
Abstract
In recent years, deep learning has become a hot research topic. Although it can yield unexpectedly positive results in some cases, bugs within deep learning software can lead to catastrophic consequences, especially when the software is used in safety-critical applications. In this paper, we present an empirical study of a typical deep learning library—TensorFlow—analyzing its defects for the first time. Based on the research results, we summarize 8 findings and provide answers to 4 research questions. For instance, we found that the bugs in TensorFlow are more similar to those in regular projects (like Mozilla) rather than other machine learning libraries (like Lucene). Additionally, we discovered that most TensorFlow bugs exist in its interfaces (26.24%), learning algorithms (11.79%), as well as in how to compile (8.02%), deploy (7.55%), and install across platforms (4.72%).
1 Introduction
In recent years, deep learning has been a hot research topic, with researchers applying deep learning techniques to solve problems across various fields. When implementing deep learning applications, programmers often build their applications based on mature deep learning libraries instead of reinventing the wheel. Among these libraries, TensorFlow is the most popular. Due to the popularity of these libraries, a bug in a deep learning library can lead to bugs in many applications, which may result in catastrophic consequences.
To our knowledge, there has been no previous research exploring the internal errors of popular deep learning libraries. We conducted the first empirical study to analyze the bugs within TensorFlow. Our research has the following two contributions:
(1) Previous work only analyzed the symptoms and causes of bugs; we also analyzed bug fixes and multilingual bugs.
(2) We compared the symptoms, causes, and fix patterns identified in our experiments with previous studies, finding that TensorFlow exhibits type confusion, which has not been reported in earlier research. Moreover, like deep learning applications, TensorFlow also has dimension mismatches.
We primarily studied and answered the following four questions. 1: What are the symptoms and causes of bugs? 2: How do errors propagate between components? 3: What are the fix patterns within TensorFlow? 4: Which bugs involve multiple programming languages?
2 Preliminary Work
2.1 Implementation of TensorFlow
TensorFlow uses data flow graphs to define the computation and state of machine learning algorithms. In a data flow graph, each node represents an individual mathematical operator (e.g., matrix multiplication), while each edge represents a data dependency. On each edge, a tensor (n-dimensional array) defines the data format for transmitting information between two nodes.
TensorFlow provides official APIs in different programming languages such as Python, C++, Java, JavaScript, and Go. Additionally, as unofficial APIs, the open-source community provides APIs in other programming languages like C#, Julia, Ruby, Rust, and Scala.
2.2 Bug Fixing Process in TensorFlow
The source code of TensorFlow is maintained on GitHub, where issues have been reported since November 2015, and commits are recorded. Typically, if a user encounters a bug, they submit a bug report. The bug report includes basic information about the bug, such as the operating system platform, TensorFlow version, and code snippets that demonstrate the bug behavior. Upon receiving the bug report, developers discuss the possible causes of the bug and how to fix it, then submit a fix version. Afterwards, reviewers need to evaluate the fix and communicate with the developers regarding the modifications. Finally, if the changes are confirmed to be correct, other developers will approve the changes and merge the commits.
3 Methodology
3.1 Dataset
We chose TensorFlow as our research subject and applied the following steps to extract approved pull requests. (1) Filter pull requests by label; (2) Search pull requests by keywords; (3) Extract bug reports and code modifications.
We collected 202 bug fixes in TensorFlow, of which 84 had corresponding bug reports. This number is comparable to other empirical studies. In fact, for deep learning programs, libraries are typically much larger than applications. Therefore, the bugs we analyzed are much more complex than those studied previously.
3.2 Manual Analysis
We invited two graduate students to manually review all the bugs. According to our protocol for each question, the two students independently examined the bugs and compared their results. If they could not reach a consensus on TensorFlow vulnerabilities, they would discuss it in weekly group meetings.
Protocol for Question 1: For bug classification, if a pull request has a corresponding bug report, we first read the bug report to determine its symptoms and root causes. If there is no corresponding description in the report, we manually identify the symptoms and root causes from the pull request description, discussions related to the bug, code modifications, and comments. After extracting all the symptoms and root causes of the bugs, we further categorize them and use uplift functions to measure the correlation between symptoms and root causes. The uplift between two categories (A and B) is defined as follows.
