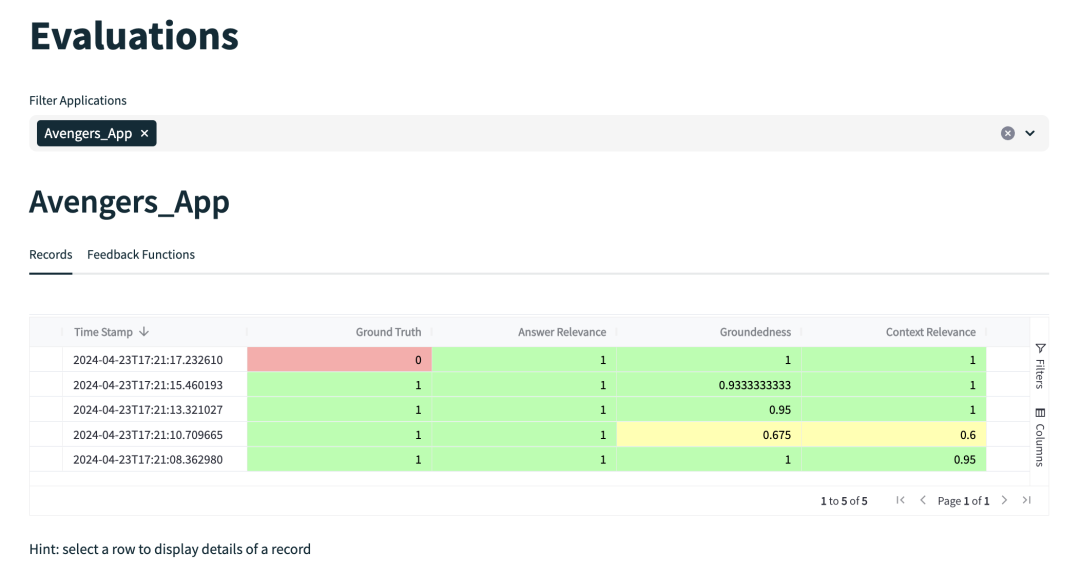
I have previously written an article about TruLens, which can be found here, containing more detailed introductions and usage examples.
Ragas
Ragas[5] is another framework for evaluating RAG applications. Compared to TruLens, Ragas has more and more detailed evaluation metrics.
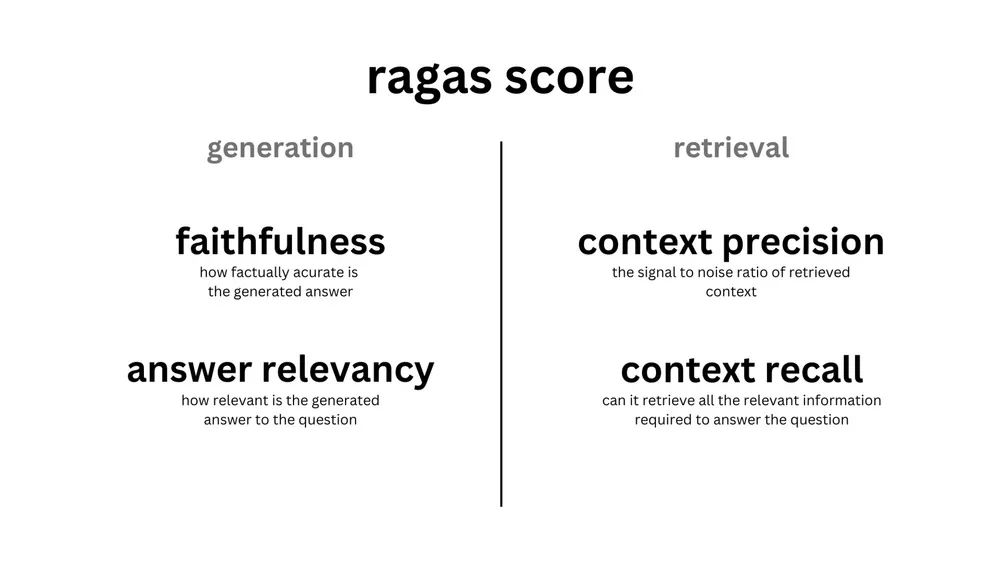
Evaluation Metrics
Ragas primarily uses the following metrics to evaluate RAG applications:
-
Faithfulness: Evaluates the consistency between
QuestionandContext, similar to TruLens’s Groundedness. -
Answer Relevance: Evaluates the consistency between
AnswerandQuestion, similar to TruLens’s Answer Relevance. -
Context Precision: Evaluates whether
Ground Truthranks high inContext. -
Context Recall: Evaluates the consistency between
Ground TruthandContext. -
Context Entities Recall: Evaluates the consistency between entities in
Ground Truthand entities inContext. -
Context Relevancy: Evaluates the consistency between
QuestionandContext, similar to TruLens’s Context Relevance. -
Answer Semantic Similarity: Evaluates the semantic similarity between
AnswerandGround Truth. -
Answer Correctness: Evaluates the correctness of
Answerrelative toGround Truth. This metric will use the results ofAnswer Semantic Similarity, similar to TruLens’s Ground Truth. -
Aspect Critique: Other aspects of evaluation, such as harmfulness and correctness.
Usage Example
In the official documentation of Ragas, there is an example of integrating LlamaIndex[6]. The code there is outdated, and Ragas no longer supports this integration method in the latest version. Therefore, we need to manually integrate LlamaIndex. Below is a simple integration example:
