
Click the “MLNLP” above to select the “Star” public account
Heavyweight content delivered first-hand
From | Zhihu
Author | Lucas
Address | https://zhuanlan.zhihu.com/p/85995376
Column | Deep Learning and Sentiment Analysis
Editor | Machine Learning Algorithms and Natural Language Processing
Understanding RNN: Recurrent Neural Networks and Their Implementation in PyTorch
Recurrent Neural Networks (RNN) are a type of neural network that has short-term memory capabilities. Specifically, the network remembers previous information and applies it to the current output calculation, meaning that the input to the hidden layer includes not only the output from the input layer but also the output from the previous hidden layer. In simple terms, RNNs are designed to handle sequential data. If CNNs can be seen as a simulation of human vision, then RNNs can be viewed as a simulation of human memory capabilities.
Why Do We Need RNN? What Are the Main Differences from CNN?
-
CNNs are like human vision; they have no memory and cannot process new tasks based on previous memories. RNNs, on the other hand, are based on the concept of human memory, expecting the network to recognize features that appeared earlier and use them to complete downstream tasks.
-
CNNs require fixed-length inputs and outputs, while RNNs can accept inputs and outputs of varying lengths.
-
CNNs have only a one-to-one structure, while RNNs have multiple structures.
Structural Composition
A simple RNN consists of three parts: the input layer, hidden layer, and output layer (obviously). If we expand the diagram above, the Recurrent Neural Network can also be represented as follows:
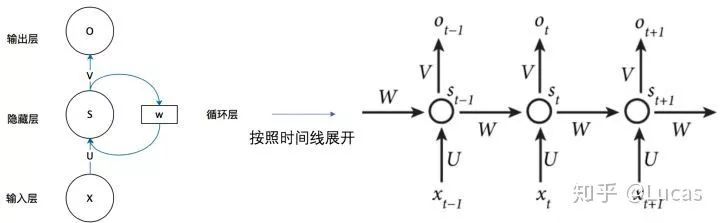
Why can RNNs look back at multiple input values?
Look, this is the calculation formula for the output layer o and hidden layer s.
If we keep substituting formula 2 into formula 1, we get:
Memory Capabilities
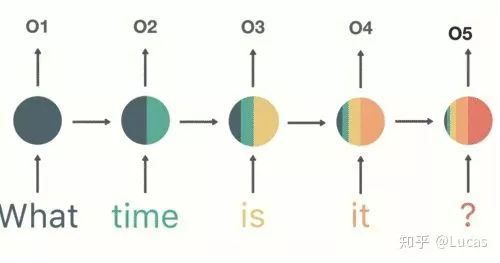
This model has certain memory capabilities, allowing it to process information of arbitrary length sequentially. Previous inputs influence future outputs. What does this mean? As shown in the figure below. When we input the phrase “What time is it?” into the neural network, each word will affect the next word.
Disadvantages: Vanishing and Exploding Gradients
From the examples above, we find that short-term memory has a significant impact (as shown in the orange area), while long-term memory has a very small impact (as shown in the black and green areas). This is the short-term memory problem of RNNs.
Mo Fan Python explains this very vividly:
‘Today I want to make braised pork ribs, first I need to prepare the ribs, then… finally, a delicious dish is ready.’ Now, let RNN analyze what dish I made today. RNN might give the answer “spicy chicken.” Due to this misjudgment, RNN will start learning the relationship between this long sequence X and ‘braised pork ribs’, but the key information “braised pork ribs” appears at the beginning of the sentence.
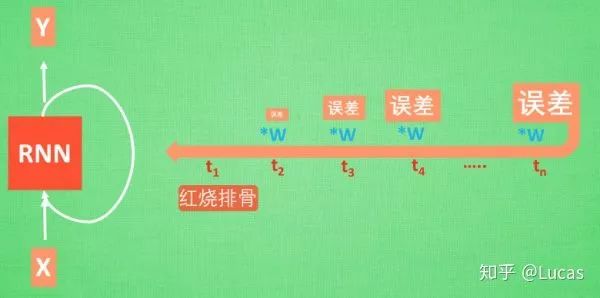
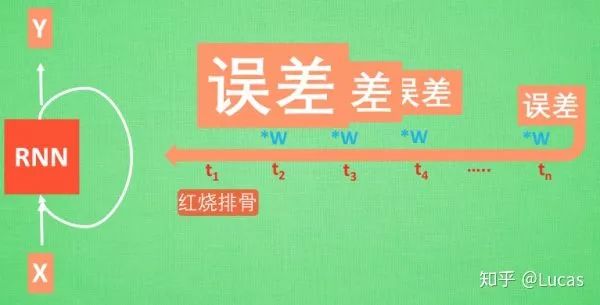
The memory of the information “braised pork ribs” has to go through a long journey before it can reach the final time point. Then we get the error, and when backpropagating the error, it is multiplied by its own parameter W at each step. If this W is a number less than 1, say 0.9, this 0.9 keeps multiplying the error, and the error that reaches the initial time point will be close to zero, so for the initial moment, the error essentially disappears. We call this problem gradient vanishing. Conversely, if W is a number greater than 1, say 1.1, it keeps multiplying, resulting in an infinitely large number, which causes RNN to be overwhelmed by this infinite number. We call this situation gradient explosion, which is why ordinary RNNs cannot recall long-term memories.
Thanks to
@Mo Fan
for the explanation of basic knowledge in machine learning, allowing juniors to grow rapidly. Knowledge sharing is a noble quality of humanity. I sincerely thank you!
Basic Model Implementation in PyTorch
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
def forward(self, input, hidden):
# Combine input and previous hidden layer parameters.
combined = torch.cat((input, hidden), 1)
hidden = self.i2h(combined) # Calculate hidden layer parameters
output = self.i2o(combined) # Calculate network output
return output, hidden
def init_hidden(self):
# Initialize hidden layer parameters
return torch.zeros(1, self.hidden_size)References
morvanzhou.github.io/tu
easyai.tech/ai-definiti
Code repository:
github.com/zy1996code/n
Recommended Reading:
Made 109 billion in one battle, the terrifying Zhang Yiming!
ALBERT, XLNet, NLP technology is developing too fast, how can we keep up with the pace?
Shanghai Jiao Tong University 25-Year-Old PhD Dad Becomes Famous! Six-Pack Abs, First Author in Science, Praised by People’s Daily
