

Produced by Big Data Digest
Compiled by: Xiao Qi, Mixed Sweet, Xia Yawei
Trump’s new re-election campaign has begun.
The author’s interest in Trump’s distinctive language style raises the question: can a speech that embodies his style be generated using a Recurrent Neural Network (RNN) trained on his tweets and speeches? The conclusion is that if the data and computational power are sufficiently large, there may indeed be a place for algorithmic speechwriting robots in the presidential campaign team.
On December 30, 2015, a campaign rally was in full swing in South Carolina, adding another brilliant chapter to Trump’s “Trumpism” quotes. It is these remarks that have garnered him the love and support of his followers, while also becoming a source of amusement for some.
No matter what your personal opinions about Trump are, you cannot deny that he has a unique way of speaking—scattered high-level vocabulary and unconventional sentence structures that make his speeches highly recognizable among predecessors and peers.
I am very interested in this unique style and plan to use machine learning algorithms to learn and generate text similar to Trump’s speaking style.
Data Collection and Processing
First, a large number of examples must be collected to understand President Trump’s speaking style. There are mainly two sources—one is Twitter, and the other is presidential speeches and addresses.

One example of unconventional sentence structure
Trump’s tweets are the easiest place to access his rhetoric. He is the only president to communicate and interact directly with the American people through social media platforms. Additionally, as a public figure, his remarks are naturally collected and organized for future reference, saving me a lot of trouble, as I do not need to scrape Twitter’s unstable and limited API. In total, there are less than 31,000 tweets available for my use.
Tweet link:
https://developer.twitter.com/en.html
Presidential Addresses and Speeches
However, in addition to his online persona, I also want to examine his more formal speaking style as president. To do this, I hope to obtain some materials from the White House briefing statement archives. With the help of some Python tools, I quickly collected about 420 speeches and other comments from the president. These materials cover various events, such as meetings with foreign dignitaries, roundtable discussions with members of Congress, and award ceremony speeches.
White House briefing archive link:
https://www.whitehouse.gov/briefings-statements/
Python tools link:
https://www.crummy.com/software/BeautifulSoup/
Every word in the tweets is written or dictated by Trump himself, but these speeches may involve other politicians and some well-meaning journalists. We need to separate Trump’s words from those of others, which is a daunting task.
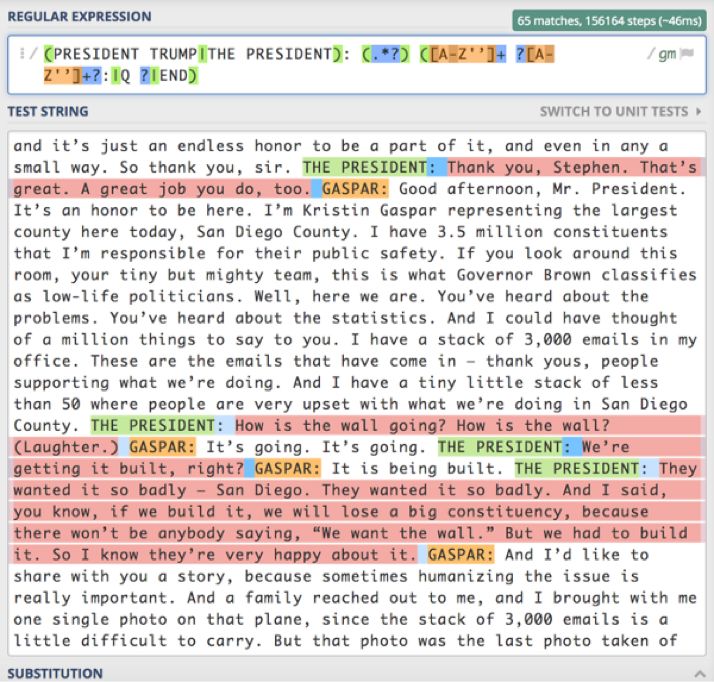
I find regular expressions to be quite magical
Inputting a regular expression—while it may sound boring, it is a powerful and absolutely fascinating tool.
Regular expressions allow the specification of search patterns, which can include any number of specific constraints, wildcards, or other limitations, thus precisely returning only the desired content without including anything else.
Through some trial and error, I generated a complex regular expression that only returns the president’s spoken words, separating out and discarding other vocabulary or comments.
Does the data need cleaning?
Typically, the first step in processing text is to normalize it. The degree and complexity of this normalization vary according to people’s needs, ranging from simply removing punctuation or capital letters to reducing all forms of a word to a single root.
Example workflow:
https://towardsdatascience.com/into-a-textual-heart-of-darkness-39b3895ce21e.
Root word link:
https://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html
However, during the normalization process, specific characteristics and patterns that I need to retain may be lost. Therefore, to make the generated text more credible and authentic, I chose to bypass most of the standard normalization processes.
Text Generation
Markov Chains
Before diving into deep learning models, I wanted to explore another commonly used text generation method—Markov chains. For a long time, Markov chains have been the best choice for generating joke texts—searching for keywords like “Star Trek”, “previous presidents”, “The Simpsons”, etc., yields many stories.
Markov chain link:
https://en.wikipedia.org/wiki/Markov_chain
Story link:
https://hackernoon.com/automated-text-generator-using-markov-chain-de999a41e047
Since Markov chains only determine the next word based on the current word, they are very fast but not particularly effective. This algorithm focuses solely on a specific word, and the next word is generated accordingly. The next word is randomly selected based on probabilities that are proportional to frequency. Here’s a simple example:

