Author: Sovit Rath
Translator: ronghuaiyang
This article introduces the structure and usage of TrOCR, teaching step by step from each line of code.
Optical Character Recognition (OCR) has seen several innovations in recent years. Its impact on retail, healthcare, banking, and many other industries is tremendous. Despite its long history and some state-of-the-art models, researchers are constantly innovating. Like many other areas of deep learning, OCR has also witnessed the importance and impact of transformer networks. Today, we have models like TrOCR (Transformer OCR) that truly surpass previous technologies in terms of accuracy.
In this article, we will introduce TrOCR and focus on four topics:
-
What is the structure of TrOCR -
What types are included in the TrOCR series -
How to pre-train the TrOCR model -
How to use TrOCR and Hugging Face for inference
Structure of TrOCR
TrOCR was introduced by Li et al. in the paper TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models.
The authors proposed an approach that deviates from traditional CNNs and RNNs, using visual and language transformer models to construct the TrOCR architecture.
The TrOCR model consists of two stages:
-
The encoder stage consists of a pre-trained visual transformer model. -
The decoder stage consists of a pre-trained language transformer model.
Due to its efficient pre-training, transformer-based models perform very well on downstream tasks. Therefore, the authors chose DeIT as the visual transformer model. For the decoder stage, they selected either RoBERTa or UniLM models, depending on the TrOCR variant.
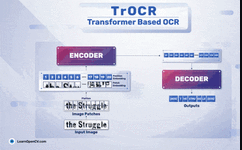
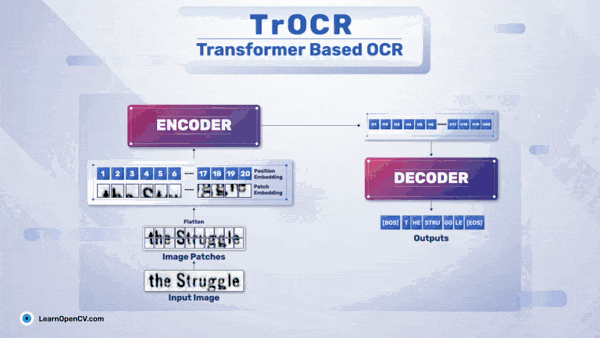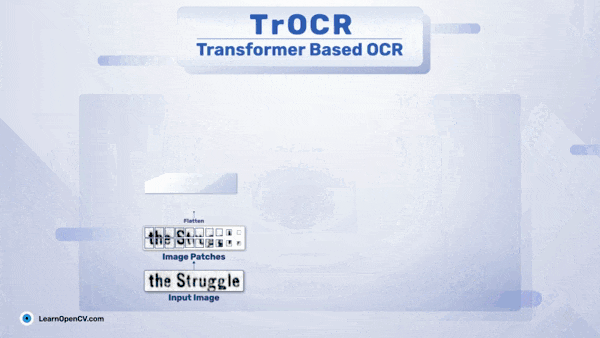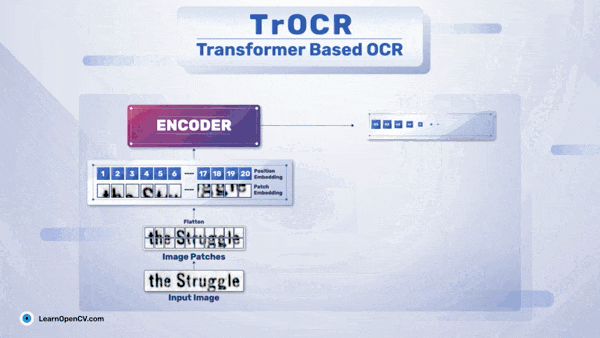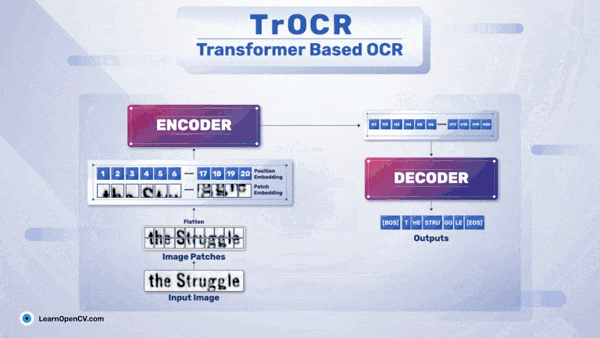
The diagram below shows a simple OCR pipeline using TrOCR.
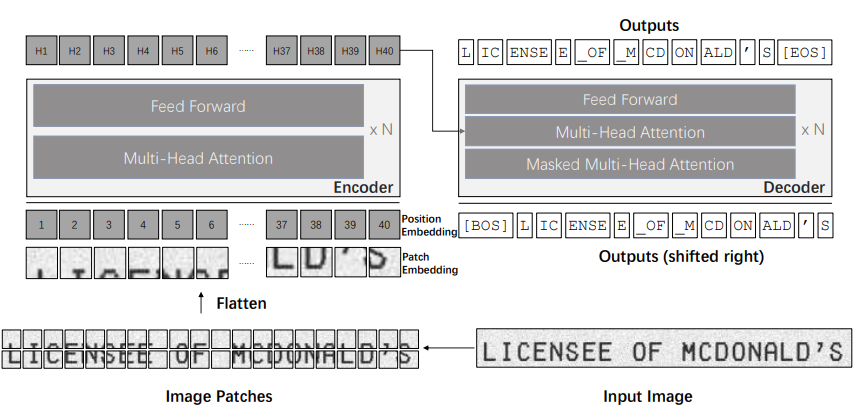
In the above diagram, the left block shows the visual transformer encoder, while the right block shows the language transformer decoder. Here’s a simple breakdown of the inference stage of TrOCR:
-
First, we input the image into the TrOCR model, which goes through the image encoder. -
The image is broken down into small patches and then processed through multi-head attention blocks. The feed-forward block generates image embeddings. -
These embeddings then enter the language transformer model. -
The decoder part of the language transformer model generates encoded outputs. -
Finally, we decode the encoded outputs to obtain the text in the image.
It is important to note that before entering the visual transformer model, the image is resized to a resolution of 384×384. This is because the DeIT model expects the image to be of a specific size.
Models in the TrOCR Family
The TrOCR family models include several pre-trained and fine-tuned models.
TrOCR Pre-trained Models
The pre-trained models in the TrOCR family are referred to as stage one models, which are trained on a large amount of generated data. The dataset includes millions of images of printed text lines.
The official code repository contains three different sizes of pre-trained models:
-
TrOCR-Small-Stage1 -
TrOCR-Base-Stage1 -
TrOCR-Large-Stage1
Larger models perform better, but they are slower.
TrOCR Fine-tuned Models
After the pre-training step, the models are fine-tuned on IAM handwritten data text images and SROIE printed receipt datasets.
The IAM handwritten dataset contains handwritten text, and fine-tuning on this dataset allows the model to perform better on handwritten text than other models.
Similarly, the SROIE dataset contains thousands of receipt image samples, and after fine-tuning, it performs well on printed text.
Like the pre-trained models, the handwritten and printed models also include three different sizes:
-
TrOCR-Small-IAM -
TrOCR-Base-IAM -
TrOCR-Large-IAM -
TrOCR-Small-SROIE -
TrOCR-Base-SROIE -
TrOCR-Large-SROIE
Using TrOCR and Hugging Face for Inference
All models of TrOCR are available on Hugging Face, including those for pre-training and fine-tuning.
We will use two models, one for handwritten fine-tuning and one for printed fine-tuning, to conduct inference experiments.
On Hugging Face, the naming of the models follows the trocr-<model_scale>-<training_stage> convention.
For example, the small model trained on the IAM handwritten dataset is called trocr-small-handwritten.
We will use trocr-small-printed and trocr-base-handwritten for inference.
Installing Dependencies, Importing, Setting Up Computing Device
First, some libraries need to be installed: Hugging Face transformers, sentencepiece tokenizer.
!pip install -q transformers
!pip install -q -U sentencepiece
Then the following import statements:
