

Soviet mathematician Andrey N. Kolmogorov (1903-1987). Image source: https://wolffund.org.il/

Introduction:
This year’s May Day holiday saw attention drawn to a paper on machine learning posted on arXiv by MIT physicist Max Tegmark and his doctoral student Ziming Liu. They proposed a new framework called KAN (Kolmogorov-Arnold Network), claiming it outperforms multi-layer perceptrons (MLP) in both accuracy and interpretability.
Today, we will discuss the origins and developments of the Kolmogorov-Arnold Superposition Theorem. In a previous article titled “Figures | Solomonoff: The Prophet of Large Language Models,” I briefly introduced the other works of Kolmogorov (A. N. Kolmogorov, 1903-1987) and Arnold (Vladimir Arnold, 1937-2010).
The versatile Soviet mathematician Kolmogorov made two significant contributions to computer science. First, he independently developed the Solomonoff-Kolmogorov-Chaitin Theory alongside American mathematicians Solomonoff and Chaitin, which is becoming the theoretical foundation and explanatory tool for large language models. Kolmogorov’s student Leonid Levin (1948-) independently derived the result of NP-completeness in the early 1970s, and after 2000, this theorem, originally named after Cook, was often referred to as the Cook-Levin theorem in textbooks on computational theory. While Levin did not receive the Turing Award like Cook, he was compensated with the Knuth Award jointly awarded by ACM and IEEE.
Another important contribution of Kolmogorov has had a wide impact in the mathematical community but was appreciated by computer scientists and AI scholars only much later, despite the work being earlier. He and his student Vladimir Arnold jointly proved the representation theorem or superposition theorem between 1956 and 1957, which later became the theoretical foundation for neural networks. The mathematical guarantee for the revival of neural networks is the universal approximation theorem, which originates from the Kolmogorov-Arnold superposition. As with many of Kolmogorov’s works, he initially pointed the way and provided the outline for proof, which was then refined into a perfect sketch by his students.
Another significant work of Kolmogorov, the KAM theory, was also completed in collaboration with Arnold. Arnold shared the 2001 Wolf Prize with Israeli logician Saharon Shelah and the 2008 Shaw Prize with another Russian mathematician, Leonid Faddeev. Shing-Tung Yau fairly stated that under the leadership of Alexandrov and Kolmogorov, the Russian mathematical school was nearing the overall level of American mathematics at that time. The story of the Jewish mathematicians in this context is inspiring yet poignant.
Discussions triggered by large language models represented by ChatGPT have mainly focused on engineering issues such as data and computing power, while theoretical research has been less fervent. Large models pose new questions to computational theory, which can also help large models reveal first principles, thus finding boundaries and directions. When current theories cannot explain engineering practices, engineers may turn to history to seek insights from the thoughts of predecessors that have been overlooked, striving to provide directional insights for where to go.
Neural networks, inspired by the brain, began with the work of Warren McCulloch (1898-1969) and Walter Pitts (1923-1969) in 1943. One of the authors, Pitts, was a self-taught logician, while McCulloch, a neuropsychologist, was a mentor figure to Pitts. They proposed that neurons have a threshold, meaning that stimulation must exceed this threshold to generate a pulse. Although they did not cite Alan Turing and Alonzo Church in their papers from 1936-1937, they clearly stated that given infinite storage, their network could simulate λ-calculus and Turing machines.
Subsequent related research continued. Church’s student Stephen Cole Kleene (1909-1994) further studied the expressive power of the McCulloch-Pitts network in 1956. The choice of various activation functions is an art. The McCulloch-Pitts network is discrete, specifically Boolean, with outputs of either 0 or 1. Most modern neural network activation functions are nonlinear and not limited to Boolean values. It can be said that the McCulloch-Pitts network resembles a Boolean circuit rather than a neural network in the modern sense.
