
LLM has become an indispensable productivity tool across various industries, such as text generation, language translation, and knowledge Q&A. Sometimes, the responses from LLMs can be surprising, as they are quicker and more accurate than humans. This demonstrates their significant impact on today’s technological landscape.
As we delve deeper into the field of artificial intelligence, two tools have emerged as key drivers: LlamaIndex and LangChain. LlamaIndex offers a unique approach focused on data indexing and enhancing the performance of LLMs, while LangChain provides a more general framework that is flexible enough to pave the way for a wide range of LLM applications.
While both LlamaIndex and LangChain have the capability to develop comprehensive generative AI applications, they each focus on different aspects of the application development process.
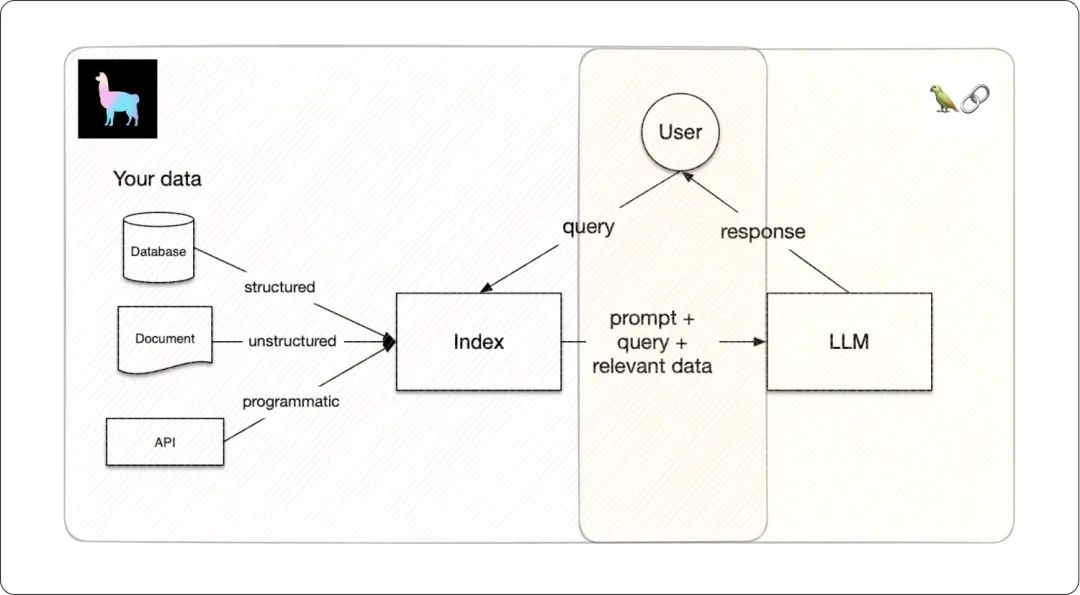
The above image illustrates how LlamaIndex focuses more on the initial stages of data processing, such as loading, ingestion, and indexing to form a knowledge base. In contrast, LangChain emphasizes the later stages, particularly facilitating the interaction between AI (LLM) and users through multi-agent systems.
Essentially, the combination of LlamaIndex’s data management capabilities with LangChain’s enhanced user interaction features can lead to more powerful and efficient generative AI applications.
Let’s first understand the roles of these two frameworks in building LLMs:
LlamaIndex: A Bridge Between Data and LLMs
LlamaIndex serves as a crucial tool moving forward, allowing users to build structured data indexes, use multiple LLMs for different applications, and improve data querying with natural language.
It stands out with its data connectors and indexing capabilities, simplifying data integration by ensuring data is directly extracted from local sources, facilitating efficient data retrieval, and enhancing the quality and performance of the data used by LLMs.
LlamaIndex is renowned for its engine, which creates a symbiotic relationship between data sources and LLMs through a flexible framework. This synergistic collaboration paves the way for applications like semantic search and context-aware query engines that consider user intent and context to provide tailored, insightful responses.
Features of LlamaIndex
LlamaIndex is an innovative tool designed to enhance the utilization of LLMs by seamlessly connecting data with the powerful computational abilities of these models. It boasts a range of features to simplify data tasks and enhance LLM performance for various applications, including:
Data Connectors:
-
Data connectors simplify the process of integrating data from various sources into a data repository, bypassing the manual and error-prone extraction, transformation, and loading (ETL) process.
