Selected from Medium
Author: Eugenio Culurciello
Translation by Machine Heart
Contributors: Liu Xiaokun, Siyuan
The author states: We have been trapped in the pit of RNNs, LSTMs, and their variants for many years; it is time to abandon them!
In 2014, RNNs and LSTMs were revived. We all read Colah’s blog “Understanding LSTM Networks” and Karpathy’s praise of RNNs “The Unreasonable Effectiveness of Recurrent Neural Networks.” But back then, we were all “too young too simple.” Now, sequence transformation (seq2seq) is the real answer to sequence learning, achieving superior results in tasks like speech-to-text understanding, enhancing the performance of Siri, Cortana, Google Assistant, and Alexa. Additionally, machine translation has progressed to translate text into multiple languages. Sequence transformation has also been effective in applications such as image-to-text, text-to-image transformations, and video captioning.
Between 2015 and 2016, ResNet and Attention models emerged. Thus, we learned that LSTM is merely a clever “bridge technique.” The attention model shows that MLP networks can be replaced “by averaging the influence of networks through context vectors.” This will be discussed further below.
After more than two years, we can finally say: “Abandon your RNN and LSTM routes!”
We can see that attention-based models are increasingly being used in AI research at Google, Facebook, and Salesforce. They have undergone a process of replacing RNN models and their variants with attention-based models, and this is just the beginning. RNN models were once the foundation of many applications, but compared to attention-based models, they require more resources to train and operate. (See: https://towardsdatascience.com/memory-attention-sequences-37456d271992)
Readers can refer to Machine Heart’s GitHub project to understand the concepts and implementations of RNNs and CNNs in sequence modeling.
Why?
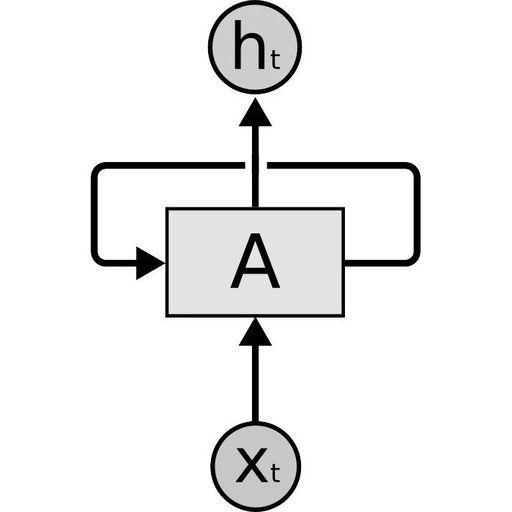
RNNs, LSTMs, and their variants primarily process sequential data for time series. As shown in the horizontal arrow section of the figure below:
Sequence processing in RNN, from “Understanding LSTM Networks”
These arrows indicate that long-term information must be sequentially passed through all previous units before accessing the current processing unit. This means it is prone to the gradient vanishing problem.
To address this, LSTM models were developed, which can be viewed as a combination of multiple gating mechanisms. ResNet also draws on this structure, allowing it to bypass certain units to remember information over longer time steps. Therefore, LSTM can somewhat overcome the gradient vanishing problem.
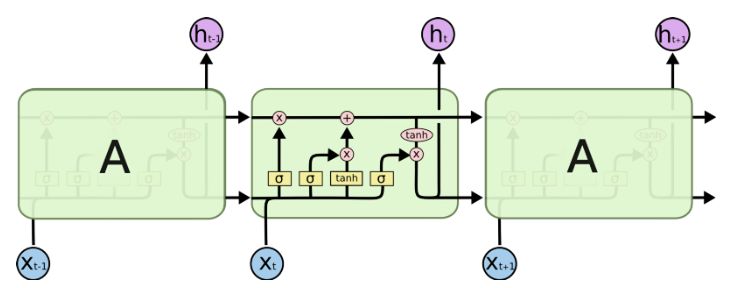
Sequence processing in LSTM, from “Understanding LSTM Networks”
However, this does not completely solve the issue, as shown in the figure above. There remains a sequential path from past units to the current unit in LSTM. In fact, these paths have become even more complex now, as they are also connected with branches for memory addition and memory forgetting. Undoubtedly, LSTMs, GRUs, and their variants can learn a substantial amount of long-term information (see “The Unreasonable Effectiveness of Recurrent Neural Networks”), but they can remember at most about 100s of long-term information, not 1000s or 10000s.
Moreover, a significant issue with RNNs is that they are very resource-intensive. If rapid training of RNNs is required, it necessitates a large amount of hardware resources. The cost of running these models in the cloud is also high, and with the rapid growth in demand for speech-to-text applications, cloud computing resources currently cannot keep up with this demand.
What is the solution?
