

Author: Nie Runze, Harbin Institute of Technology, SCIR
1. Abstract
Current neural machine translation systems have achieved good results, and Transformer-based translation models have shown advanced performance in various translation tasks. However, how to use document-level context to handle discourse phenomena remains a challenge. Existing machine translation systems are generally based on independence and locality assumptions, meaning that they either translate word-by-word, phrase-by-phrase (completed by SMT), or translate sentences individually (completed by NMT). In contrast, text is not composed of isolated, unrelated elements, but rather consists of collocated and structured groups of sentences bound together by complex linguistic elements, known as discourse. Ignoring the interrelationships between these discourse elements may lead to translations that are perfect at the sentence level but lack key properties that aid in understanding the text. One approach to solving this problem is to learn the underlying discourse structure of the text by using contextual information in a broader context. Thus, sentence-by-sentence translation easily overlooks the logicality and fluency between statements, while document-level translation improves this by introducing contextual information.
This article introduces the main work currently being done in the field of document-level machine translation. Through document-level machine translation, our intention is to leverage inter-sentence contextual information to further enhance performance, including the discourse aspects of the document or the surrounding sentences of the source sentences. In addition, we will introduce evaluation strategies that have been introduced to assess improvements in this field.
2. Tasks
3. Datasets
There are corresponding public tasks for document-level machine translation in WMT19 and WNGT19. There are commonly used document-level datasets in the field, such as TED, News, and Europarl, but overall, the datasets are limited, and there is a lack of large-scale document-level parallel corpora in specific domains.
Commonly used training datasets are shown in Table 1:
Table 1: Commonly Used Datasets
| Data Type | Language | Dataset | Sentence/Document Count |
|---|---|---|---|
| TED (Speech Subtitles) | Chinese -> English | IWSLT 2015 | 205K/1.7K |
| English -> German | IWSLT 2017 | 206K/1.7K | |
| News (News Reports) | English -> German | News Commentary v11 | 236K/6.1K |
| Spanish -> English | News Commentary v14 | 355K/9.2K | |
| French -> English | News Commentary v14 | 303K/7.8K | |
| Russian -> English | News Commentary v14 | 226K/6.0K | |
| Europarl | English -> German | Europarl v7 | 1.67M/118K |
4. Existing Methods
4.1 Using Additional Context Encoders
Wang et al.[1] proposed the first context-aware RNN-based NMT model, which showed significant improvements over context-independent sentence-based NMT models.
Later, Bawden et al.[2] used a multi-encoder NMT model to leverage the context of the previous source sentence, thereby combining information from the context and the current source sentence using concatenation, gating, or hierarchical attention mechanisms. Additionally, they introduced a method that combines multiple encoders with the decoding of previous and current sentences. They emphasized the importance of target-side context, but scores decreased when evaluated with BLEU.
Voita et al.[3] modified the encoder in the Transformer architecture to a context-aware encoder (see Figure 1), which has two sets of encoders: a source encoder and a context encoder. Their experiments on English to Russian subtitle data and an analysis of the impact of contextual information on pronoun translation indicated that their model implicitly learned anaphora resolution. They also attempted to use the context of the source sentence as context and found that its performance was inferior to the baseline using the Transformer.
