
To pave the way for future workflows and local models, it is necessary to discuss the installation of the Ollama local large language model backend.

1. Ollama
Before installation, it is necessary to clarify what Ollama is..
Ollama is a backend service for large language models that helps users easily deploy large language models without any prior knowledge.
Its features include:
Advantages: The Ollama backend service allows users to easily build large language model services and provides corresponding APIs to extend to other web frontends like Dify and note-taking software like Obsidian, forming AI Q&A/AGENT/workflow formats at the fastest speed. Additionally, Ollama offers free downloads of models, allowing users to directly download various mainstream open-source large language models. Ollama also supports different systems such as Windows, Linux, and MacOS.
Disadvantages: Some special open-source models are not supported/not included, and the number of models is large, requiring users to discern the characteristics of large language models based on their needs.
From various perspectives, Ollama is currently the fastest and most convenient backend for local large language models.
2. Installing Ollama
2.1 Download Ollama
Before downloading, please note:
1. Windows systems require Windows 10 or higher;
2. If you want to run models larger than 7B, it is recommended to have at least 6GB of video memory and 16GB of RAM, with a dedicated graphics card being preferable. Non-dedicated graphics cards will use the CPU, which will significantly slow down performance.
The download address for Ollama is:
https://ollama.com
After opening the page, the official website will appear. Click on Download to download:
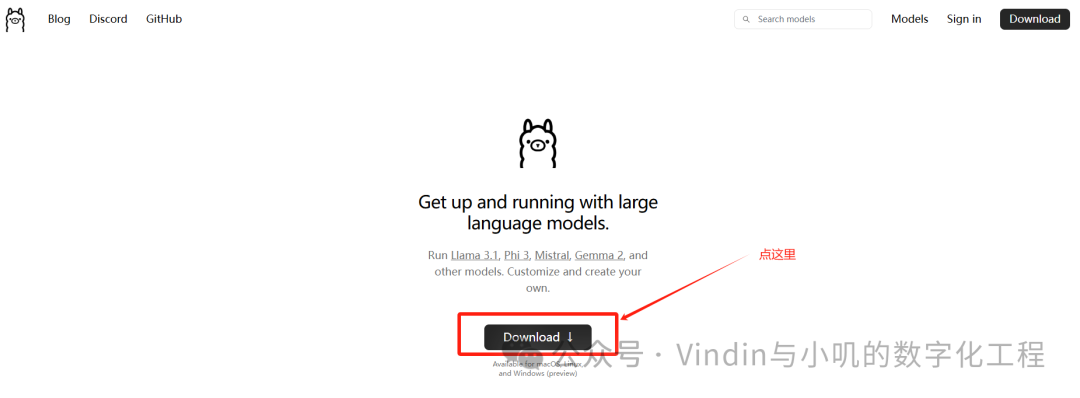
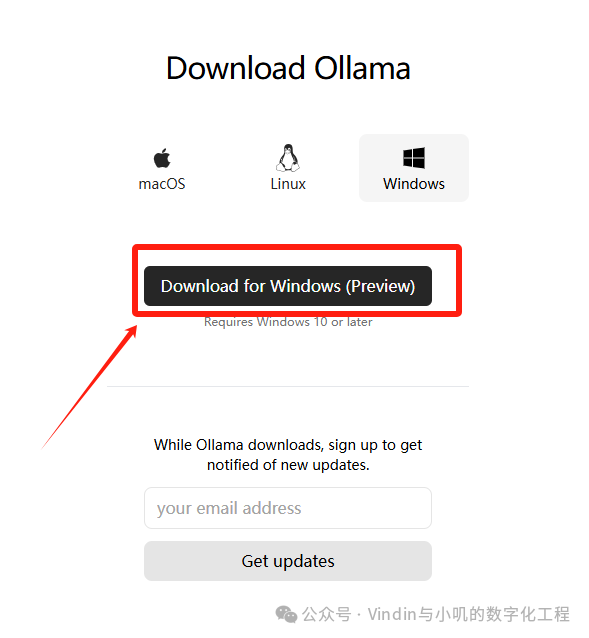
After clicking download, the corresponding Ollama program will be downloaded. Once downloaded, double-click and proceed with the installation steps to run it.
2.2 Check if the installation was successful
If the installation is successful, Ollama will appear in the lower right corner:

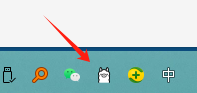
If this icon appears, it indicates that Ollama has been successfully installed.
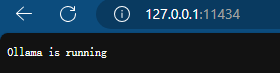
Open your browser and enter
http://127.0.0.1:11434
or
http://localhost:11434
If a line of small text appears, it indicates that the Ollama service is running successfully.
