GiantPandaCV Introduction: This series has not been updated for several months, and we will continue to explore the papers in this direction. In 2019 and 2020, many studies on Attention emerged. This paper, SA-Net: Shuffle Attention for Deep Convolutional Neural Networks, published in ICASSP 21, inherits the design concept of SGE while introducing Channel Shuffle, achieving good results backed by evidence.
1. Abstract
The attention mechanism can currently be divided into two categories: spatial attention mechanism and channel attention mechanism. Their goals are to capture pixel-level relationships and inter-channel dependencies. Using both attention mechanisms simultaneously can achieve better results, but inevitably increases the computational load of the model.
This paper proposes the Shuffle Attention (SA) module to address this issue, efficiently combining both attention mechanisms. Specifically:
-
SA groups channel features to obtain sub-features from multiple groups. -
Each sub-feature uses the SA Unit to apply both spatial and channel attention mechanisms. -
Finally, all sub-features are aggregated, and a Channel Shuffle operation is applied to fuse features from different groups.
Experimental Results: On the ImageNet-1k dataset, the SA results exceed ResNet50’s top-1 accuracy by 1.34%. Additionally, experiments on the MS COCO dataset for object detection and segmentation achieved SOTA with relatively low model complexity.
The experimental approach is reminiscent of SENet, where the idea of grouped processing was mentioned in SGE. SA-Net incorporates the Channel Shuffle operation, referencing ShuffleNet series papers, which is well-founded and straightforward to implement.
2. Design Philosophy
Multi-branch Structure
Multi-branch structures, such as the original InceptionNet series and ResNet series, follow the ‘Split – Transform – Merge’ operational pattern, allowing models to become deeper and easier to train.
Many works in the design of attention modules have also introduced multi-branch structures, such as SKNet, ResNeSt, SGENet, etc.
Grouped Features
The initial division of features into different groups can be traced back to AlexNet. Due to limited GPU memory at the time, the model had to be split into two groups, each processed on a separate GPU, to address the issue of using more computational resources.
Subsequent models like MobileNet and ShuffleNet series utilized grouped features to reduce computational load and accelerate processing speed.
CapsuleNet treats the neurons in each group as a capsule, where the activated neurons represent various attributes of specific entities in the image.
Attention Mechanism
The attention module has become an essential component that must be considered in network design. It selectively focuses on useful feature information while suppressing unimportant features. The self-attention method computes a weight based on a position and its contextual information, applied across the entire image. SE models inter-channel relationships using two fully connected networks for self-learning. ECA employs 1-D convolution to generate inter-channel attention, reducing the computational load of SE. Models like CBAM, GCNet, and SGE combine spatial and channel attention mechanisms. DANet adaptively integrates local features and their global dependencies by summing two attention modules from different branches.
3. Shuffle Attention
The design philosophy of SA combines grouped convolution (to reduce computational load), spatial attention mechanism (implemented using GN), channel attention mechanism (similar to SENet), and ShuffleNetV2 (using Channel Shuffle to merge information between different groups).
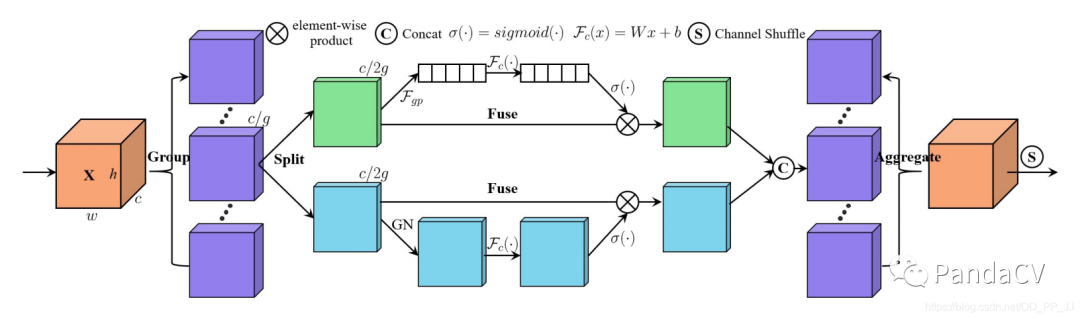
As shown in the figure above:
-
First, the tensor is divided into g groups, with the SA Unit processing each group. -
The internal SA uses a spatial attention mechanism, as indicated by the blue part, specifically implemented using GN. -
The internal channel attention mechanism of SA, as indicated by the green part, is similar to SE. -
The SA Unit fuses information within the group using concatenation. -
Finally, a Channel Shuffle operation rearranges the groups, facilitating information flow between different groups.
Spatial Attention Implemented with GN
Generally, the role of the spatial attention mechanism is to identify which specific part of the image is more important. In SA, GroupNorm is used to obtain information from the spatial dimension. This part is quite unique, but the author has demonstrated the effectiveness of this module through ablation experiments. Perhaps there are better spatial attention mechanisms? After all, there is no comparative method like CBAM’s spatial attention, so it is unclear whether GN as spatial attention has advantages.


