

Part.1
Overview of RAG
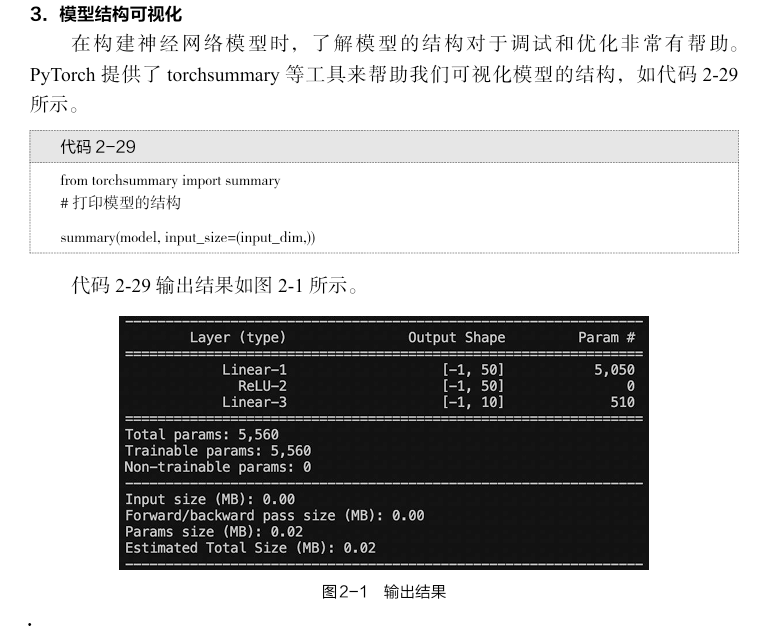
· Retriever: This is the first stage of the RAG model, responsible for retrieving documents relevant to the query from a pool of candidate documents. It can utilize various retrieval techniques and algorithms, such as keyword matching and semantic similarity, to quickly filter out potentially relevant documents.
· Generator: This is the second stage of the RAG model, responsible for generating summaries or answers related to the query based on the retrieved candidate documents. It typically employs generative models, such as language models or Generative Adversarial Networks (GANs), to produce text in natural language.
· Ranker: This is the final stage of the RAG model, responsible for ranking and scoring the generated text to determine the final output order of the documents. It can utilize various ranking algorithms, such as machine learning and deep learning, to score and rank the documents.
(1) Supports diverse search needs, including document retrieval, question answering, and summary generation.
(2) Supports multilingual and multimedia searches, including various forms of information such as text, images, audio, and video.
(3) Effectively utilizes deep learning techniques to represent and model documents, thereby improving the accuracy and relevance of search results.
(4) Provides personalized search services based on user queries and historical search records, enhancing the user search experience.
· Application in enterprise knowledge management systems: Intelligent knowledge retrieval and sharing, intelligent Q&A and problem-solving, knowledge graph construction and intelligent recommendation, intelligence analysis and decision support;
· Application in online Q&A systems: Automatic Q&A and customer service, internal knowledge sharing and collaboration, educational and learning assistance;
· Application in intelligence retrieval systems: Rapid information retrieval and analysis, integration of diverse information resources, intelligence analysis and decision support.
……
Part.2
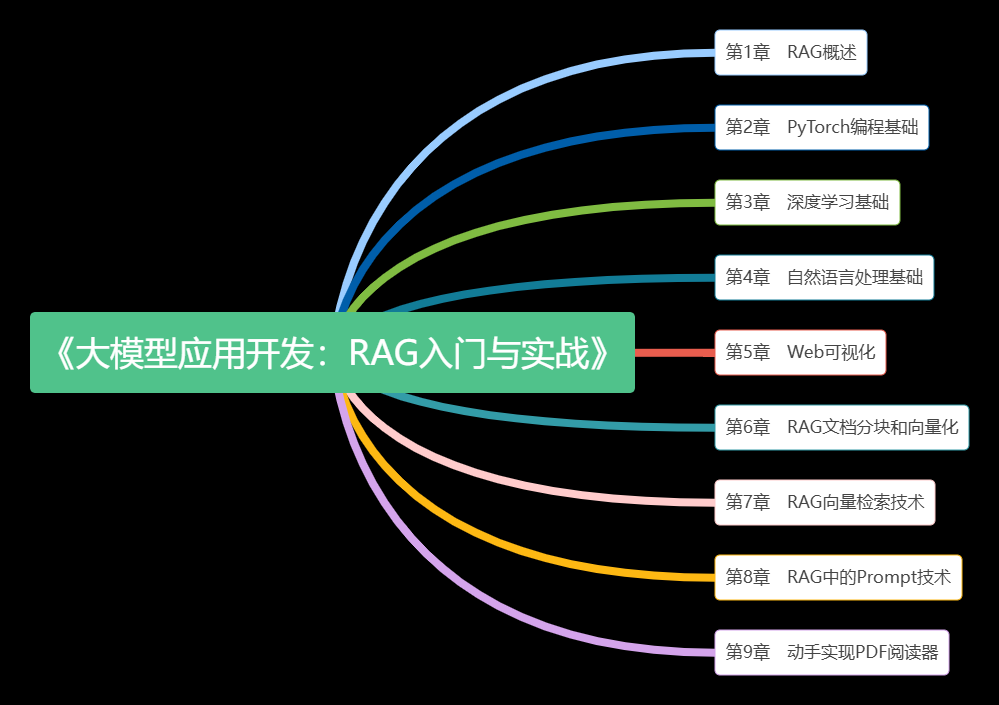
Hands-On RAG Development
Basic Introduction
Technical Deep Dive
Practical Applications



Part.3
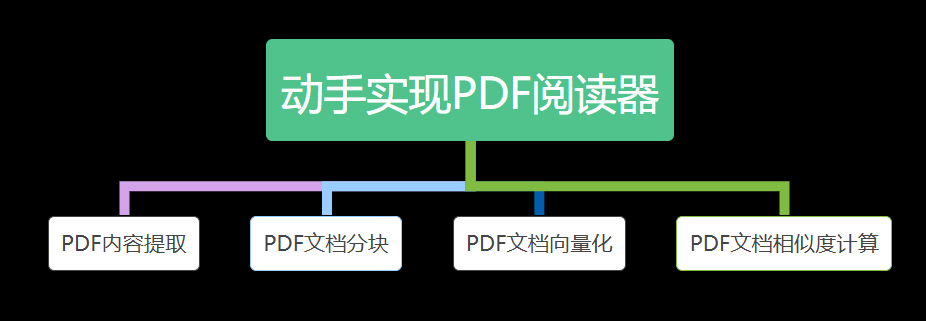
① Comprehensive Coverage: It takes you from document extraction all the way to similarity search, covering every core aspect of document search to ensure you master the key technologies.
② In-Depth Analysis: Each aspect is not just superficially covered, but delves into the core of the technology, with practical cases showing how to apply it in projects.
③ Cutting-Edge Technology: Not only does it teach you the old ways, but it also introduces you to the application of cutting-edge technologies like large model Q&A in document search, keeping you abreast of technological trends.
④ Simple and Understandable: It uses plain language, avoiding professional jargon and complex mathematics, making it accessible for beginners.
 ▼Click below toget the book at half price, for the first 200 people
▼Click below toget the book at half price, for the first 200 people
Share Your Thoughts on RAG
Participate in the interaction in the comment section, and click on ‘Like’ and share the activity to your friend circle. We will select one reader to receive a free e-book, deadline October 15.