
Selected from Medium
Author:Harshvardhan Gupta
Compiled by Machine Heart
Contributors: Liu Xiaokun, Lu Xue
Last year, Facebook published a paper titled “Unsupervised Machine Translation Using Monolingual Corpora Only,” proposing unsupervised machine translation using monolingual corpora. Recently, an article on Medium interpreted this paper, and Machine Heart has compiled an introduction to it.
Deep learning is widely used in daily tasks, particularly excelling in areas that involve a degree of “humanity,” such as image recognition. Perhaps the most useful feature of deep networks is that their performance improves with more data, which is different from traditional machine learning algorithms.
Deep networks perform well in machine translation tasks. They are currently the best solution for this task and are practical, with even Google Translate using them. Machine translation requires sentence-level parallel data to train models, meaning that for each sentence in the source language, there is a corresponding translation in the target language. The challenge lies in the difficulty of obtaining large datasets for certain language pairs (to leverage the power of deep learning).
Issues with Machine Translation
As mentioned, the biggest issue with neural machine translation is the need for bilingual data sets. For widely used languages like English and French, such data is relatively easy to obtain, but this is not necessarily the case for other language pairs. If bilingual data can be obtained, then the problem becomes a supervised task.
Solutions
The authors of the paper point out how to transform this task into an unsupervised task. In this task, the only required data is any corpus in each of the two languages, such as English novels vs. Spanish novels. Note that the two novels do not have to be the same.
In other words, the authors discovered how to learn the shared latent space between the two languages.
A Brief Review of Autoencoders
An autoencoder is a broad category of neural networks used for unsupervised tasks. They can recreate the same input as the input fed into them. The key feature is that there is a layer in the autoencoder known as the bottleneck layer. This layer captures all the interesting information from the input while discarding useless information.
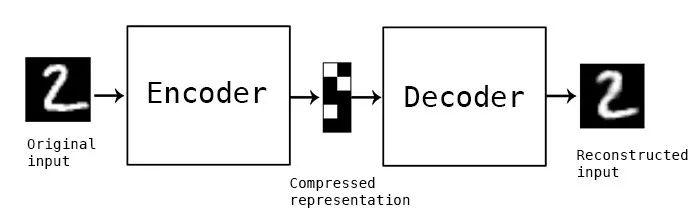
Illustration of an autoencoder. The middle module is the bottleneck layer that stores compressed representations. (Image source: https://blog.keras.io/building-autoencoders-in-keras.html)
In short, the space where the input in the bottleneck layer (transformed by the encoder) resides is the latent space.
Denoising Autoencoders
If an autoencoder can learn to perfectly reconstruct the input as received, then it might not learn anything at all. In this case, the output can be perfectly reconstructed, but there are no useful features in the bottleneck layer. To address this, we can use a denoising autoencoder. First, some noise is added to the input, and then a network is constructed to reconstruct the original image (the version without noise). In this way, by making the network learn what noise is (and what features are truly useful), it learns useful features of the image.