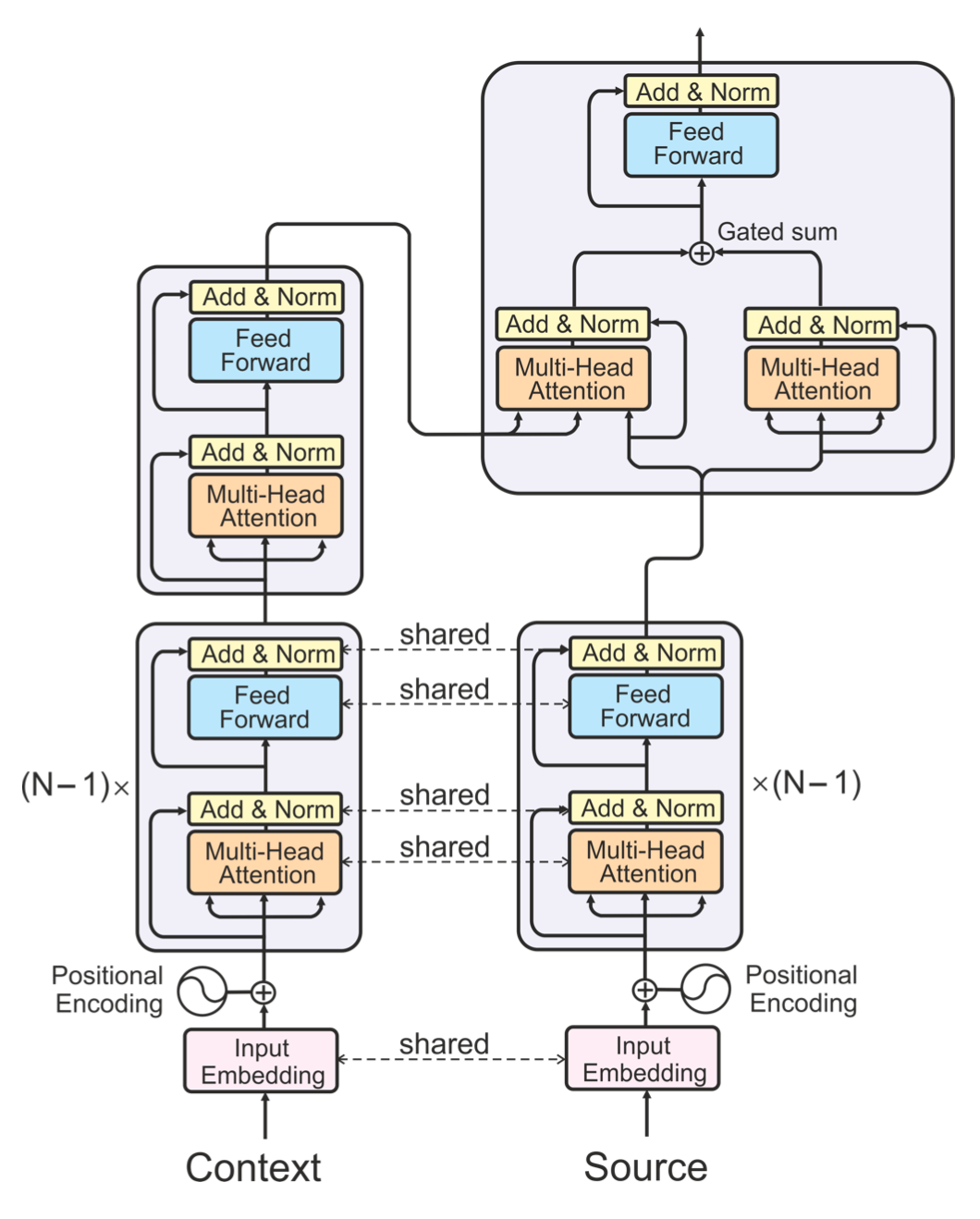
Figure 1: Context-Aware Encoder
Zhang et al.[4] further utilized context-aware encoders in the Transformer (see Figure 2), using sentence-based pre-trained embeddings as input to the context encoder. In the second stage of training, they only learned document-level parameters without fine-tuning the sentence-level parameters of their model. They conducted experiments on NIST Chinese to English and IWSLT French to English translation tasks, reporting a significant increase in BLEU scores relative to the baseline.
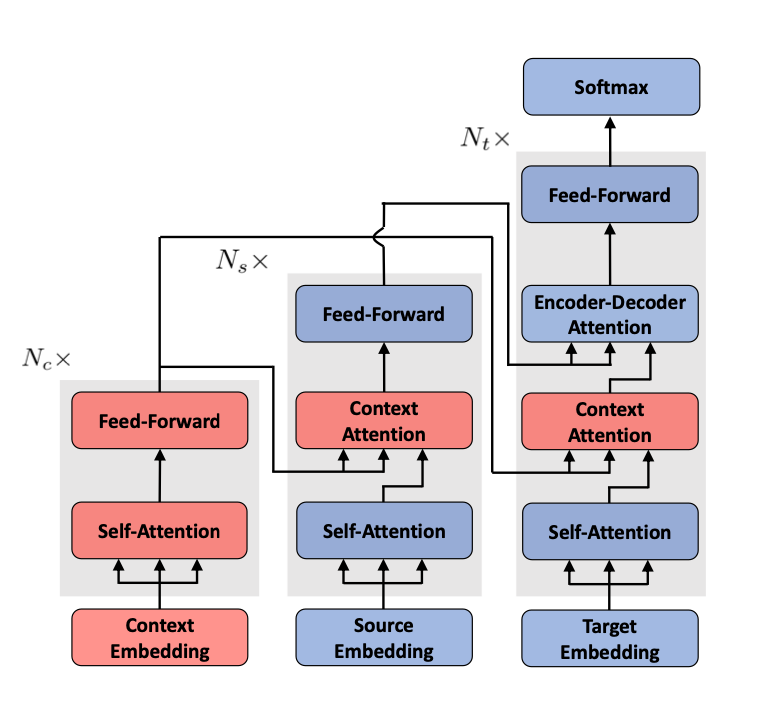
Figure 2: Context Encoder Proposed by Zhang et al.