2.3 Ollama model download path settings
If you don’t want your C drive to be occupied by large model downloads (many are several GB to tens of GB), you can make the following settings; if it’s not a concern, you can skip this operation:
Click the Windows start button or directly open the start menu, select settings, or press the Windows shortcut key win+i to open settings:
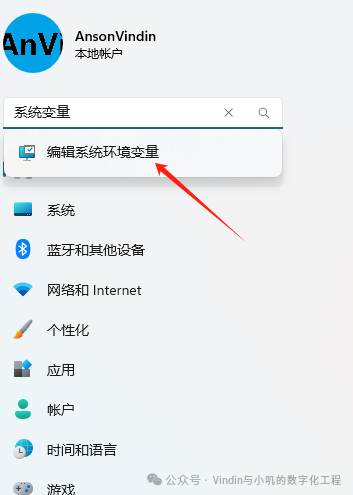
Type system variables in the search box.
Select Environment Variables in the pop-up window, then click New in the User Variables section of the new window, and enter the following in the pop-up small window:
Variable name:
OLLAMA_MODELS
Variable value:
(The path where you want to store the large language models, for example: if I want to store the models in the E drive under the Github code folder named OLLAMAMODEL, the variable value would be as follows)
E:\Github code\OLLAMAMODEL
Click OK, and this new variable will appear in your user variables.
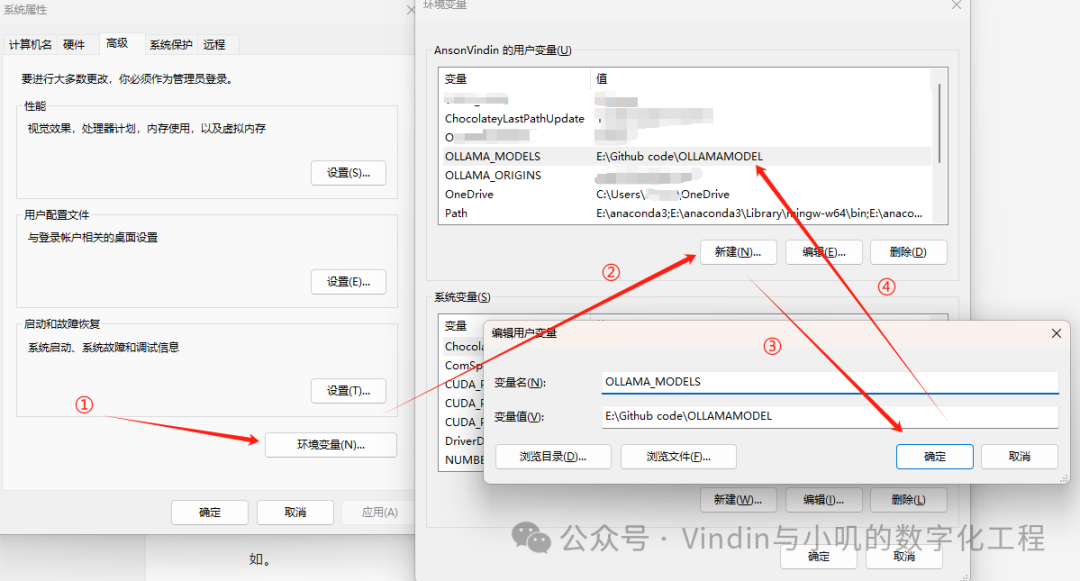
As for the variable OLLAMA_HOST, it is not recommended to set it as it may be detrimental for Docker deployment.
3. Running Ollama
Note: If the above operations are successful but the following operations are not successful, you may need to restart your computer.
3.1 Ollama Trial Run (Non-Large Model)
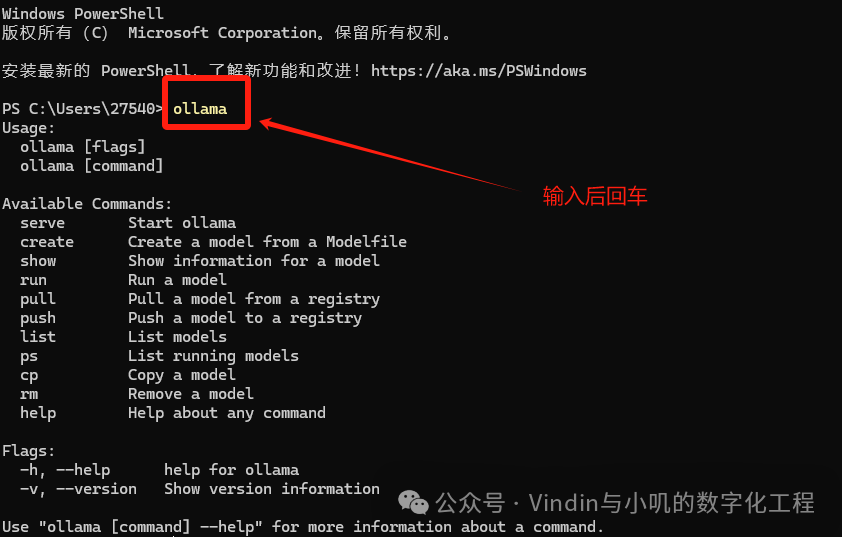
Right-click on the windows button and select Terminal Administrator/Terminal. Alternatively, you can press win+r and type cmd to start the command prompt, but it is recommended to use Administrator Privileges:

In the opened black window, type ollama, then press Enter. If the following content appears, it indicates that the service is normal:
If you need images, videos, mini-program cards, or code blocks, it is more convenient to obtain them from the WeChat backend.