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_relevancy,
answer_correctness,
)
from ragas import evaluate
from datasets import Dataset
metrics = [
faithfulness,
answer_relevancy,
context_relevancy,
answer_correctness,
]
answers = []
contexts = []
for q in questions:
response = query_engine.query(q)
answers.append(response.response)
contexts.append([sn.get_content() for sn in response.source_nodes])
data = {
"question": questions,
"contexts": contexts,
"answer": answers,
"ground_truth": ground_truth,
}
dataset = Dataset.from_dict(data)
result = evaluate(dataset, metrics)
result.to_pandas().to_csv("output/ragas-evaluate.csv", sep=",")
-
We still use the original question and answer data:
questionsandground_truth. -
Using evaluation metrics similar to those in TruLens, including
faithfulness,answer_relevancy,context_relevancy, andanswer_correctness. -
We need to manually construct the evaluation dataset by obtaining generated answers and contexts by querying each question, adding them to
data. -
Finally, we pass the dataset to the
evaluatefunction for evaluation and save the evaluation results to a local file.
Evaluation Results
We can view Ragas’s evaluation results in the local file, which includes scores for various evaluation metrics. Below are the evaluation results of Ragas:
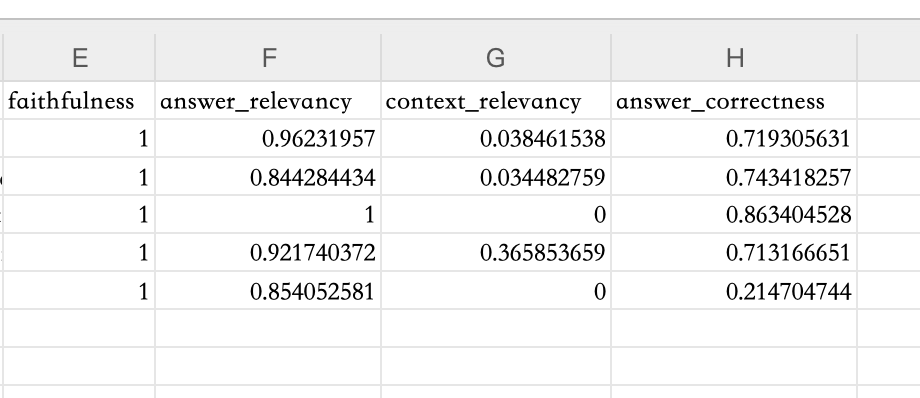
It can be seen that the evaluation results of Ragas differ significantly from those of TruLens, especially the evaluation result of Context Relevancy, which scored relatively low. In fact, when evaluating Context, Ragas recommends using Context Precision and Context Recall as the two evaluation metrics. Here, we used Context Relevancy for comparison with TruLens’s evaluation results.
