
Panchuang AI Share
Panchuang AI Share
We start with the following questions:
-
Recurrent Neural Networks can solve the problems present in Artificial Neural Networks and Convolutional Neural Networks. -
Where can RNNs be used? -
What is RNN and how does it work? -
Challenges of RNNs: vanishing and exploding gradients. -
How LSTM and GRU address these challenges.
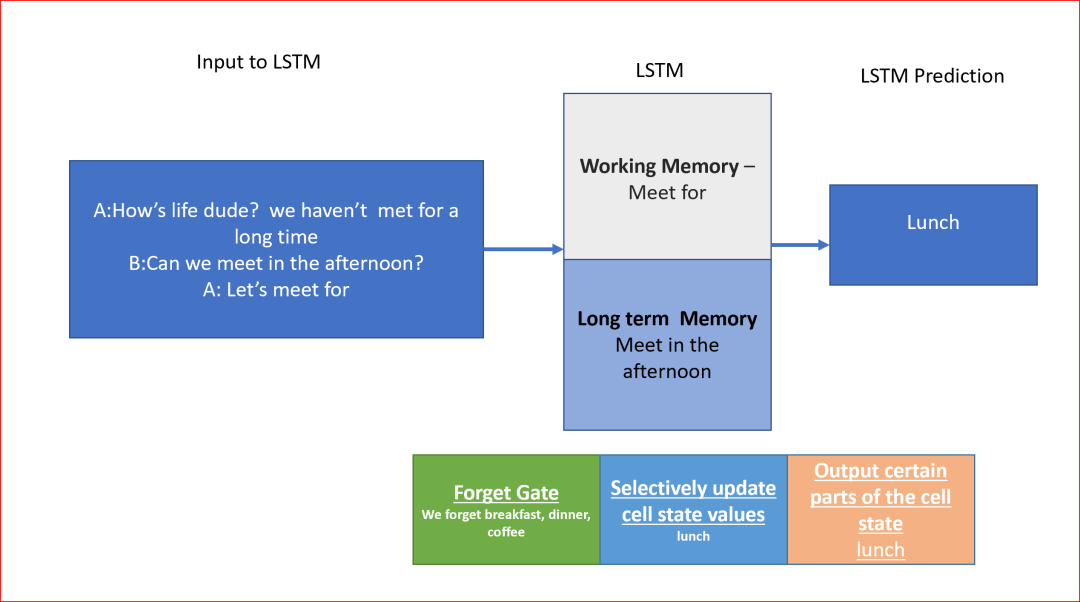
Assuming we are writing a message “Let’s meet for___”, we need to predict what the next word is. The next word could be lunch, dinner, breakfast, or coffee. We can more easily infer based on context. If we know we are meeting in the afternoon and this information has been retained in our memory, we can easily predict that we might meet for lunch.
When we need to process sequence data that requires multiple time steps, we use Recurrent Neural Networks (RNN).
Traditional neural networks and CNNs require a fixed input vector and apply activation functions on a fixed set of layers to produce a fixed-size output.
For example, we use an input image of size 128×128 to predict images of dogs, cats, or cars. We cannot make predictions with images of variable sizes.
Now, if we need to operate on sequence data that depends on previous input states (like messages), or where sequence data can be present in input or output, or both simultaneously, this is where RNNs come in.
In RNNs, we share weights and feed the output back into the recurrent input; this recurrent formula helps to handle sequence data.
RNNs utilize continuous data to infer who is speaking, what is being said, what the next word might be, and so on.
An RNN is a type of neural network that has cycles to retain information. RNNs are called recurrent because they perform the same task on each element in the sequence, and the output element depends on previous elements or states. This is how RNNs persist information to use context for inference.
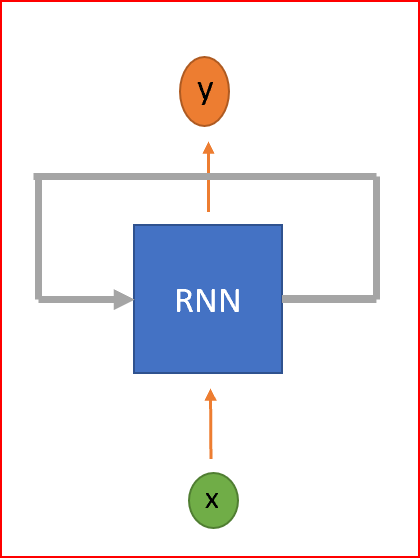
RNN is a neural network with cycles.
