
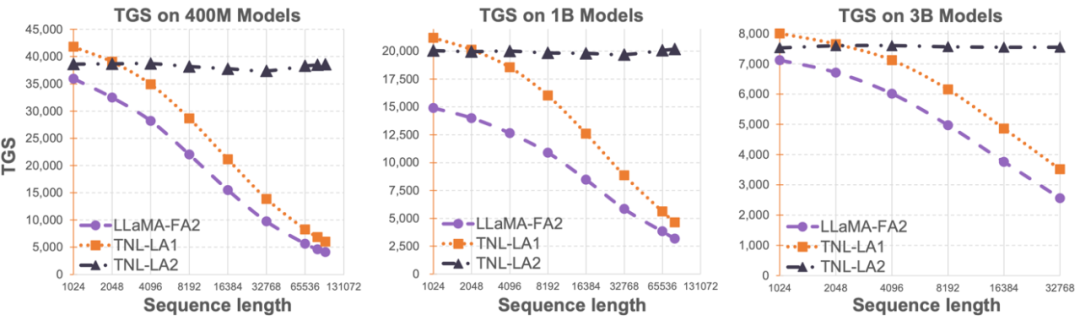
Lightning Attention-2 is a novel linear attention mechanism that aligns the training and inference costs of long sequences with those of a 1K sequence length.

-
Paper: Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models -
Paper Link: https://arxiv.org/pdf/2401.04658.pdf -
Open Source Link: https://github.com/OpenNLPLab/lightning-attention
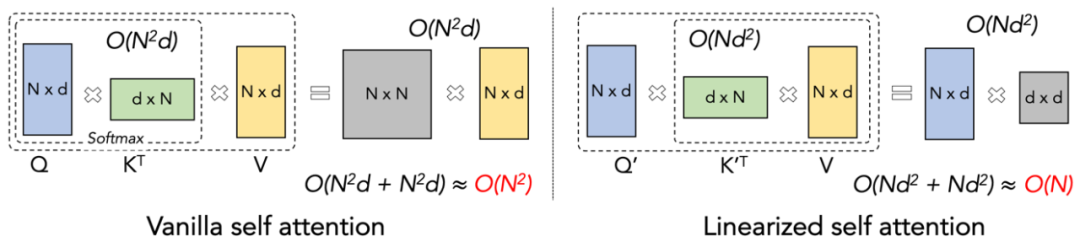
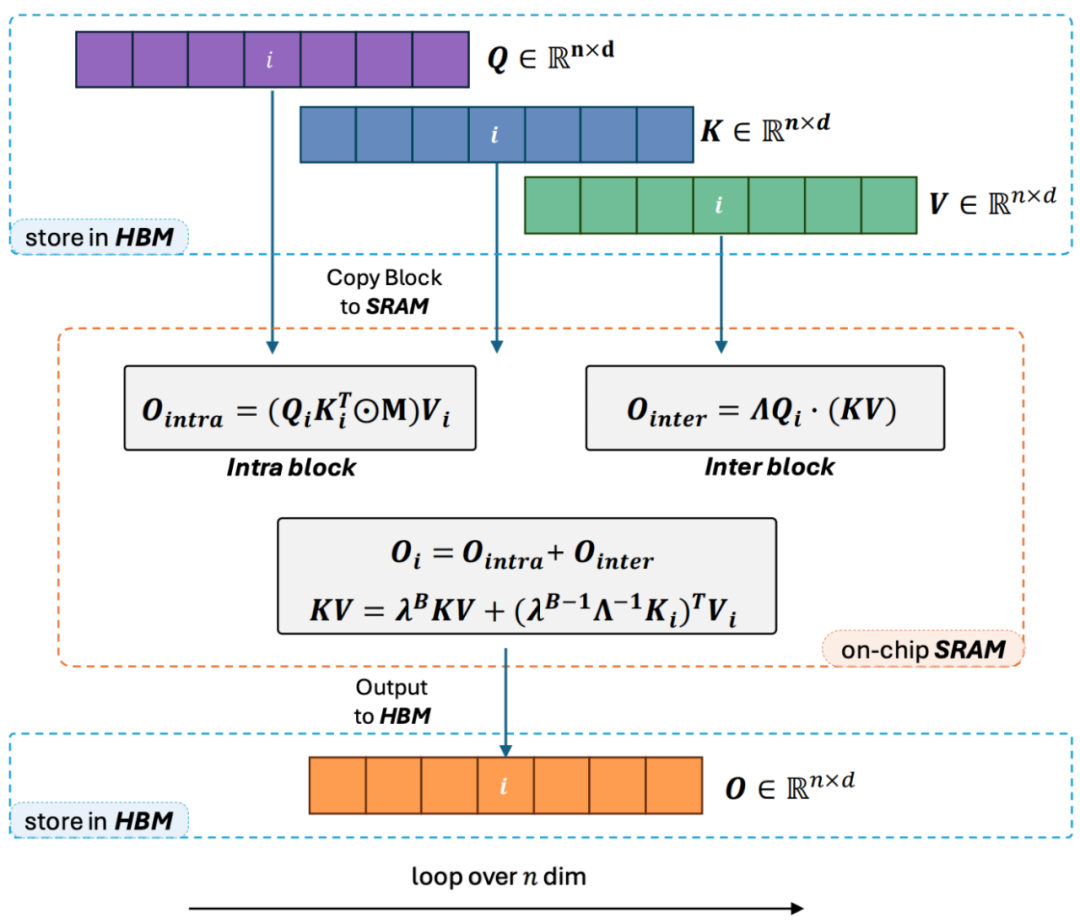
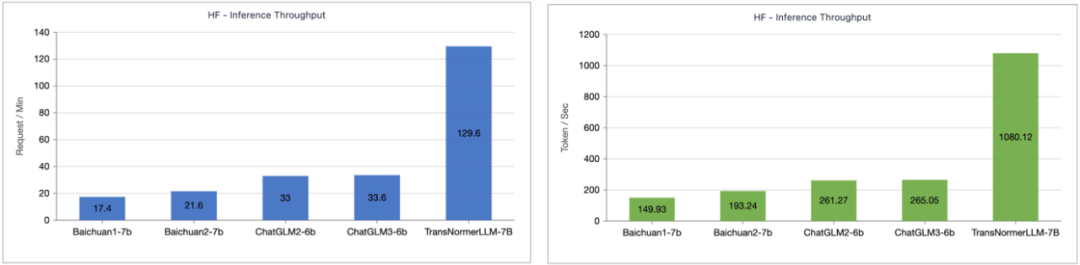


Source: Machine Heart
More AI and Human-Computer Interaction
Welcome to join the discussion group
Scan to add assistant WeChat
Note: “Add XR group,” to join the discussion group

For academic exchange only, if infringement, please leave a message, immediate deletion!