Frank Rosenblatt‘s Perceptron, proposed in the 1950s, is a hallmark work of neural networks. Rosenblatt, with a background in psychology, implemented a single-layer perceptron neural network on an IBM 704 machine in 1957, proving that the perceptron could handle linearly separable pattern recognition problems. He later conducted several psychological experiments to demonstrate the learning capability of the perceptron. In 1962, Rosenblatt published the book Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms, summarizing all his research findings, which became a must-read for the neural network community. Rosenblatt’s fame grew, and his research funding increased. The US Department of Defense and Navy funded his research. Rosenblatt transformed from a shy individual into a star, frequently appearing in the media, driving flashy cars, playing the piano, and showing off. Almost every era has its media-friendly tech representative. The media exhibited excessive enthusiasm for Rosenblatt, as constructing a machine that could simulate the brain was undoubtedly front-page news. This made another faction quite displeased.

Rosenblatt and his Perceptron (Frank Rosenblatt, 1928-1971). Image source: Wikipedia
Marvin Minsky was one of the founding figures of artificial intelligence and one of the organizers of the 1956 Dartmouth Conference, which defined the term “artificial intelligence” and included neural networks within its research scope. Early on, Minsky supported neural networks. His 1954 Princeton University doctoral thesis was titled “The Theory of Neural-Simulating Reinforcement Systems and Its Applications to Brain Model Problems,” which was essentially a paper on neural networks. However, he later changed his stance, believing that neural networks were not an effective tool for solving artificial intelligence problems. In later interviews, he jokingly mentioned that his 300-page doctoral thesis was never formally published, probably only three copies were printed, and he could no longer recall its content. It seems he wanted to distance himself from the field of neural networks.
Minsky and Rosenblatt were high school classmates at the Bronx Science High School, one of the most intellectually dense high schools in the world, producing nine Nobel laureates, six Pulitzer Prize winners, and two Turing Award winners among its graduates. Minsky graduated in 1945, while Rosenblatt graduated in 1946. They knew each other and were mutually envious.
At a conference, Minsky and Rosenblatt had a heated argument. Subsequently, Minsky collaborated with MIT professor Seymour Papert to prove that Rosenblatt’s perceptron network could not solve the XOR problem. XOR is a fundamental logical problem; if it cannot even solve this problem, it suggests that the computational capability of neural networks is indeed limited. Minsky and Papert published their collaborative results in the book Perceptrons: An Introduction to Computational Geometry, which had a significant impact and nearly negated the entire field of neural network research.

Minsky (Marvin Minsky, 1927-2016). Image source: Wikipedia
In fact, Rosenblatt had already sensed the limitations of the perceptron, particularly in terms of “symbolic processing,” and pointed out from his experience as a neuropsychologist that some brain-injured individuals could not process symbols. However, the flaws of the perceptron were presented by Minsky in a hostile manner, which was a fatal blow to Rosenblatt. Ultimately, government funding agencies gradually ceased support for neural network research. In 1971, Rosenblatt drowned while rowing on his 43rd birthday, with some suggesting it was suicide.


Rosenblatt and Minsky’s respective works titled Perceptron.
To understand the significance of AlphaFold3’s advancements, one must grasp that biological entities contain multiple layers of complexity. The blueprint for biological operation is derived from DNA through transcription to RNA, which is then translated into proteins. After generation, proteins undergo modifications (chemical changes occurring after protein production) and are influenced by interactions with small molecular ligands and ions, as well as interactions between proteins, to execute specific functions.
In 1900, at the second International Congress of Mathematicians, David Hilbert proposed 23 unsolved mathematical problems that guided subsequent mathematical development. The 13th problem proposed by Hilbert is not particularly noteworthy compared to others, even within the mathematical community, and is far from well-known. We can compare the 10th and 13th problems using the online search engine Google Ngram to get a sense of this.
