Join Leifeng Network to share the information dividend of the AI era and walk alongside the intelligent future. It is said that the experts have clicked here.

In 2016, Google released a brand new neural machine translation system (GNMT) and claimed that due to the intervention of neural network algorithms, this system reduced the error rate by 80% compared to traditional machine translation, nearing the level of human translation.
However, there are differing opinions within the industry regarding Google’s release and whether neural networks (or deep learning) algorithms are truly suitable for natural language processing.
Recently, Riza C. Berkan, founder of the American AI company exClone and chairman of superconducting materials company Epoch Wires, published an article on his blog expressing his views on this issue. He believes that Google’s GNMT system is merely a gimmick and that due to the inherent characteristics of natural language, it is fundamentally unsuitable to process with existing neural network algorithms.
Natural Language is Not a Continuous Process
The author believes that the technical characteristics of neural network algorithms determine that they are more suitable for processing continuous variables or continuous processes, where there is a continuous change relationship between independent and dependent variables (such as temperature changes), rather than a jump-like change (such as a person’s bank balance changes). However, natural language, purely from the perspective of word composition, is not a continuous process; natural language is a non-continuous change produced by various non-continuous processes such as grammatical rules, logical thinking, and progressive decision boundaries.
For example, the sentence “Mary loves her cat” is non-continuous from the perspective of word composition. Because the relationship between Mary and the cat is not logically continuous, but rather a random incidental relationship (Mary can love anything, not necessarily a cat). If this incidental change relationship is directly used to train the neural network system, the system will miss the training focus and fail to achieve the expected output effect.
However, if we reorganize the above sentence: {Proper Noun-Mary: human female}{Verb-love: emotional attachment}{Noun-cat: pet}, we can achieve a relatively more continuous data structure. Because from a cognitive perspective, “human female has emotional attachment to pets” is more consistent than “Mary loves cats.” If we input such data into the neural network system for training, we can achieve an ideal effect.
It should be noted that the latter organization method is not simply a part-of-speech parsing, but a logical cognitive recognition, which requires a large amount of human and material resources to achieve. Currently, there is no reliable machine method to replace manual efforts, which also explains why training neural network systems based on word composition has not achieved significant breakthroughs in the past 30 years.
What Happens if We Insist on Using Neural Networks?
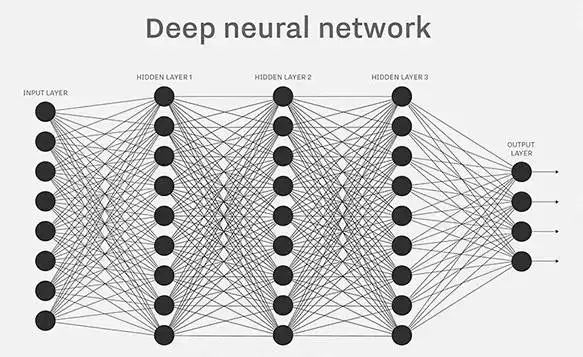
As shown in the figure, a typical multi-layer neural network model is assumed here, where the input and output are both based on natural language text data (for example, in scenarios like machine translation or machine chatting), and then using common neural network algorithms like backpropagation for training. Perhaps in the end, this system can converge, but the author believes that its effectiveness in problem-solving cannot be guaranteed.
If the training is conducted using the first data organization method mentioned above, that is, based on word composition analysis, due to the non-continuity of the data, the final result will only yield a statistical vocabulary combination. At this point, the neural network has not “understood” the true meaning of the text. In other words: it ultimately only achieves a simple mapping between vocabulary, and this mapping does not change with variations in semantics.
Even if vectorization is applied to the data or other neural network implementation architectures are used, this phenomenon will not change. Because fundamentally, the non-continuity of the data forces the neural network system to allocate storage units for each decision boundary (for each non-continuous state), similar to neurons in the human neural network system. This is akin to allocating separate storage space for each data element in database processing, which inherently contradicts one of the greatest advantages of neural network systems: the high correlation between data.
The result of training with such data is: when inputting samples that are highly similar to the training data, acceptable results may be obtained. However, once the input sample differs significantly from the training data, it is likely to yield a pile of garbled data, because no mapping relationship from the previous training can be found in the non-continuous data available for analysis and utilization. In other words, the effectiveness of the system output will be very limited to the similarity between the input samples and the training data set.
In contrast, if continuous data is used for training, i.e., the second data organization method mentioned above, based on cognitive concept analysis, the neural network system will maintain strong reproducibility and flexibility for the logical connections learned during training. Just like the human brain, while ensuring a certain level of fault tolerance, it can establish universal correlations between each storage unit. Such a neural network system actually possesses a certain logical inference capability, which is also the reason why neural network systems are widely applied in engineering fields.
Some engineers may attempt to preprocess using vectorization and dimensionality reduction methods to forcibly convert raw data into continuous data. However, this may lead to a significant side effect: loss of information. A certain degree of information loss may be acceptable in feature detection and classification fields (e.g., image processing), but it is entirely different in the language domain. Because whether it is an entire text or a single sentence, language is not merely a statistical quantity of vocabulary, but a byproduct based on concepts and cognition. Statistical methods may aid in natural language processing, such as addressing the “fat tail” phenomenon in language processing, or assisting neural network algorithms beyond training data through vectorization, but they are not the ultimate solution. It is essential to clarify that: neither neural networks nor statistical methods can cover all issues in natural language processing based on word composition analysis; some scenarios must rely on cognitive concept-based analysis methods.
Is Google Translate Just Hype?
The author also mentions Google’s latest GNMT system, stating: Since we cannot access the original data used by Google to train the neural network system, we cannot determine whether the sample translation sentences provided by Google are closely related to the original training data, and thus cannot assess whether its high translation accuracy has any reference value.
On the other hand, Google has not disclosed the specific training parameters of the GNMT system, including the convergence level of the neural network model, whether it only works on part of the training data set, what the reasons for translation errors are, and the frequency of errors, etc.
From these details, we can ascertain: Google’s release of the GNMT system is not aimed at overturning academia; otherwise, if it were not for the security considerations of technical details, Google would certainly disclose various training parameters of the neural network.
This point can also be verified in Google’s announcement, as follows: Rekimoto tweeted this discovery to his more than 100,000 followers, and in the subsequent hours, thousands of users broadcast their test results using Google Translate on Twitter, some translations were correct, while others intentionally misspelled words for humor.
The Data Volume Issue
When using neural network algorithms to address natural language issues, another easily overlooked problem is the volume of data.
The author provides an analogy: Suppose we use a volume of 10,000 pages of text data to train the neural network model. How much is the total knowledge reserve of humanity worldwide? This is clearly an astronomical number that cannot be calculated. Let’s assume the total knowledge amounts to 10 to the power of 21 pages. The question arises: how can the neural network master all the knowledge contained in 10 to the power of 21 pages with only 10,000 pages of training data? The answer is: the available training data volume is simply too small.
On the other hand, for experts in grammar rules and semantic understanding, it is evident that the human brain can fully master all the knowledge contained in 10 to the power of 21 pages (because this knowledge is written by those experts). More crucially, any ordinary person, as long as they possess basic reading and writing skills, can gradually master the complete knowledge of 10 to the power of 21 pages through self-learning. The author believes that this is the most frightening aspect of the human brain compared to current neural network models, namely the true learning ability.
About “Bricks” and “Bridges”
The author believes that to perfectly solve the problem of natural language processing, it is essential to find a new machine learning method that can master grammar and semantics, rather than a simple mapping between vocabulary. Here, the author illustrates with the example of “bricks” and “bridges.”

