
RAG can be said to be one of the most successful application modes in the era of large models. Through the retrieval-generation method, it significantly expands the application boundaries of large models. However, implementing RAG in practice is not so simple. Those who have worked on RAG systems must have encountered the following problems:
In what scenarios or problems is retrieval needed? A calculation problem like 1+2=? seems not to need it, but why does 1+2=3 seem to require it?
Is the retrieved information useful? Is it correct?
How to use the retrieved information? Should it be directly concatenated with the user’s question, or does it need to be compressed before concatenation?
What logic should be used for recall? Does the recalled information need to be sorted?
……
There are no universally applicable answers to these questions; solutions vary in different scenarios and data contexts.
Since the popularity of RAG in 2023, various RAG frameworks or solutions have emerged, with dozens if not hundreds available, such as AnythingLLM, RAGFlow, and Ollama. Each can build a complete knowledge base based on RAG, but general applicability does not equal usability. Each scenario, and even each individual’s data, is unique, posing significant challenges for the effectiveness of RAG systems. However, this has also led to a flourishing of research in the RAG field.
Today, let’s take a look at some recent articles on RAG together with everyone to understand the academic exploration in RAG.
Brief Summary
We can observe the following trends:
-
Specialization trend: Many RAG variants have been optimized for specific fields, such as healthcare, finance, and materials science.
-
Multimodal integration: More and more RAG technologies are beginning to handle multimodal data, such as combinations of video, images, and text.
-
Security considerations: With the popularity of RAG technology, security issues (such as those studied by RAG-Thief) are also gaining attention.
-
Efficiency optimization: New RAG variants are attempting to improve processing efficiency and reduce computational costs in various ways.
-
Enhanced interpretability: Many new methods emphasize the importance of interpretability, trying to make the model’s decision-making process more transparent.
Innovations in Infrastructure
Have you ever encountered a situation where asking RAG a question results in either a lot of relevant but inaccurate information or an outright irrelevant answer? It’s like a newcomer at work who, despite having a good knowledge base, doesn’t quite know how to “get to the point”.
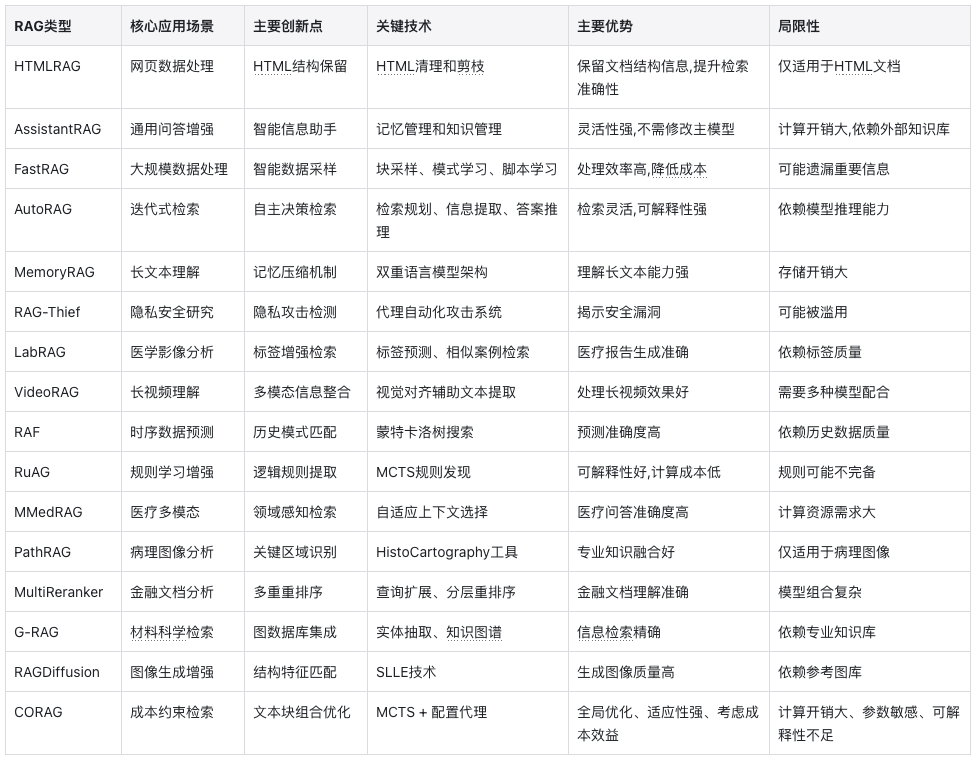
To address these foundational issues, researchers have proposed a series of innovative solutions. For example, the AutoRAG proposed by the Chinese Academy of Sciences is no longer just about “finding what you give” but teaches the RAG system to make independent judgments.