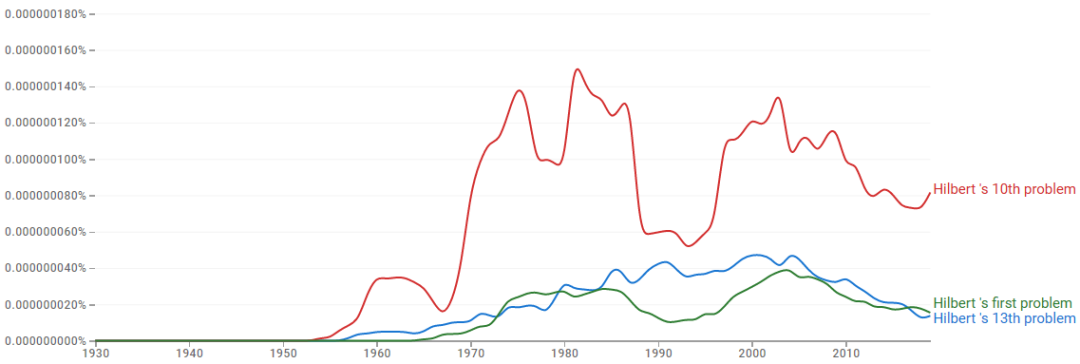
Results from Google Ngram
Hilbert’s 13th problem states: Can the solutions of the 7th degree equation be represented as combinations of functions of two variables? (Impossibility of the solution of the general equation of the 7-th degree by means of functions of only two arguments). Hilbert conjectured that it could not.
We know that equations of degree five or higher do not have root-finding formulas. However, the univariate fifth and sixth degree equations can be transformed into:
The Irish mathematician William Rowan Hamilton proved in 1836 that the 7th degree equation can be simplified through transformation to:
Solutions are expressed as functions of coefficients a, b, c, i.e., x=f(a, b, c). Hilbert’s 13th problem asks whether this ternary function can be expressed as a combination of binary functions.
While Rosenblatt was working on the perceptron, Kolmogorov and Arnold were investigating the “superposition” problem. In 1956, Kolmogorov first proved that any multivariate function can be constructed from a finite number of ternary functions. Arnold subsequently proved that two variables suffice. Their results are referred to as the Kolmogorov-Arnold representation theorem or Kolmogorov superposition theorem, sometimes also called the Arnold-Kolmogorov superposition (AK superposition), because it was Arnold who completed the final proof. In this article, we will collectively refer to this as the KA superposition theorem or KA representation theorem. Kolmogorov’s original intention was not solely to solve Hilbert’s 13th problem, but the superposition theorem essentially constitutes a fundamental negation of Hilbert’s original conjecture regarding the 13th problem. Later, Arnold and Japanese mathematician Goro Shimura made further advancements on this issue.

As for whether Kolmogorov and Arnold’s “superposition” constitutes a complete solution to Hilbert’s 13th problem, opinions in the mathematical community vary. Some mathematicians believe that Hilbert was originally referring to algebraic functions, while Kolmogorov and Arnold proved continuous functions. Hilbert’s original phrasing was “continuous functions,” but considering the Riemann-Klein-Hilbert tradition, mathematicians believe that Hilbert’s intent was algebraic functions. The study of Hilbert’s 13th problem did not conclude with the KA superposition theorem, but continues to this day, which is beyond the scope of this article. Regardless, the superposition theorem serendipitously laid the theoretical foundation for subsequent neural network research.

Connecting the KA superposition theorem with neural networks is a mathematician-turned-entrepreneur. Robert Hecht-Nielsen (1947-2019) was a staunch believer in neural networks. In 1986, he founded a software company named after himself, HNC, specializing in credit card fraud detection. He bet the core technology of the company on neural networks at a time when they were in a downturn, requiring immense courage and foresight. In 2002, the company was acquired by the largest credit rating company, Fair Isaac, for $810 million. In 1987, Hecht-Nielsen presented a paper at the first International Conference on Neural Networks (ICNN, later renamed the International Joint Conference on Neural Networks, IJCNN), demonstrating that the Kolmogorov-Arnold superposition could be realized using a three-layer neural network. This paper was brief, only three pages, but it sparked great ideas. This result theoretically provided comfort to neural network research and inspired a series of interesting studies in mathematics and theoretical computer science.
