


Recently, the Qwen team released the technical report titled “Qwen2.5 Technical Report”. Below is a brief summary of the report to help everyone gain a quick understanding.
Link: https://arxiv.org/pdf/2412.15115
Abstract
Qwen2.5 is a series of large language models (LLMs) designed to meet diverse needs. Compared to previous versions, Qwen 2.5 has made significant improvements in both pre-training and post-training phases. The pre-training dataset has been expanded from 70 trillion tokens to 180 trillion tokens, providing the model with a solid foundation of common sense, expert knowledge, and reasoning capabilities. The post-training phase includes complex supervised fine-tuning with over 1 million samples and multi-stage reinforcement learning, significantly enhancing the model’s alignment with human preferences, long text generation, structured data analysis, and instruction-following capabilities.
Features of the Qwen2.5 Series
-
Diverse configurations: Offers different sizes of base models and instruction-tuned models ranging from 0.5B to 72B parameters, as well as quantized versions.
-
Performance: Demonstrates outstanding performance in multiple benchmark tests, especially in language understanding, reasoning, mathematics, coding, and alignment with human preferences.
-
Model scale: Qwen2.5-72B-Instruct competes in performance with Llama-3-405B-Instruct, which is five times larger.
Architecture and Tokenizer
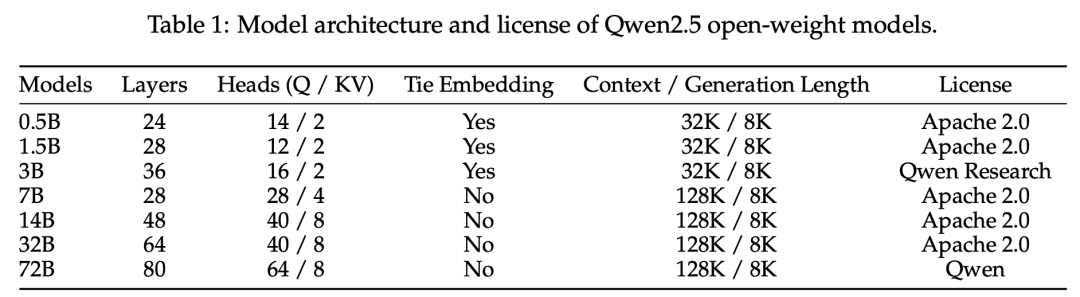
The Qwen2.5 series includes dense models based on Transformer and MoE (Mixture of Experts) models for API services. The model architecture includes grouped query attention, SwiGLU activation