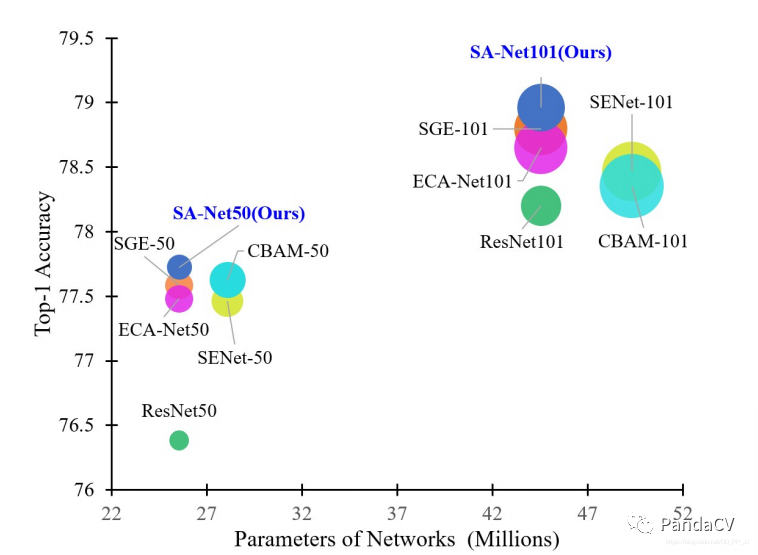
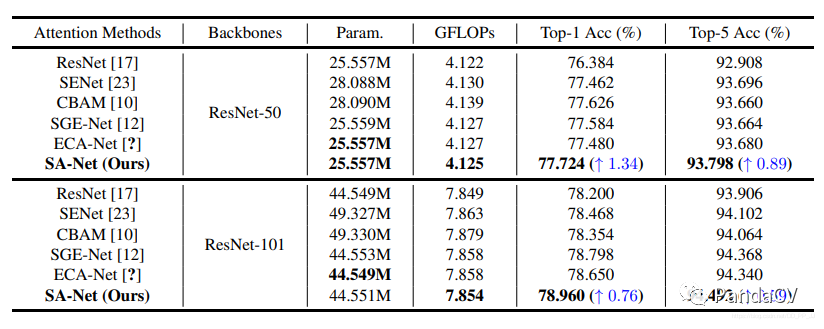
4. Experimental Results
It can be seen that it performs better than models like ECA-Net, exceeding the baseline ResNet50’s top-1 accuracy by 1.34%. Similarly, adding the SA module to ResNet-101 also results in a top-1 accuracy increase of 0.76% over the baseline.
Comparison of experimental results in object detection:
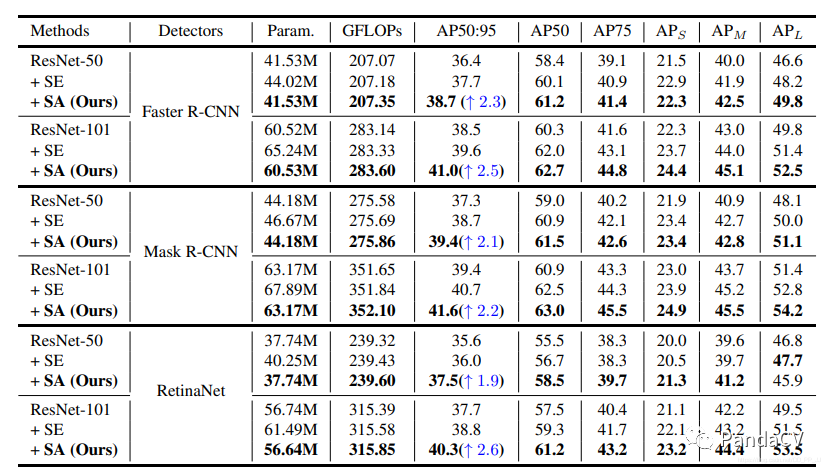
It can be seen that the experimental improvement is significant, with an AP increase of about 2-3 percentage points.
Comparison of experimental results in instance segmentation tasks:
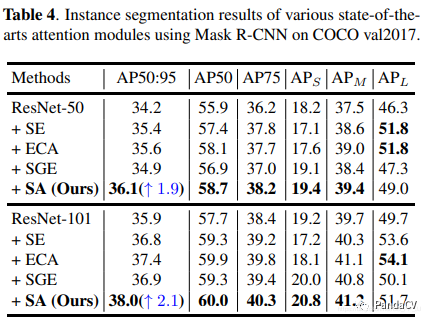
5. Conclusion
The core idea of SA is traceable, introducing grouped convolution to reduce computational load, then applying spatial and channel attention to each group, and finally using Channel Shuffle operation to facilitate information flow between different groups.
6. References
Code link: https://github.com/wofmanaf/SA-Net
Paper link: https://arxiv.org/pdf/2102.00240.pdf
If you have questions about the article or want to join the discussion group, you can add the author’s WeChat and specify your intention.