The KA superposition theorem states:
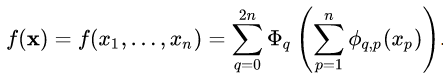
That is, any multivariate continuous function can be expressed as a sum of several unary functions and addition. Addition is the only binary function. Simple functions can be constructed through addition and unary functions, which is not difficult to understand, as shown below, subtraction, multiplication, and division can be formed through addition:
a − b = a + (−b),
a · b = 1 /4 ((a + b) 2 − (a − b) 2) ,
a /b = a · 1/ b
All elementary operations can be completed through unary operations and addition. In this sense, addition is universal; using addition to perform other operations does not require additional dimensions.
Hecht-Nielsen pointed out that the KA superposition theorem can be implemented through a two-layer network, where each layer implements one addition in the superposition. He simply named this realization network the Kolmogorov Network. French mathematician Jean-Pierre Kahane improved the KA superposition theorem in 1975 as follows:
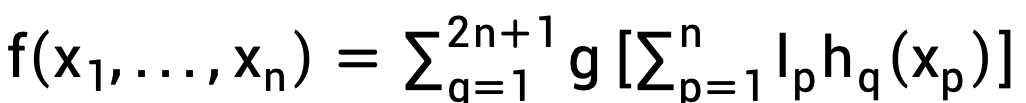
Where h is further restricted to be a strictly monotonic function, and lp is a normal quantity less than 1.


Another mathematician-turned-engineering professor, George Cybenko, later proved in 1988 that a neural network with two hidden layers and sigmoid activation functions can approximate any continuous function. Cybenko’s article provided more details and proofs. Although Cybenko did not cite Hecht-Nielsen’s 1986 work, he did reference Kolmogorov’s 1957 work. We do not know if he was inspired by Hecht-Nielsen. Almost simultaneously, independent works such as Hornik-1989 also referenced both Kolmogorov and Hecht-Nielsen, indicating Hecht-Nielsen’s prophetic insights into the implications of the Kolmogorov-Arnold superposition for computer science. These related conclusions and various variants and extensions are collectively referred to as the Universal Approximation Theorem. In addition to continuous functions, there are efforts to prove that discontinuous functions can also be approximated using three-layer neural networks (Ismailov, 2022). Regardless, those with a mathematical background can always consider problems from first principles. Subsequently, the crisis in neural networks caused by Minsky was finally resolved.

In 1974, a doctoral thesis in statistics at Harvard proved that increasing the number of layers in neural networks to three and utilizing the back-propagation learning method could solve the XOR problem. The author of this thesis, Paul Werbos, later received the Pioneer Award from the IEEE Neural Networks Society. When Werbos’s article was first published, it did not attract much attention in the neural network community, primarily because his advisor was in sociology and political science, and the problems he aimed to solve were also in statistics and social sciences. Applying “back-propagation” to multi-layer neural networks became known as “deep learning.”
Deep learning first achieved breakthroughs in speech and image recognition and later, with the help of reinforcement learning, saw astonishing success in games and natural language processing. However, the mechanisms behind deep learning have yet to be satisfactorily explained.
Tomaso Poggio, a collaborator of the prematurely deceased computer vision researcher David Marr, gradually shifted his focus towards the theory of machine learning and neural networks after Marr’s death in 1980. Many mathematicians were also drawn in, such as Fields Medalist and long-lived, prolific mathematician Stephen Smale. However, Poggio does not recognize that the KA superposition theorem can serve as the mathematical foundation for universal approximation networks. As early as 1989, he pointed out that networks implementing KA superposition are non-smooth (see Girosi & Poggio, 1989). In subsequent work, he further noted that the curse of dimensionality (CoD) depends on dimension/smoothness. Poor smoothness naturally leads to dimensionality issues. Although the KA superposition theorem has theoretical value, its direct application to practical neural networks encounters smoothness problems, resulting in little engineering progress. Consequently, the KA superposition theorem was forgotten.
By May of this year, the KA superposition theorem regained attention. MIT physicist and popular science writer Max Tegmark, who has always been interested in tracking artificial intelligence, especially machine learning, sought to revive the KA superposition theorem in his latest paper, co-authored with Liu. They believe that the original Kolmogorov network only had two layers, and if the number of layers is increased and the width expanded, it may overcome the smoothness issues. They named the expanded network KAN (Kolmogorov-Arnold Network), while in fact, Hecht-Nielsen had long referred to the network that realizes the KA superposition theorem as the Kolmogorov Network.

