

Author: David 9
Address: http://nooverfit.com/
RNN seems to be better at information preservation and updating, while CNN seems to excel at precise feature extraction; RNN has flexible input and output dimensions, while CNN dimensions are relatively rigid.
1Question
When talking about Recurrent Neural Networks, our first reaction might be: time sequence.
Indeed, RNNs are good at time-related applications (natural language, video recognition, audio analysis). But why can RNNs handle time sequences better than CNNs? Why have we previously mentioned that RNNs have a certain memory capacity?
2General Prediction
Mathematically, if we want to predict the next word y after a word x, we need three main elements (the input word x; the context state h1 of x; a function to output the next word based on x and h1, such as softmax):
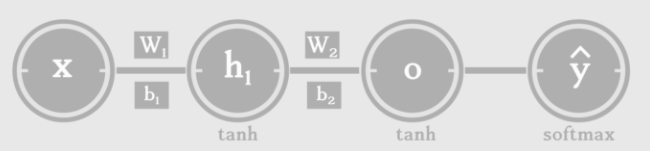
Source: http://suriyadeepan.github.io/2017-01-07-unfolding-rnn/
The mathematical calculation is as follows:
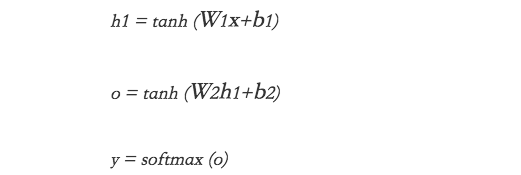
The above is a very simple directed acyclic graph (DAG), but this is just a prediction of the word at time t, such a simple prediction can even be replaced by CNN or other simple prediction models.
3Introduction to RNN
However, CNNs are not good at updating state or preserving state. We know that at the next time point t+1, the context (state) of word x has changed:
Therefore, the different threshold structure of RNN and the convolutional structure of CNN (different ways of preserving information) also cause RNNs to excel at handling time sequence problems. Even if we do not use threshold networks but other models, we still need a similar cyclic structure as shown in the image above, to update the context state at each time point and preserve it.
Thus, in applications involving time sequences, updating the state at each time point is so important that we need networks like RNN:
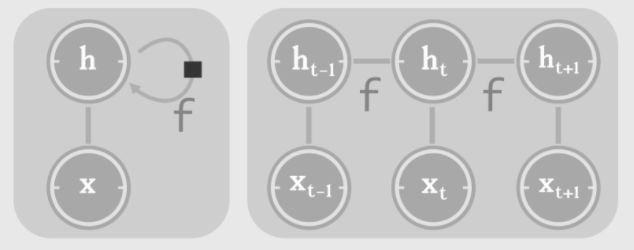
At each time point, the same update function f is used to update the context state, and the state at each time point t is based on the state of the previous time point t-1 and the input of the current signal xt:
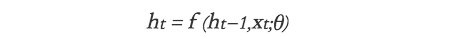
Additionally, RNN’s threshold network has a natural Markovization property, where the current state S3 after multiple cycles already contains information from several time points ago (where the semicolon represents encoding previous states with parameters θ):
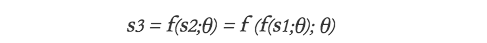
The current prediction only needs to be based on the current state. This immense ability to preserve state information seems to be what RNN threshold units excel at. (CNNs seem to be better at precise feature extraction).
Traditional RNN processes one word at each time t, generating another word, but the reality is not always so simple.
4Variants of RNN
Finally, let’s look at some variants of RNN structures.
Vector to Sequence
There are some applications, such as outputting captions for an image:

This type of RNN requires inputting the feature vector of the image x (such as the last hidden layer of CNN) and outputting a sentence caption, but the words of this sentence y are generated one by one.