-
These connectors can retrieve data directly from raw formats and sources, eliminating the need for time-consuming data transformations.
-
The advantages of using data connectors include automatically enhancing data quality, ensuring data security through encryption, improving data performance via caching, and reducing maintenance of data integration solutions.
Engine:
-
LlamaIndex engine drives the connection between LLMs and data sources, ensuring direct access to real-world information.
-
These engines are equipped with intelligent search systems capable of understanding natural language queries, allowing smooth interaction with data.
-
Not only can they organize data for quick access, but they can also enrich LLM-supported applications by adding supplementary information and assisting in LLM selection for specific tasks.
Data Agents:
-
Data agents are intelligent components powered by LlamaIndex that easily execute data management by processing various data structures and interacting with external service APIs.
-
These agents go beyond static query engines, dynamically ingesting and modifying data to adapt to changing data environments.
-
Building a data agent involves defining decision loops and establishing tool abstractions for unified interaction interfaces between different tools.
-
LlamaIndex supports OpenAI Function agents and ReAct agents, both of which leverage the advantages of LLMs combined with tool abstractions, elevating the automation and intelligence of data workflows to new heights.
Application Integration:
-
LlamaIndex’s true advantage lies in its extensive integration with other tools and services, allowing the creation of powerful, multifunctional LLM-supported applications.
-
Integrations with vector stores like Pinecone and Milvus facilitate efficient document search and retrieval.
-
LlamaIndex can also merge with tracking tools like Graphsignal to gain insights into LLM-supported application operations and integrate with application frameworks like Langchain and Streamlit for easier building and deployment.
-
Integration extends to data loaders, agent tools, and observability tools, enhancing the capabilities of data agents and providing various structured output formats for easy consumption of application results.
LangChain: A Flexible Architecture for LLM Applications
In contrast, LangChain has become a master of versatility. It is a comprehensive modular framework that enables developers to combine LLMs with various data sources and services.
LangChain thrives on its scalability, allowing developers to orchestrate operations like retrieval-augmented generation (RAG), defining steps to use external data during the generation process of LLMs. With RAG, LangChain acts as a pipeline, transmitting personalized data during creation, embodying the magic of customized outputs to meet specific needs.
Features of LangChain
The key components of LangChain include model I/O, retrieval systems, and chains.
Model I/O:
-
LangChain’s model I/O module facilitates interaction with LLMs, providing standardized and streamlined processes for developers to integrate LLM capabilities into their applications.
-
It includes prompts that guide LLMs to perform tasks, such as generating text, translating languages, or answering queries.
-
Supporting multiple LLMs, including popular ones like OpenAI API, Bard, and Bloom, ensures developers can use the right tools for various tasks.
-
The input parser component converts user input into structured formats that LLMs can understand, enhancing the application’s ability to interact with users.
Retrieval Systems:
-
One of LangChain’s standout features is retrieval-augmented generation (RAG), which allows LLMs to access external data during the generation phase, providing personalized outputs.
-
Another core component is the document loader, which provides access to a vast array of documents from different sources and formats, supporting LLMs’ ability to acquire knowledge from rich knowledge bases.
-
Text embedding models are used to create embeddings that capture the semantics of text, thus improving the retrieval capabilities of relevant content.
-
Vector storage is crucial for efficiently storing and retrieving embeddings, offering over 50 different storage options.
-
These include different retrievers that provide a range of retrieval algorithms, from basic semantic search to advanced techniques that enhance performance.
Chains:
-
LangChain introduces chains, a powerful component for building more complex applications that require sequential execution of multiple steps or tasks.
-
Chains allow LLMs to collaborate with other components, providing a traditional chain interface or leveraging LangChain Expression Language (LCEL) for chain composition.
-
Supporting both pre-built and custom chains indicates the system’s versatility and scalability designed around developers’ needs.
-
The Async API in LangChain is used for asynchronously running chains, enhancing the usability of complex applications involving multiple steps.
-
Custom chain creation allows developers to craft unique workflows and add memory (state) enhancements to the chains, enabling them to remember past interactions for conversational maintenance or progress tracking.
Comparison of LlamaIndex and LangChain
When we compare LlamaIndex with LangChain, we see a complementary vision aimed at maximizing the capabilities of LLMs. LlamaIndex is a superhero around tasks of data indexing and LLM enhancement, such as document search and content generation.
On the other hand, LangChain possesses the ability to build robust, adaptive applications across multiple domains, including text generation, translation, and summarization.