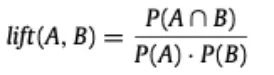
Where P(A), P(B), and P(A∩B) are the probabilities of a bug belonging to category A, category B, and both categories A and B, respectively. If the uplift value is greater than 1, then a symptom is related to a root cause; otherwise, it is not related.
The two graduate students referred to previous studies to establish their own classifications of bug symptoms and their roots. If a TensorFlow bug belonged to an existing category, they would add that category to the existing category library. If the bug did not belong to any existing category, they would try to find similar categories from previous studies. If they could not find similar categories, they would add a new category.
Protocol for Question 2: In this research question, the two students analyzed the locations of the bugs. As an open-source project, TensorFlow does not formally list its components, but like other projects, TensorFlow organizes its source files into different directories based on their functionality. In determining their functionalities, they referred to various sources, such as official documentation, TensorFlow tutorials, and forum discussions.
We measured the correlation between the fault locations and symptoms or root causes using the uplift metric defined in formula (1). Here, if a bug involves multiple directories, we calculate once for each directory to ensure that no symptoms and root causes are lost.
Protocol for Question 3: We found that some bug fixes were redundant, appearing at least twice, so we analyzed these fixes according to the following steps.
(1) Examine the symptoms and root causes. We review the symptoms, root causes, and location information obtained from previous sections to outline an overall picture of a bug.
(2) Identify relevant code modifications. We determine the scale of a bug fix from the code modifications, including the number of relevant files, the number of modified lines, and the frequency of commits.
(3) Analyze the characteristics of the modifications. Focus on several characteristics of bug fixes to detail the fixing process.
(4) Extract fix templates. We assume that bug fixes with the above similar characteristics may share the same fix template. Based on these characteristics, we define fix patterns and extract frequently occurring instances as templates.
Protocol for Question 4: For bugs involving both programming languages and build script languages, we examine their symptoms and root causes to determine whether they include configuration errors and additional defects. For bugs involving only programming languages, we further examine the relevant reports and fixes to identify their fix targets in the corresponding files, thereby summarizing the main patterns of these bugs.
4 Empirical Results
4.1 Question 1: Symptoms and Root Causes
l Categories of Symptoms:
1 Functional Errors (35.64%). If a program does not operate according to its designed functionality, we refer to it as a functional error. 2 Crashes (26.73%). A crash occurs when a program exits abnormally; at this point, the program throws an error exception. 3 Hanging (1.49%). A hanging occurs when a program runs indefinitely without stopping or responding. 4 Performance Degradation (1.49%). Performance degradation occurs when a program fails to return results within the expected time frame. 5 Build Failures (23.76%). This type of error occurs during the compilation process. 6 Warning Errors (10.89%). Warning errors indicate that the program’s execution is not hindered but still requires modifications to eliminate risks or improve code quality, including deprecated interfaces, redundant code, and poor coding styles.
l Categories of Root Causes Leading to Bugs:
1 Dimension Mismatch (3.96%), caused by dimension mismatches in tensor computations and transformations; 2 Type Confusion (12.38%), caused by type mismatches; 3 Data Processing (22.28%), caused by incorrect variable assignments or initializations, variable formatting errors, or other errors related to data processing; 4 Version Inconsistency (16.83%), caused by incompatible bugs due to API changes or version updates; 5 Algorithm (2.97%), caused by erroneous logic in the algorithm; 6 Extreme Cases (15.35%), caused by improper handling of extreme situations; 7 Logic Errors (9.90%), errors occurring in the program’s logic; 8 Configuration Errors (7.43%), caused by incorrect configurations; 9 Reference Type Errors (4.95%), resulting from missing or unnecessary include or import statements; 10 Memory (2.97%), caused by incorrect memory usage; 11 Concurrency (0.99%), caused by synchronization issues.
4.2 Question 2: Bug Localization and Propagation
Figure 4 shows the correlation between symptoms, root causes, and error locations. In this figure, rectangles represent root causes, ellipses represent symptoms, and cylinders represent error locations. Lines indicate correlations, with values greater than 1 highlighted.