Where are RNNs used?
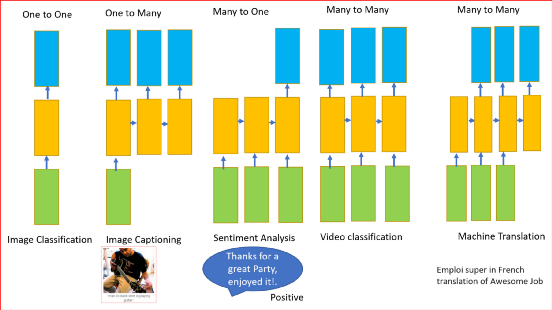
The RNN described above can have one or more inputs and one or more outputs, i.e., variable input and variable output.
RNNs can be used for:
-
Image classification -
Image captioning -
Machine translation -
Video classification -
Sentiment analysis
How does RNN work?
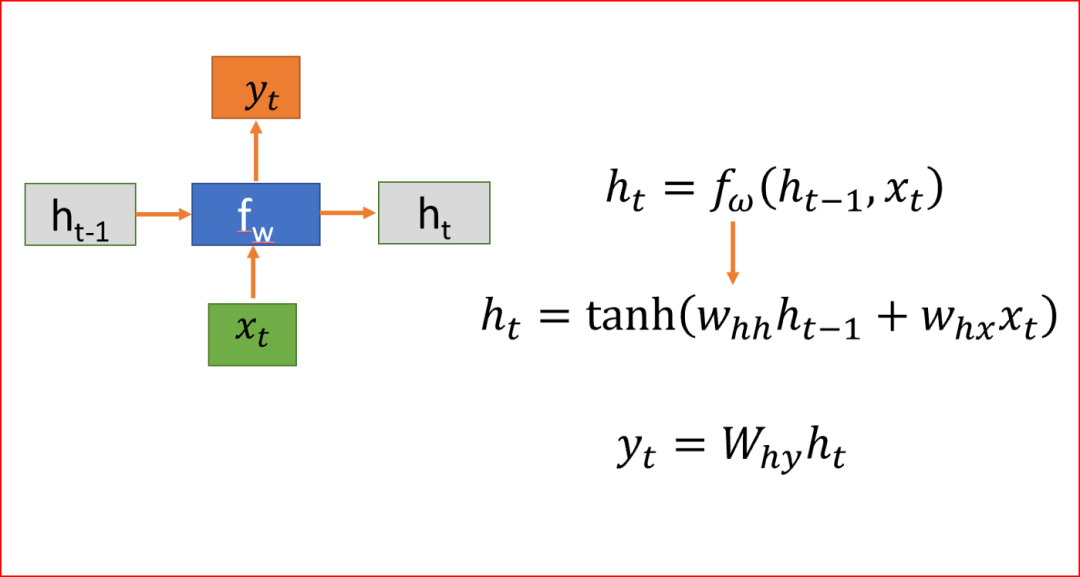
Let’s explain the symbols.
-
h is the hidden state -
x is the input -
y is the output -
W is the weight -
t is the time step
When we process sequence data, RNN takes an input x at time step t. RNN takes the hidden state value from time step t-1 to compute the hidden state h at time step t and applies the tanh activation function. We use tanh or ReLU to represent the non-linear relationship between the output and time t.