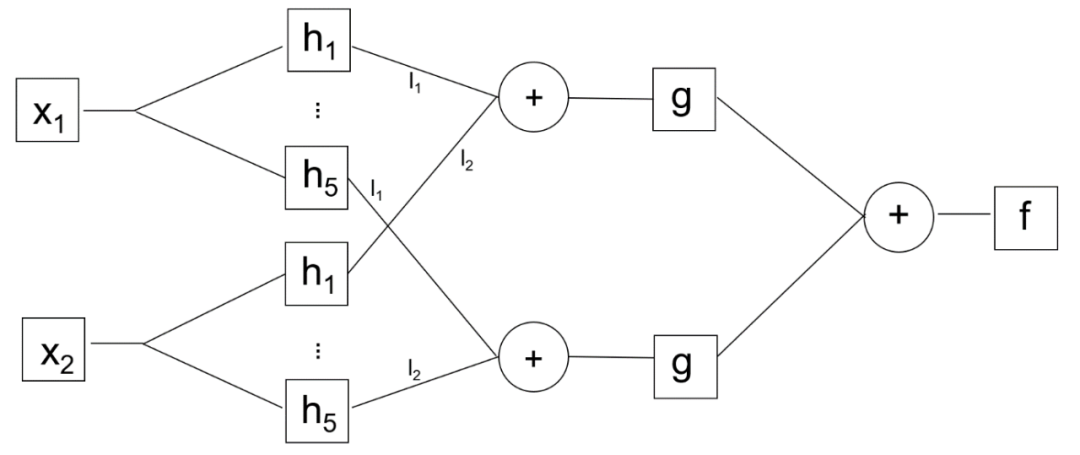
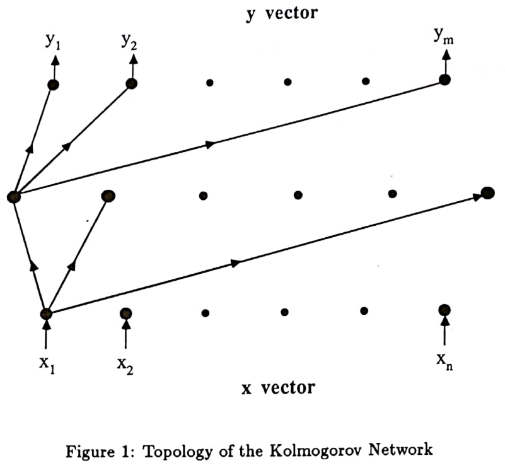
One of the key innovations claimed by the authors of KAN is placing computation on the network’s edges rather than at the nodes, where nodes only perform addition operations, thus reducing the scale of the network. Since the superposition theorem only requires addition (binary) and unary functions, the realization of unary functions at the nodes can collapse into edges, making edges nodes and vice versa, which is not surprising. As shown in the figure, node h can be seen as the edge connecting the input x and g before the addition. In KAN, addition can only be implemented at nodes because it is binary and requires two inputs. In this sense, KAN does not fundamentally differ from multi-layer perceptrons (MLP). In normal networks, the number of edges is squared relative to the number of nodes, and whether the reduction in network scale truly results in a decrease in computational load still requires joint exploration between theory and experimentation.
Another innovation of KAN is learning the activation function instead of learning the weights. However, learning functions is significantly more challenging than learning weights. In KAN, the activation function is fitted using B-splines, which naturally brings along all of B-spline’s disadvantages into KAN. If the cost of learning the activation function is high, the network loses its universality. Currently, further engineering practice is needed to prove KAN’s advantages. Nevertheless, KAN’s work encourages us to seek new paths from first principles, providing mathematical foundations for explanations.
