Paper Title:
Inverted Transformers are Effective for Time Series Forecasting
Authors:
Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, Mingsheng Long
Compiler: Sienna
Reviewer: Los
Introduction:
iTransformer is the latest research achievement in the field of time series forecasting in 2024, currently demonstrating the best performance (SOTA) on standard time series forecasting datasets. The core innovation of iTransformer lies in the application and transposition design of the classic Transformer architecture.©️【Deep Blue AI】compiled

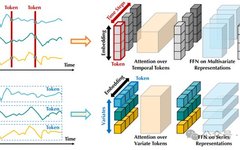
Recently, linear prediction models have flourished, leading to a decrease in enthusiasm for modifying transformer predictor architectures. As shown in Figure 1, these predictors utilize transformers to model global dependencies of time tokens in time series, where each token consists of multiple variants from the same timestamp. However, due to performance degradation and computational explosion, transformers face challenges when predicting sequences with large backtracking windows. Furthermore, the embedding of each time token integrates multiple variables representing potential delayed events and different physical measurements, which may fail to learn variable-centered representations and lead to meaningless attention maps. Specifically:
● Points at the same time essentially represent completely different physical meanings, recorded by inconsistent measurements, which are embedded into one token, erasing multivariate correlations;
● Due to the excessive number of local receptive fields and temporally inconsistent events represented at the same timestamp, tokens formed at a single time step struggle to reveal useful information;
● Even though sequence variations can be significantly influenced by the sequence order, the attention mechanism does not appropriately adopt a permutation-invariant approach in the temporal dimension;
Therefore, the ability of Transformers to capture fundamental sequence representations and characterize multivariate correlations is weak, limiting their processing capacity and generalization ability for different time series data.
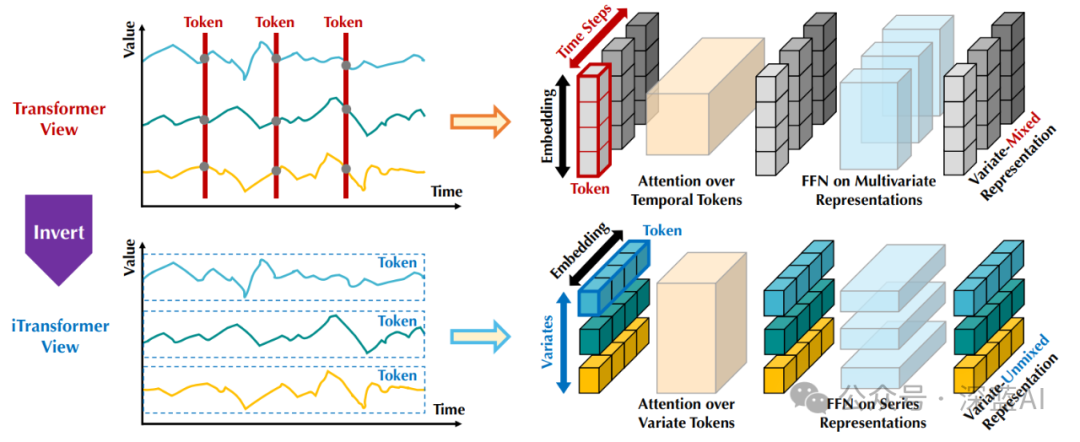
▲Figure 1 | Comparison between traditional transformers (top) and the proposed iTransformer (bottom). The Transformer embeds time tokens containing multivariate representations for each time step. iTransformer independently embeds each sequence into variable tokens, allowing the attention module to describe multivariate correlations while the feedforward network encodes sequence representations ©️【Deep Blue AI】compiled
In this work, the authors reflect on the roles of Transformer components and reuse the Transformer architecture without modifying the fundamental components. As shown in the lower part of Figure 1, the proposed iTransformer only applies attention and feedforward networks in the transposed dimensions. Specifically, the time points of a single sequence are embedded into variable tokens, and the attention mechanism utilizes these tokens to capture multivariate correlations; simultaneously, the feedforward network is applied to each variable token to learn nonlinear representations. Through experiments, iTransformer achieves comprehensive SOTA in multivariate prediction tasks.