If sequence processing is unavoidable, we should find computational units that can predict forward and review backward, as most real-time causal data we handle only knows past states and expects to influence future decisions. This is different from translating sentences or analyzing recorded videos, as we will utilize all the data and infer multiple times on the input. These forward-predicting and backward-reviewing units are the neural attention modules, which will be briefly introduced below.
To combine multiple neural attention modules, we can use the hierarchical neural attention encoder shown in the figure below:
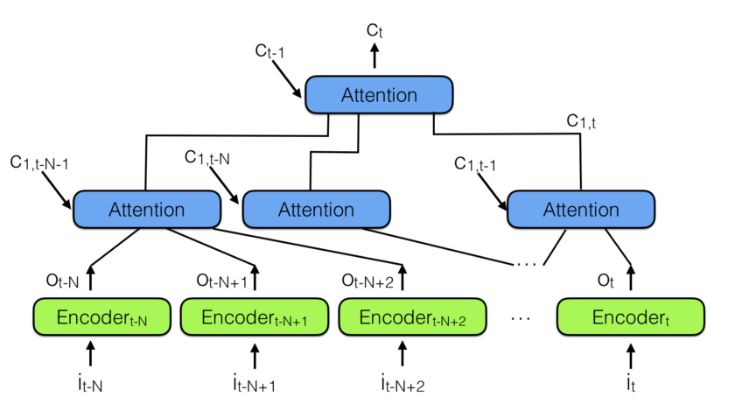
Hierarchical Neural Attention Encoder
A better way to observe past information is to use attention modules to aggregate past encoding vectors into context vector C_t. Note that there is a hierarchical attention module above, which is very similar to hierarchical neural networks.
In the hierarchical neural attention encoder, multi-layer attention can view a small portion of past information, such as 100 vectors, while the upper layer’s attention module can view 100 lower layer attention modules, i.e., 100×100 vectors. Utilizing hierarchical modules can greatly expand the range of observation for the attention mechanism.
This is a method that can review more historical information and predict the future.
This architecture is similar to the Neural Turing Machine, but it allows the neural network to decide what to read from memory through attention. This means that a practical neural network will determine which past vector is more important for future decisions.
But what about memory storage? Unlike the Neural Turing Machine, the architecture above will store all historical representations in memory. This can be inefficient, as it would store the representation of every frame in a video, and in most cases, the representation vectors do not change frame by frame, leading to excessive storage of redundant information. We can indeed add another unit to prevent storing related data, such as not storing vectors that are too similar to previous ones. But this is just a trick; a better approach might be to let the architecture decide for itself which vectors need to be stored and which do not. This issue is also a key focus in current research, and we can expect more interesting findings.
So, to summarize: Forget RNNs and their variants; all you need is the attention mechanism module.
Currently, we find that many companies still use RNNs/LSTMs as architectures for natural language processing and speech recognition, and they remain unaware of how inefficient and non-scalable these networks are. For instance, in RNN training, they are difficult to train due to requiring a large memory bandwidth, which is unfriendly to hardware design. Essentially, recursion is non-parallelizable, thus limiting the acceleration of parallel computing with GPUs and others.
In simple terms, each LSTM unit requires four affine transformations, and each time step must run once; this type of affine transformation demands a lot of memory bandwidth. Therefore, the actual reason we cannot use many computational units is that the system does not have enough memory bandwidth to transfer computations. This poses a significant limitation for model training, especially for system tuning, which is why many industrial applications are now turning towards CNNs or attention mechanisms.
Paper: Attention Is All You Need

Paper link: https://arxiv.org/abs/1706.03762
In the encoder-decoder configuration, the dominant sequence transduction model is based on complex RNNs or CNNs. The best-performing models also need to connect the encoder and decoder through the attention mechanism. We propose a new type of simple network architecture—Transformer, which is entirely based on the attention mechanism, completely abandoning recurrence and convolution. Experiments on two machine translation tasks show that these models have superior translation quality, are more parallelizable, and significantly reduce training time. Our model achieved a BLEU score of 28.4 on the WMT 2014 English-to-German translation task, surpassing the current best results (including ensemble models) by over 2 BLEU points. On the WMT 2014 English-to-French translation task, after training for 3.5 days on 8 GPUs, our model achieved a new top single-model BLEU score of 41.0, which is just a fraction of the best model’s training cost in the literature. We demonstrate that the Transformer generalizes well on other tasks, successfully applying it to English group analysis with both abundant and limited training data.
This article is translated by Machine Heart, Please contact this public account for authorization to reprint..
✄————————————————
Join Machine Heart (Full-time Reporter/Intern): [email protected]
Submissions or inquiries for coverage: [email protected]
Advertising & Business Cooperation: [email protected]