A Piece of History and a Thought Experiment: The Tycho Machine
The thoughts of the Enlightenment evolved iteratively between rationalism and empiricism. Science is no different. Nicholas Copernicus was undoubtedly a rationalist, using mathematics as his tool. Following him, Johannes Kepler was also a rationalist. However, Tycho Brahe was a thorough empiricist, using self-made measuring instruments, lacking telescopes at that time. He left behind 24 volumes of observational data, including a catalog of 777 stars. This batch of data was inherited by Kepler. The dying nobleman Tycho Brahe had nearly fallen out with the petty Kepler. A simplified version of this history is: Copernicus overturned the geocentric theory of Ptolemy, replacing it with a simpler heliocentric theory. However, Tycho Brahe did not go that far; according to Cambridge historian of science Simon Schaffer, Tycho was conservative where Copernicus innovated and innovative where Copernicus was conservative. He proposed a quasi-heliocentric theory: all planets revolve around the sun, but the sun, along with the planets, revolves around the earth. Kepler corrected Tycho’s work and proposed three laws of planetary motion, with mathematics as his tool. Kepler’s work received validation from Galileo Galilei, who was also an empiricist, equipped with a newer tool: the telescope. In 1609, when Kepler first published his first two laws in New Astronomy, Galileo had just built a three-fold telescope.
Tycho Brahe’s self-made observational devices, by today’s standards, appear to be crude toys. But let us assume he had, in addition to those devices, a modern advanced machine learning setup. For convenience, we shall temporarily call it the Tycho Machine. This learning machine could implement various machine learning algorithms today, including deep learning and reinforcement learning. He could feed his 24 volumes of recorded data into this Tycho Machine for training, and the trained Tycho Machine could output the orbital data of any star or planet. If so, does it matter whether the heliocentric or geocentric theory is correct? After all, the Tycho Machine can output the data we need. The performance of the Tycho Machine would undoubtedly be difficult for people of that time to explain, and they would likely refer to it as “emergent.” Can we say that the functionality completed by this Tycho Machine constitutes science? Can its behavior be explained? Must equations be listed to be considered an explanation? How simple must an equation be to be regarded as an explanation? This could even influence our approach to science; according to the mechanism of the Tycho Machine, we are merely responsible for continuously collecting data and feeding it to the machine, constantly refining the prediction mechanism. If deep learning had existed before Newton, would there have been no Newton’s laws or even relativity? Is a world described by equations that only offer numerical solutions without analytical solutions not to be understood? Can the unsolvable three-body problem not be considered understood?
Conclusion
Arnold, in addition to making profound contributions to the technical content of mathematics, also made many interesting assertions regarding the philosophy and history of mathematics. He once said: “Mathematics is the part of physics where experiments are cheap.” We can also adapt this statement to say that computer science is, in fact, the part of physics where experiments are very cheap. We can ask: Can humans learn more, less, or the same as rationality? The universal approximation theorem seems to suggest that rationality cannot exceed what is learnable. We can delve deeper into the philosophical implications of the KA superposition theorem.
Arnold stated in an interview: “The Bourbaki school claims that all great mathematicians—using Dirichlet’s words—replace blind computation with clear thoughts. This statement from the Bourbaki manifesto, when translated into Russian, became ‘replace clear thoughts with blind computation,’ and the translator was Kolmogorov, who was fluent in French. I was astonished when I discovered this error and sought out Kolmogorov to discuss it. He replied: ‘I don’t think there’s a problem with the translation; it describes the Bourbaki style more accurately than they do themselves.’ Unfortunately, Henri Poincaré did not establish a school in France.” The sharp wit and humor of Soviet mathematicians are unique.
When Hume stated that Newton discovered the laws of nature, he intended to draw Newton into the camp of empiricism. However, Newton rejected mechanism. We strive to say that the Church-Turing thesis is the law of the mind (in fact, it is a “thesis”). Our demands for the explainability of AI are based on mechanism. The purpose of explainability is to provide explanations to the average person in court rather than to reach a consensus among the smartest elites. In the past, scientific explainability was a hallmark of scientific success. Reductionism, as the tradition of modern science, reduces a difficult large problem into smaller, more primitive, and easier-to-explain problems. Mechanism reduces all motion to some sort of collision; universal gravitation does not require collisions, which, from a mechanistic perspective, is inexplicable. Large models, on the other hand, bundle together previously uncertain small problems and resolve them. When the overall problem is solved, the smaller problems within it are no longer considered important.