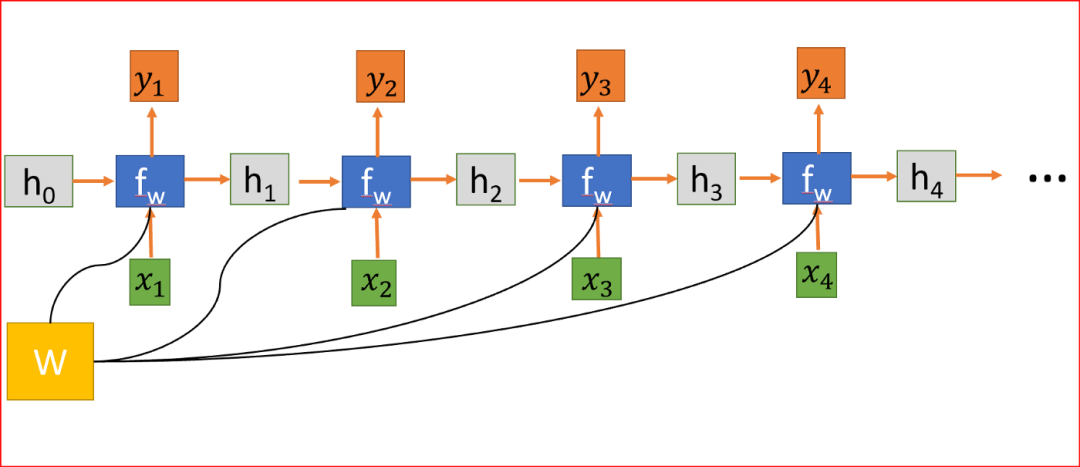
Unfolding the RNN into a four-layer neural network, sharing the weight matrix W at each step.
The hidden state connects information from previous states, acting as memory for the RNN. The output at any time step depends on the current input as well as previous states.
Unlike other deep neural networks that use different parameters for each hidden layer, RNNs share the same weight parameters at each step.
We randomly initialize the weight matrix, and during training, we need to find values for the matrix that yield ideal behavior, so we compute the loss function L. The loss function L is calculated by measuring the difference between the actual output and the predicted output. We calculate L using the cross-entropy function.
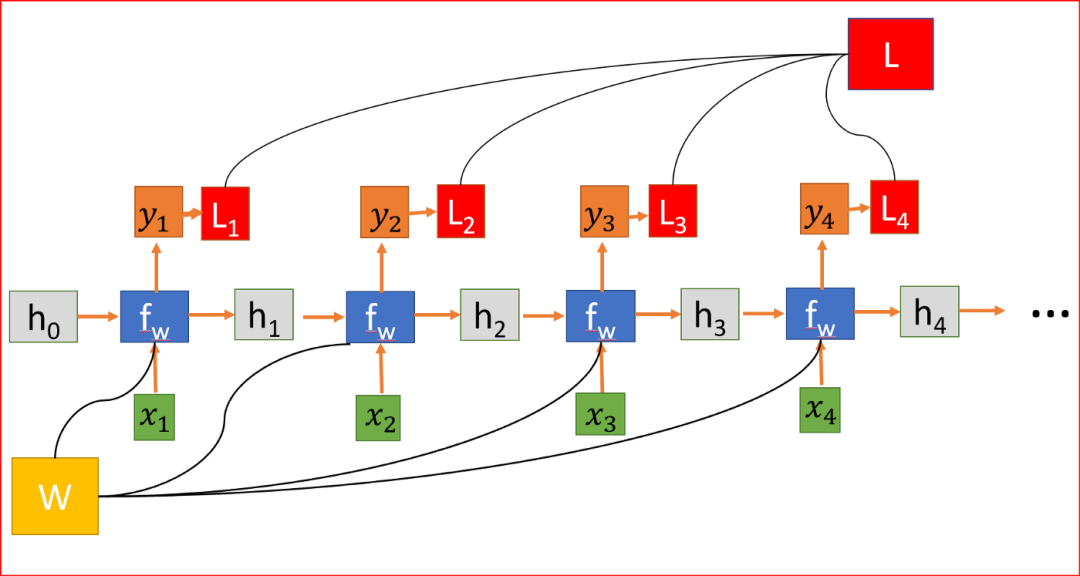
RNN, where the loss function L is the sum of losses from all layers.
To minimize loss, we use backpropagation, but unlike traditional neural networks, RNNs share weights across multiple levels, meaning it shares weights across all time steps. Thus, the error gradient at each step also depends on the loss from the previous step.
