What Are Large Language Models (LLM)
Large Language Models (LLM), also known as large language models, are a type of artificial intelligence model designed to understand and generate human language. The LLMs we commonly refer to typically contain hundreds of billions (or more) parameters and are trained on massive amounts of text data, allowing them to gain a deep understanding of language.
In contrast, there is also VLM (Visual Language Model), which is an artificial intelligence model that combines visual information processing with language understanding. This model can not only process text data but also understand and generate descriptions related to images, achieving semantic associations between images and text. VLMs are typically used for tasks such as image captioning, Visual Question Answering (VQA), and multimodal translation. By integrating visual and language information, VLMs can provide richer and more accurate language generation and understanding capabilities.
To explore the limits of performance, many researchers have started training increasingly larger language models, such as GPT-3 with 175 billion parameters and PaLM with 540 billion parameters. Although these large language models use similar architectures and pre-training tasks as smaller language models (for example, BERT with 330 million parameters and GPT-2 with 1.5 billion parameters), they exhibit vastly different capabilities, especially showing remarkable potential in solving complex tasks, known as “emergent abilities.” For instance, while GPT-3 can solve few-shot tasks by learning from context, GPT-2 performs poorly in this regard. Therefore, the research community has coined the term “Large Language Model (LLM)” for these massive language models. A prominent application of LLM is ChatGPT, which is a bold attempt to use the GPT series of LLMs for conversational applications with humans, demonstrating very fluent and natural performance.
For mainstream LLMs, refer to:
https://arxiv.org/abs/2303.18223
Capabilities and Characteristics of LLM
One of the most significant features distinguishing large language models (LLM) from previous pre-trained language models (PLM) is their emergent abilities. Emergent abilities are surprising capabilities that are not evident in smaller models but are particularly pronounced in larger models. Similar to phase transition phenomena in physics, emergent abilities are like a sudden improvement in model performance as the scale increases, surpassing random levels, which we often refer to as qualitative changes caused by quantitative changes.
Emergent abilities can be related to certain complex tasks, but we are more concerned with their general capabilities. Next, we briefly introduce three typical emergent abilities of LLM:
-
Contextual Learning: The ability for contextual learning was first introduced by GPT-3. This capability allows the language model to perform tasks by understanding context and generating corresponding outputs when provided with natural language instructions or multiple task examples, without the need for additional training or parameter updates.
-
Instruction Following: By fine-tuning with multi-task data described in natural language, known as instruction fine-tuning. LLMs have been shown to perform well on unseen tasks described in instruction format. This means that LLMs can execute tasks based on task instructions without having seen specific examples beforehand, demonstrating their strong generalization capabilities.
-
Step-by-Step Reasoning: Smaller language models often struggle with complex tasks that involve multiple reasoning steps, such as mathematical problems. However, LLMs utilize a Chain of Thought (CoT) reasoning strategy, employing a prompting mechanism that includes intermediate reasoning steps to solve these tasks and arrive at final answers. This ability is speculated to be acquired through training on code.
These emergent abilities enable LLMs to excel in handling various tasks, making them powerful tools for solving complex problems and applying across multiple fields.
Characteristics of LLM
Large language models have several significant characteristics that have sparked widespread interest and research in natural language processing and other fields. Here are some of the main characteristics of large language models:
-
Massive Scale: LLMs typically have a massive parameter scale, reaching tens of billions or even hundreds of billions of parameters. This allows them to capture more linguistic knowledge and complex grammatical structures.
-
Pre-training and Fine-tuning: LLMs adopt a learning method of pre-training and fine-tuning. They are first pre-trained on large-scale text data (unlabeled data) to learn general language representations and knowledge. Then they are fine-tuned (labeled data) to adapt to specific tasks, resulting in excellent performance across various NLP tasks.
-
Context Awareness: LLMs have strong context awareness when processing text, enabling them to understand and generate text content that relies on previous context. This allows them to excel in dialogue, article generation, and situational understanding.
-
Multilingual Support: LLMs can be used for multiple languages, not limited to English. Their multilingual capabilities make cross-cultural and cross-linguistic applications easier.
-
Multimodal Support: Some LLMs have expanded to support multimodal data, including text, images, and sounds. This enables them to understand and generate content across different media types, allowing for more diverse applications.
-
Ethical and Risk Issues: Despite their impressive capabilities, LLMs also raise ethical and risk issues, including generating harmful content, privacy concerns, and cognitive biases. Therefore, research and application of LLMs need to be approached with caution.
-
High Computational Resource Requirements: LLMs have a vast parameter scale and require substantial computational resources for training and inference. They typically need high-performance GPU or TPU clusters to achieve this.
Introduction to Retrieval-Augmented Generation (RAG)
Compared to traditional language models, large language models (LLM) have more powerful capabilities; however, they may still fail to provide accurate answers in certain cases. To address the challenges faced by large language models in generating text and improve the performance and output quality of the models, researchers have proposed a new model architecture: Retrieval-Augmented Generation (RAG). This architecture cleverly integrates relevant information retrieved from a vast knowledge base and uses it as a basis to guide large language models in generating more precise answers, significantly enhancing the accuracy and depth of responses.