Ma et al.[5] subsequently proposed a document-level translation model based on a single encoder in the Transformer (see Figure 3), leveraging a single encoder to capture contextual information and considering the position of source sentences in the text, achieving better results on the English-German task while simplifying the model.

Figure 3: Single Encoder Based on Transformer
4.2 Context-Extended Translation Units
In the work of context-extended translation units, Rios et al.[6] focused on the word sense disambiguation (WSD) problem in neural machine translation. One of their approaches to solving this problem was to use the lexical chains of semantically similar words in the document as feature inputs to the NMT model. Although this approach did not produce substantial improvements over the baseline on general test sets, there were some improvements on the target test set introduced in the same work. They also found evidence that without document-level context, even humans could not eliminate certain ambiguities in the target test set they used.
4.3 Using Document-level Tokens
Maće and Servan [7] added document tags as additional tokens at the beginning of the source sentences and used document-level embeddings during model training. Document-level embeddings are the averages of word embeddings learned when training sentence-level models. Additionally, they fixed word embeddings while training document-level models to maintain the relationship between word embeddings and document-level embeddings. This minor change in the encoder input produced good results for both translation directions in the English-French language pair and significant improvements for English to German.
4.4 Applying Cache to Store Context Information
Using a cache to store relevant information in the document and then using this external memory to improve translation quality. Tu et al.[8] used a cache to store hidden representations in bilingual contexts (see Figure 4), designing keys to help match queries (the current context vector generated through attention) with source-side context, and values to assist in finding relevant target-side information to generate the next target word. Then, they combined the final context vector from the cache with the decoder’s hidden state through a gating mechanism. The cache has a limited length and is updated after generating the complete translation statement. Their experiments on a multi-domain Chinese to English dataset showed that the effectiveness of this method has negligible impact on computational costs.
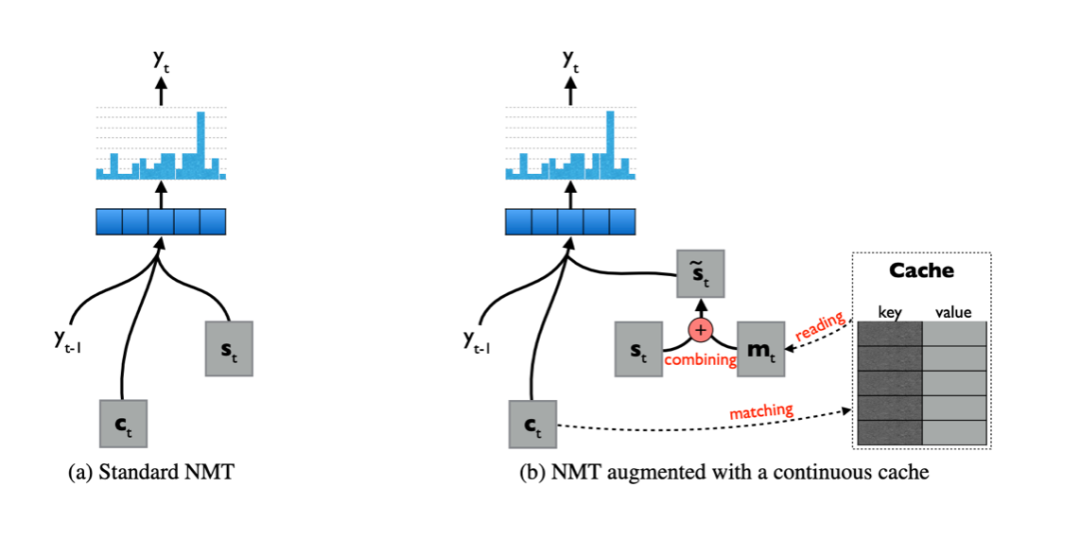
Figure 4: Applying Cache to Store Context Information
4.5 Using Context-Aware Decoders
Voita et al.[9] proposed a context-aware decoder (see Figure 5). They modified the decoder in the Transformer architecture, allowing the multi-head attention sublayer to also engage previous context sentences beyond the current source sentence. They also added an additional multi-head attention sublayer that involves previous target context sentences and the current target sentence. Their model performed well on the introduced targeted test set, but in terms of BLEU, its performance was comparable to sentence-level translation models. They continued to propose a context-aware model that performs automatic editing on a series of sentence-level translations and corrects inconsistencies between individual translations in each other’s context. The novelty of this work is that the model is trained solely on monolingual document-level data in the target language, thus learning to map inconsistent sentence groups to consistent corresponding sentences. They reported significant improvements in human evaluations against several discourse phenomena.
