Click I Love Computer Vision to star and get the latest CVML technologies faster
This article is reprinted from Machine Heart.
Selected from Medium
Author:Ajinkya Khalwadekar
Translated by Machine Heart
Contributors:Panda, Egg Sauce
In the fields of machine learning and computer vision, Optical Character Recognition (OCR) and Handwritten Text Recognition (HTR) have long been important topics of research.This article will help computer vision enthusiasts understand how to recognize text in document images.
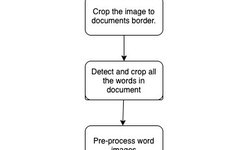
Optical Character Recognition and Handwritten Text Recognition are very classic problems in the field of artificial intelligence.OCR is simply converting document photos or scene photos into machine-encoded text;while HTR performs the same operation on handwritten text.The author breaks this problem down into a set of smaller problems and creates the following flowchart.
Figure 1.1: Application Flowchart
Crop Image by Document Borders
In image processing, it is often necessary to edit images in advance to achieve better representation.Cropping is one of the most commonly used operations in image editing, which can remove unwanted parts of the image and add desired features to the image.
You can easily find the edges of the document in the image using OpenCV. The best way to find the edges of the document in the image is to use a threshold image.OpenCV provides different threshold styles, determined by the fourth parameter of its function.In this function, the first parameter is the source image, which should be a grayscale image;the second parameter is the threshold for classifying pixel values;the third parameter is maxVal, which is the value to be given when the pixel value exceeds (sometimes below) the threshold.
The following code will help you find the threshold image and then determine the contours of the document edges, which you can compare with the edges of the image to determine the document’s edges.
# threshold image
ret, thresh = cv2.threshold(imgray, 150, 255, 0)
cv2.imwrite('thresh.jpg', thresh)
# edge contours
contours, hierarchy = cv2.findContours(thresh, 1, 2)
Detect and Crop/Segment All Words in the Document
Word detection in a constrained controlled environment can usually be achieved using heuristic methods, such as utilizing gradient information or the fact that:text is often grouped into paragraphs and arranged in lines of characters.However, using heuristic methods has drawbacks, as many unwanted areas in the image can also be detected as words, so we can use OpenCV’s EAST (Efficient and Accurate Scene Text) detector.
You can refer to the article about the EAST detector written by Adrian Rosebrock:https://www.pyimagesearch.com/2018/08/20/opencv-text-detection-east-text-detector/
Then improve it based on the method shared by Tom Hoag:https://medium.com/@tomhoag/opencv-text-detection-548950e3494c
This method can detect handwritten text and machine-printed text with high accuracy.After detecting the words in the image, crop them out and save them all.
How should the image be preprocessed?This completely depends on what you are going to do next.If you want to classify handwritten and machine-printed words, all images need to be in grayscale mode.To convert the image to a grayscale image, you also need to use OpenCV:
imgray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
Is this a handwritten word?
This is a classification problem:to determine whether the word in a specific image is “handwritten” or “machine-printed”.The author reviewed several articles and research papers and found that Support Vector Machine (SVM) is the best solution for this problem, then used the SVM classifier from the sklearn package to accomplish this task.
For the dataset used for classification, the author mentioned a good dataset of handwritten words with annotated data, the IAM dataset:http://www.fki.inf.unibe.ch/databases/iam-handwriting-database
For machine-printed word images, the author collected about 2000 word images.Here are the features used for prediction:
1. Average pixel intensity
2. Standard deviation of pixel intensity
3. Otsu threshold
4. Number of local maxima in the pixel intensity histogram
5. Percentage of pixels belonging to the upper quarter of pixel intensity
6. Percentage of pixels belonging to the lower quarter of pixel intensity
According to the above, all features are related to the pixel intensity of the image.The next question is:How to find pixel intensity?
The pixel values of a grayscale image are the pixel intensities, and this can also be done using OpenCV and mathematical operations.