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
from tqdm.auto import tqdm
from urllib.request import urlretrieve
from zipfile import ZipFile
import numpy as np
import matplotlib.pyplot as plt
import torch
import os
import glob
We need to use urllib and zipfile to extract the inference data.
The forward process can use either GPU or CPU.
device = torch.device('cuda:0' if torch.cuda.is_available else 'cpu')
Helper Functions
The following function is used to download and extract the dataset.
def download_and_unzip(url, save_path):
print(f"Downloading and extracting assets....", end="")
# Downloading zip file using urllib package.
urlretrieve(url, save_path)
try:
# Extracting zip file using the zipfile package.
with ZipFile(save_path) as z:
# Extract ZIP file contents in the same directory.
z.extractall(os.path.split(save_path)[0])
print("Done")
except Exception as e:
print("\nInvalid file.", e)
URL = r"https://www.dropbox.com/scl/fi/jz74me0vc118akmv5nuzy/images.zip?rlkey=54flzvhh9xxh45czb1c8n3fp3&dl=1"
asset_zip_path = os.path.join(os.getcwd(), "images.zip")
# Download if asset ZIP does not exist.
if not os.path.exists(asset_zip_path):
download_and_unzip(URL, asset_zip_path)
The above code downloads images that include:
-
Printed text data from old newspapers for running the printed model. -
Handwritten text images for running the handwritten fine-tuning model. -
Distorted text images to test the limits of the TrOCR model.
Next, we use a simple function to read images.
def read_image(image_path):
"""
:param image_path: String, path to the input image.
Returns:
image: PIL Image.
"""
image = Image.open(image_path).convert('RGB')
return image
The read_image() function takes the image path as a parameter and returns the image in RGB format.
We also wrote a function to implement the OCR pipeline.
def ocr(image, processor, model):
"""
:param image: PIL Image.
:param processor: Huggingface OCR processor.
:param model: Huggingface OCR model.
Returns:
generated_text: the OCR'd text string.
"""
# We can directly perform OCR on cropped images.
pixel_values = processor(image, return_tensors='pt').pixel_values.to(device)
generated_ids = model.generate(pixel_values)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
return generated_text
The ocr() function requires the following parameters:
-
image: RGB formatted PIL image data. -
processor: The Hugging Face OCR pipeline that needs to convert the image to the required format. -
model: This is the Hugging Face OCR model that takes the pre-processed image and provides the decoding output.
Before the return statement, there is a batch_decode() function that actually converts the generated IDs to output text, with skip_special_tokens=True indicating that we do not need special tokens in the output, such as end and start tokens.
The final function is used to run inference on new images, including the previous functions and displaying the output results.
def eval_new_data(data_path=None, num_samples=4, model=None):
image_paths = glob.glob(data_path)
for i, image_path in tqdm(enumerate(image_paths), total=len(image_paths)):
if i == num_samples:
break
image = read_image(image_path)
text = ocr(image, processor, model)
plt.figure(figsize=(7, 4))
plt.imshow(image)
plt.title(text)
plt.axis('off')
plt.show()
The eval_new_data() function takes the folder path, sample size, and model as parameters.
Inference on Printed Text
We load the TrOCR processor and model to perform printed text recognition.
processor = TrOCRProcessor.from_pretrained('microsoft/trocr-small-printed')
model = VisionEncoderDecoderModel.from_pretrained(
'microsoft/trocr-small-printed'
).to(device)
To load the TrOCR processor, we need to use the from_pretrained module, which takes the Hugging Face repository path that contains the specific module.
What does the TrOCR Processor do?
The TrOCR model is a neural network that cannot directly process images; we need to first process the image into a suitable format. The TrOCR processor first scales the image to a resolution of 384×384, then converts it to a normalized tensor format before performing model inference. We can also specify the tensor format, for instance, we can convert it to pt format, indicating it is a PyTorch tensor, and we can also obtain TensorFlow format.
Similarly, we use the VisionEncoderDecoderModel class to load the pre-trained model; in the above code, we loaded the trocr-small-printed model and loaded it onto the device. Then, we call the eval_new_data() function to start inference.
eval_new_data(
data_path=os.path.join('images', 'newspaper', '*'),
num_samples=2,
model=model
)
Running the above code can yield the following output:
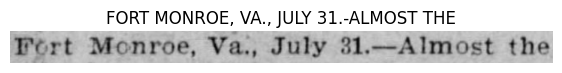

