
Click the above “Beginner’s Visual Learning” to choose to add “Star” or “Top”
Heavyweight content delivered first time

Transformers have rapidly gained popularity in the field of computer vision, particularly in object recognition and detection. After reviewing the results of state-of-the-art object detection methods, we noticed that Transformers outperform mature CNN-based detectors on almost every video or image dataset. Although Transformer-based methods are still at the forefront of small object detection (SOD) technology, this article aims to explore the performance advantages offered by this extensive network and identify the potential reasons for its SOD advantages. Due to the low visibility of small objects, they have been identified as one of the most challenging object types in detection frameworks. We aim to investigate potential strategies that could enhance the performance of Transformers in SOD. This review presents a classification of over 60 studies on Transformer-based SOD tasks, spanning from 2020 to 2023. These studies cover various detection applications, including general images, aerial images, medical images, active millimeter images, underwater images, and small object detection in videos. We have also compiled and listed 12 large-scale datasets suitable for SOD that have been overlooked in previous research, and compared the performance of the reviewed studies using popular metrics (such as mean average precision (mAP), frames per second (FPS), number of parameters, etc.).

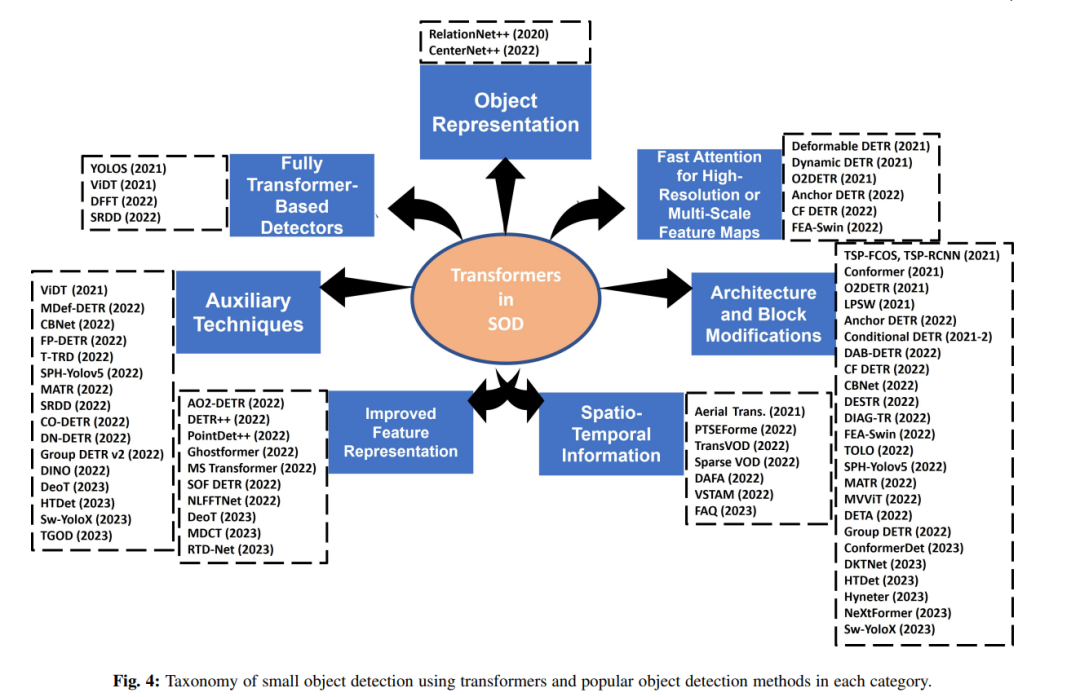
Small object detection (SOD) has been recognized as a significant challenge facing current state-of-the-art object detection methods (SOTA) [1]. “Small objects” refer to objects that occupy a small portion of the input image. For example, in the widely used MS COCO dataset [2], it is defined as objects with bounding boxes of 32 × 32 pixels or smaller in a typical 480 × 640 image (Figure 1). Other datasets have their definitions as well, such as objects occupying 10% of the image. Small objects are often missed or detected with incorrect bounding boxes, sometimes even with incorrect labels. The primary reason for under-localization in SOD is the limited information provided in the input image or video frame, which exacerbates the spatial degradation they experience through multiple layers in deep networks. Since small objects frequently appear in various application areas, such as pedestrian detection [3], medical image analysis [4], facial recognition [5], traffic sign detection [6], traffic light detection [7], ship detection [8], and target detection based on synthetic aperture radar (SAR) [9], it is worthwhile to study the performance of modern deep learning SOD techniques. This article compares the performance of Transformer-based detectors and CNN-based detectors in small object detection. In cases where Transformers significantly outperform CNNs, we attempt to unveil the reasons behind the strong performance of Transformers. A direct explanation may be that Transformers model the interactions between paired positions in the input image. This is an effective way of contextual encoding. Moreover, it is well-known that context is a major source of information for humans and computational models when detecting and recognizing small objects [10]. However, this may not be the only factor explaining the success of Transformers. Specifically, our goal is to analyze this success along several dimensions, including object representation, fast attention on high-resolution or multi-scale feature maps, fully Transformer-based detection, architecture and block modifications, auxiliary techniques, improved feature representation, and spatiotemporal information. Additionally, we point out potential methods to enhance the performance of Transformers in SOD.
