Hello everyone, I am Liu Cong from NLP.
Just tonight, Kimi released the latest model K1.5, first, let’s take a look at the leaderboard results, it’s simply explosive.
In long reasoning, K1.5 far surpasses OpenAI’s O1 model in mathematical ability, whether in pure text or visual multimodal; it is on par with Codeforces, slightly lagging on LiveCode, but has a significant advantage over QVQ and QWQ.
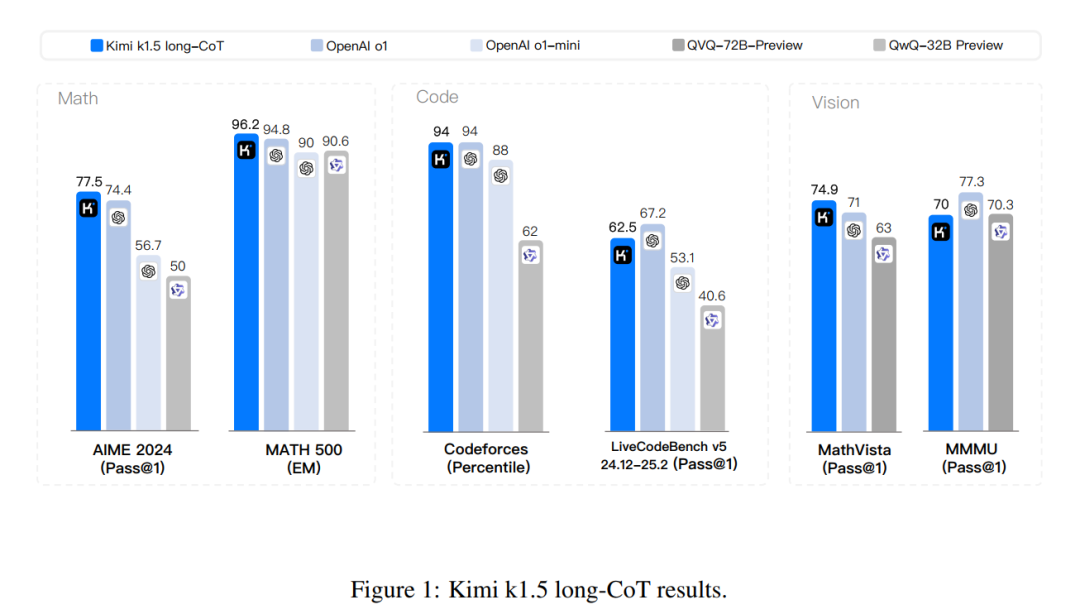
In short reasoning, K1.5’s mathematical ability is truly leading, whether compared to GPT-4O or Claude 3.5-sonnet, both are far inferior to K1.5, especially on the AIME leaderboard, where K1.5 scores 60.8, while the highest deepseek-v3 only scores 39.2, which is a significant crushing advantage. This should be attributed to their Long2short RL technology (to be introduced later); moreover, K1.5 is mostly on par with top open-source and closed-source models in other scenarios. To be honest, Kimi’s new model this time has something special.
Most importantly, Kimi released a technical report titled Kimi K1.5: Scaling Reinforcement Learning with Large Language Models. I glanced at it, it’s 25 pages, packed with valuable information. They have done a lot of work on reinforcement learning, covering data, strategy, and infrastructure.
Paper link: https://github.com/MoonshotAI/Kimi-k1.5/blob/main/Kimi_k1.5.pdf
After a brief look, what impressed me most was the RL data collection section, the Long2short part, and the Hybrid Deployment Framework section in Infra.
The Long2short part is likely the core reason why the K1.5 model can achieve superior results in short reasoning. Since O1 came out, we all know that increasing test time can improve model reasoning performance and significantly enhance model intelligence, which is why O1 sparked a new wave of LLMs.
However, long-cot is excellent, but it consumes a large amount of token budget and time during the reasoning phase. So, can we transfer the prior knowledge of the long-cot model’s reasoning to the short-cot model? K1.5 tried several methods:
-
Model Merging: Previously, model merging was used to improve model generalization. K1.5 found that long-cot and short-cot models could also be merged to improve output efficiency, balance output content, and require no training. -
Shortest Reject Sampling: Sample the model’s output n times (in experiments, n=8), and select the shortest correct result for model fine-tuning. -
DPO: Similar to shortest reject sampling, using the long-cot model to generate multiple outputs, the shortest correct output is treated as a positive sample, while longer responses (including incorrect long outputs and correct long outputs that are 1.5 times longer than the selected positive sample) are treated as negative samples, conducting DPO preference learning based on the constructed positive and negative samples. -
Long2Short Reinforcement Learning: After the standard reinforcement learning training phase, select a model that balances performance and output efficiency as the base model and conduct a separate reinforcement learning training phase from long-cot to short-cot. In this phase, a length penalty is applied, further penalizing outputs that exceed the expected length while ensuring the model can still output correct answers.
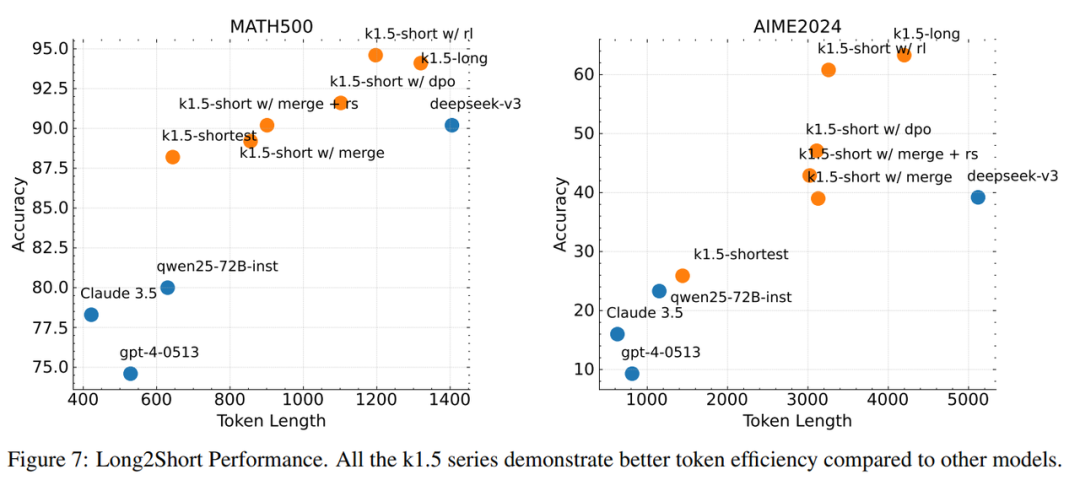
The effects of Long2short are shown below, significantly improving model performance while enhancing output efficiency.
In the RL data collection section, I feel Kimi really spoke to my heart. After working on LLMs, I spent a long time on data-related work. And the data quality and diversity during the RL phase can guide the model to robust reasoning while reducing the risks of reward hacking and overfitting.
The three key elements of high-quality RL prompt data are:
-
Coverage – Broad: Prompt data should cover a wide range of disciplines, such as science, technology, engineering, and mathematics (STEM), coding, and general reasoning, enhancing the model’s universality across different fields. Here, K1.5 developed a labeling system to categorize prompts by field and discipline, ensuring balanced data across different academic areas. -
Difficulty Distribution – Even: Prompt data should include questions of varying difficulty levels (easy, medium, hard), allowing the model to learn progressively and preventing overfitting to specific complex problems. K1.5 evaluates each prompt’s difficulty based on the model’s reasoning ability, generating 10 answers for the same prompt at a relatively high temperature, then calculating the pass rate; a lower pass rate indicates a higher prompt difficulty. -
Evaluability – Accurate: Prompt data should allow validators to conduct objective and reliable evaluations, ensuring model results are based on correct reasoning processes rather than simple patterns or random guesses. Here, K1.5 predicts possible answers without any chain reasoning steps; if it predicts the correct answer within N attempts, it considers that prompt likely to produce reward hacking.
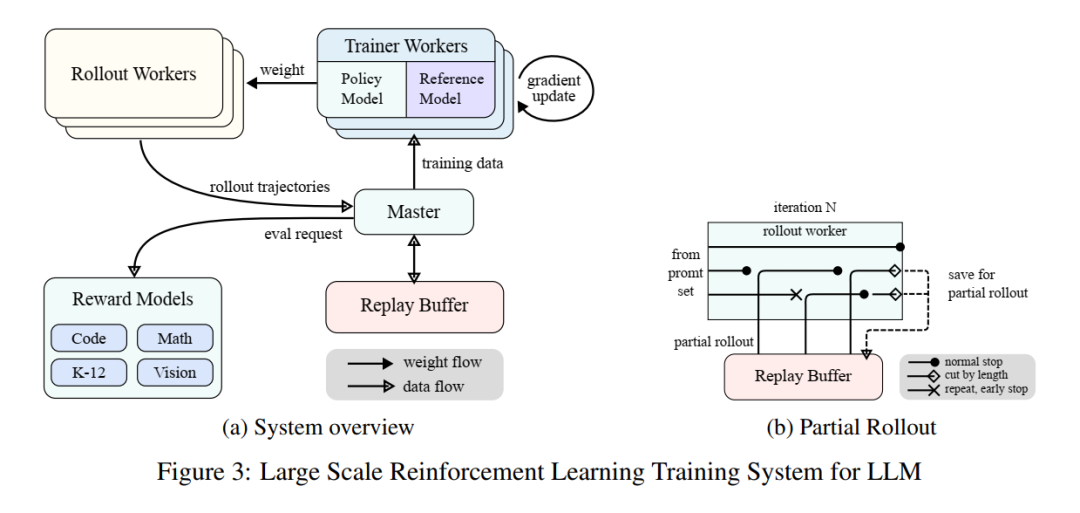
The K1.5 report includes extensive content on infrastructure. After reading it, I gained a lot because I am not primarily focused on infrastructure, so I wasn’t very familiar with many details before. After reading K1.5’s content, I really learned a lot.
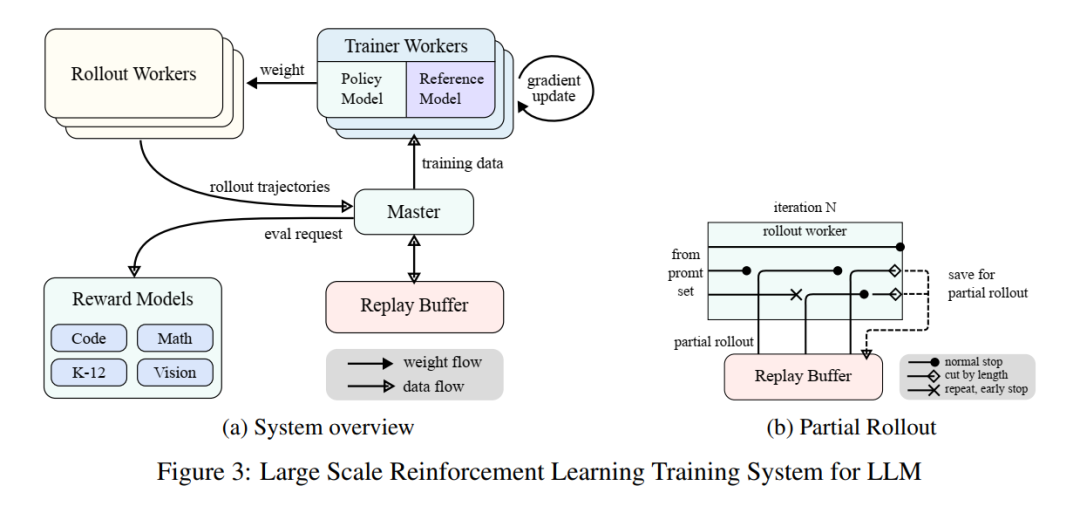
Among them, the Hybrid Deployment Framework section contains some engineering aspects. The RL phase mainly consists of the following stages:
-
Training Stage: Megatron (Shoeybi et al. 2020) and vLLM (Kwon et al. 2023) run in separate containers, encapsulated by a shell process called Checkpoint Engine (see section 2.6.3 for details). Megatron starts the training process first. After training is complete, Megatron releases GPU memory and prepares to pass the current weights to vLLM. -
Training Stage: Megatron and vLLM run in separate containers, encapsulated by a shell process called Checkpoint Engine. Megatron starts the training process first, and after training is complete, it releases GPU memory and prepares to pass the current weights to vLLM. -
Reasoning Stage: After Megatron releases memory, vLLM starts with virtual model weights and receives the latest weight updates from Megatron via Mooncake. After playback is complete, the Checkpoint Engine stops all vLLM processes. -
Subsequent Training Stage: After releasing memory occupied by vLLM, Megatron reloads memory and begins the next round of training.
Current frameworks struggle to meet all of the following features:
-
Complex Parallel Strategies: Megatron and vLLM may adopt different parallel strategies. It is challenging to share training weights distributed across multiple nodes in Megatron with vLLM. -
Minimizing Idle GPU Resources: For online policy reinforcement learning, SGLang and vLLM may retain some GPUs during training, leading to idle training GPUs. How to share the same devices makes training more efficient. -
Dynamic Scalability: By increasing the number of reasoning nodes while keeping the training process unchanged, training can be significantly accelerated. How to efficiently utilize idle GPU nodes.
As shown in the figure below, K1.5 implements this hybrid deployment framework based on Megatron and vLLM, reducing the time to switch from the training phase to the reasoning phase to less than a minute, while switching from the reasoning phase back to the training phase takes about only ten seconds.
After reading the entire paper, I learned a lot, there are still some other contents, which I will share with you later when I have the opportunity, and I look forward to other infrastructure and RL experts interpreting it.
Finally, K1.5 has just been released and is currently undergoing a gradual rollout. You might soon become one of the lucky ones to experience the overall effect of K1.5 in advance. I am really looking forward to it.
PS: If you find this good, please give a like, follow, and subscribe. Add a 【star⭐️】 to the public account so you won’t get lost! Your support is my greatest motivation to keep going!
Feel free to follow the public account “NLP Workstation”, join the group chat, and make friends. Let’s learn and progress together!