functions, and rotary position embeddings. The tokenizer uses byte-level Byte Pair Encoding (BBPE) with a vocabulary of 151,643 regular tokens.
Pre-training
The quality of the pre-training data has been significantly improved, including better data filtering, integration of mathematical and code data, generation of synthetic data, and data mixing (mainly through data manipulation). The pre-training data has increased from 70 trillion tokens to 180 trillion tokens.
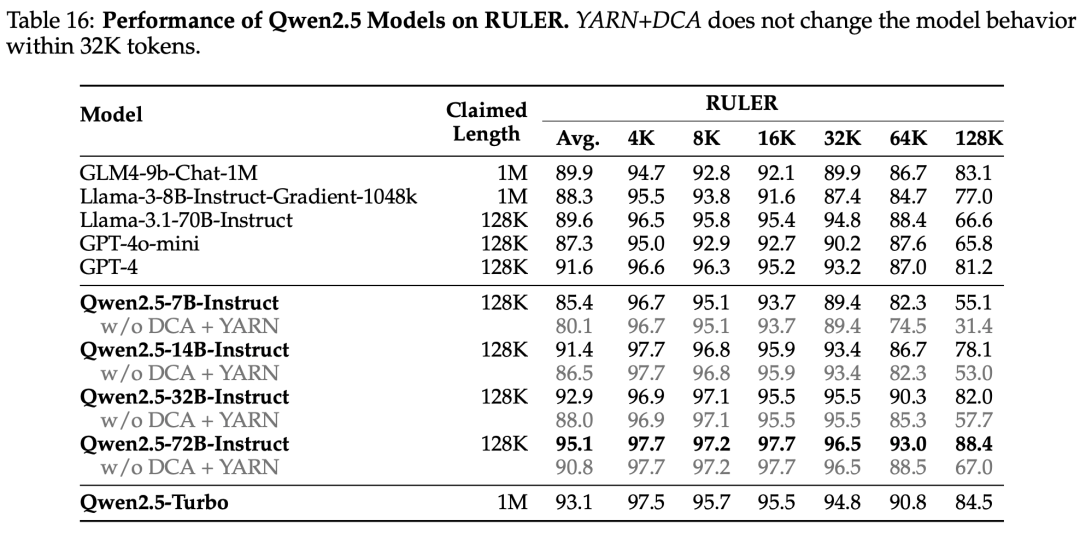
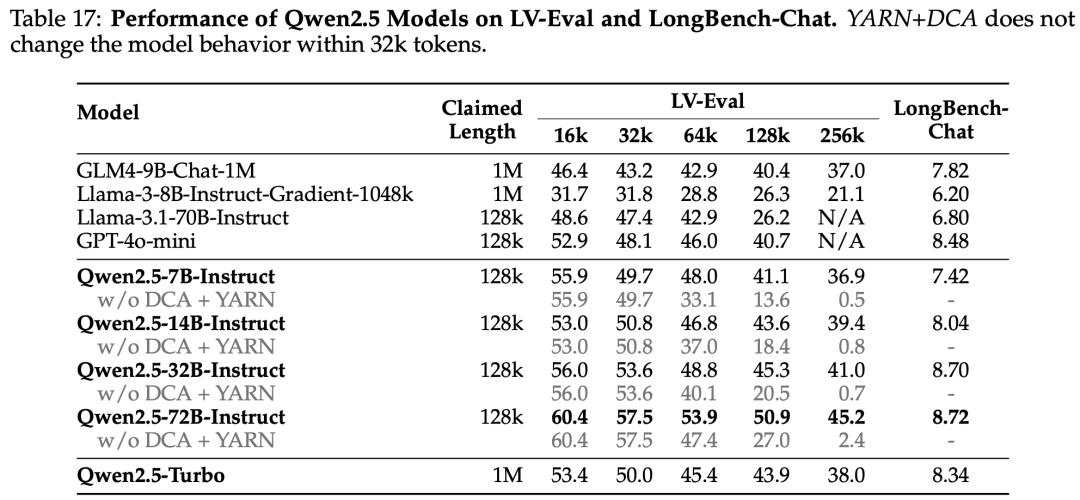
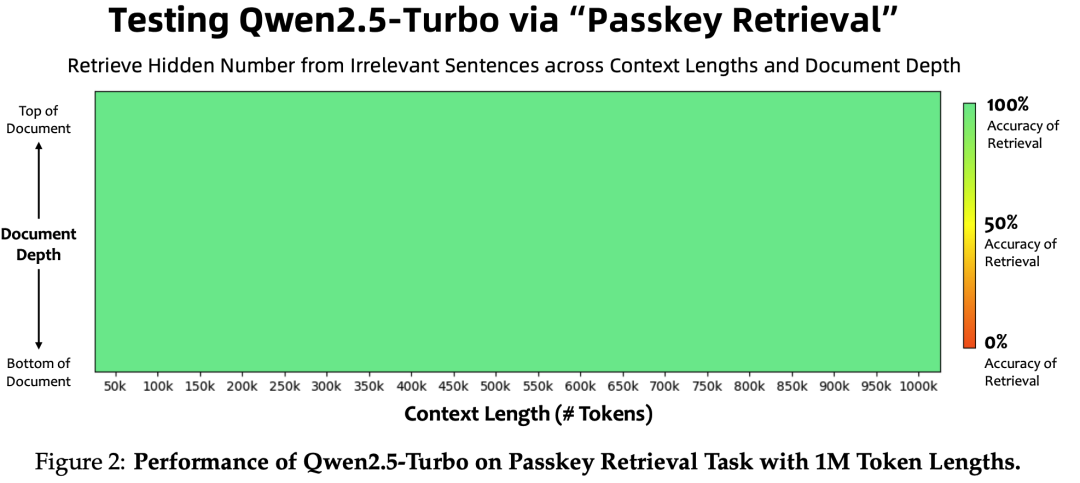
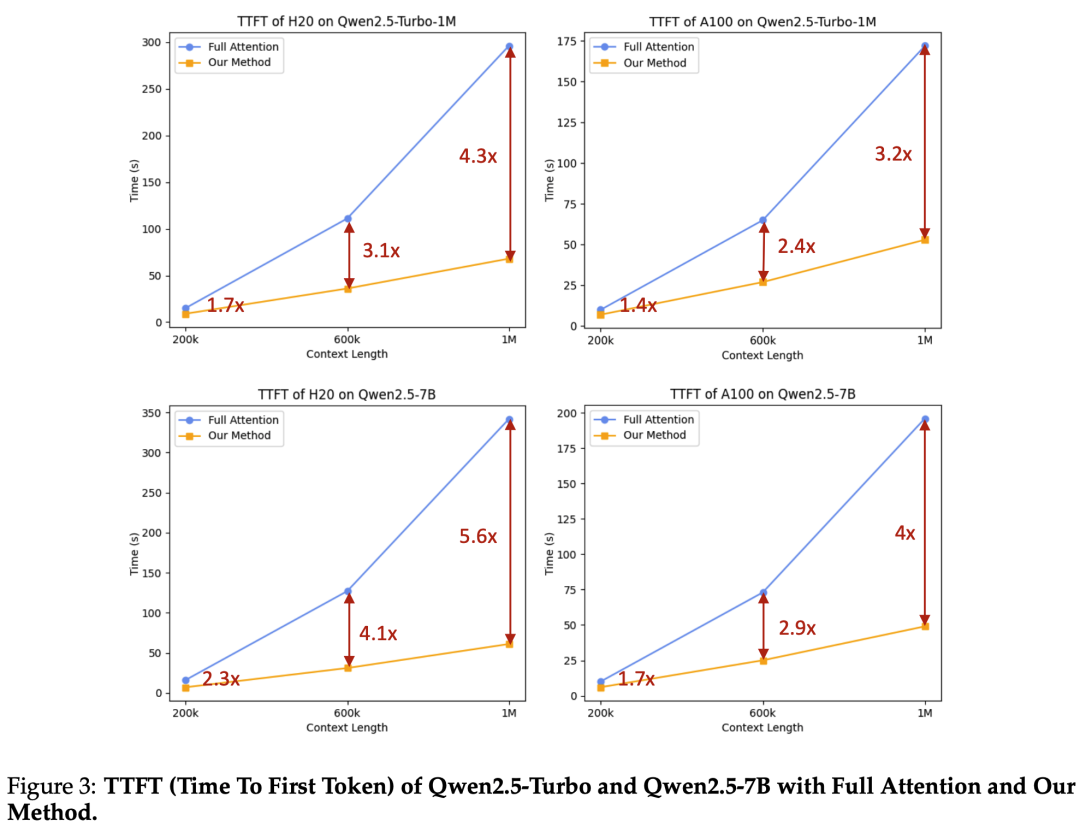
Long context pre-training has been enhanced, with RoPE’s base increasing from 10,000 to 1,000,000, and context length expanding from 4,096 to 32,768. To support long-context performance, YARN (Peng et al., 