This is the most challenging problem in this article. After trying different solutions (including retraining Tesseract on a handwritten character dataset), the results showed that the method in Harald Scheidl’s article is the best:https://towardsdatascience.com/build-a-handwritten-text-recognition-system-using-tensorflow-2326a3487cd5
The author used a similar approach but made some minor modifications, using a neural network composed of 5 convolutional neural network (CNN) layers, 2 recurrent neural network (RNN) layers, and 1 connectionist temporal classification (CTC) layer.The dataset used to train this neural network is the IAM dataset, but you can also use any labeled word image dataset.
Figure 1.2: Diagram from Harald Scheidl’s article
The input of the CNN layer is a grayscale image of size 128×32.The output of the CNN layer is a sequence containing 32 items, each with 256 features.These features are further processed by the RNN layer, but some features have already shown a high correlation with specific high-level properties of the input image.
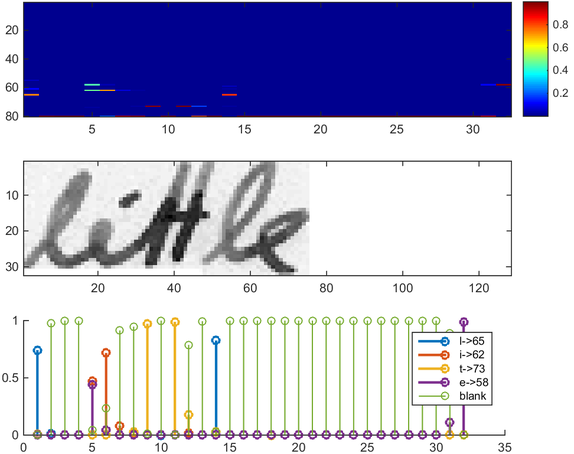
Figure 1.3: Diagram from Harald Scheidl’s article
Figure 1.3 shows the visualized RNN output matrix when processing an image containing the text “little”.The matrix in the top chart contains scores for the characters, with the last item (the 80th) being a CTC blank label.The other matrix items correspond to the following characters from top to bottom:!”#&()*+,-./0123456789:;?ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
It can be seen that most of the time, the predicted characters appear right at their positions in the image (for example, you can compare the position of i in the image and the chart).Only the last character e is not aligned.But this is actually not a problem, because the CTC operation is unsegmented and does not care about absolute positions.The bottom chart shows the scores of the characters l, i, t, e, and the CTC blank label, and this text can be easily decoded:We just need to take the most likely character from each time step, which will form the so-called best path, then we discard duplicate characters, and finally discard all blanks, resulting in:“l—-ii—t-t—l-…-e”→”l—-i—t-t—l-…-e”→”little”.
For more detailed information on how to implement this method, please refer to Harald Scheidl’s article.
Tesseract is currently the best open-source OCR tool for machine-printed character recognition.Tesseract supports the Unicode (UTF-8) character set and can recognize more than 100 languages, also including various output supports such as plain text, PDF, TSV, etc.However, to achieve better OCR results, the quality of the images provided to Tesseract must also be improved.
Note that before performing actual OCR, Tesseract internally performs various different image processing operations (using the Leptonica library).It usually performs well, but in some cases, the results may not be good enough, leading to significant drops in accuracy.
Before passing the image to Tesseract, you can try the following image processing techniques, but which techniques to use depends on the images you want to read:
1. Invert the image
2. Rescale
3. Binarization
4. Remove noise
5. Rotate/Adjust tilt angle
6. Remove edges
All these operations can be implemented using OpenCV or through Python using numpy.
To summarize briefly, this article introduces some issues and possible solutions related to OCR and HTR.If you want to truly understand, you must try to implement them yourself.
Original link:https://medium.com/@ajinkya.khalwadekar/building-ocr-and-handwriting-recognition-for-document-images-f7630ee95d46
OCR Group Chat
Follow the latest cutting-edge OCR and HTR technologies, scan the code to add CV Jun to pull you into the group (if you are already friends with other CV Jun accounts, please directly private message)
(Please be sure to indicate: OCR)

If you like to communicate on QQ, you can add the official QQ group: 805388940.
(Not always online, please forgive if you don’t pass the verification in time)

Long press to follow I Love Computer Vision