In the above example, to compute the gradient at step 4, we need to sum the losses from the first three steps and the loss from step 4. This is called backpropagation through time (BPTT).
We compute the gradient of the error with respect to the weights to learn the correct weights for ideal output.
Since W is used at every step until the final output, we backpropagate from t=4 to t=0. In traditional neural networks, we do not share weights, so we do not need to sum gradients, while in RNNs, we share weights and need to sum the gradients of W at each time step.
Calculating the gradient of h at time step t=0 involves many factors of W since we need to backpropagate through each RNN unit. Even if we do not take the weight matrix and multiply by the same scalar value repeatedly, if the time steps are particularly large, say 100 time steps, this will be a challenge.
If the maximum singular value is greater than 1, the gradient will explode, known as exploding gradient.
If the maximum singular value is less than 1, the gradient will vanish, known as vanishing gradient.
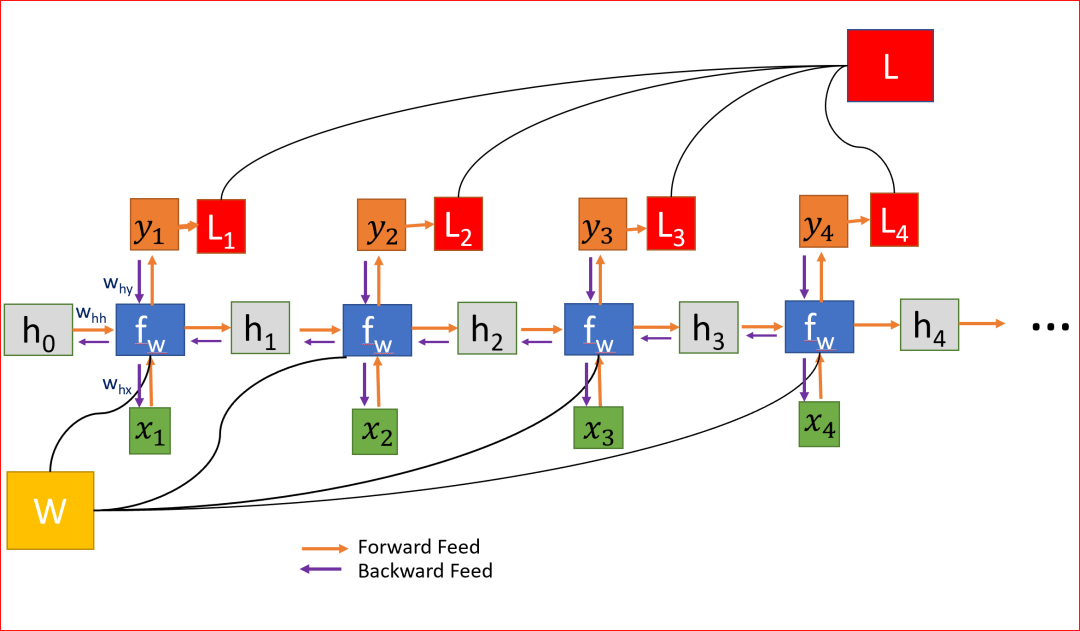
Sharing weights across all layers leads to gradient explosion or vanishing.
To address the exploding gradient issue, we can use gradient clipping, where we can set a threshold in advance, and if the gradient value exceeds the threshold, we can clip it.
To solve the vanishing gradient problem, commonly used methods are Long Short-Term Memory (LSTM) or Gated Recurrent Units (GRU).
In our message example, to predict the next word, we need to go back several time steps to understand the previous words. There is a possibility of having enough gap between two related pieces of information. As the gap widens, RNNs struggle to learn and connect the information. But this is the powerful feature of LSTM.

Long Short-Term Memory Networks (LSTM)
LSTMs can learn long-term dependencies more quickly. LSTMs can learn across time intervals of up to 1000 steps. This is achieved through an efficient gradient-based algorithm.
To predict the next word in the message, we can store context at the beginning of the message, so we have the correct context. This is exactly how our memory works.
Let’s delve into the LSTM architecture to understand how it works.