For instance, if you ask, “Who is the voice actor of the donkey in ‘Shrek’?” a regular RAG system might clumsily search all materials containing “donkey” and “voice acting.” But AutoRAG thinks this way:
Do you see the difference? AutoRAG is like an assistant that can think independently, knowing how to step by step find the most accurate answer. Moreover, it can explain its thought process in natural language, helping you understand why it does what it does. This transparency is particularly important in practical applications.
CORAG proposes a solution from another angle. Existing RAG systems often consider text blocks independently when selecting them, ignoring the relevance between text blocks. It’s like answering a complex question by only looking at scattered knowledge points without organically connecting them.
The core innovation of CORAG is to use Monte Carlo Tree Search (MCTS) to explore the optimal combination order of text blocks while introducing configuration agents to dynamically adjust system parameters. It’s like playing an advanced version of a puzzle game:
However, this method also has its limitations: building and traversing the strategy tree requires considerable computational resources, and parameter adjustments need careful balancing.
We all know that large models have context length limitations, and excessively long context content significantly reduces the effectiveness of large models. This is especially evident in RAG. To allow RAG to “remember” and “understand” knowledge, researchers have proposed some very interesting solutions.
FastRAG developed a two-step strategy: first, quickly define the scope using simple keyword matching, then identify the most relevant content using more complex semantic analysis, just like when you look for a book, first checking the classification label on the shelf to find the general area, then locating the specific book based on the title and table of contents. Isn’t this the logic of traditional search engines’ recall-coarse ranking-fine ranking?
Perhaps the authors of AssistantRAG intended to draw inspiration from the concept of adapters, proposing a similar design: since a large model’s memory capacity is limited, equip the main model with a “specialized secretary” model.
The secretary model is responsible for memory management and knowledge management; it records historical Q&A information, assesses the usefulness of this memory for current questions, and breaks down complex questions into simpler sub-questions to retrieve external knowledge for each one, while the main model generates the final output. This method’s advantage lies in its flexibility, allowing quick adaptation in different scenarios by changing the secretary model.

MemoryRAG introduces a “memory module,” akin to an experienced librarian who not only knows how to find books but also understands the reader’s potential needs. For instance, when you want to find a book on the theme of love, the title might not even include the word love.
MemoryRAG employs a dual architecture: one handles long texts to form a holistic impression, while the other is responsible for generating the final answer. This design is particularly suitable for handling complex queries that require a global understanding, such as analyzing character relationships in literary works or summarizing long reports.
To better utilize external knowledge, RuAG enhances the model’s understanding through rule-based methods. For example, in weather forecasting scenarios, rather than having the model memorize vast amounts of weather data, it is taught to understand rules like “if the temperature exceeds 30 degrees and the humidity is below 50%, then the weather is clear.” This method is easier to comprehend and remember, with lower computational costs.
Handling Complex Data
As RAG application scenarios continue to increase, we may encounter various types of data: web pages, PDFs, text, time series, audio, video, etc., each data type presents unique challenges.
In web data processing, HtmlRAG offers a clever solution. It does not simply convert web pages into plain text, but attempts to retain HTML tags that convey important meanings. It first cleans out “interference information” like advertisement codes and style sheets from the web page while retaining HTML tags that convey important meanings.
For example, the tag “
Windows Installation Tutorial
” will be preserved because it indicates that this is an important title. Compared to plain text methods, HtmlRAG can utilize web information more efficiently based on such structured information.
Time series forecasting is a long-standing issue, such as predicting tomorrow’s weather, stock trends, or electricity consumption. Traditional methods often treat these predictions as independent tasks. But think about it: if we could find similar historical situations as references, would the prediction be more accurate?