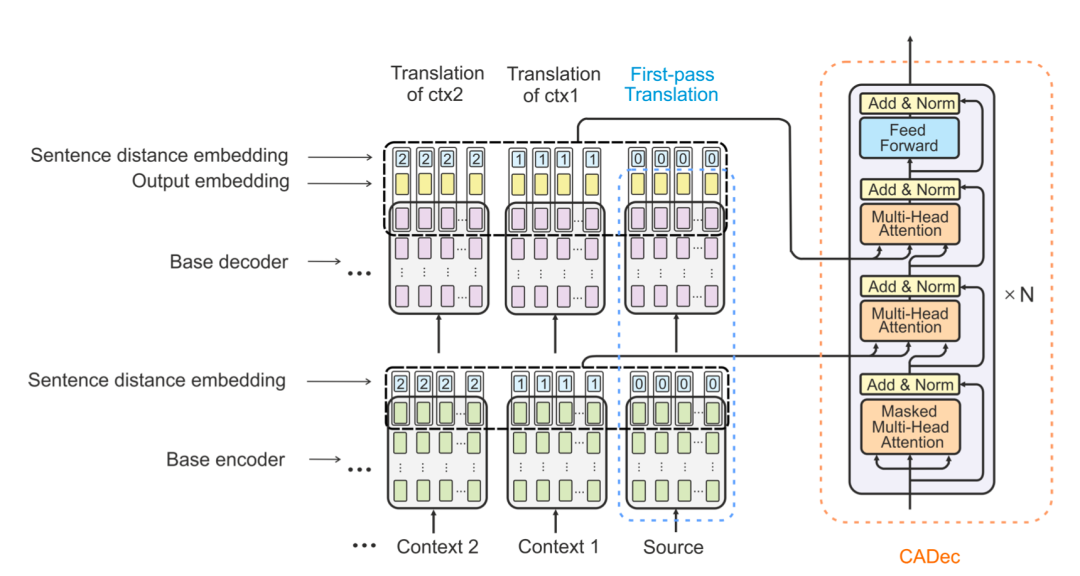
Figure 5: Context-Aware Decoder
4.6 Context-Adaptive Modeling
So far, all the mentioned works have utilized neural architectures, modifying the structure of basic sentence-level NMT models to incorporate contextual information. However, not all contextual information is useful, and to achieve better performance, some of this information must be ignored. Zheng et al.[10] introduced a general framework that utilizes discriminators to enable NMT models to ignore irrelevant information.
Jean and Cho [11] studied this problem from a learning perspective and designed a regularization relationship that allows NMT models to effectively utilize contextual information. This method applies to token, sentence, and corpus levels, and their proposed method makes the model more sensitive to other contexts, outperforming context-independent Transformer models in terms of BLEU scores.
5. Evaluation Methods
The output of machine translation is almost always evaluated using metrics such as BLEU and METEOR, which assess translation quality based on n-gram overlap between translations and references. However, these metrics do not look for specific semantic phenomena in translations, so they may fail to evaluate the quality of longer generated texts. L̈aubli et al.[12] found that when evaluating the adequacy and fluency of translations, evaluators preferred human translations. Therefore, with the improvement of translation quality, there is an urgent need for document-level evaluation, as errors related to discourse phenomena remain invisible in sentence-level evaluations.
For the problems that document-level machine translation tasks aim to solve (semantic phenomena), some works have proposed automatic evaluation metrics for assessing specific discourse phenomena.
Hardmeier and Federico [13], Jwalapuram et al.[14], and Werlen et al.[15] have each proposed different approaches to automatically evaluate pronoun translation based on text alignment and pronoun lists. Wong and Kit [16] and Gong et al.[17] proposed evaluation methods for lexical cohesion issues based on topic models and lexical chains, which have significantly improved BLEU while having little impact on METEOR. Hajlaoui and Popescu-Belis [18] and Smith and Specia [19] proposed evaluation methods for discourse connectives based on alignment and dictionaries to assess the quality of discourse connective translations.
6. Conclusion
This article introduces the significance of document-level machine translation and its current developments, as well as existing work and related evaluation methods for document-level machine translation.
References
Longyue Wang, Zhaopeng Tu, Andy Way, and Qun Liu. Exploiting cross-sentence context for neural machine translation. In EMNLP 2017.
[2]Rachel Bawden, Rico Sennrich, Alexandra Birch, and Barry Haddow. Evaluating discourse phenomena in neural machine translation. In NAACL 2018.
[3]Elena Voita, Pavel Serdyukov, Rico Sennrich, and Ivan Titov. Context-aware neural machine translation learns anaphora resolution. In ACL 2018.
[4]Jiacheng Zhang, Huanbo Luan, Maosong Sun, Feifei Zhai, Jingfang Xu, Min Zhang, and Yang Liu. Improving the transformer translation model with document-level context. In EMNLP 2018.
[5]Ma, Shuming, Dongdong Zhang, and Ming Zhou. A Simple and Effective Unified Encoder for Document-Level Machine Translation. In ACL 2020.
[6]Annette Rios Gonzales, Laura Mascarell, and Rico Sennrich. Improving word sense disambiguation in neural machine translation with sense embeddings. In WMT 2017.
[7]Valentin Mac ́e and Christophe Servan. Using whole document context in neural machine translation. In IWSLT 2019.
[8]Zhaopeng Tu, Yang Liu, Shuming Shi, and Tong Zhang. Learning to remember translation history with a continuous cache. In TACL 2018.
[9]Elena Voita, Rico Sennrich, and Ivan Titov. When a good translation is wrong in context: Context-aware machine translation improves on deixis, ellipsis, and lexical cohesion. In ACL 2019.
[10]Zaixiang Zheng, Shujian Huang, Zewei Sun, Rongxiang Weng, Xin-Yu Dai, and Jiajun Chen. Learning to discriminate noises for incorporating external information in neural machine translation. CoRR, abs/1810.10317, 2018.
[11]S ́ebastien Jean and Kyunghyun Cho. Context-aware learning for neural machine translation. CoRR, abs/1903.04715, 2019.
[12]Samuel L ̈aubli, Rico Sennrich, and Martin Volk. Has machine translation achieved human parity? A case for document-level evaluation. In EMNLP 2018.
[13]Christian Hardmeier and Marcello Federico. Modelling pronominal anaphora in statistical machine translation. In IWSLT 2010.
[14]Prathyusha Jwalapuram, Shafiq Joty, Irina Temnikova, and Preslav Nakov. Evaluating pronominal anaphora in machine translation: An evaluation measure and a test suite. In EMNLP 2019 and IJCNLP 2019.
[15]Lesly Miculicich Werlen and Andrei Popescu-Belis. Validation of an automatic metric for the accuracy of pronoun translation (APT). In the Third Workshop on Discourse in Machine Translation 2017.
[16]Billy T. M. Wong and Chunyu Kit. Extending machine translation evaluation metrics with lexical cohesion to document level. In EMNLP-CoNLL 2012.
[17]Zhengxian Gong, Min Zhang, and Guodong Zhou. Document-level machine translation evaluation with gist consistency and text cohesion. In the Second Workshop on Discourse in Machine Translation 2015.
[18]Najeh Hajlaoui and Andrei Popescu-Belis. Assessing the accuracy of discourse connective translations: Validation of an automatic metric. In CICLING 2013.
[19]Karin Sim Smith and Lucia Specia. Assessing crosslingual discourse relations in machine translation. CoRR, abs/1810.03148, 2018.
Download 1: Four Essentials
Reply "Four Essentials" in the backend of the Machine Learning Algorithm and Natural Language Processing public account to obtain the learning essentials for TensorFlow, Pytorch, machine learning, and deep learning!
Download 2: Repository Address Sharing
Reply "Code" in the backend of the Machine Learning Algorithm and Natural Language Processing public account to obtain 195 papers from NAACL + 295 papers from ACL 2019 with open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code
Exciting! The Machine Learning Algorithm and Natural Language Processing exchange group has officially been established! There are abundant resources in the group, and everyone is welcome to join and learn!
Additional welfare resources! Deep learning and neural networks, official Chinese tutorials for Pytorch, data analysis using Python, machine learning study notes, official Chinese documentation for pandas, effective java (Chinese version), and 20 other welfare resources.
How to obtain: After entering the group, click on the group announcement to obtain the download link.
Note: Please modify the remarks when adding to [School/Company + Name + Direction].
For example - HIT + Zhang San + Dialogue System.
Please bypass if you are a micro-business. Thank you!
Recommended Reading:
Implementation of NCE-Loss in Tensorflow and word2vec
Overview of Multimodal Deep Learning: Summary of Network Structure Design and Modal Fusion Methods
Awesome-Adversarial-Machine-Learning Resource List