Currently, scientists have merely drawn inspiration from the basic principles of how the human brain’s neural network processes real-world problems to construct the current neural network model. Just like the relationship between bricks and bridges in the figure, without understanding the deep mechanisms of how the human brain processes problems, it is like seeing only bricks and not the bridge; therefore, the current neural network model only simulates the human brain on a microscopic structure and has not realized a complete problem-solving framework, and this macro framework may be the key to addressing difficult issues such as natural language understanding. The author refers to this framework as a network built on neural networks, i.e., a “network of networks.” It is important to emphasize that this “network of networks” is not a simple increase in the layers of the existing neural network model or a change in the internal feedback direction, but a more advanced organizational form.
The author states that this macro problem-solving framework of the human brain is crucial, and until biologists crack this deep mystery, we can only wait patiently. Until then, the so-called “deep learning” may only be termed “deep darkness.”
So returning to the question of Google Translate, is Google really just hype? The answer may be affirmative. The author believes: Since our understanding of the human brain’s neural network system is still at a very superficial stage, almost all statements claiming that we have fully mastered the key technologies and achieved significant breakthroughs can be regarded as “hype.” The author also humorously remarks: Of course, there are exceptions, such as if Google has secretly deciphered the deep working principles of the human brain’s neural network system, thus discovering the “bridge” made up of numerous “bricks.”
Source: LinkedIn

|
Click on the keywords to view related historical articles ● ● ● Popular Articles How did the mini-program perform on its first day of launch? Let’s hear what the first batch of companies has to say Sun Jian: My six months at Face++ How Hasselblad Ruined a Good Hand iPhone Ten Years: Looking Back on the Legendary Birth of This Great Product Faraday Future Releases New Car, Can It Extend LeEco’s Life by One Second? Taking the Main Stage at CES, Nvidia Awaits the Explosion of GPU Computing ● ● ● Mini Program | Zuckerberg’s Development Notes | Shared Bicycles GoPro | Spring Festival Ticketing Principles | AI Beauty IoT Year-End Review | AI Medical Imaging Company Review Huawei 5G | Autopilot 2.0 | JD X Division Commercial Sex Robots | Taobao Buy+ | Zhang Xiaolong’s Internal Speech Xiaomi MIX | Xiaomi VR | Huawei Kirin 960 Smartisan M1/M1L | Loongson 3A3000 | Samsung Note 7 Dji “Mavic” | Google Home Domestic Multi-Line Laser Radar | Google Daydream VR Headset |