In the evaluation results of Ragas, we only see scores but not the specific reasons for the scores.
DeepEval
DeepEval[7] is an open-source evaluation framework for LLMs, characterized by its ability to run evaluation tasks like unit tests, making it easier to check and optimize RAG applications.
Evaluation Metrics
DeepEval mainly uses the following evaluation metrics, some of which are used to evaluate RAG applications, while others are for other aspects of LLM applications:
-
Faithfulness: Evaluates the consistency between
QuestionandContext, similar to TruLens’s Groundedness. -
Answer Relevance: Evaluates the consistency between
AnswerandQuestion, similar to TruLens’s Answer Relevance. -
Contextual Precision: Evaluates whether
Ground Truthranks high inContext, similar to Ragas’s Context Precision. -
Contextual Recall: Evaluates the consistency between
Ground TruthandContext, similar to Ragas’s Context Recall. -
Contextual Relevancy: Evaluates the consistency between
QuestionandContext, similar to TruLens’s Context Relevance. -
Hullucination: Evaluates the degree of hallucination present.
-
Bias: Evaluates the degree of bias present.
-
Toxicity: Evaluates the degree of toxicity present, referring to personal attacks, mockery, hate, belittling, threats, and intimidation.
-
Ragas: Can use Ragas’s evaluation and generate reasons for scores.
-
Knowledge Retention: Evaluates the information retention of LLM applications.
-
Summarization: Evaluates the summarization effect of documents.
-
G-Eval: G-Eval is a framework that uses LLMs with chain-of-thought (CoT) to perform evaluation tasks, which can evaluate LLM outputs based on any custom criteria, as detailed in related papers[8].
Usage Example
DeepEval can run evaluation tasks like unit tests, so the execution file needs to start with test_. Below is a simple usage example:
import pytest
from deepeval.metrics import (
AnswerRelevancyMetric,
FaithfulnessMetric,
ContextualRelevancyMetric,
)
from deepeval.test_case import LLMTestCase
from deepeval import assert_test
from deepeval.dataset import EvaluationDataset
def genrate_dataset():
test_cases = []
for i in range(len(questions)):
response = query_engine.query(questions[i])
test_case = LLMTestCase(
input=questions[i],
actual_output=response.response,
retrieval_context=[node.get_content() for node in response.source_nodes],
expected_output=ground_truth[i],
)
test_cases.append(test_case)
return EvaluationDataset(test_cases=test_cases)
dataset = genrate_dataset()
@pytest.mark.parametrize(
"test_case",
dataset,
)
def test_rag(test_case: LLMTestCase):
answer_relevancy_metric = AnswerRelevancyMetric(model="gpt-3.5-turbo")
faithfulness_metric = FaithfulnessMetric(model="gpt-3.5-turbo")
context_relevancy_metric = ContextualRelevancyMetric(model="gpt-3.5-turbo")
assert_test(
test_case,
[answer_relevancy_metric, faithfulness_metric, context_relevancy_metric],
)
-
Executing DeepEval evaluation tasks also requires constructing a test dataset, which includes questions, generated answers, contexts, and standard answers.
-
For evaluation metrics, we used
Faithfulness,Answer Relevance, andContext Relevance. Since DeepEval does not have theGround Truthmetric, we cannot align it with the evaluation results of TruLens and Ragas. -
DeepEval defaults to using the
gpt-4model. If you want to save costs, it’s recommended to specify the model name in the evaluation metrics, such asgpt-3.5-turbo. -
In the evaluation metrics class of DeepEval, there is a
thresholdparameter, with a default value of 0.5, indicating the threshold for evaluation metrics. If the score is below this threshold, it indicates a test failure.
