
First, we need to clarify that we require two types of models:
-
LLM, which is the large model responsible for generating content.
-
Embedding model, which is responsible for generating embeddings that represent text semantics in vector form.
Set Up OpenAI API Key
By default, LlamaIndex uses OpenAI’s LLM and embedding models, so we first need to have an OpenAI API key:
import os
os.environ["OPENAI_API_BASE"] = "https://example.com/v1"
os.environ["OPENAI_API_KEY"] = "sk-example-key"Load Data and Build Index
Now, we can load the document dataset and build an index from it:
from llama_index.core import ( VectorStoreIndex, SimpleDirectoryReader,)
documents = SimpleDirectoryReader("./data").load_data()
index = VectorStoreIndex.from_documents(documents)SimpleDirectoryReader can directly scan all documents in the specified directory.
Our directory structure is as follows:
Query the Index
Now we can generate a query engine on the built index, and then we can use the query engine to ask questions:

Is This Answer Correct?
Since there is only “Brief History of China’s Space Development” in the data directory, all the questions we ask will try to find answers from “Brief History of China’s Space Development”. Let’s take a look at this excerpt from the original text:

We can see that the answer is correct. The LLM uses the question we asked and the retrieved information to perform a bit of reasoning to generate the answer.
If there wasn’t any retrieved information, the response from OpenAI’s ChatGPT 3.5 would be as follows:

Want to See the Query Process Logs?
Then you need to add the following at the beginning of your code file:
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))When the log level is set to logging.INFO, the printed logs will be less.
Save the Index
The index is actually a series of embedding vectors that represent text semantics, and these vectors are currently in memory. We can save the index to disk:
index.storage_context.persist(persist_dir="./storage")
After executing, you will see that a storage directory has been created.
Now we can improve our code:
-
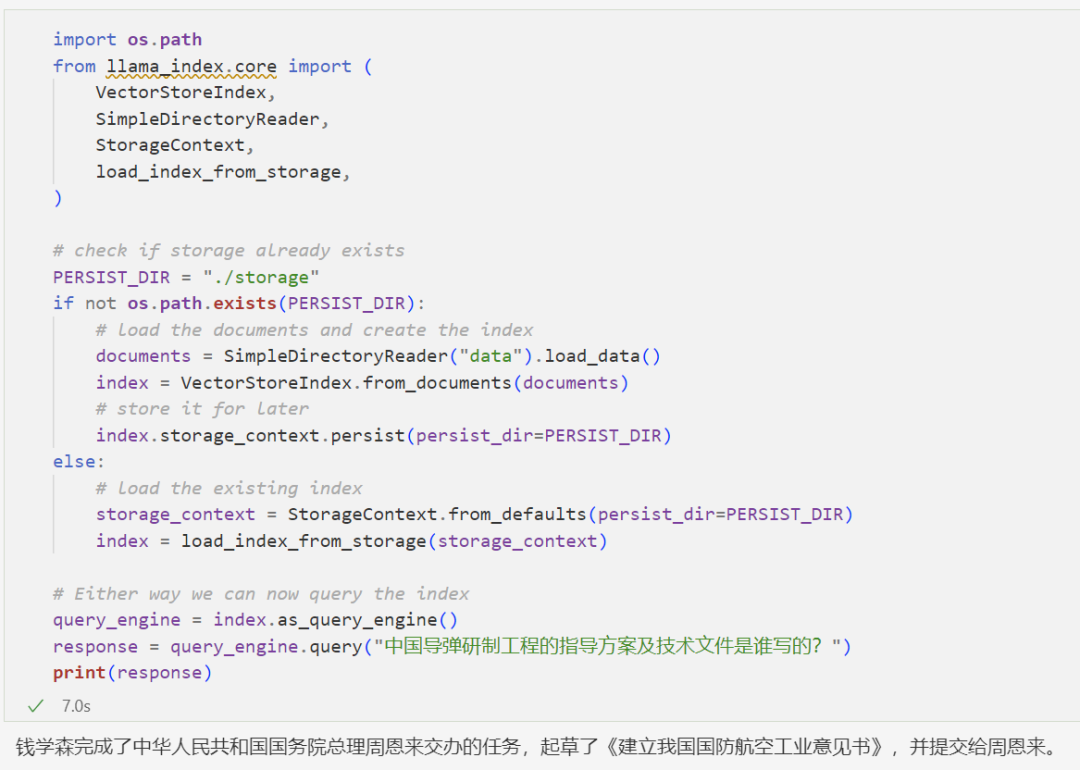
If the index is not on disk, then load the data, build the index, and save the index to disk.
-
Otherwise, directly load the index from disk, saving the time to generate the index and the token cost of calling OpenAI’s embedding model.
Using Local Models
Due to costs, network environment, data privacy, etc., we need to use open-source models. Now we will replace the default embedding model and LLM with BGE’s and the Chinese version of Meta’s open-source Llama2-chat-13B:
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.llama_cpp import LlamaCPP
from llama_index.core import Settings
embed_model = HuggingFaceEmbedding( model_name="../models/BAAI/bge-large-zh-v1.5", query_instruction="Generate a representation for this sentence to retrieve related articles:")
Settings.embed_model = embed_model
llm = LlamaCPP( model_path="../models/Llama/chinese-alpaca-2-13b-q8_0.gguf")
Settings.llm = llmAnd set the global embedding model and LLM through Settings.
Then rebuild the index and ask questions.
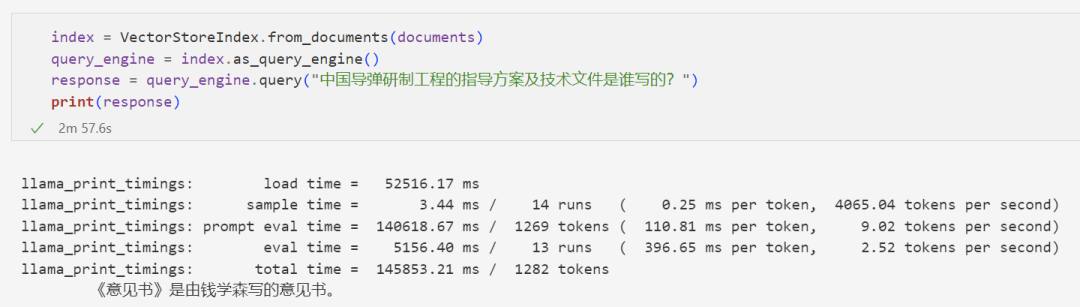
Although the response is not great, it is still correct.
Note! To run the Llama2 13B model locally, you need at least 32GB of memory. As for the GPU, it doesn’t matter; if you have one, it will be faster; if not, it will be slower.
Source Code
https://github.com/realyinchen/LlamaIndex/quick_start.ipynb