A simplified example of a Markov chain, where “taxes” is followed by only three words: “bigly”, “soon”, and the end of the sentence.
In real life, if Trump says the word “taxes”, there’s a 70% chance that “bigly” follows. Therefore, in the text generated by the Markov chain, there’s a 70% probability that the next word will be “bigly”.
But sometimes, he may not follow “bigly” and instead end the sentence, or follow it with another word. In this case, the Markov chain is likely to choose “bigly”, but it may also select other possible words, resulting in diverse generated text. This process is repeated until the sentence ends.
This is suitable for quick and low-quality applications, but it is easy to see where it can go wrong. Since Markov chains only care about the current word, they can easily fall into absurdity. A sentence that starts discussing the domestic economy may easily end with “The Apprentice”.
Based on a limited text dataset, most outputs from Markov chains are absurd. However, occasionally, some brilliant and humorous quotes emerge:

Results generated by a Markov chain starting with “FBI”
Recurrent Neural Networks
However, to produce more coherent sentences, I need something more complex. Recurrent Neural Networks (RNNs) have become the preferred architecture for many text or sequential applications. The specific workings of RNNs exceed the scope of this article, but here are some relatively beginner-friendly resources.
Resource link:
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
The notable feature of these neural units is their internal “memory” of sequences; vocabulary choice and grammar largely depend on the surrounding context, allowing this “memory” to create coherent thoughts by tracking tenses, subjects, and objects.
One drawback of these types of networks is their heavy computational load—running this model on a laptop takes over an hour to process the entire text, considering I need to do this about 200 times, which is not practical.
But this is also the direction of current cloud computing development. Many established tech companies offer cloud services, with Amazon, Google, and Microsoft being the largest. In a powerful GPU computing instance, the cycle time is reduced to ninety seconds, more than forty times faster!
GPU computing instance:
https://aws.amazon.com/ec2/instance-types/p3/
Result Evaluation
Can you judge whether this statement is real?
California finally deserves a great Government to Make America Great Again! #Trump2016
(California finally deserves to have a great government to make America great again!)
This text was extracted from a speech supporting a Republican gubernatorial candidate by Trump, but it could easily become a tweet released by Trump on the eve of the 2016 election.
Link to Trump supporting the Republican gubernatorial candidate’s speech:
https://twitter.com/realDonaldTrump/status/997597940444221440
The more complex neural network I implemented has hidden fully connected layers both before and after the recurrent layers, which can generate internally consistent coherent text based on as few as 40 characters as a seed.
I want them all to get together and I want people that can look at the farms.
(I want them all to come together, and I want people to see the farmers.)
China has agreed to buy massive amounts of the world—and stop what a massive American deal.
(China has agreed to buy massive amounts of products from the world and stopped a massive deal with America.)
Less complex networks exhibit a bit of instability in sentence coherence but still capture the tone and feel of Trump’s speech:
Obama. We’ll have a lot of people that do we—okay? I’ll tell you they were a little bit of it.
(Obama, we will have a lot of people—okay? I tell you, they were just a few of them.)

Conclusion and Reflection
While it is unlikely that text generated through RNNs can deceive everyone, this attempt has shown us the power of RNNs. In a short period, these networks learned spelling and certain grammatical knowledge. In some cases, if the neural network were designed better, and with a larger dataset and more training time, it might even learn how to use hashtags and hyperlinks.
If you are interested in the code for these models, you can find the repository here:
https://github.com/tetrahydrofuran/presidential-rnn
Feel free to ask any questions or provide feedback!
Related reports:
https://towardsdatascience.com/the-best-words-cf6fc2333c31
【Today’s Machine Learning Concept】
Have a Great Definition

Contributors
Reply “Volunteer” to join us