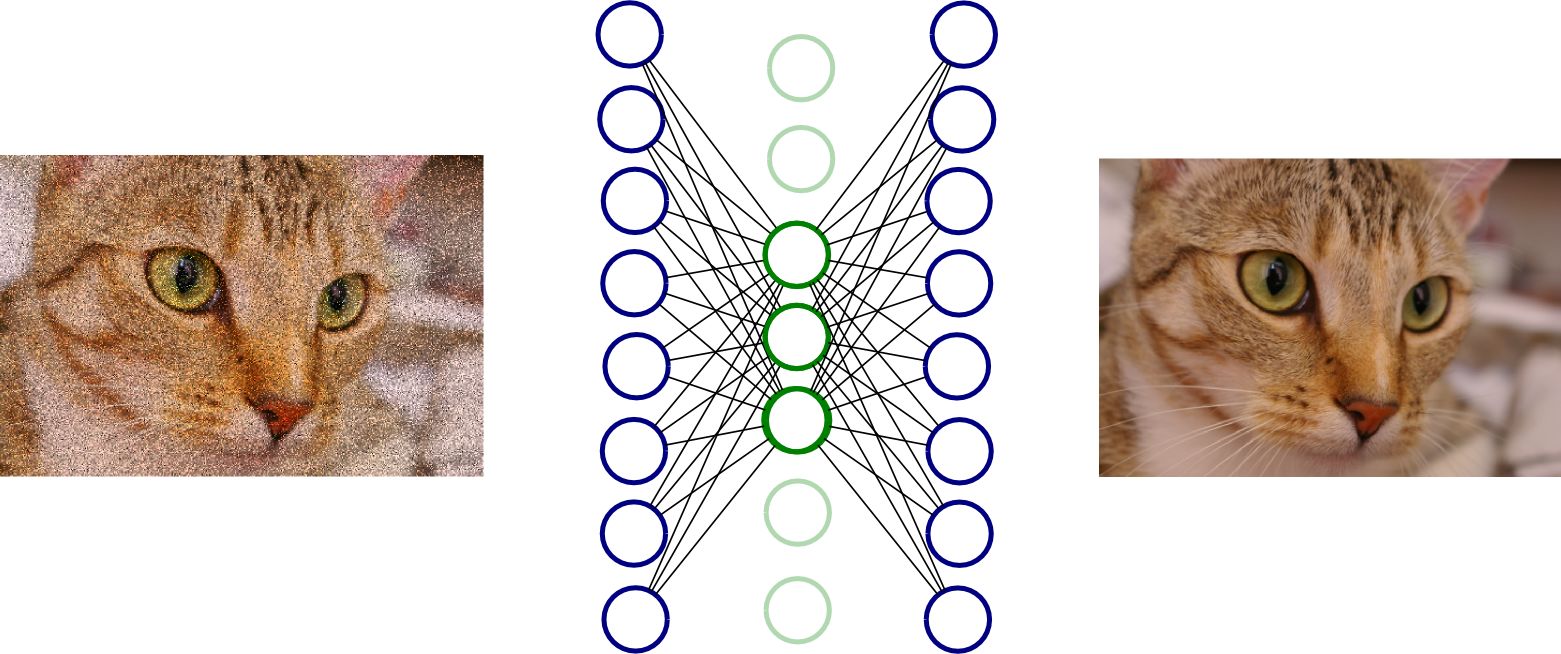
Illustration of a denoising autoencoder. The neural network reconstructs the left image to generate the right image. In this example, the green neurons represent the bottleneck layer. (Image source: http://www.birving.com/presentations/autoencoders/index.html#/)
Why Learn Shared Latent Space?
The latent space captures the features of the data (in machine translation, the data consists of sentences). If we can learn a space where the input-output characteristics of language A and language B are the same, then translation between these two languages can be achieved. Since the model has already learned the correct “features,” it can encode using the encoder for language A and decode using the decoder for language B to complete the translation.
As you might expect, the authors of the paper use denoising autoencoders to learn the feature space. They also point out how to make the autoencoder learn a shared latent space (referred to as aligned latent space in the paper) to perform unsupervised machine translation.
Denoising Autoencoders in Language
The authors use denoising autoencoders to learn features in an unsupervised manner. The loss function defined is:
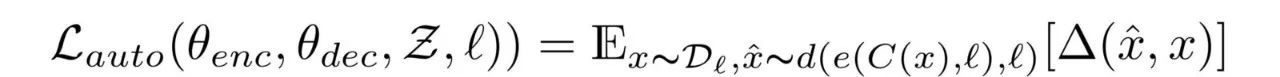
Equation 1.0 Denoising Autoencoder Loss Function
Explanation of Equation 1.0
l is the language (there should be two possible languages as per its settings), x is the input, C(x) is the result after adding noise to x. e() is the encoder, d() is the decoder. The Δ(x_hat, x) term at the end of the equation is the total cross-entropy error at the token level. Since the output sequence is obtained from the input sequence, we need to ensure that each token is arranged in the correct order. Thus, the loss function in the equation is derived. It can be viewed as a multi-label classification problem, where the i-th token in the input is compared with the i-th token in the output. A token is a unit that cannot be further decomposed. In machine translation, a word is a token.