2023) and Dual Chunk Attention (DCA, An et al., 2024) techniques have been used, enabling Qwen2.5-Turbo to handle 1 million tokens while other models can manage up to 131,072 tokens.
Post-training
Qwen 2.5 introduces two significant advancements in post-training design: expanded coverage of supervised fine-tuning data (mainly through data manipulation) and two-stage reinforcement learning (first offline DPO followed by online GRPO).
Evaluation
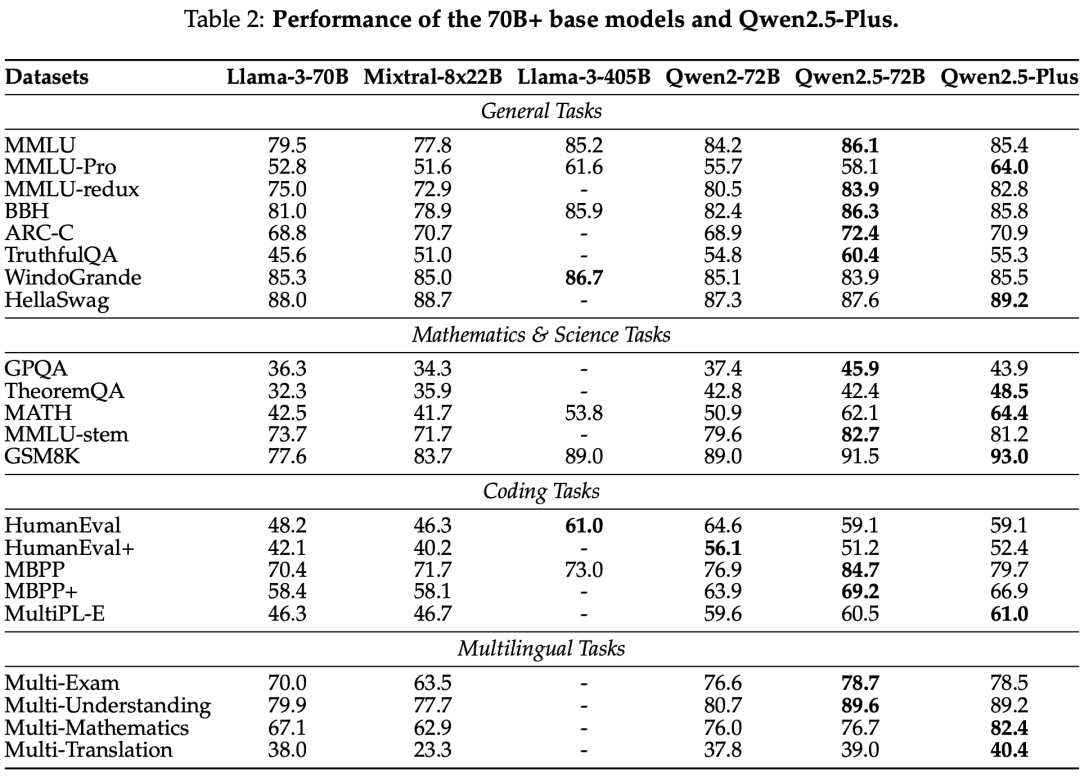
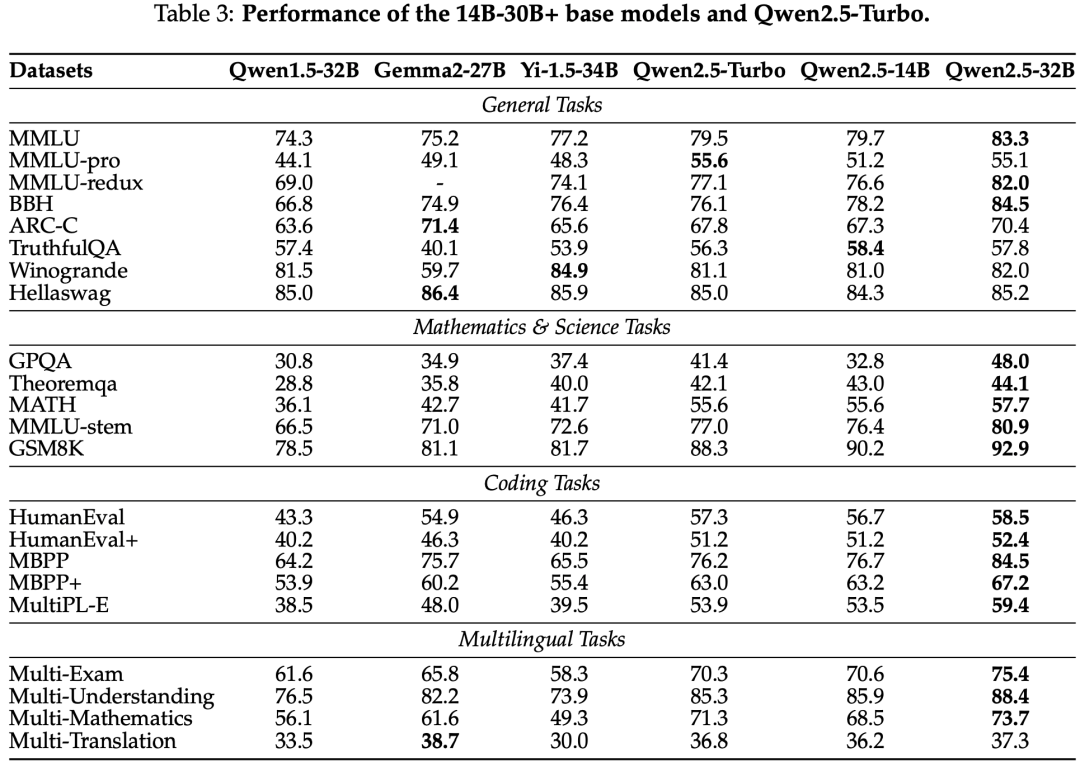
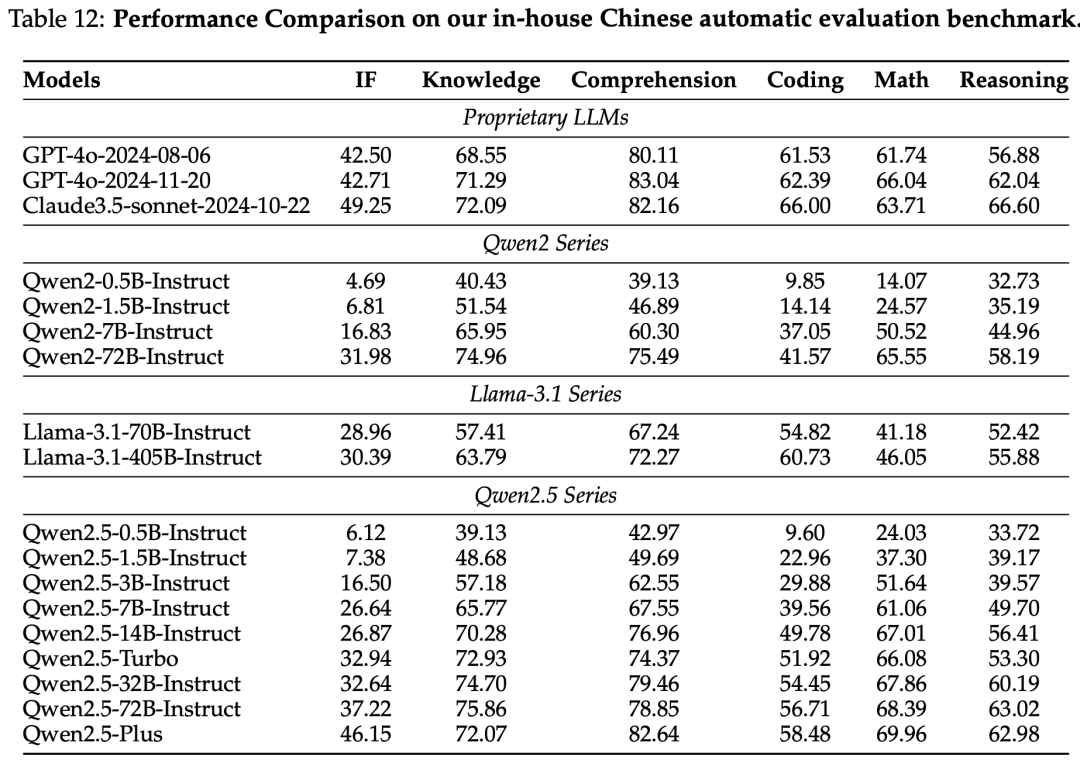
The Qwen2.5 series models have been evaluated on multiple benchmark tests, including natural language understanding, programming, mathematics, and multilingual capabilities. Qwen2.5-72B and Qwen2.5-Plus excelled in various tasks, competing with leading open-weight models.