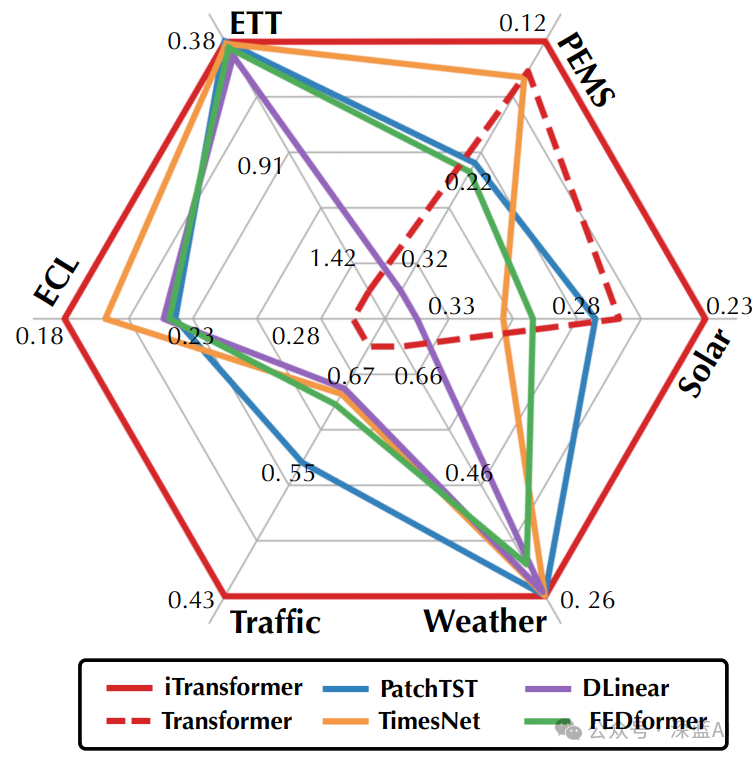
▲Figure 2 | Average results (MSE) across multiple datasets ©️【Deep Blue AI】compiled

In multivariate time series forecasting, given historical observation data, there are time steps and variables, predicting the future time steps. For convenience, represents the time points recorded simultaneously at the step, and represents the entire time series for each variable indexed by . Notably, due to systematic time delays between variables in the dataset, may not reflect the same events in the real world at a certain time point. Moreover, the elements in may differ from each other in physical measurements and statistical distributions, while the variable typically shares with them.
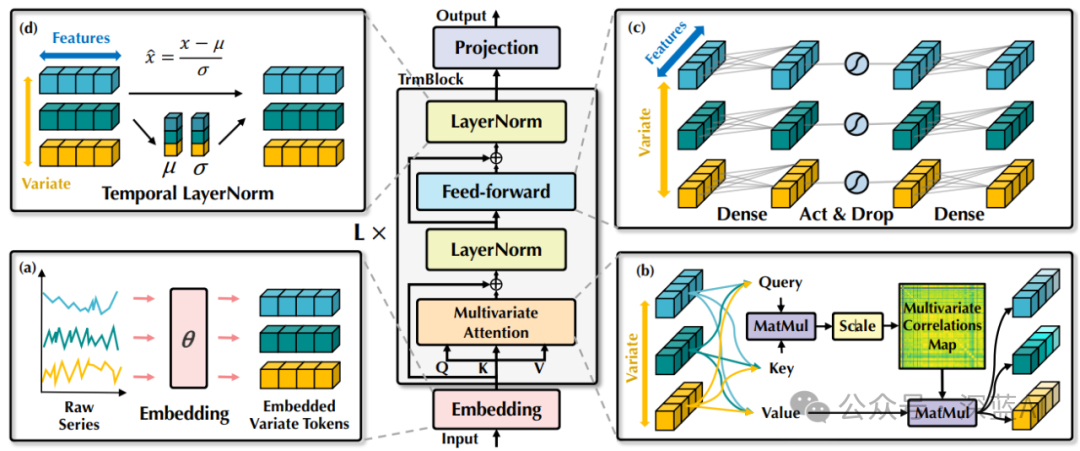
The structure of iTransformer is shown in Figure 3, which adopts a pure encoder architecture of Transformer, including embedding, projection, and Transformer modules:
▲Figure 3 | Overall structure of iTransformer, which has the same module arrangement as the Transformer encoder. (a) Original sequences of different variables are independently embedded as tokens. (b) Self-attention is applied to the embedded variable tokens to enhance interpretability and reveal multivariate correlations. (c) A shared feedforward network extracts sequence representations for each token. (d) Layer normalization is applied to reduce differences between variables ©️【Deep Blue AI】compiled
■2.1 Complete Sequence Embedded as Tokens
Based on the above considerations, in iTransformer, the process of predicting the future sequence of each specific variable based on the backtracked sequence is simply stated as follows:
← Swipe left and right to view the complete formula →
where the embedded tokens contain dimensions, and the superscript indicates the layer index. Embedding: and Projection: are implemented by multilayer perceptrons (MLP). The obtained variable tokens influence each other through self-attention and are independently processed by the shared feedforward network in each TrmBlock. Specifically, since the order of the sequence is implicitly stored in the arrangement of neurons in the feedforward network, there is no longer a need for position embeddings in the original Transformer.