LSTMs operate by remembering information over long periods, so they need to know what to remember and what to forget.
LSTM uses four gates, which you can think of as deciding whether to remember the previous state. The cell state plays a crucial role in LSTMs. LSTMs can use four regulating gates to decide whether to add or remove information from the cell state.
These gates act like faucets, determining how much information should pass through.

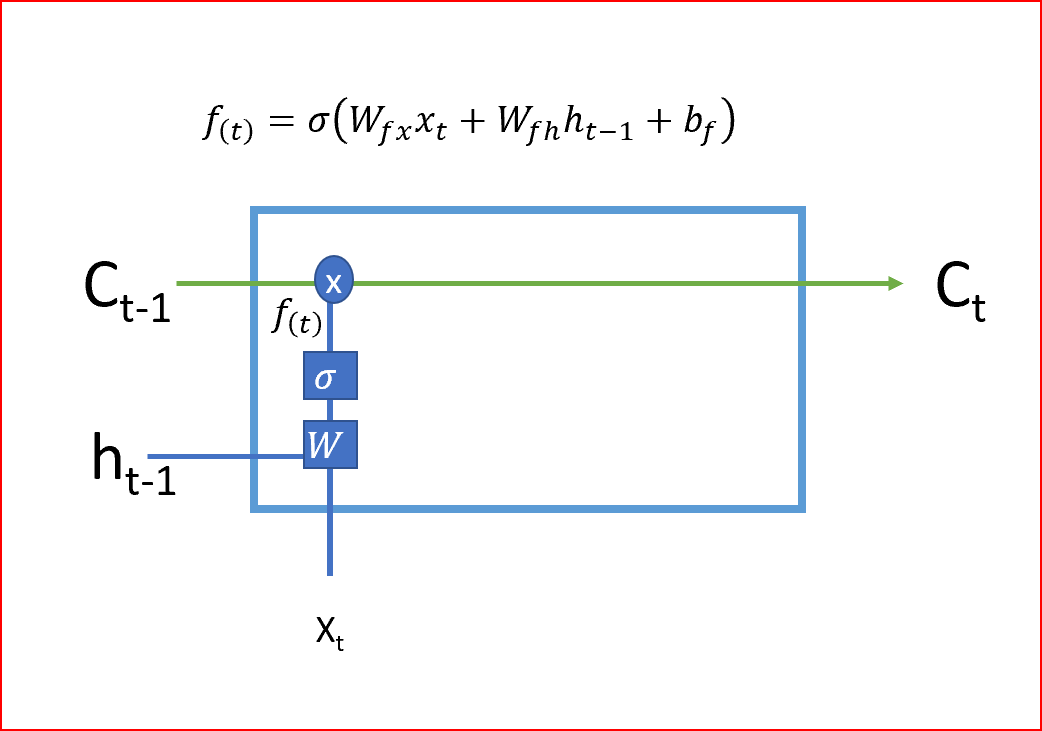
-
The first step of LSTM is to decide whether we need to remember or forget the cell’s state. The forget gate uses a Sigmoid activation function, outputting values of 0 or 1. An output of 1 from the forget gate tells us to keep that value, while a value of 0 tells us to forget that value.