3.2 Ollama Model Selection
Enter the Ollama model library to find models:
https://ollama.com/library
However, at this point, you may not know which model to search for or what your business scenario ideas are, so I recommend the following models:
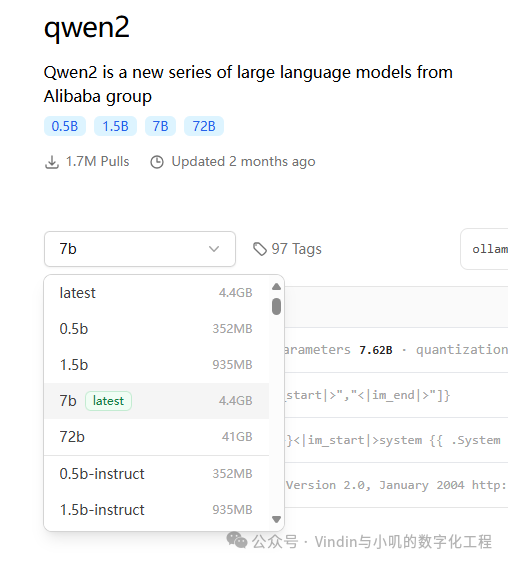
Qwen2: The Qwen2 large model has excellent support for Chinese and is considered one of the best general-purpose open-source models for Chinese. It is recommended to use the 1.5B model (running on CPU) for average computers and the 7B model (preferably with a dedicated graphics card). The larger 72B model is not recommended if the graphics card capability is poor.
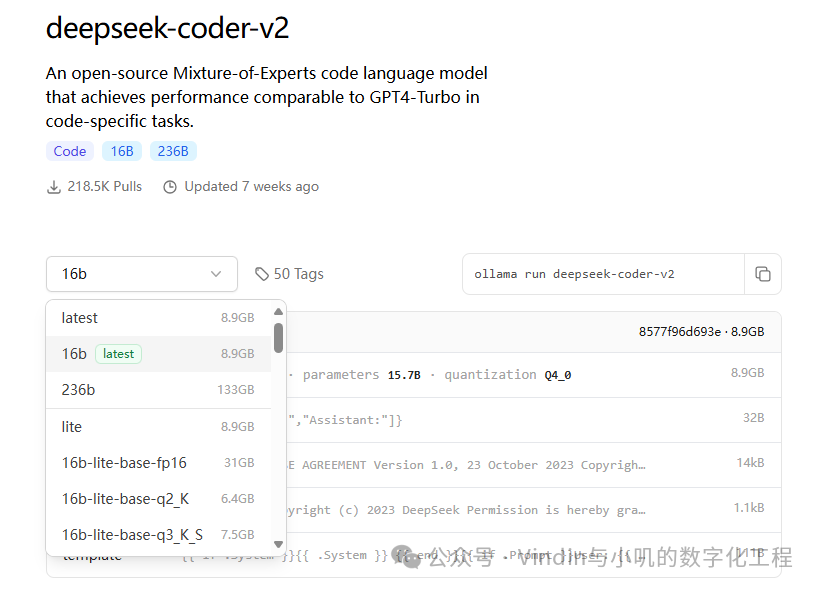
deepseek-coder-v2: If you are a programmer, then deepseekV2 is definitely suitable for you. It uses the MoE architecture and provides good response speed, supporting multiple programming languages, and can be understood as a very good programming assistant model.
Phi3: A small model from Microsoft that runs very fast, occupies very little space, and has decent performance, suitable for running models on computers with insufficient hardware. However, because the model is too small, its input and output capabilities are very limited. For the medium model of Phi3, we can retract the previous statement, but the main training data is in English, so its Chinese capabilities are average.
The above is a screenshot of the Phi3 medium model.