For root causes, we found inconsistencies to be common, while for symptoms, crashes and build failures are prevalent in components. From a component perspective, we found that the kernel has a strong correlation with functional errors and extreme cases, indicating that semantic errors dominate this component. At the same time, we found that the API has a strong correlation with root causes related to tensor computations. For libraries and tools, their symptoms are strongly correlated with build failures, while their root causes are strongly correlated with inconsistencies.
In summary, most TensorFlow errors exist in deep learning algorithms, API interfaces, and platform-related components. Moreover, the correlation between their locations and symptoms or root causes follows specific patterns.
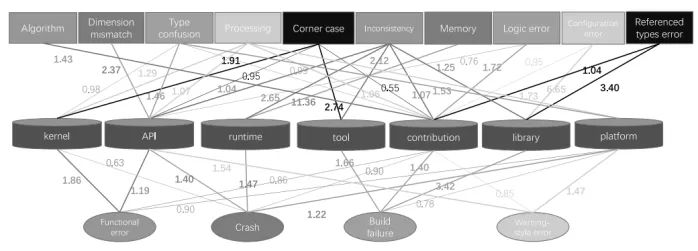
Figure 4. Correlation between locations.
4.3 Question 3: Fix Patterns
l Categories of Fix Patterns
1 Parameter Modifiers (21.85%), adding, deleting, or replacing parameter inputs; 2 Method Replacers (16.81%), replacing one method with another method that is compatible in terms of parameters and return types; 3 Value Checkers (14.29%), checking the values of variables; 4 Type Replacements (11.76%), replacing the types of variables; 5 Reference Type Modifiers (11.76%), adding, relocating, or replacing reference types; 6 Initialization Modifiers (6.72%), modifying the initial values of variables; 7 Mutable Replacements (5.88%), replacing variables with compatible variables; 8 Format Checkers (5.04%), this fix pattern checks the data format of variables; 9 Condition Replacements (2.52%), replacing predicates in branches with compatible predicates; 10 Exception Adders (1.68%), handling exceptions; 11 Syntax Modifiers (1.68%), which can eliminate syntax errors.
4.4 Question 4: Multilingual Programming
We discovered a total of 10 bugs designed for multiple languages, distributed as shown in Figure 5. We categorized them into two types: (1) Configuration bugs, totaling 6; (2) Bugs caused by test cases using other languages, totaling 4. The number is quite limited.
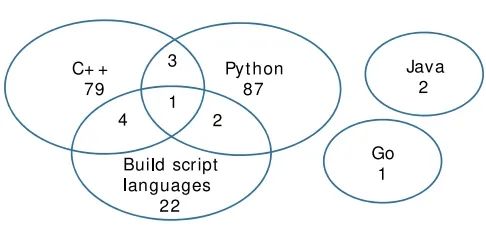
Figure 5. Distribution of programming languages.
4.5 Threats to Validity
Internal threats to validity include potential errors in our manual checks. To mitigate this threat, we asked two students to review our errors. When they encountered contentious cases, we discussed them in group meetings until we reached a consensus. The threat can be alleviated by involving more researchers, which is why we published our findings. External threats to validity include our subject matter, as we only analyzed TensorFlow errors. Although the errors we analyzed are similar to those in previous and other studies, they are limited to TensorFlow errors. This threat can be reduced by examining more errors.
5 Conclusion
While researchers have conducted empirical studies to understand bugs in deep learning, these studies have mainly focused on bugs in its applications, while bugs within deep learning libraries remain largely unknown. To deepen the understanding of such bugs, we analyzed 202 bugs within TensorFlow. Our results indicate: (1) its root causes are more determinative than its symptoms; (2) bugs in traditional software and TensorFlow share various common characteristics; (3) inappropriate data formats (dimensions and types) are prone to bugs and are prevalent in API implementations, while inconsistent bugs are common in other supporting components.
Acknowledgments
This paper was translated and summarized by Liu Fan, a master’s student from the School of Software at Nanjing University, and reviewed by Liu Jiawei.