Recently, the official Ollama released its Python tool library. This article introduces a guide to integrating Ollama into Python, showcasing how developers can easily utilize AI capabilities. 

The previous article discussed how to deploy Ollama’s large model. This time, we will expand on that foundation to create a web Q&A bot.
Integrating the large model into a notebook: Ollama + Open Web UI
Design Idea:
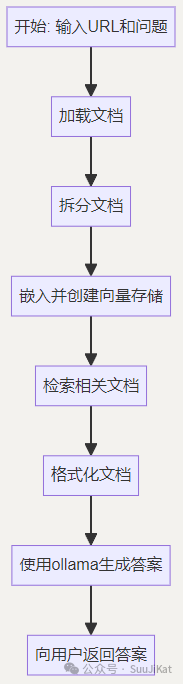
1
First, we create a new Python environment and install the Ollama Python library.
conda create -n ollama python=3.11
conda activate ollama
pip3 install ollama
Next, we install the necessary dependencies, such as langchain (prompt engineering), beautifulsoup4 (HTML scraping), chromadb (handling word embeddings), and gradio (graphical interface), and then create a Python file.
pip3 install langchain beautifulsoup4 chromadb gradio
# Create Python file
New-Item QAmachine.py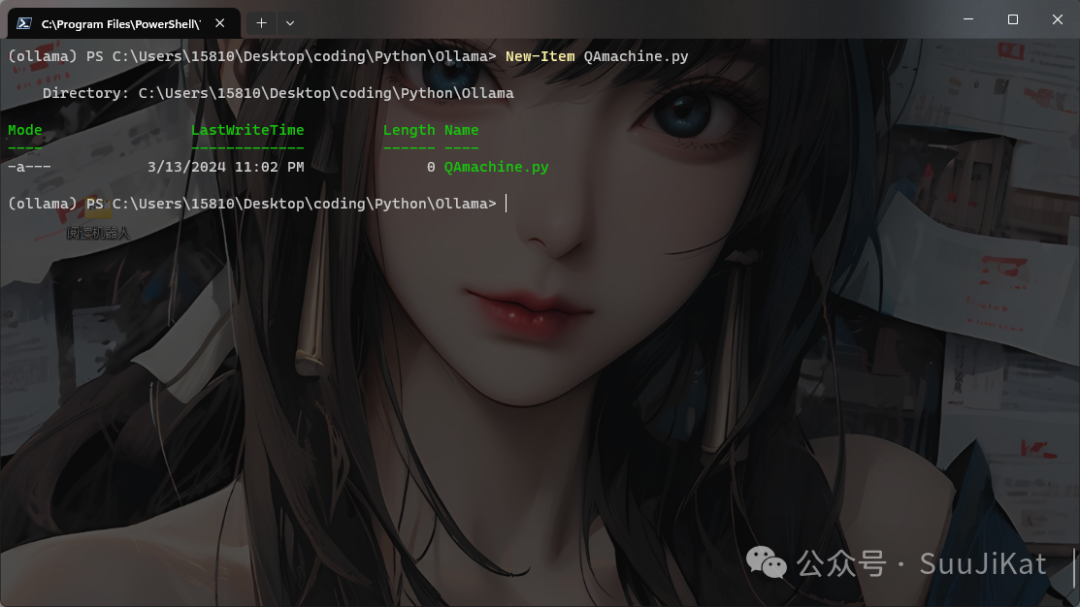
2
In the file, first import the dependencies and create a web content receiver, splitter, and embedding storage to load, split, and retrieve documents later. Most of this uses langchain’s interface, which is very useful in large model applications. Note that the LLM used here is OpenAI’s “Mistral,” suitable for text processing.
import gradio as gr
import bs4
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import OllamaEmbeddings
import ollama
# Function to load, split, and retrieve documents
def load_and_retrieve_docs(url):
# Initialize document loader with given URL
loader = WebBaseLoader(
web_paths=(url,),
bs_kwargs=dict() # Empty dictionary for BeautifulSoup's initialization parameters
)
# Load documents
docs = loader.load()
# Initialize document splitter, set chunk size and overlap size
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
# Split documents
splits = text_splitter.split_documents(docs)
# Initialize embedding model
embeddings = OllamaEmbeddings(model="mistral")
# Create vector store from document splits and embeddings
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
# Convert vector store to retriever and return
return vectorstore.as_retriever()3
Merge document contents and define the retriever to answer questions from the text content, thus implementing RAG.