For instance, if you are predicting tomorrow’s temperature in a city, finding historical days with very similar weather conditions and observing how the temperature changed afterward would yield a more accurate prediction.
This is the core idea of the proposed retrieval-augmented forecasting (RAF). It first finds similar pattern fragments in historical data, observes how the patterns changed thereafter, and uses these historical experiences as references for prediction.
Beyond text, have you considered that the RAG concept can also be applied to video understanding scenarios? But do you know what issues current large language models face when processing long videos? The main problem is “forgetting” — context window limitations make it difficult for them to handle long videos.
Some teams have attempted to extend the model’s processing capabilities through fine-tuning, while others have tried using larger models. However, these methods either require large amounts of training data or are too costly.
VideoRAG proposes a unique approach. It understands videos from different angles:
Indeed, understanding videos from multiple dimensions can yield better results, but aligning different pieces of information may be a consideration.

Innovations in Vertical Domains
RAG technology has shown strong application potential in various vertical domains. Researchers have proposed a series of innovative solutions tailored to the characteristics of different fields.
In the medical field, accurate and reliable diagnostic information processing is crucial. LabRAG mimics the process of a doctor viewing images, first identifying key medical findings and then writing reports based on these findings. PathRAG is optimized specifically for pathological slice images, combining key area identification with large language models, improving accuracy by nearly 10 percentage points.

MMedRAG addresses the frequent hallucination issues that medical visual language models encounter when generating answers. It introduces domain-aware retrieval mechanisms, adaptive context selection methods, and RAG-based preference fine-tuning strategies, significantly enhancing the originality and reliability of generated content.
In the field of materials science, G-RAG provides an innovative solution. It integrates graph databases into the retrieval process, employing techniques such as entity extraction and association, intelligent document parsing, and graph-enhanced retrieval, achieving accuracy scores far superior to traditional RAG systems. This improvement is particularly important in fields like materials science that require precise information.
RAGDiffusion offers a practical solution for the fashion e-commerce sector. It acts like an experienced photographer, analyzing input clothing photos to find similar reference samples in a standard clothing image database, then employing multi-level generative alignment strategies to ensure high-quality generated images.
Surprisingly, this system also exhibits excellent generalization; by simply updating the retrieval database, it can handle entirely new clothing styles. This flexibility is particularly important in the fast-changing fashion industry.
Financial analysts read a large volume of financial reports, announcements, and research reports daily, with particularly high timeliness requirements. To address this, researchers developed the MultiReranker system. Its operation is as follows:
First, it decomposes and rewrites the user’s question from multiple dimensions. For example, when you ask, “What is the ROE for Q3?” the system will first understand:
Then, it adopts a “multi-level filtering” strategy, like forming a team of financial analysts:
Through multi-level retrieval mechanisms, it achieves efficient utilization of information. Particularly, when the input text is too long, the system splits the document in half to process separately, then merges the generated answers, ensuring both accuracy and efficiency.
The Double-Edged Sword of RAG

There is no absolutely secure system, nor is there absolutely secure technology.
With the widespread application of RAG technology in sensitive fields such as healthcare, finance, and law, security issues are becoming increasingly prominent. The research by RAG-Thief clearly reveals the security risks present in current RAG systems.
Many might wonder: RAG systems only return relevant information; how could there be security issues? However, researchers have revealed risks through cleverly designed experiments.
Imagine a hospital using a RAG system to answer medical inquiries. When someone asks, “What are the symptoms of a cold?” the system would normally return general medical knowledge.
But if someone cleverly designs a question to extract original case information, the system might inadvertently leak patient privacy data. The paper found that without special protective measures, attackers could extract over 70% of the knowledge base content.
To tackle these issues, some exploratory measures can be taken. For example, at the system level, strict access control mechanisms need to be established, sensitive content should be desensitized, and comprehensive security audit systems should be implemented. On the algorithmic level, noise perturbation and differential privacy techniques can be introduced to reduce the risk of information leakage. Regular security assessments and timely vulnerability fixes are also essential in daily operations.
Conclusion
Finally, a brief summary. The RAG paradigm is simple and understandable, but many problems and pain points arise in the actual implementation process. The RAG methods or frameworks mentioned above only provide directions for optimization exploration; truly harnessing the effects of RAG in one’s own scenarios requires further exploration.
When applying RAG in practice, comprehensive considerations can be made. If performance is unsatisfactory, various combinations can be tried. Ultimately, avoid overly focusing on performance when the results are not up to standard; after all, discussing performance without considering results is disingenuous!

Scan the QR code to add assistant WeChat
About Us