Llama3.1: The latest Llama model, it is recommended to use the 8B model or the corresponding quantized model (which can run very fast). If your primary language is Chinese, llama3.1 may not be the most suitable for you.
command-r and command-r-plus: The Command-r series is one of my personally favorite large models. In previous comparisons of versions 9.8 and 9.11, it was the only one that answered correctly, and the model is very organized, making it very suitable for use as a corporate large model. However, the models are quite large, especially command-r+, which has a size of 104B that is not suitable for ordinary graphics cards, thus requiring high hardware specifications. This company has also released excellent large models like aya, which is also a great model for character-driven digital humans.
llava: A highly recommended multimodal large model that can recognize images and output them, but has poor support for Chinese, so it is recommended to use the variant llava-llama3, which has better language support.
bge-large and bge-m3: An embeddings knowledge compression model that is not used for text output, but for knowledge compression, especially with good support for Chinese text, making it a special large model. bge-m3 is the latest model of bge.
3.3 Downloading Ollama Models
For the large models you like, select the corresponding large model, and the command to run will automatically appear on the right. Here, we take the recently hyped llama3.1 model as an example:
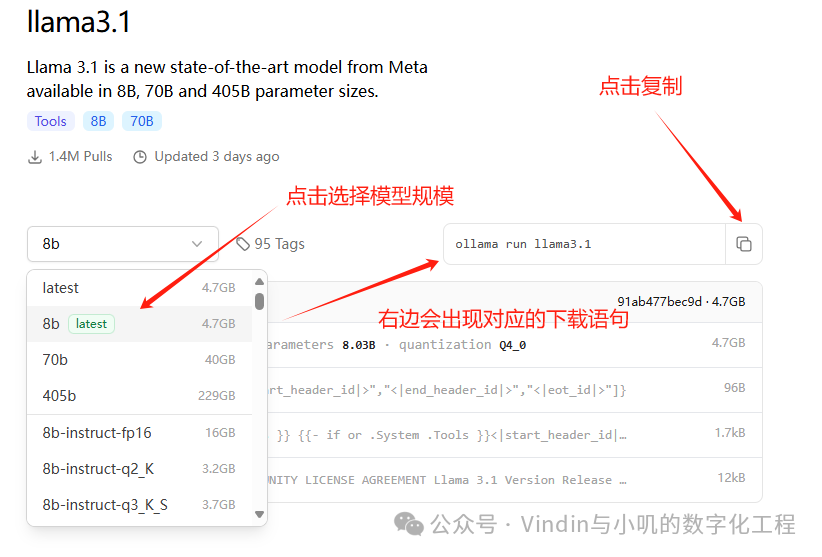
Then right-click in the black window to copy the command to the run bar and press Enter:
Wait for the download to complete; there will be a progress bar, and the time depends on your internet speed.

After the download is complete, it will run automatically (already downloaded models will run directly, as below):
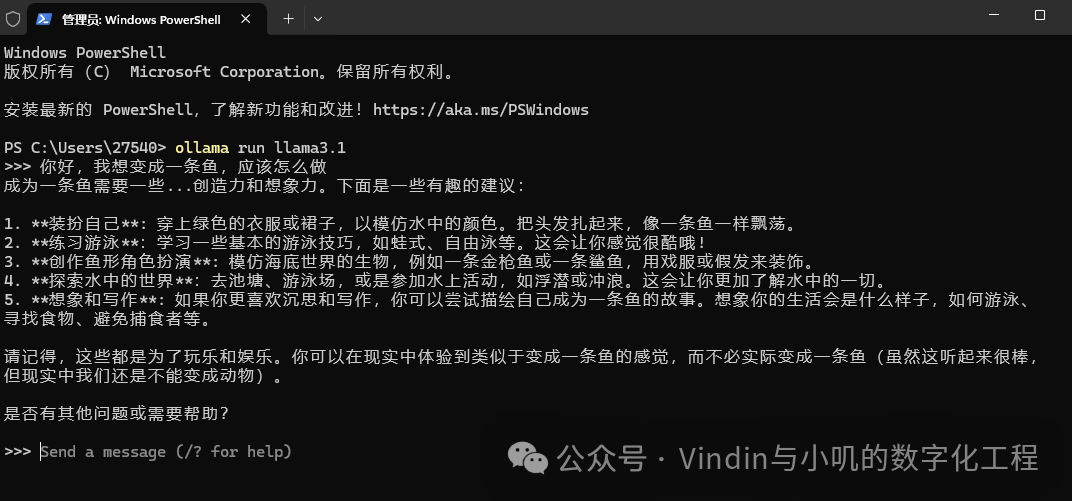
You can directly input questions here and press Enter to get answers:
4. Conclusion
Thus, Ollama has been successfully deployed on your local computer.
In the following process, we will introduce how to build a personal knowledge base centered around Ollama.
As open-source large models continue to update, users need to assess their needs based on their business scenarios and requirements.