# Function to format documents
def format_docs(docs):
# Merge document contents into a single string and return
return "\n\n".join(doc.page_content for doc in docs)
# Define RAG chain execution function
def rag_chain(url, question):
# Load and retrieve documents related to the URL
retriever = load_and_retrieve_docs(url)
# Use retriever to fetch documents based on the question
retrieved_docs = retriever.invoke(question)
# Format the retrieved documents
formatted_context = format_docs(retrieved_docs)
# Construct input prompt for the Ollama model
formatted_prompt = f"Question: {question}\n\nContext: {formatted_context}"
# Use Ollama model to generate an answer
response = ollama.chat(model='mistral', messages=[{'role': 'user', 'content': formatted_prompt}])
return response['message']['content']4
Finally, create a web UI with Gradio and write the launch command.
# Create Gradio interface
iface = gr.Interface(
fn=rag_chain,
inputs=["text", "text"],
outputs="text",
title="RAG Chain Web Q&A",
description="Enter URL and get answers from the RAG chain."
)
# Launch command
iface.launch()After saving the code, run it by entering python + QAmachine.py in the command line, and click the port link to enter the web Q&A bot interface~
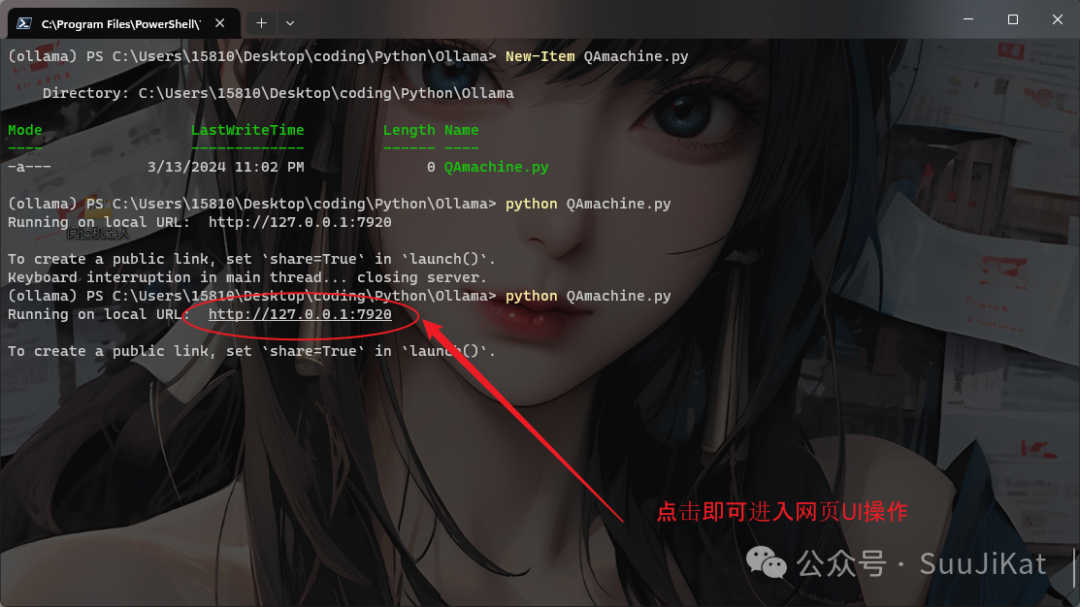
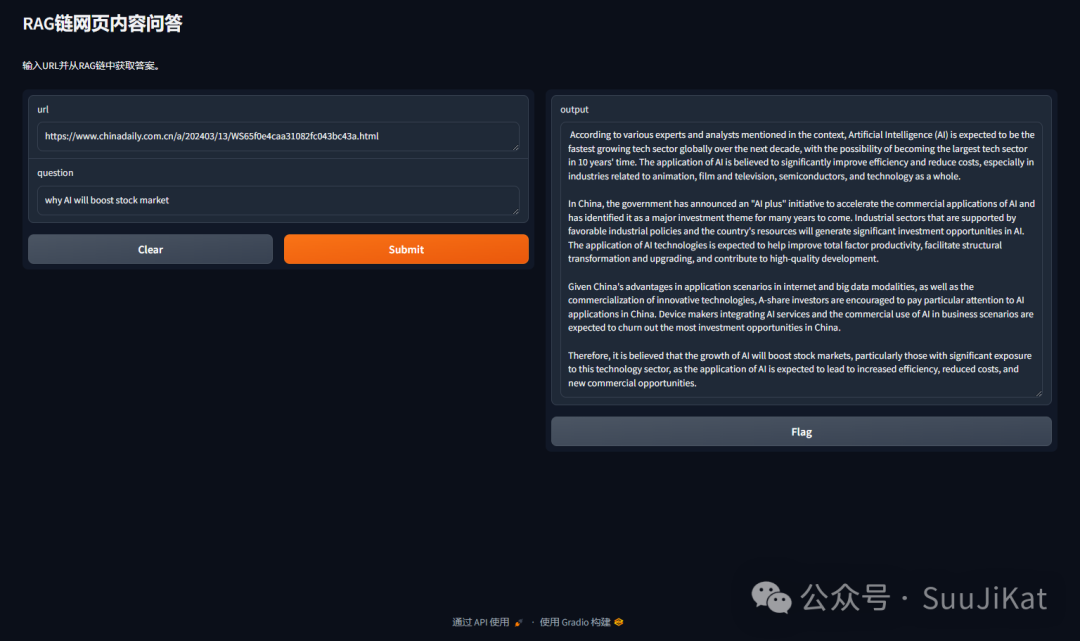
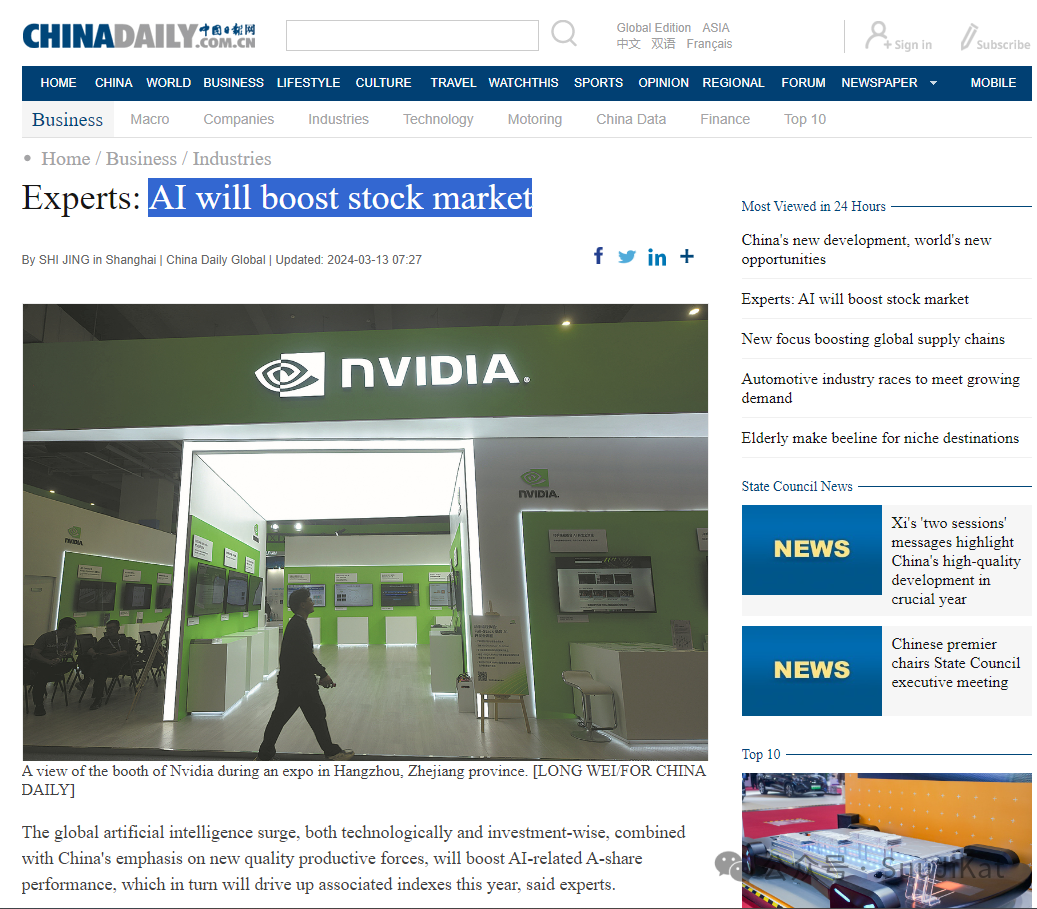
Here, I tested with a news report from “China Daily,” and the accuracy of the content was very high, which is very RAG. I will continue to explore more local LLM applications. Bye~