In our previous work, we investigated many strategies used in deep learning to improve the performance of small object detection in optical images and videos up to 2022 [11]. We demonstrated that, in addition to adapting to new deep learning structures (such as Transformers), popular methods include data augmentation, super-resolution, multi-scale feature learning, context learning, attention-based learning, region proposals, loss function regularization, leveraging auxiliary tasks, and spatiotemporal feature aggregation. Furthermore, we observed that Transformers are one of the primary methods for localizing small objects in most datasets. However, considering that [11] primarily evaluated over 160 papers focused on CNN-based networks, there has been no in-depth exploration of Transformer-centered methods. Recognizing the growth and exploratory pace in this field, there is now a timely window to delve into the current Transformer models aimed at small object detection. The goal of this article is to provide a comprehensive understanding of the contributing factors to the impressive performance of Transformers when applied to small object detection, and how they differ from strategies used for general object detection. To lay the groundwork, we first highlight the notable Transformer-based SOD detectors and compare their advancements with CNN-based methods.
Since 2017, many review articles have been published in this field. In our previous survey [11], these reviews were extensively discussed and listed. Another recent survey article [12] also primarily focuses on CNN-based techniques. The narrative of the current survey is distinctly different from previous ones. This article specifically narrows the focus to Transformers—an aspect that has not been explored before—positioning Transformers as the primary network architecture for image and video SOD. This requires a unique taxonomy tailored for this innovative architecture, consciously marginalizing CNN-based methods. Given the novelty and complexity of this topic, our review prioritizes works published after 2022. Additionally, we clarify the new datasets used for small object localization and detection in broader application areas. The main methods studied in this survey are those tailored for small object localization and classification or indirectly address the challenges of SOD. What drives our analysis is the detection results targeting small objects in these papers. However, early studies pointed out the results of SOD but either demonstrated below-standard performance or overlooked specific SOD parameters in the development methods, thus were not considered for inclusion in this review. In this survey, we assume that readers are already familiar with general object detection techniques, their architectures, and relevant performance metrics. If readers need a foundational understanding of these areas, we recommend referring to our previous work [11].
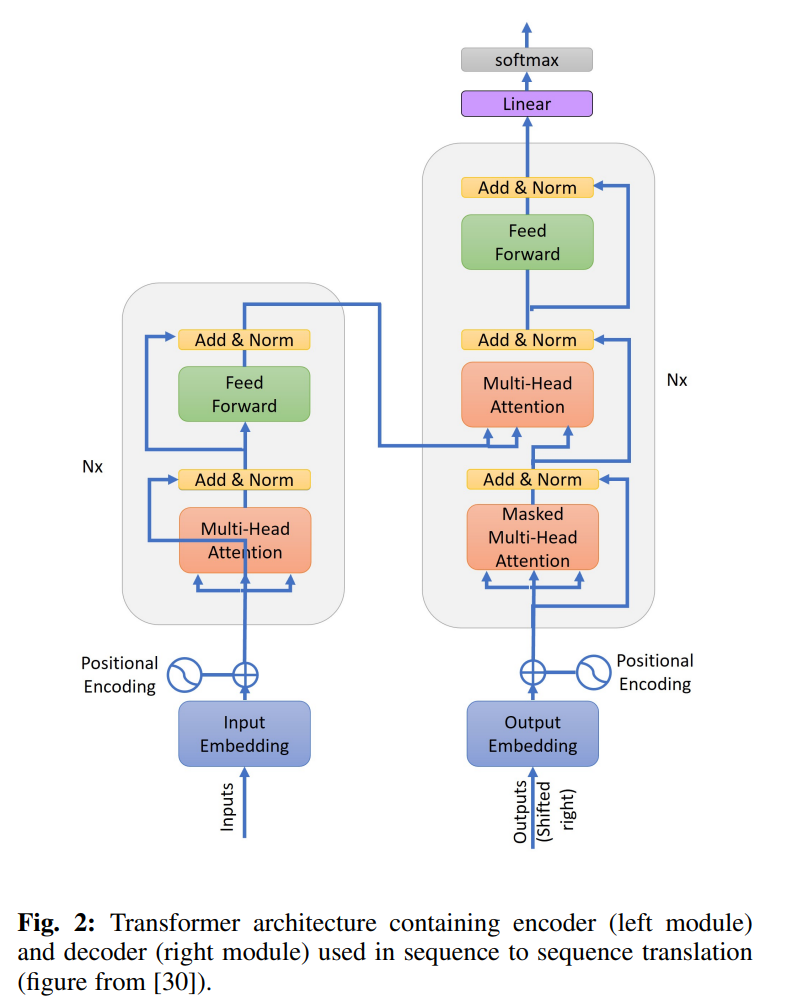
The structure of this article is as follows: Section 2 provides an overview of CNN-based object detectors, Transformers, and their components, including encoders and decoders. This section also discusses the two initial iterations of Transformer-based object detectors: DETR and ViT-FRCNN. In Section 3, we classify Transformer-based SOD techniques and conduct a comprehensive in-depth study of each category of techniques. Section 4 presents different datasets used for SOD and evaluates them across a range of applications. In Section 5, we analyze and compare these results with earlier results derived from CNN networks. This article concludes in Section 6.
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply: Extension Module Chinese Tutorial in the “Beginner's Visual Learning” public account backend to download the first OpenCV extension module tutorial in Chinese, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Visual Practical Project 52 Lectures
Reply: Python Visual Practical Project in the “Beginner's Visual Learning” public account backend to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply: OpenCV Practical Project 20 Lectures in the “Beginner's Visual Learning” public account backend to download 20 practical projects based on OpenCV, advancing OpenCV learning.
Discussion Group
Welcome to join the public account reader group to exchange ideas with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (which will gradually be subdivided). Please scan the WeChat number below to join the group, noting: “Nickname + School/Company + Research Direction”, for example: “Zhang San + Shanghai Jiao Tong University + Visual SLAM”. Please follow the format for remarks, otherwise, you will not be approved. After successful addition, you will be invited to relevant WeChat groups based on your research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group. Thank you for your understanding~