This requires RNN to generate a time sequence from a single vector at once:
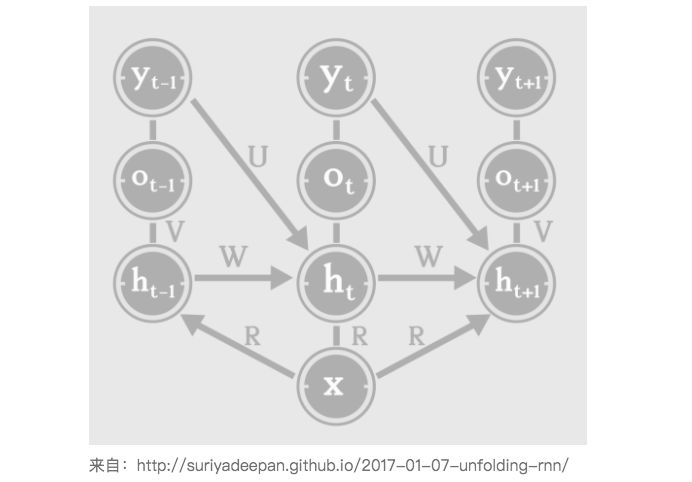
Of course, the generation of the time sequence follows the rule of cyclically updating the internal state in chronological order.
5Sequence to Sequence (seq2seq)
In machine translation problems, such as translating an English sentence into a French sentence, the number of corresponding words may not be equal. Therefore, traditional RNNs need to be modified.
A common approach is to use two RNNs, one RNN to encode the sentence (encoder), and another RNN to decode it into the desired language (decoder):
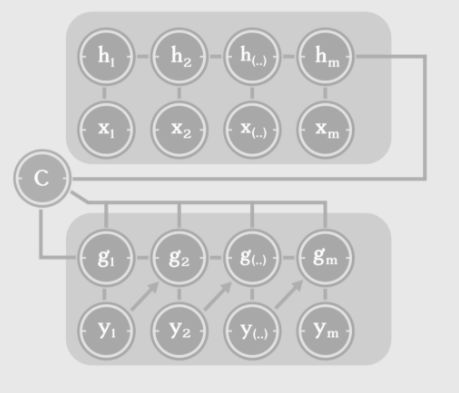
Here, C is the context information, which, along with the encoded hidden layer information, is sent as input to the decoder for translation.
6Bidirectional RNN:
Traditional RNNs predict a word by only capturing the context state before that word, while Bidirectional RNNs also capture the influence of the words following that word:
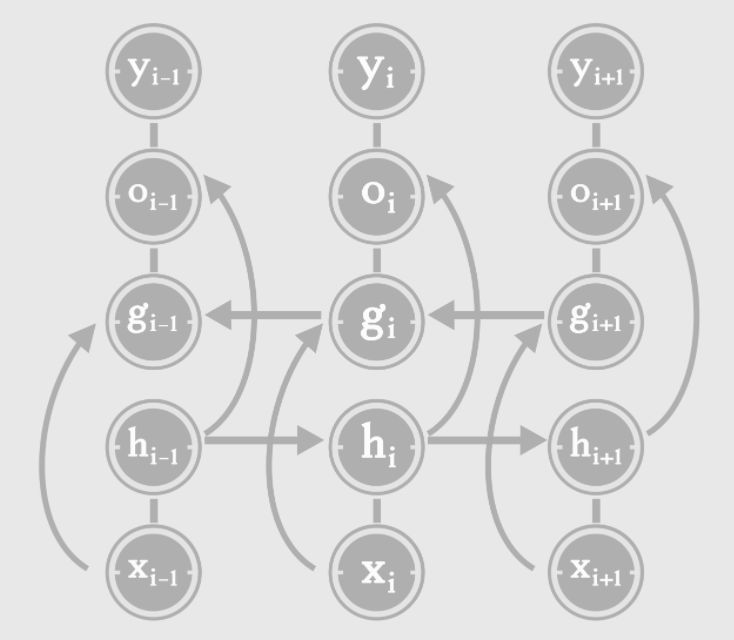
The Bidirectional RNN in the above image can actually be seen as two RNNs, one RNN is the traditional RNN we mentioned earlier (with only the hidden state h layer); and the other RNN captures the word environment after the word (the hidden state g layer).
This type of RNN takes into account the contextual information of a word to the left and to the right, which generally improves accuracy.
Reference: http://suriyadeepan.github.io/2017-01-07-unfolding-rnn/
Recommended Reading:
Harbin Institute of Technology SCIR Center Launches Dialogue Technology Platform – DTP (Beta)
[Deep Learning Practical] How to Handle Variable Length Sequences Padding in PyTorch RNN
[Machine Learning Basic Theory] Detailed Explanation of Maximum A Posteriori Probability Estimation (MAP)
Welcome to follow the public account for learning and communication~