Then run the command deepeval test run test_deepeval.py in the terminal to execute the evaluation task. After executing the command, DeepEval will automatically run the evaluation task and output the results. If the test passes, it will display PASSED; otherwise, it will display FAILED, followed by the complete evaluation results.
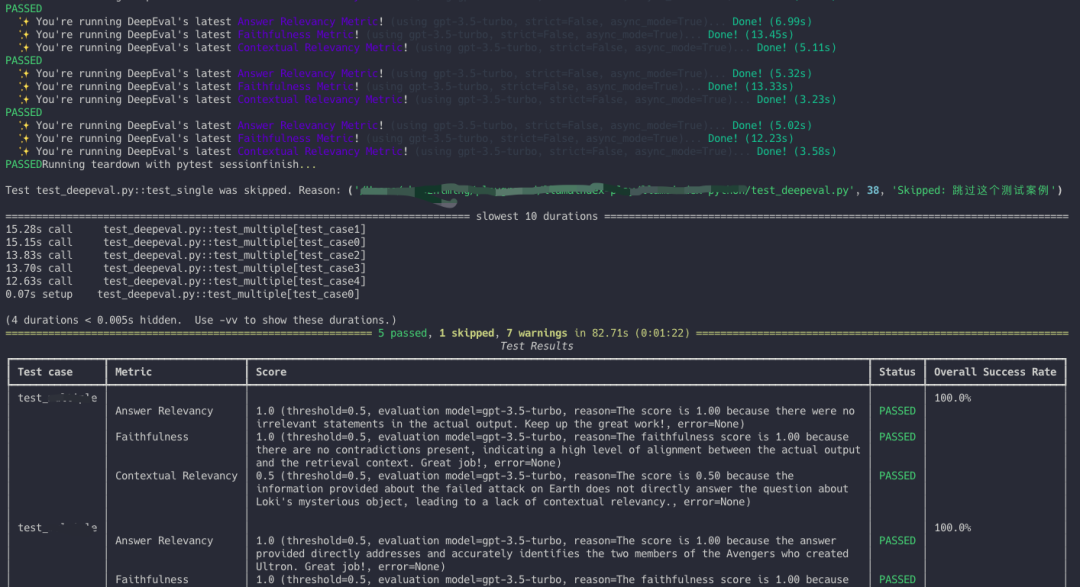
Evaluation Results
Viewing evaluation results in the terminal may not be very convenient. DeepEval offers several other ways for us to better view the evaluation results.
One way is to save the evaluation results to a local file. Before executing the test command, set the environment variable export DEEPEVAL_RESULTS_FOLDER="./output", so that the results will be saved in JSON format in the output directory. We can view the evaluation results by checking the file.
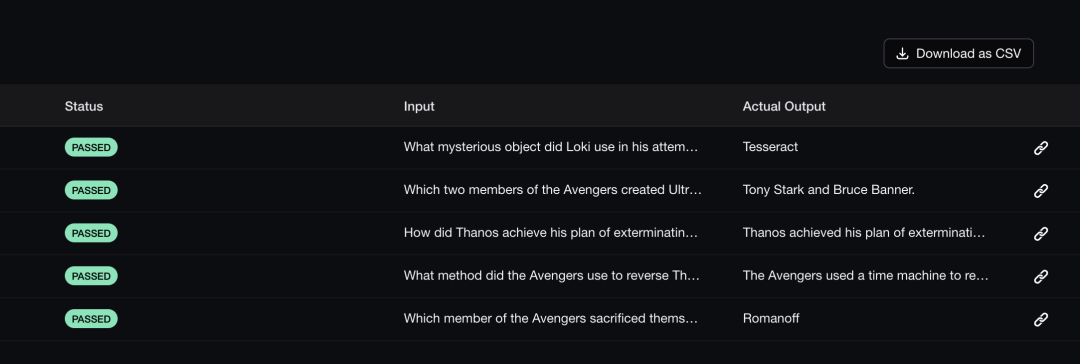
Another way is to register for a Confident[9] account to obtain an API_KEY, then log in using the command deepeval login --confident-api-key your_api_key, and then execute the test command. This way, after the command execution is completed, the results will be automatically uploaded to the Confident platform for easy viewing. Below is a screenshot of the evaluation results on the Confident platform:
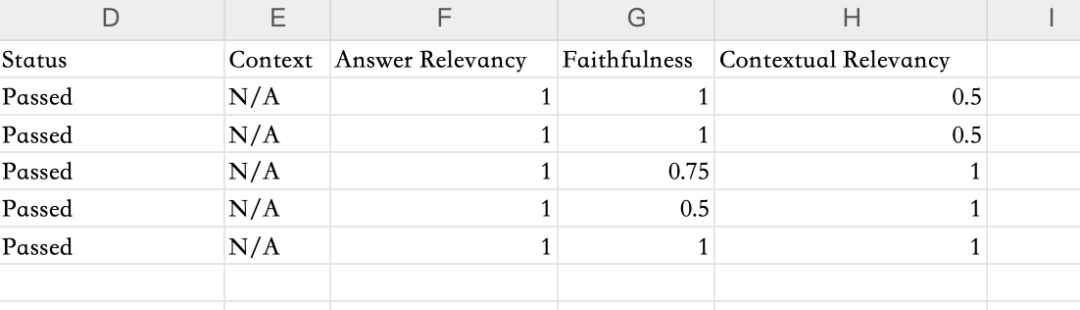
On the website, you can also export the evaluation results as a CSV file for local viewing:
UpTrain
UpTrain[10] is an open-source platform for evaluating and improving LLM applications. Compared to other evaluation tools, UpTrain has the richest evaluation metrics, helping developers gain a comprehensive understanding and optimization of RAG applications.

Evaluation Metrics
UpTrain primarily uses the following evaluation metrics, which are applicable not only to RAG applications but also to other LLM applications:
-
Response Matching: Evaluates the consistency between
AnswerandGround Truth, similar to TruLens’s Ground Truth. -
Response Completeness: Evaluates whether
Answeraddresses all aspects of theQuestion. -