The text on the image represents the model’s output, and the model also performs well on blurred images. In the first image, the model can predict all punctuation marks, spaces, and even dashes.
Inference on Handwritten Text
For handwritten text inference, we use the base model (larger than the small model); we first load the handwritten TrOCR processor and model.
processor = TrOCRProcessor.from_pretrained('microsoft/trocr-base-handwritten')
model = VisionEncoderDecoderModel.from_pretrained(
'microsoft/trocr-base-handwritten'
).to(device)
Our method is similar to the printed text model, just changing the repository address to the required model.
When running inference, we need to change the data path.
eval_new_data(
data_path=os.path.join('images', 'handwritten', '*'),
num_samples=2,
model=model
)
Here is the output:

This example demonstrates the effectiveness of TrOCR on handwritten text, accurately recognizing all characters, even connected ones.

For different handwriting styles, the model also performs well. The power of combining visual and language models is evident.
Testing the Limits of TrOCR
TrOCR does not perform well on all types of images. For example, the small model performs poorly on curved text, as shown in the following examples:

Clearly, the model fails to understand and recognize the word STATES, outputting <.
Here’s another example:

This time, the model was able to predict a word, but it was incorrect.
Improving the Performance of TrOCR
As seen above, the TrOCR model may perform poorly in certain scenarios, which is a limitation stemming from the capabilities of both the visual transformer and language transformer. A visual model trained on curved text images and a language model capable of understanding such tokens are needed.
The best approach is to fine-tune the TrOCR model on a curved text dataset; we will train on the SCUT-CTW1500 dataset.
Conclusion
OCR has developed for a long time with simple architectures, and now, TrOCR brings new possibilities to the field. We started with an introduction to TrOCR and delved into its architecture. After that, we introduced different TrOCR models and their training strategies. We completed this article by running inference and analyzing the results.
A simple yet effective application could be digitizing old articles and newspapers that are difficult to read clearly by hand.
However, TrOCR also has its limitations when dealing with curved text and text in natural scenes. We will explore this further in the next article, where we will fine-tune the TrOCR model on a curved text dataset and unlock new capabilities.

Original English text: https://learnopencv.com/trocr-getting-started-with-transformer-based-ocr/