Base Model
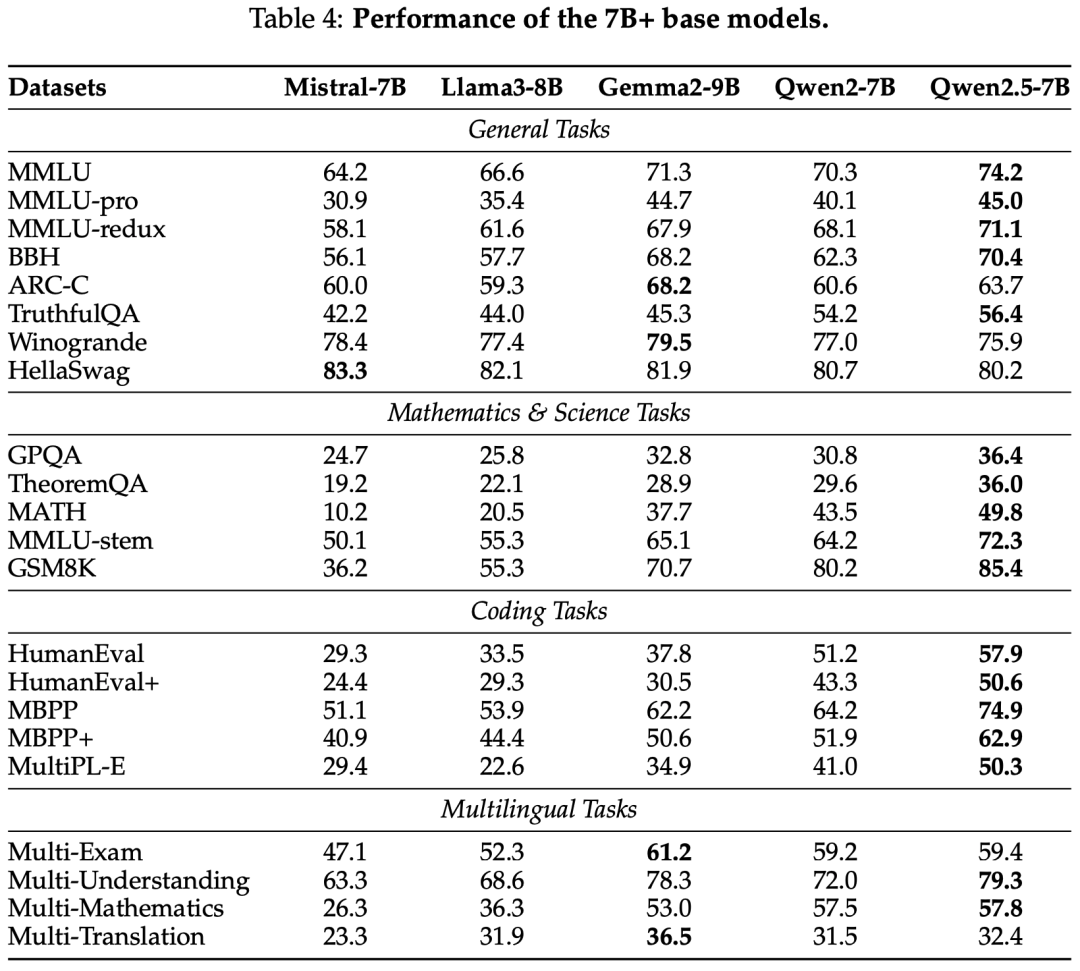
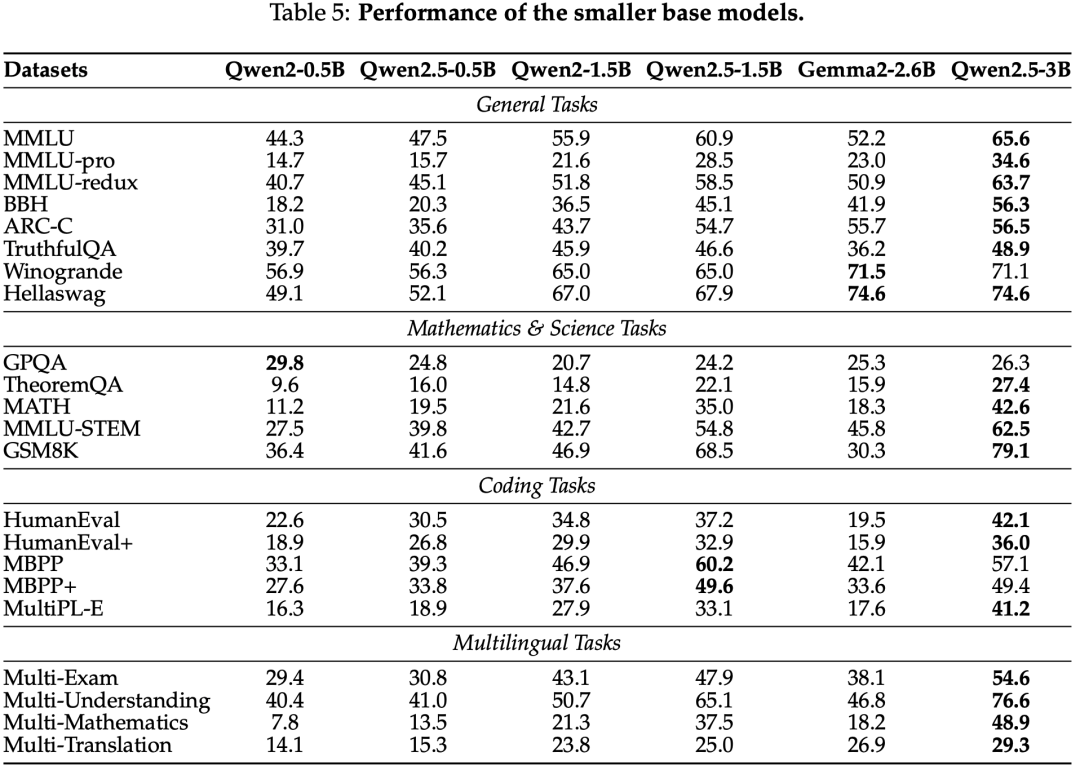
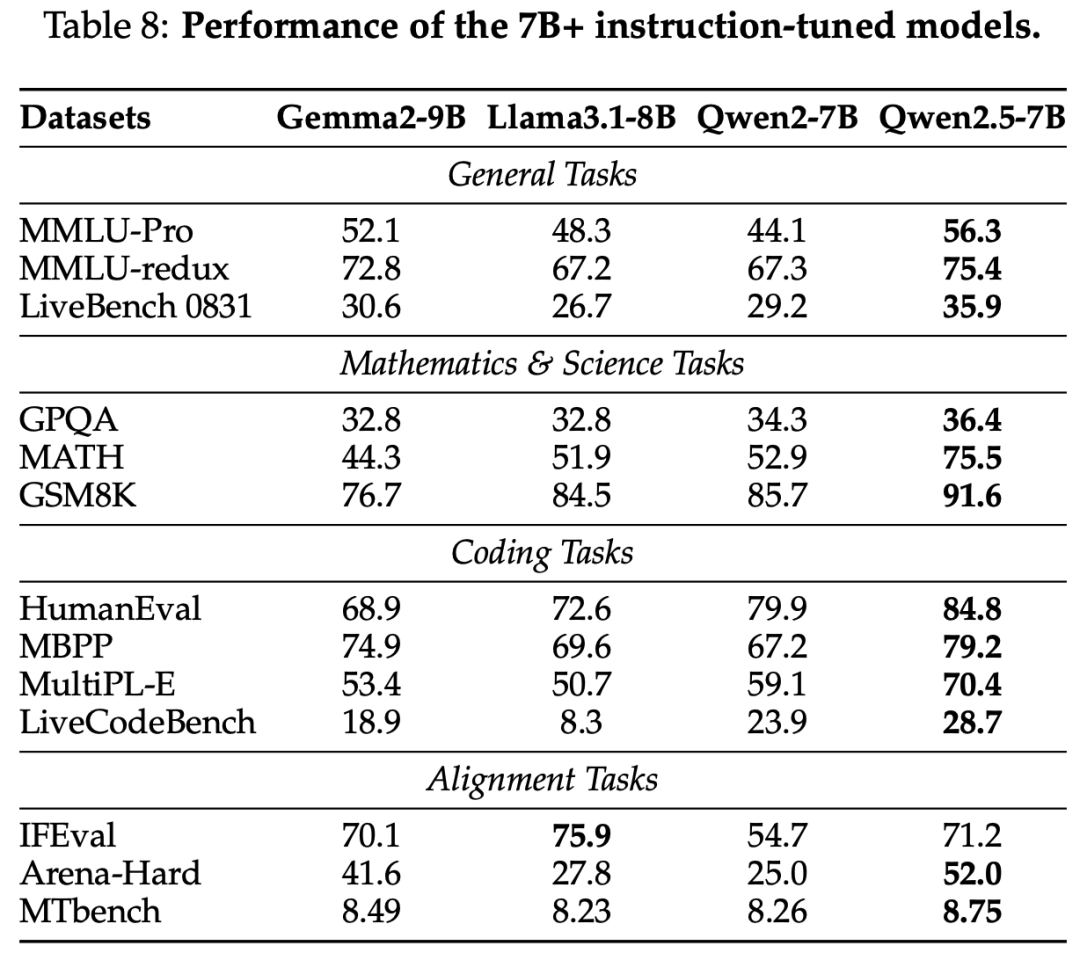
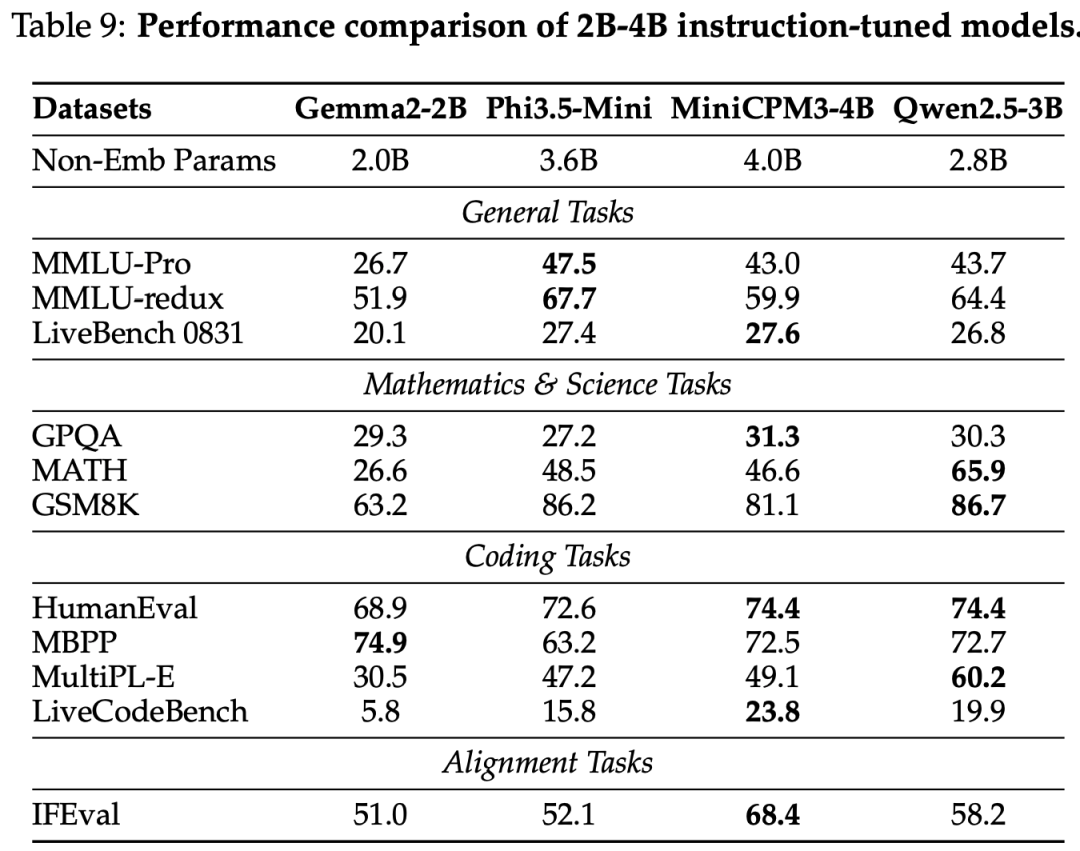