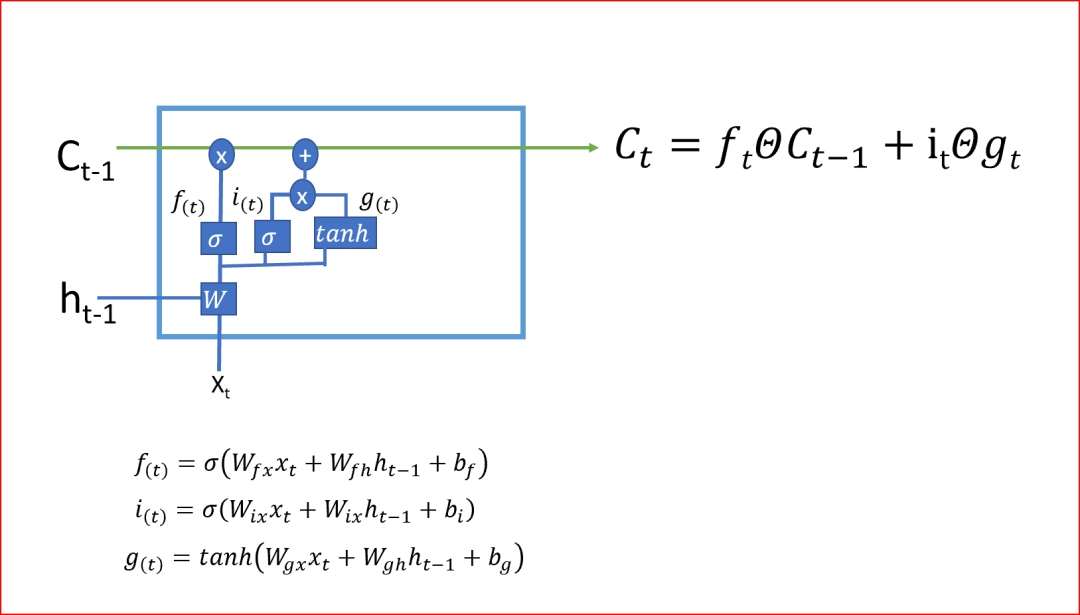
-
The second step decides what new information we will store in the cell state. This has two parts: one part is the input gate, which uses the sigmoid function to decide whether to write to the cell state; the other part uses the tanh activation function to determine what new information is added.

-
In the final step, we create the cell state by combining the outputs of steps 1 and 2, where the outputs of steps 1 and 2 are multiplied by the output of the output gate after applying the tanh activation function to the current time step. The tanh activation function gives an output range between -1 and +1.
-
The cell state is the internal memory of the unit, which multiplies the previous cell state by the forget gate and then multiplies the newly computed hidden state (g) by the output of the input gate i.
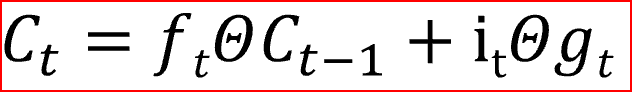
Finally, the output will be based on the cell state.
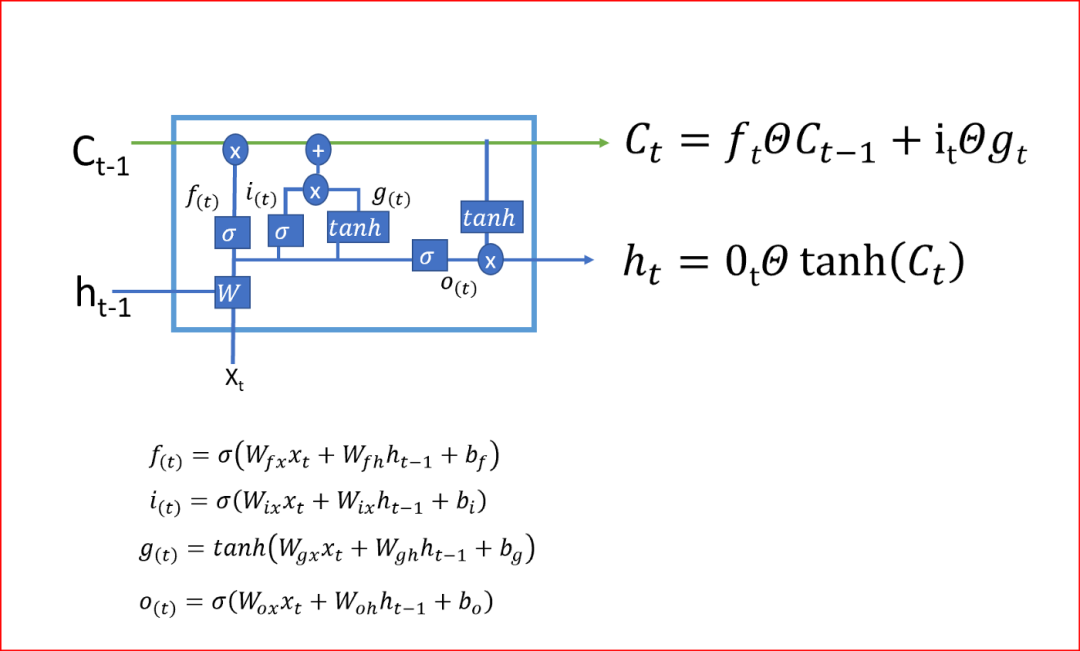
The backpropagation from the current cell state to the previous cell state only involves multiplying the forget gate’s cell without multiplying the weight matrix W, which utilizes the cell state to eliminate the vanishing and exploding gradient problems.