As developers and innovators seek tools to expand the reach of LLMs, a deep dive into the offerings of LlamaIndex and LangChain can guide them in creating standout applications that resonate with efficiency, accuracy, and creativity.
Centralized Focus vs. Flexibility
LlamaIndex:
-
Designed specifically for search and retrieval applications, it excels in efficiently indexing and organizing data for quick access.
-
Features a streamlined interface that allows for direct querying of LLMs, enabling relevant document retrieval.
-
Explicitly optimized for indexing and retrieval, enhancing the accuracy and speed of search and summarization tasks.
-
Specialized in efficiently handling large volumes of data, making it well-suited for dedicated search and retrieval tasks requiring robust performance.
-
Provides a simple interface primarily for building search and retrieval applications, facilitating direct interaction with LLMs for efficient document retrieval.
-
Focuses on the indexing and retrieval process, optimizing search and summarization capabilities to manage large datasets effectively.
-
Allows for the creation of organized data indexes with user-friendly features that simplify data tasks and enhance LLM performance.
LangChain:
-
Proposes a comprehensive modular framework that excels in building a variety of LLM-supported applications with general functionalities.
-
Offers a flexible and scalable structure that supports various data sources and services, skillfully assembling these sources and services to create complex applications.
-
Includes tools such as model I/O, retrieval systems, chains, and memory systems, providing control over LLM integration to customize solutions based on specific requirements.
-
Proposes a comprehensive modular framework that excels in building a variety of LLM-supported applications with general functionalities.
-
Offers a flexible and scalable structure that supports various data sources and services, skillfully assembling these sources and services to create complex applications.
-
Includes tools such as model I/O, retrieval systems, chains, and memory systems, providing control over LLM integration to customize solutions based on specific requirements.
Use Cases and Case Studies
LlamaIndex is designed to leverage the advantages of LLMs for practical applications, primarily focusing on simplifying search and retrieval tasks. Here are detailed use cases for LlamaIndex, particularly around semantic search, along with case studies highlighting its indexing capabilities:
Using LlamaIndex for Semantic Search:
-
It is tailored to understand the intent and contextual meaning behind search queries, providing users with relevant and actionable search results.
-
Utilizing indexing capabilities to improve speed and accuracy, making it an effective tool for semantic search applications.
-
By optimizing indexing performance and following best practices suited to their application needs, developers can enhance the search experience.
Case Studies Highlighting Indexing Capabilities:
-
Data Indexing: LlamaIndex’s data indexing acts as a hyper-speed assistant for data search, enabling users to interact efficiently with data through Q&A and chat functionalities.
-
Engine: As the core of indexing and retrieval, the LlamaIndex engine provides a flexible structure that connects multiple data sources with LLMs, enhancing data interaction and accessibility.
-
Data Agents: LlamaIndex also includes data agents designed to manage “read” and “write” operations. They interact with external service APIs and handle unstructured or structured data, further enhancing the automation of data management.
Due to its fine control and adaptability, LangChain’s framework is specifically designed for building complex applications, including context-aware query engines. Here’s how LangChain facilitates the development of such complex applications:
-
Context-Aware Query Engines: LangChain allows for the creation of context-aware query engines that consider the context of queries, providing more precise and personalized search results.
-
Flexibility and Customization: Developers can leverage LangChain’s fine control to design custom query processing pipelines, which is crucial when developing applications that need to understand the subtle context of user queries.
-
Integration of Data Connectors: LangChain supports the integration of data connectors for easy data ingestion, facilitating the building of query engines that extract contextually relevant data from different sources.
-
Optimization for Specific Needs: Through LangChain, developers can optimize performance and fine-tune components to build context-aware query engines that meet specific needs and provide customized results, ensuring users have the best search experience.
Which Framework Should I Choose?
Understanding these unique aspects enables developers to choose the right framework based on their specific project needs:
-
If the application you are building places a strong emphasis on the efficiency and simplicity of search and retrieval, where high throughput and handling large datasets are critical, choose LlamaIndex.
-
If your goal is to build more complex, flexible LLM applications (potentially including custom query processing pipelines, multi-modal integration, and highly adaptive performance tuning needs), choose LangChain.
In summary, by recognizing the unique functionalities and differences between LlamaIndex and LangChain, developers can more effectively align their needs with the capabilities of these tools, thus building more efficient, powerful, and accurate search and retrieval applications powered by LLMs.