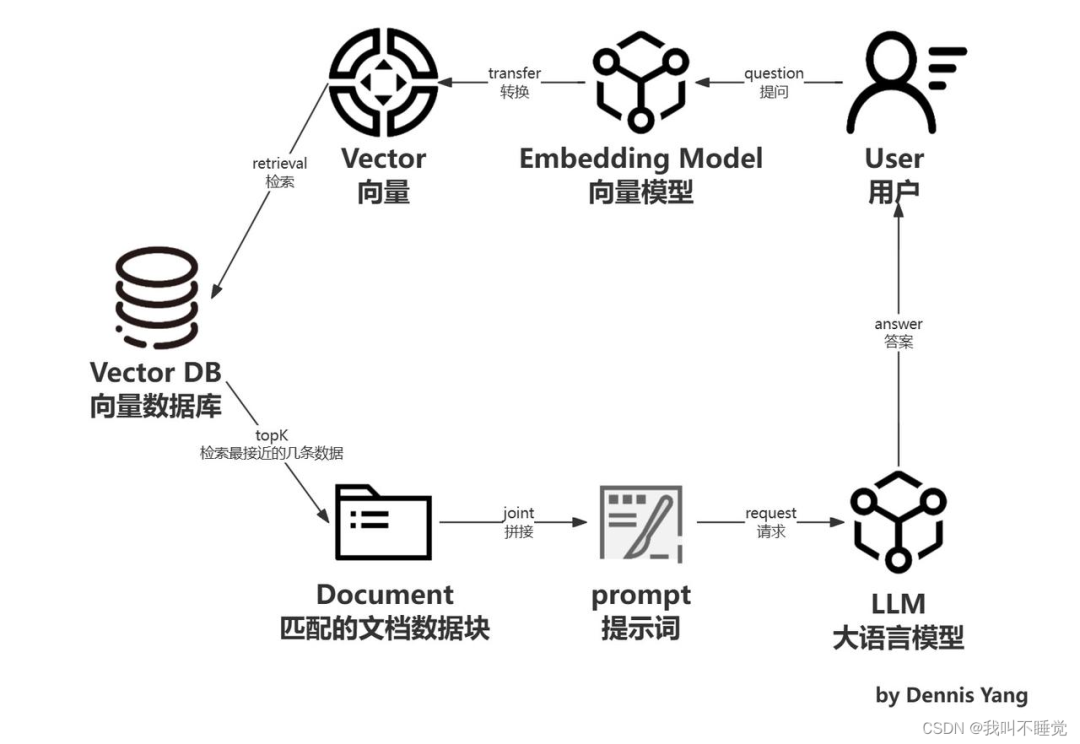
RAG is a complete system, whose workflow can be simply divided into four stages: data processing, retrieval, augmentation, and generation:
1. Data Processing Stage
-
Clean and process the raw data.
-
Convert the processed data into a format usable by the retrieval model.
-
Store the processed data in the corresponding database.
2. Retrieval Stage
Input the user’s question into the retrieval system to retrieve relevant information from the database.
3. Augmentation Stage
Process and enhance the retrieved information so that the generation model can better understand and utilize it.
4. Generation Stage
Input the enhanced information into the generation model, which generates answers based on this information.
RAG vs Fine-tune
Fine-tuning: This involves further training the large language model on specific datasets to improve its performance on specific tasks.
|
Features |
RAG |
Fine-tuning |
|
Input and Feedback |
Automatically filter and synthesize knowledge bases without retraining. Information is presented flexibly to meet actual data needs. |
Generally requires retraining or using specific datasets to train the model. The model’s flexibility and adaptability are relatively low. |
|
Incorporation of External Knowledge |
Through long-term deployment evolution, continuous iterations will import their specialized/non-proprietary databases into the model. |
External knowledge is learned internally within the LLM. |
|
Data Processing |
Low requirements for data processing and manipulation. |
Relies on building high-quality datasets; limited datasets may lead to poor generalization of information. |
|
Model Customization |
Smart knowledge through information retrieval and fusion, but may not fully customize model behavior or industry relevance. |
Can customize LLM behavior based on specific areas or contexts, with stronger industry relevance. |
|
Interpretability |
Can transparently introduce external data sources, with good interpretability and traceability. |
Black box, with relatively low interpretability. |
|
Computational Resource Consumption |
Requires close resource investment to support the establishment and maintenance of large-scale knowledge bases. |
Relies on expensive training resources to maintain and train the model, with high computational resource demands. |
|
Inference Speed |
Increases the time spent on retrieval steps. |
Pure LLM completes tasks faster. |
|
Application Scenarios |
Suitable for models where retrieved real information includes industries such as politics and healthcare. |
Models have relatively flexible learning capabilities for specific domain data, but may still produce inaccuracies when facing unseen scenarios. |
|
Information Update Frequency |
Systems and use of external data sources can automate regular and continuous updates. |
Strict management of sensitive information in streaming data to prevent leaks. |
Swipe left and right to view the complete table
Recruitment Requirements
Complete the production of robot-related videos that meet the requirements
The total duration must reach more than 3 hours
The video content must be high-quality courses, ensuring quality and professionalism
Instructor Rewards
Enjoy course revenue sharing
Gift 2 courses from GuYue Academy’s premium courses (excluding training camps)
Contact Us
Add staff WeChat: GYH-xiaogu