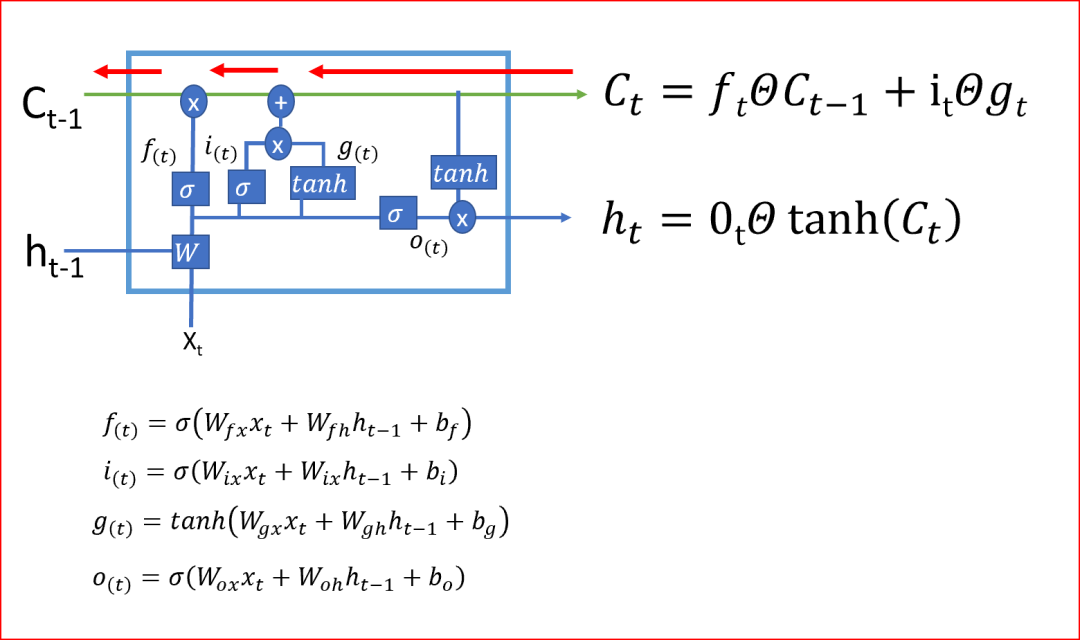
LSTM decides when and how to transition memory at each time step by determining what to forget, what to remember, and what information to update. This is how LSTMs help store long-term memory.
Here’s an example of how LSTM predicts in our message.
GRU, A Variant of LSTM
GRU uses two gates, a reset gate and an update gate, differing from the three steps in LSTM. GRU does not have internal memory.
The reset gate decides how to combine new inputs with the memory from the previous time step.
The update gate determines how much of the previous memory should be retained. The update gate is a combination of the input gate and the forget gate we understand in LSTM.
GRU is a simpler variant of LSTM to address the vanishing gradient problem.
Original link: https://medium.com/datadriveninvestor/recurrent-neural-network-rnn-52dd4f01b7e8
If you liked this article, please click “Read” or feel free to “Share” or “Like“.

Past Highlights
Suitable routes and materials for beginners to enter AI
Machine learning and deep learning notes and materials printing
Online manual for machine learning
Collection of deep learning notes
Code reproduction collection of "Statistical Learning Methods"
AI Basics Download
Mathematical foundations of machine learning collection
Get a discount coupon for our knowledge circle by copying the link and opening it directly:
https://t.zsxq.com/yFQV7am
Join our QQ group 1003271085.
Scan the code to join the WeChat group: