Skip to content
Today, I will share the improved model DC-UNet, which is based on the U-Net architecture. The improvement comes from the 2020 paper titled “DC-UNet: Rethinking the U-Net Architecture with Dual Channel Efficient CNN for Medical Images Segmentation.” By understanding the concept of this model, similar improvements can be made based on VNet.
1. The original UNet has some defects. The authors of the paper proposed the improved UNet, DC-UNet (Dual Channel UNet), which is designed in two main aspects: one is to design an efficient CNN structure to replace the encoder and decoder in UNet, and the second is to replace the skip connections between the encoder and decoder with residual modules. Compared to the original UNet, the results were improved by 2.9%, 1.49%, and 11.42% accuracy on three datasets.
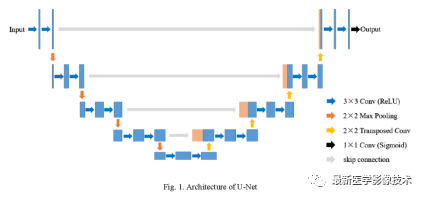
2. Classic Structure of UNet
It consists of convolutional layers, pooling layers, upsampling layers, and skip connection layers.
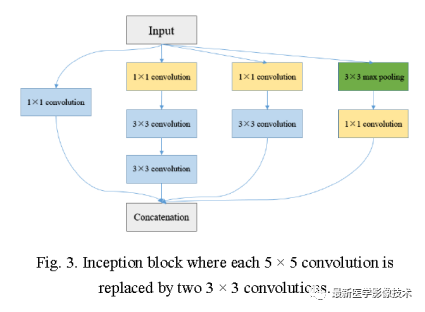
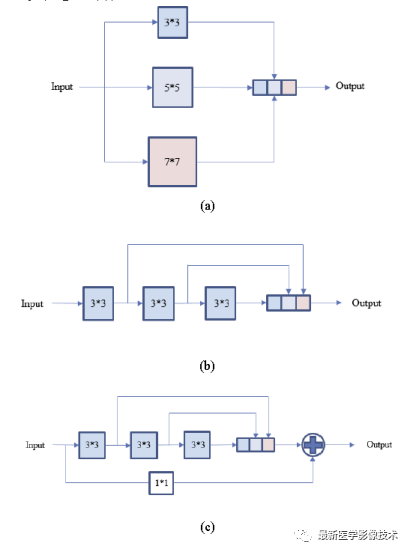
1.1. Different sizes of convolution kernels are used to replace the convolutions in the original UNet to extract features, and then the results of different convolutions are concatenated to achieve feature fusion at different image scales. As shown in the figure below, to reduce the number of channels and thus reduce parameter calculations, 1×1 convolutions are used to reduce dimensions, as shown in the figure below.
In the paper, the authors simplified the above Inception module, achieving the effect of different sizes of convolution kernels through a series of identical convolution operations, and then concatenated the results of different convolutions to complete the fusion of features at different scales, as shown in figure b below. Additionally, the authors added residual connections to the Inception module, as shown in figure c below.
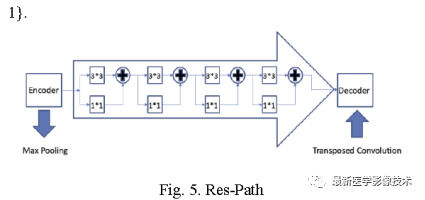
2.2. The skip connection module in UNet is replaced with a residual path connection, as shown in the figure below. The input of this module is the output of the decoding network, which goes through four 3×3 residual connection convolution operations, and finally concatenates with the output of the encoding network.
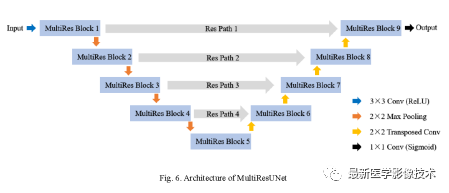
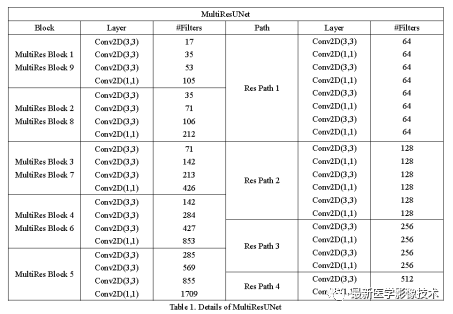
2.3. The structure of MultiResUnet with multi-scale residual modules and residual paths is shown below. The convolution kernel sizes and counts for each multi-scale residual network are three 3×3 and one 1×1, with different feature channel counts for each module, as detailed in Table 1. The convolution kernel size of the residual path is the combination of multiple 3×3 and 1×1 modules, as seen in the figure below, where the counts of 3×3 and 1×1 residual modules are 4, 3, 2, and 1 respectively. For specifics, see Table 1.
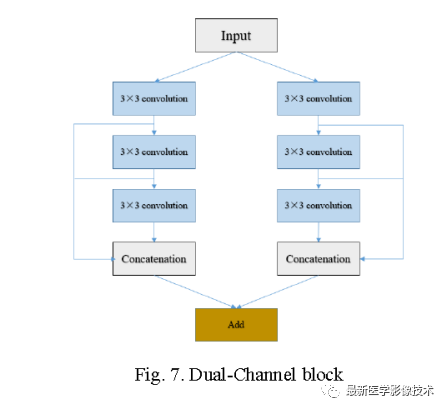
 DC-UNet proposes a more effective network structure to extract more spatial features based on the MultiResUnet model. To overcome the issue of ineffective spatial features, three 3×3 convolution layers with multiple paths are used to replace the residual connections in the MultiRes module. The authors of the paper used two paths of three 3×3 convolution layers in the dual-channel module, and finally linearly added the results of these two paths for output, as shown in the figure below.
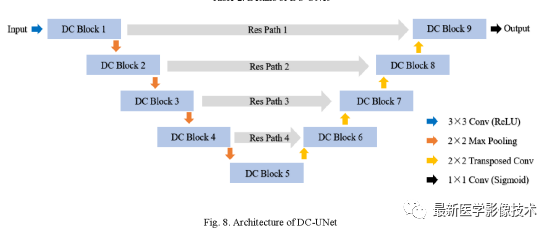
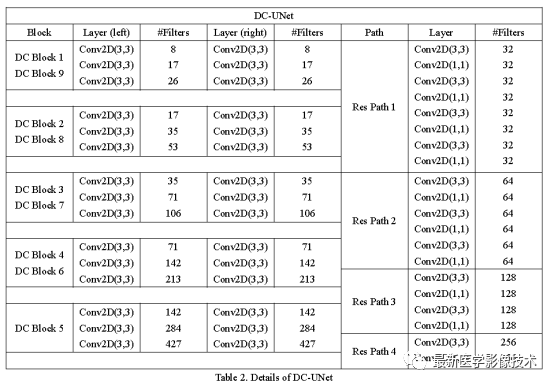
The structure of DC-Unet with dual-channel modules and residual paths is shown below. The convolution kernel size of each dual-channel module is 3×3, and the feature channel counts for each module are different, as detailed in Table 2. The convolution kernel size of the residual path is the combination of multiple 3×3 and 1×1 modules, as seen in the figure below, where the counts of 3×3 and 1×1 residual modules are 4, 3, 2, and 1 respectively. For specifics, see Table 2.
The preprocessing involves resizing images to 256×128 and converting the image data from 16-bit format to 8-bit format. The binary cross-entropy loss function is used, and the optimizer is Adam with its default parameters.
Since the output images are values from 0 to 1, binary comparison methods can be used: Jaccard similarity (IOU). Grayscale comparison methods can also be used: Mean Absolute Error (MAE), Tanimoto similarity (an extension of Jaccard similarity), and Structural Similarity (SSIM).
Comparisons were made among UNet, MultiResUNet, and DC-UNet on three datasets. Both in terms of objective evaluation metrics and subjective visual assessment, the results of DC-Unet were the best.
DC-UNet proposes a more effective network structure to extract more spatial features based on the MultiResUnet model. To overcome the issue of ineffective spatial features, three 3×3 convolution layers with multiple paths are used to replace the residual connections in the MultiRes module. The authors of the paper used two paths of three 3×3 convolution layers in the dual-channel module, and finally linearly added the results of these two paths for output, as shown in the figure below.
The structure of DC-Unet with dual-channel modules and residual paths is shown below. The convolution kernel size of each dual-channel module is 3×3, and the feature channel counts for each module are different, as detailed in Table 2. The convolution kernel size of the residual path is the combination of multiple 3×3 and 1×1 modules, as seen in the figure below, where the counts of 3×3 and 1×1 residual modules are 4, 3, 2, and 1 respectively. For specifics, see Table 2.
The preprocessing involves resizing images to 256×128 and converting the image data from 16-bit format to 8-bit format. The binary cross-entropy loss function is used, and the optimizer is Adam with its default parameters.
Since the output images are values from 0 to 1, binary comparison methods can be used: Jaccard similarity (IOU). Grayscale comparison methods can also be used: Mean Absolute Error (MAE), Tanimoto similarity (an extension of Jaccard similarity), and Structural Similarity (SSIM).
Comparisons were made among UNet, MultiResUNet, and DC-UNet on three datasets. Both in terms of objective evaluation metrics and subjective visual assessment, the results of DC-Unet were the best.