Instruct Model
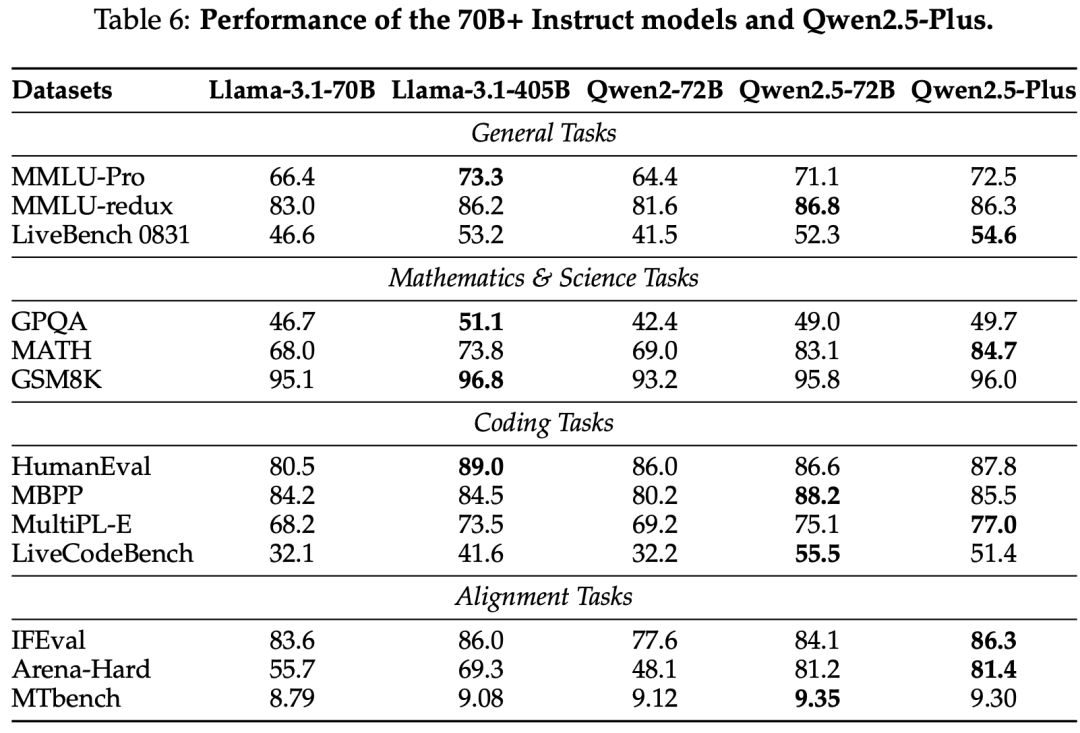
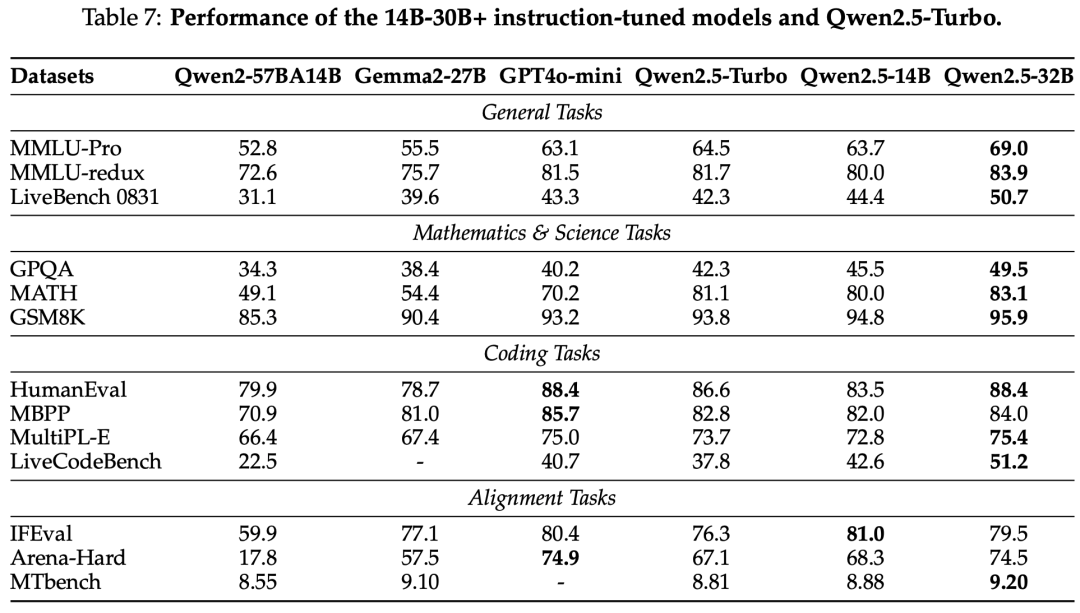
On Our In-house Chinese Automatic Evaluation
Long Text
Conclusion
Qwen2.5 represents a significant advancement in large language models, offering various configurations and excelling in multiple benchmark tests. The powerful performance, flexible architecture, and broad availability of Qwen2.5 make it a valuable resource for academic research and industrial applications.

Scan the QR code to add the assistant WeChat
About Us
Conclusion