Therefore, the purpose of Equation 1.0 is to minimize the difference between the network’s output (given the noisy input) and the original statement.
How to Add Noise
Noise in image processing can be added by introducing floating-point numbers into pixels, while adding noise in language is different. Therefore, the authors of the paper developed their own noise generation system. They denote the noise function as C(). C() takes the input statement and outputs a noisy version of that statement.
There are two methods to add noise.
One is to remove a word from the input with a probability of P_wd;the other is to shift each word according to the constraint in the following formula:
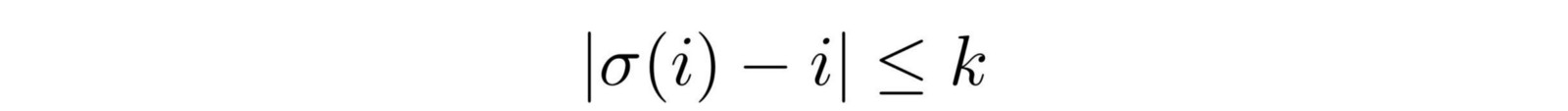
Here, σ is the position after the i-th token is shifted. Thus, the meaning of the above equation is that “a token can deviate from its original position by at most k tokens.”
The k value used by the authors is 3, and the P_wd value is 0.1.
Cross-Domain Training
To learn mutual translation between the two languages, a process that maps the input sequence (language A) to the output sequence (language B) must be constructed. The authors refer to this learning process as cross-domain training. First, a sample input statement x is taken, and then the model M() from the previous iteration generates the translated output y, i.e., y=M(x). After that, the noise function C() is applied to y to obtain C(y). The encoder for language A encodes C(y), and then the decoder for language B decodes it, reconstructing the noise-free version of C(y). The same total cross-entropy error, similar to Equation 1.0, is used during model training.
Learning Shared Latent Space Through Adversarial Training
The paper does not mention how to learn the shared latent space. The aforementioned cross-domain training might help learn similar spaces to some extent, but to get the model to learn similar latent spaces, a stronger constraint needs to be added.
The authors used adversarial training. They employed another model called a discriminator, which takes the output from each encoder as input and predicts the language to which the encoded statement belongs. Then, the encoder must also learn to deceive the discriminator. This is conceptually similar to standard GANs. The discriminator predicts the type of language the input belongs to through the feature vector at each time step (due to the use of RNN).
Integrating All Parts
The three different losses (autoencoder loss, translation loss, and discriminator loss) mentioned above are combined, and all model weights are updated in a single step.
Since this is a sequence-to-sequence problem, the authors used LSTM networks combined with attention mechanisms, i.e., there are two LSTM-based autoencoders, one for each language.
There are three main steps when training this architecture. The training process is iterative. The training loop consists of the following three steps:
1. Translate using the encoder for language A and the decoder for language B;
2. Given a noisy statement, train each autoencoder to regenerate a denoised statement;
3. Add noise to the translated statement obtained in step 1 and regenerate it to enhance translation capability. In this step, the encoder for language A and the decoder for language B (as well as the encoder for language B and the decoder for language A) need to be trained together.
Note that although steps 2 and 3 are separate, the weights are updated synchronously.
How to Quickly Start This Framework
As mentioned above, the model uses previously iterated translations to enhance its translation capability. Therefore, it is important to have some form of translation capability before the training loop begins. The authors used FastText to learn a word-level bilingual dictionary. Note that this method is quite rough and is only used at the start of the model.