■2.2 Components of iTransformers
As shown in Figure 3, iTransformers are composed of stacked modules consisting of layer normalization, feedforward networks, and self-attention modules.
In typical transformer-based predictors, this module normalizes the multivariate representations at the same time point, causing gradual fusion between variables. Once the collected time points do not represent the same event, this operation also introduces interaction noise between non-causal or delayed processes. In our transposed version, normalization is applied to the sequence representation of individual variables, as shown in formula 2:
← Swipe left and right to view the complete formula →
The Transformer employs a feedforward network (FFN) as the fundamental component for token encoding and encodes each token in the same way. In ordinary transformers, multiple variables constituting the same time point of a token may be misaligned and overly localized, failing to provide sufficient information for prediction. In the transposed version, the FFN utilizes the sequence representation of each variable token. According to the universal approximation theorem, they can extract complex representations to describe time series. By stacking transposed modules, the observed time series is encoded, and dense nonlinear connections are used to decode the representations of future sequences, which is as effective as recent works based on MLP.
Recent re-examinations of linear prediction emphasize that the temporal features extracted by MLP can be shared across different time series. This paper proposes a reasonable explanation that the neurons of the MLP are trained to depict the intrinsic properties of any time series, such as amplitude, periodicity, and even-frequency spectrum (neurons as filters), which is a more effective predictive representation learner compared to self-attention applied to time points.
Previous predictions often use the attention mechanism to facilitate modeling of temporal dependencies, while the transposed model treats the entire univariate sequence as an independent process. Specifically, for each time series, the self-attention module obtains queries, keys, and values through linear projection, where is the projection dimension. The specific query and key of a (variable) token are expressed before softmax scoring. Since each token has been normalized in its feature dimension, each score can reveal the correlation between variables to some extent, and the entire score map displays the multivariate correlations between paired variable tokens. Based on this intuition, the proposed mechanism can be considered more natural and interpretable for multivariate sequence prediction.
The pseudocode for iTransformer is shown below:
▲Figure 4 | Pseudocode of iTransformer ©️【Deep Blue AI】compiled
■3.1 Main Results of Multivariate Prediction
This paper evaluates iTransformer on a large number of challenging multivariate prediction benchmarks and the server load prediction of online transactions on Alipay (typically involving hundreds of variables, denoted as Dim). iTransformer performs particularly well in predicting high-dimensional time series.
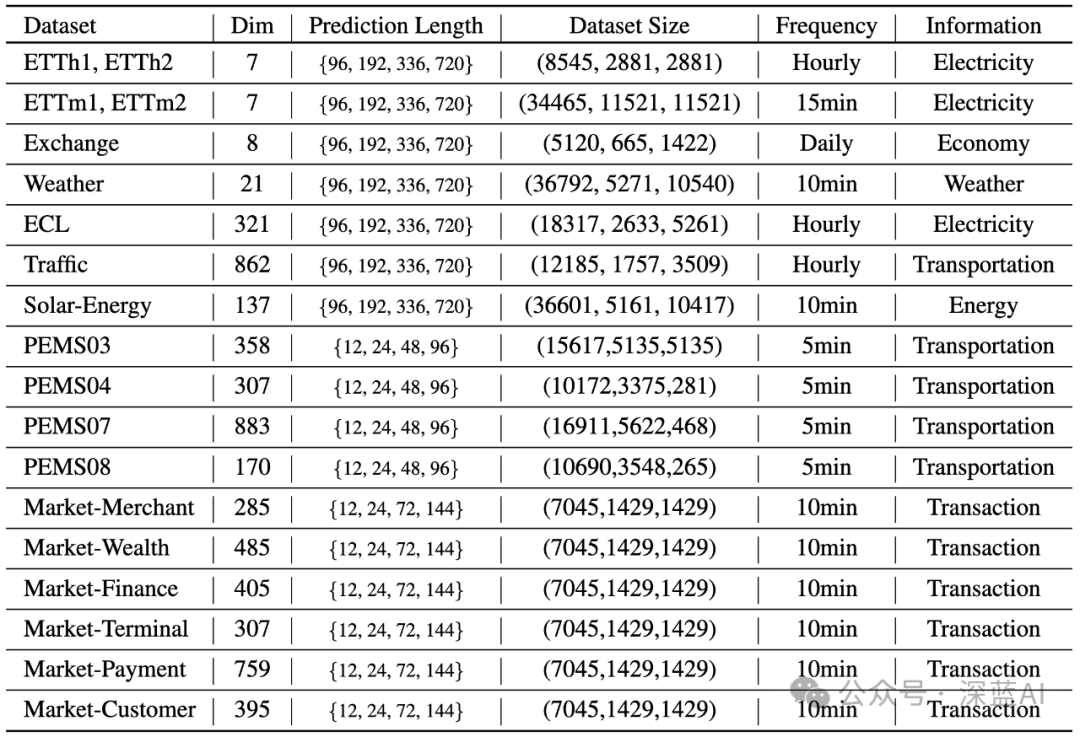
▲Table 1 | Detailed description of datasets. Dim denotes the number of variables in each dataset; Dataset Size represents the total number of time points split into (training, validation, testing); Prediction Length indicates the future time points to be predicted, with four prediction settings in each dataset; frequency denotes the sampling interval of time points ©️【Deep Blue AI】compiled
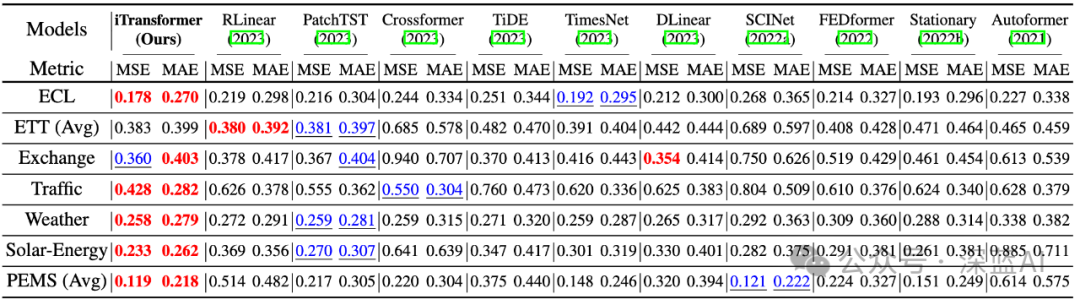
▲Table 2 | Multivariate time series prediction benchmarks (average results), with red and blue indicating optimal and suboptimal results respectively ©️【Deep Blue AI】compiled
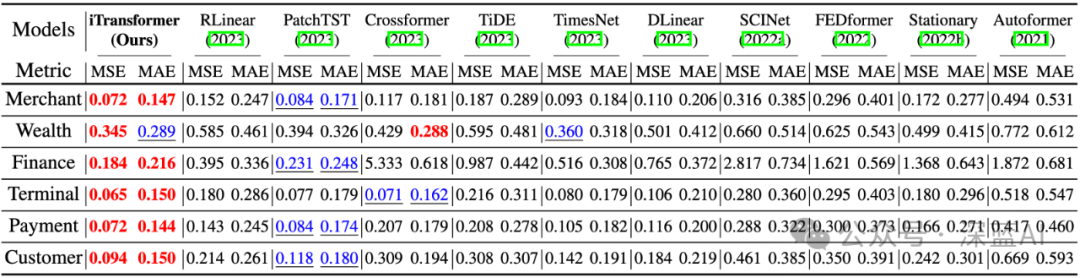
▲Table 3 | Online transaction load prediction on Alipay (average results), with red and blue indicating optimal and suboptimal results respectively ©️【Deep Blue AI】compiled
■3.2 General Performance Improvement of Transformer
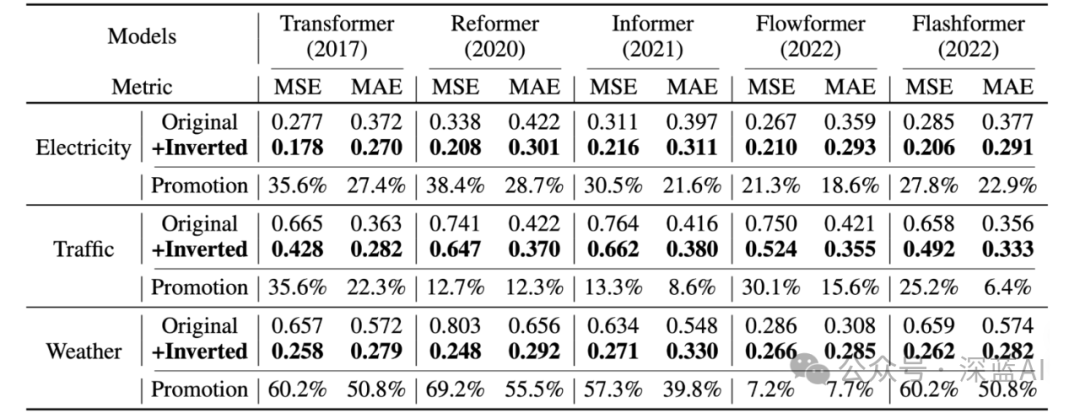
By introducing the proposed framework, the performance of Transformers and their variants has significantly improved, demonstrating the versatility of the iTransformer method and the effectiveness of efficient attention mechanisms.
▲Table 4 | Performance improvements obtained by the proposed transposed framework, including average performance and relative MSE reduction (improvement) ©️【Deep Blue AI】compiled
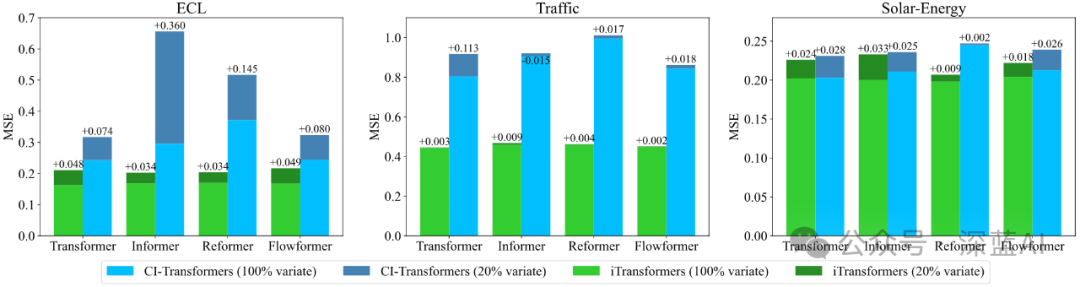
■3.3 Generalization to Unseen Variables
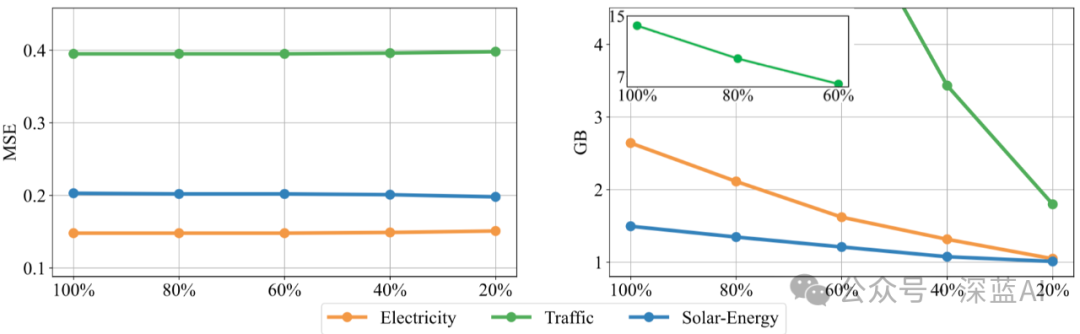
Technically, iTransformer can use any number of variables for prediction during inference. We divided the variables of each dataset into five blocks, training the model with 20% of the variables, and predicting all variables with the partially trained model.
▲Generalization performance for unseen variables ©️【Deep Blue AI】compiled
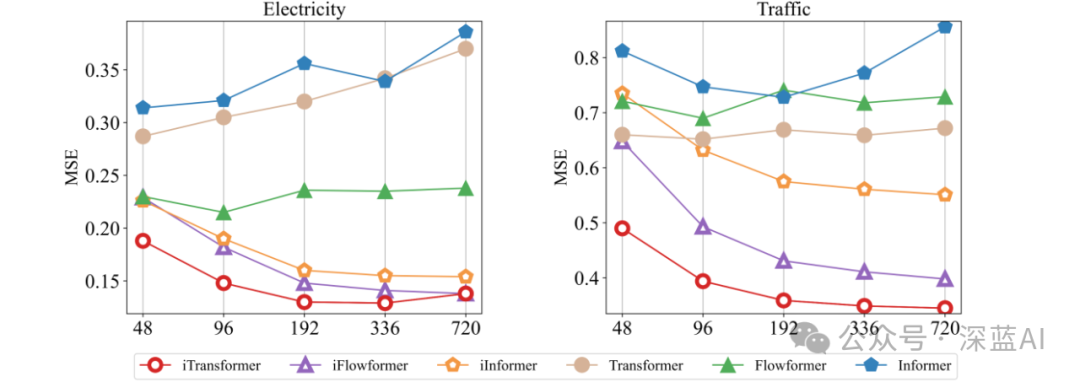
■3.3 Better Utilization of Backtracking Windows
As the length of the backtracking window increases, the predictive performance of iTransformers has significantly improved.
▲Figure 6 | Predictive performance with increasing backtracking length and fixed prediction length. Although the performance of transformer-based predictors may not necessarily benefit from an increase in backtracking length, the transposed framework enhances the performance of the original transformer and its variants when expanding the backtracking window ©️【Deep Blue AI】compiled
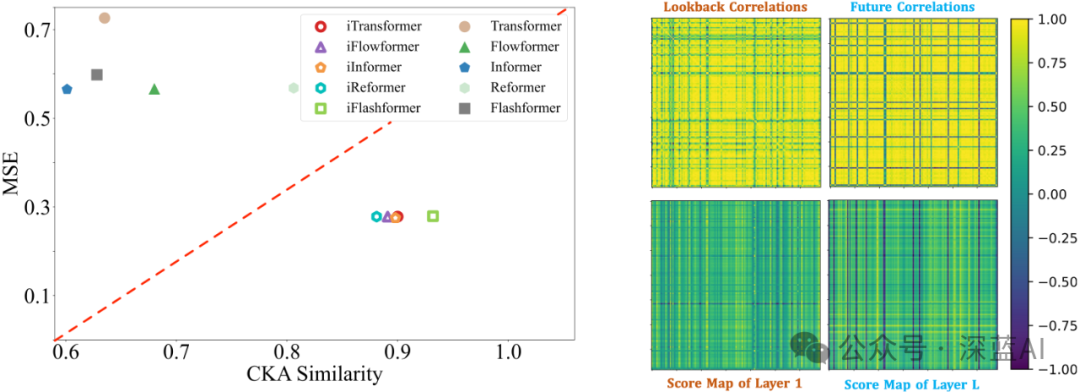
● Thanks to the transposed transformer module: As shown in the left of Figure 7, the transposed transformer learns better time series representations;
● As shown in the right of Figure 7: The transposed self-attention module learns interpretable multivariate correlations.
▲Figure 7 | Sequence representation and multivariate correlation analysis. Left: Comparison of MSE and CKAs similarity between Transformers and iTransformers. Higher CKAs similarity indicates more favorable accurate predictions; Right: Visualization of multivariate correlation cases learned through transposed self-attention compared to the original time series ©️【Deep Blue AI】compiled
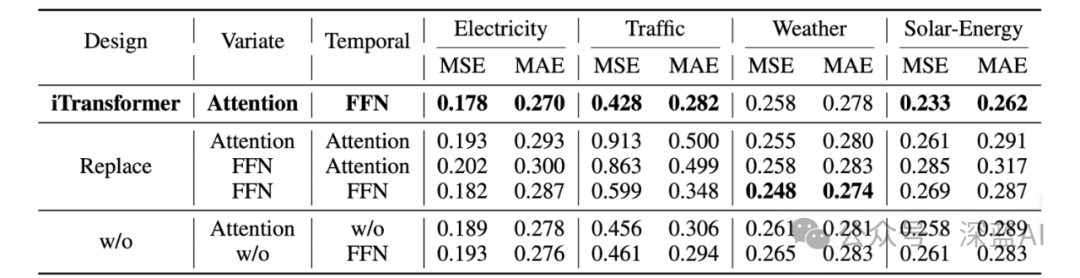
■3.4 Model Ablation
Utilizing attention in the variable dimension and feedforward in the temporal dimension yields the best performance for iTransformer. Among these designs, the performance of the original Transformer (third row) is the worst, indicating that the traditional architecture does not match the responsibilities of this task.
▲Table 5 | Ablation on iTransformer. We replace different components in their respective dimensions to learn multivariate correlations (Variate) and sequence representations (Temporal), listing the average results for all prediction lengths ©️【Deep Blue AI】compiled
■3.5 Model Efficiency
This paper proposes a multivariate sequence training strategy utilizing the variable generation capability of multivariate sequences. Although the performance of partially trained variables per batch (left) remains stable with sampling rates, the memory consumption during the training process (right) can be significantly reduced.
▲Analysis of efficient training strategy. While the performance on partially trained variables at different sampling ratios (left) remains stable, memory consumption (right) can be significantly reduced ©️【Deep Blue AI】compiled

This paper reflects on the architecture of Transformers, discovering that the original components of Transformer have not been fully developed in the context of multivariate time series. Therefore, the authors propose iTransformer, treating independent time series as tokens, capturing multivariate correlations through self-attention, and employing layer normalization and feedforward network modules to learn better global representations for time series prediction. Through experiments, iTransformer achieves comprehensive SOTA in real-world benchmark tests. This paper extensively analyzes the transposed module and architectural choices, providing directions for future improvements of Transformer-based predictors.
●●●
Author’s Tip:
This paper only uses the encoder for embedding, with the predicted data generated by the feedforward network. No decoder receiving the target sequence is used. In practical applications of time series, it can be found that using a decoder with the target sequence can lead to many issues. Personally, I believe that the simplified decoder used in this paper is expected to alleviate these troubles.

Latest Model VMamba: Disrupting Visual Transformers, The Next Generation Mainstream Backbone?
2024-02-03
Apple’s Autoregressive Visual Model AIM: Examining the Impact of Parameter Count on the Development of Visual Models
2024-01-24

【Deep Blue AI】is recruiting authors, welcoming anyone who wants to transform their scientific and technical experiences into writing to share with more readers for exchange. If you want to join, please click the tweet below for details👇
Deep Blue Academy’s Author Team is actively recruiting! Looking forward to your joining
【Deep Blue AI】‘s original content is created with personal dedication by the author team. We hope everyone follows the original rules and cherishes the authors’ labor. For reprints, please privately message for authorization, and when publishing, be sure to indicate it comes from【Deep Blue AI】WeChat official account, otherwise legal action will be taken for infringement.
*Click to view, collect, and recommend this article*