We can say that rationalism is “clear thought,” while black boxes represent “blind computation.” But are physical laws necessarily more economical than black boxes? It is often said that airplanes do not learn from birds but rely on fluid mechanics because the cost of building super birds is too high. If the cost of creating birds were lower than solving fluid mechanics equations, building birds might not be a bad choice. Max Tegmark and others are attempting to find physical laws through symbolic regression from data (Undrescu & Tegmark). One of his datasets includes the formulas listed in Feynman’s Lectures on Physics. If we view learning as compression, “blind computation” may sometimes achieve a higher compression ratio than “clear thought” (such as symbolic regression or analytical solutions). Scientific problems have, in a sense, become economic problems. It is in this sense that computer science is closer to first principles than physics; physics is merely symbolic regression of computer science.

[1] Liu, Z., Wang, Y., Vaidya, S., Ruehle, F., Halverson, J., Soljačić, M., … & Tegmark, M. (2024). KAN: Kolmogorov-Arnold Networks. arXiv preprint arXiv:2404.19756.
[2] Cucker, F. & Smale, S. (2001), On the Mathematical Foundations of Learning, BULLETIN OF THE AMS, Volume 39, Number 1, Pages 1–49
[3] Cybenko, G. (1988), Continuous Valued Neural Networks with Two Hidden Layers are Sufficient, Technical Report, Department of Computer Science, Tufts University.
[4] Cybenko, G. (1989), Approximation by Superpositions of a Sigmoidal Function, Mathematics of Control, Signals, and Systems, 2(4), 303–314.
[5] Girosi, F. & Poggio, T. (1989), Representation properties of networks: Kolmogorov’s theorem is irrelevant, Neural Computation, 1 (1989), 465–469.
[6] Hecht-Nielsen, R. (1987), Kolmogorov’s mapping neural network existence theorem, Proc. 1987 IEEE Int. Conf. on Neural Networks, IEEE Press, New York, 1987, vol. 3, 11–14.
[7] Hilbert, D. (1900). Mathematische probleme. Nachr. Akad. Wiss. Gottingen, 290-329. (“Mathematical Problems”, Mathematics and Culture, Peking University Press, 1990)
[8] Hornik, K. et al (1989), Multilayer Feedforward Networks are Universal Approximators, Neural Networks, Vol. 2, pp. 357-366, 1989.
[9] Ismailov, V. (2022), A three layer neural network can represent any multivariate function, 2012.03016.pdf (arxiv.org)
[10] Kahane, J. P. (1975), Sur le theoreme de superposition de Kolmogorov. J. Approx. Theory 13, 229-234.
[11] Kleene, S.C. (1956), Representation of Events in Nerve Nets and Finite Automata. Automata Studies, Editors: C.E. Shannon and J. McCarthy, Princeton University Press, p. 3-42, Princeton, N.J.
[12] Kolmogorov, A.N. (1957), On the representation of continuous functions of many variables by superposition of continuous functions of one variable and addition, (Russian), Dokl. Akad. Nauk SSSR 114, 953–956.
[13] Kolmogorov, A.N. (1988), How I became a mathematician, (Yao Fang et al. trans., I Became a Mathematician, Dalian University of Technology Press, 2023)
[14] W. S. McCulloch, W. Pitts. (1943), A Logical Calculus of Ideas Immanent in Nervous Activity. Bulletin of Mathematical Biophysics, Vol. 5, p. 115-133.
[15] Poggio, T. & Smale, S. (2003), The Mathematics of Learning: Dealing with Data, NOTICES OF THE AMS
[16] Togelius, J. & Georgios N. Yannakakis, Choose Your Weapon: Survival Strategies for Depressed AI Academics, [2304.06035] (arxiv.org)
[17] Udrescu, Silviu-Marian & M. Tegmark (2020), AI Feynman: a Physics-Inspired Method for Symbolic Regression, arxiv
[18] Nick (2021), A Brief History of Artificial Intelligence, 2nd edition.

Welcome to follow us. For submissions, authorization, etc., please contact
For collaboration, please add WeChat SxsLive2022