The complete structure of the framework is shown in the flowchart below:
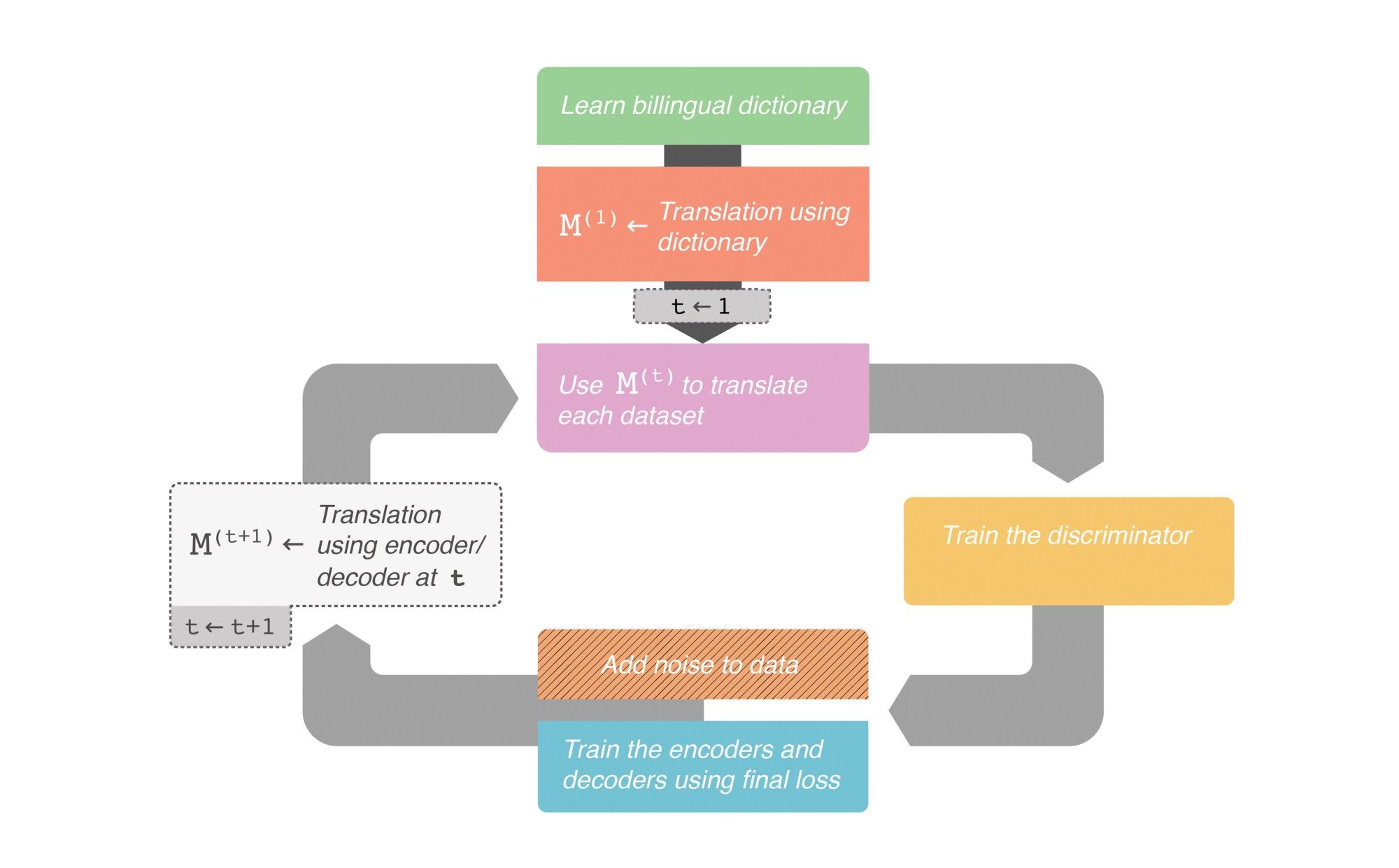
High-level flowchart of the complete translation framework. (Image source: http://robertaguileradesign.com/)
Conclusion
This article introduces a very new unsupervised machine translation technique. It uses various loss functions to enhance individual tasks while employing adversarial training to add constraints to the architecture’s behavior.
Original link: https://buzzrobot.com/machine-translation-without-the-data-21846fecc4c0
This article is compiled by Machine Heart, please contact this public account for authorization to reprint.
✄————————————————
Join Machine Heart (Full-time Reporter/Intern): [email protected]
Submissions or inquiries: [email protected]
Advertising & Business Cooperation: [email protected]