Response Conciseness: Evaluates whether
Answeravoids irrelevant content related to theQuestion. -
Response Relevance: Evaluates the relevance between
AnswerandQuestion, similar to TruLens’s Answer Relevance. -
Response Validity: Evaluates whether
Answeris valid; invalid answers refer to empty responses or responses like I don’t know. -
Response Consistency: Evaluates the consistency between
Answer,Question, andContext. -
Context Relevance: Evaluates the relevance between
ContextandQuestion, similar to TruLens’s Context Relevance. -
Context Utilization: Evaluates whether
Answercomprehensively addresses all points of theQuestionbased onContext. -
Factual Accuracy: Evaluates whether
Answeris factually correct and derived fromContext, feeling like an enhanced version of TruLens’s Groundedness. -
Context Conciseness: Evaluates whether
Contextis concise and key, without irrelevant information, requiring the addition of theconcise_contextparameter for evaluation. -
Context Reranking: Evaluates the effectiveness of the reranked
Contextagainst the originalContext, requiring the addition of thererank_contextparameter for evaluation. -
Jailbreak Detection: Evaluates whether the
Questioncontains jailbreak prompts that lead to the generation of inappropriate information. -
Prompt Injection: Evaluates whether the
Questionleaks system prompts of the LLM application. -
Language Features: Evaluates whether
Answeris concise, coherent, and free of grammatical errors. -
Tonality: Evaluates whether
Answerfits the tone of a specific role, requiring additional parameters for evaluation. -
Sub-query Completeness: Evaluates whether sub-questions cover all aspects of the original
Question, requiring the addition of thesub_questionsparameter for evaluation. -
Multi-query Accuracy: Evaluates whether variant questions are consistent with the original
Question, requiring the addition of thevariantsparameter for evaluation. -
Code Hallucination: Evaluates whether the code in
Answeris related toContext. -
User Satisfaction: Evaluates user satisfaction in conversations.
Usage Example
UpTrain integrates LlamaIndex, so we can use its EvalLlamaIndex to create evaluation objects, helping us automatically generate Answer and Context. Below is a simple usage example:
import os
import json
from uptrain import EvalLlamaIndex, Evals, ResponseMatching, Settings
settings = Settings(
openai_api_key=os.getenv("OPENAI_API_KEY"),
)
data = []
for i in range(len(questions)):
data.append(
{
"question": questions[i],
"ground_truth": ground_truth[i],
}
)
llamaindex_object = EvalLlamaIndex(settings=settings, query_engine=query_engine)
results = llamaindex_object.evaluate(
data=data,
checks=[
ResponseMatching(),
Evals.CONTEXT_RELEVANCE,
Evals.FACTUAL_ACCURACY,
Evals.RESPONSE_RELEVANCE,
],
)
with open("output/uptrain-evaluate.json", "w") as json_file:
json.dump(results, json_file, indent=2)
-
UpTrain defaults to using OpenAI’s model for evaluation, so the OpenAI API_KEY needs to be set.
-
In the initial test dataset, we only need to provide questions and standard answers; other data will be automatically generated by
EvalLlamaIndex. -
In the evaluation metrics, we used metrics similar to those in other evaluation tools.
-
Finally, save the evaluation results to a local file.
Evaluation Results
The evaluation results are saved in a JSON file. To facilitate comparison, we convert the evaluation results into a CSV file. Below are the evaluation results of UpTrain:
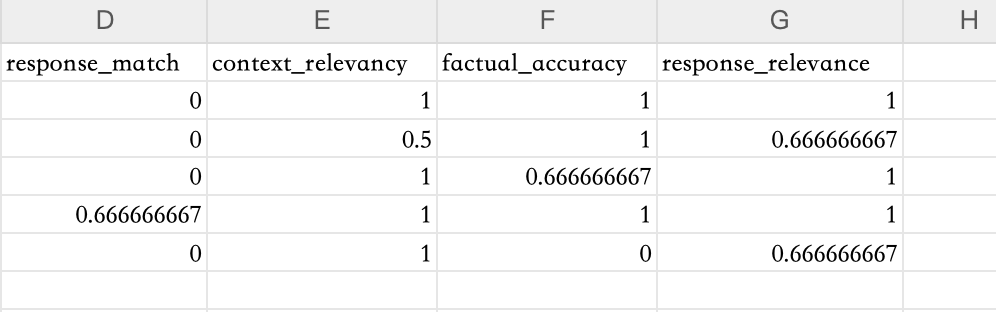
The results of Response Matching in UpTrain seem to be inaccurate. In fact, running the Response Matching evaluation metric will produce three scores: score_response_match, score_response_match_recall, and score_response_match_recall. However, even if the Answer is similar to the Ground Truth, these scores can sometimes be 0. The reason for this issue is unclear; if anyone knows, feel free to leave a comment.
Comparative Analysis
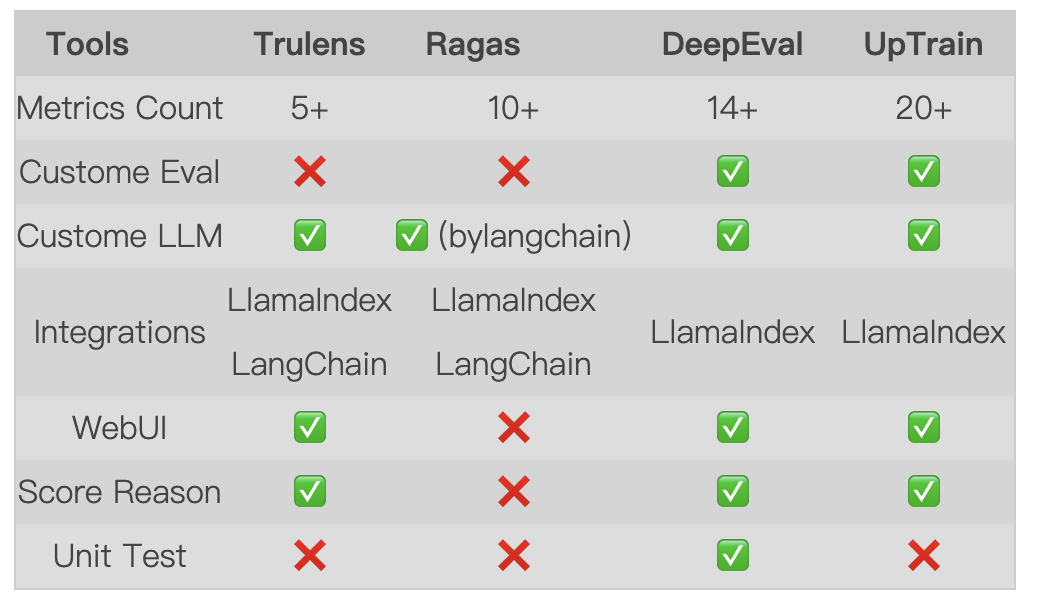
-
Evaluation Metrics: TruLens’s evaluation metrics are relatively few; while DeepEval and UpTrain have more metrics, some of them are not used for RAG applications. Ragas’s evaluation metrics, while not many, cover all aspects of RAG applications.
-
Custom Evaluation: DeepEval and UpTrain support custom evaluation metrics, allowing evaluations based on actual needs. TruLens and Ragas do not support custom evaluation metrics.
-
Custom LLM: Most of these evaluation tools support custom LLMs. Ragas implements custom LLMs through LangChain.
-
Framework Integration: This mainly compares whether they support LlamaIndex and LangChain, the two mainstream LLM development frameworks. TruLens and Ragas support both frameworks, while DeepEval and UpTrain only support LlamaIndex.
-
WebUI: WebUI pages allow for easy viewing of evaluation results. Except for Ragas, other evaluation tools support WebUI, but Ragas can implement WebUI through third-party tools.
-
Score Reasons: Except for Ragas, other evaluation tools support generating reasons for scores. Ragas does not support this, but DeepEval can help Ragas generate score reasons.
-
Unit Testing: This feature is unique to DeepEval, allowing evaluation tasks to be run like unit tests, which other evaluation tools do not support.
TruLens and Ragas are relatively early RAG evaluation tools, while DeepEval and UpTrain are newcomers. They may have been developed inspired by TruLens and Ragas, thus improving and adding features in evaluation metrics and functionalities. However, TruLens and Ragas also have their own advantages, such as TruLens’s intuitive evaluation results and Ragas’s metrics being more suitable for RAG applications.
Conclusion
This article introduced RAG evaluation tools that can be integrated with LlamaIndex and compared them. These evaluation tools can help developers better understand and optimize RAG applications. In fact, there are other evaluation tools, such as the evaluation tools provided by LlamaIndex itself and Tonic Validate[11], but due to space limitations, they will not be introduced here. If you are unsure which evaluation tool to choose, I recommend starting with one and using it in an actual project. If it turns out unsuitable, you can try other evaluation tools.
Follow me to learn about various AI and AIGC new technologies, and feel free to communicate. If you have any questions or comments, welcome to leave them in the comment section.
References:
The Avengers: https://en.wikipedia.org/wiki/Avenger
[2]
LlamaIndex: https://www.llamaindex.ai/
[3]
TruLens: https://www.trulens.org/
[5]
Ragas: https://github.com/explodinggradients/ragas
[6]
Example of integrating LlamaIndex: https://docs.ragas.io/en/latest/howtos/integrations/llamaindex.html
[7]
DeepEval: https://github.com/confident-ai/deepeval
[8]
Related papers: https://arxiv.org/abs/2303.16634
[9]
Confident: https://app.confident-ai.com/
[10]
UpTrain: https://github.com/uptrain-ai/uptrain
[11]
Tonic Validate: https://github.com/TonicAI/tonic_validate