
Follow our WeChat public account to discover the beauty of CV technology
Introduction
This paper is one of the latest articles on GANs from CVPR 2022. It is known that while GANs can generate realistic images under ideal conditions in certain fields, generating full-body human images remains challenging due to the diversity of hairstyles, clothing, and poses. Previous methods generally modeled this complex domain using a single GAN.
The authors proposed a new method that combines multiple pre-trained GANs, where one GAN generates a global human image and a set of specialized GANs generates specific body parts, seamlessly inserting the partial human images into the full-body image. A large number of experimental results in the paper also demonstrate the effectiveness of this method.

Paper link: https://arxiv.org/abs/2203.07293
Video link: https://www.youtube.com/watch?v=YKFYEt5hvOo
Overview of the Paper’s Method
In this paper, the authors proposed an unconditional generation method that uses one or more pre-trained generator networks to generate full-body images of humans. The schematic of this method is shown below, where two latent vectors are given, which are input into the pre-trained generators and generate corresponding images.
The authors used a set of losses to describe the conditions they wish to minimize during the optimization process. The images generated under different conditions are shown on the right. It can be found that directly copying and pasting the face image initially leaves rough traces, whereas the full-body images generated during the optimization process seamlessly connect the face and body parts.
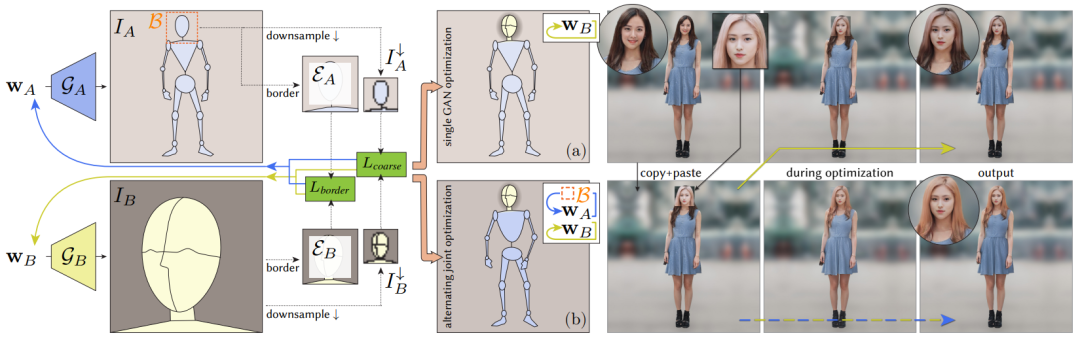
Full-Body GAN
In this paper, the authors adopted the state-of-the-art StyleGAN2 architecture. Most previous works on full-body image generation or editing were conducted at lower resolution scales, while the authors attempted unconditional generation at a resolution of 1024×1024 for the first time. Due to the complexity of the target domain, results produced by a single generator sometimes exhibit deformities in body parts and non-photorealistic appearances. Coupled with the vast diversity of human poses and appearances and the associated alignment difficulties, it becomes harder for a single generator to learn. Therefore, multiple generators need to work together to generate full-body human images.
Multi-GAN Optimization
To enhance the generation capability of Full-body GAN, the authors first used specific generators to generate images of specific body parts, and then pasted the generated results into the Full-body GAN’s output, thus better simulating the complex appearance and plasticity of the human body.
The authors demonstrated that using a Face GAN trained on cropped facial regions from full-body training images can improve the appearance of Full-body GAN results. Hence, face generators trained on other datasets can be utilized for facial enhancement. Similarly, specialized hand or foot generators can be used to improve other body areas. As shown in the figure below, the authors indicated that multiple part generators can be used simultaneously during the optimization process.

The main challenge faced by the authors in this paper is how to coordinate multiple unconditional GANs to produce consistent pixels with each other.
In this paper, a generator is used to generate full-body human images, and another generator is used to generate sub-regions of the human body. To coordinate the relationship between the part GANs and the global GAN, the authors employed a boundary detector to identify the image, cropping using the detected bounding boxes and representing the cropped pixels. The problem of inserting separately generated partial images into the full-body image is equivalent to finding a latent vector pair such that the corresponding images can be combined at the boundary areas of the images without noticeable seams.
To generate the final result, the authors directly replace the original pixels within the bounding boxes with the generated pixels, as shown in the following formula:
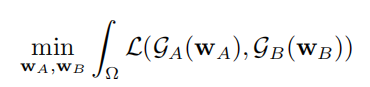
Where the main loss is used to measure the seams and stitching.
When optimizing the latent vectors, the authors considered the following multiple objectives:
-
The facial regions generated by Face GAN and Body GAN should have roughly proportionate similar appearances so that when pasting pixels generated by Face GAN onto the Body GAN image, the corresponding attributes, such as skin tone, should match between the face and neck.
-
The cropped boundary pixels should match with each other so that the limb images can seamlessly connect to the full-body human image.
-
The synthesized image results need to appear very realistic. To match the appearance of the face, the authors downsample the facial region and calculate a combined loss of perceptual and content loss, where the perceptual loss represents the downsampled image.
The image boundary matching loss is shown below:
Where the width of the boundary region is in pixels. To maintain realism during the optimization process, the authors also added two regularization terms:
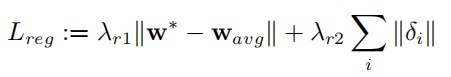
The first term prevents the optimized latent vector from straying too far from the average latent vector. The authors obtained this by randomly sampling a large number of latent vectors in the space, mapping them to the space, and calculating the average. The second term regularizes the latent vectors in the latent space.
Given a randomly generated full-body human image, the authors optimize the parameters to make the image look similar to a reference image, with the optimization objective being:
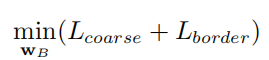


Given a real or randomly generated face image, the authors optimize the parameters to ensure that the generated body image is compatible with the input face in terms of pose, skin tone, gender, hairstyle, etc. To maintain facial identity during optimization, the authors used an additional face reconstruction loss:
where the internal region of the face crop is defined, representing the reference input face. For more precise control, face segmentation can replace the bounding box, where the authors’ objective function is:
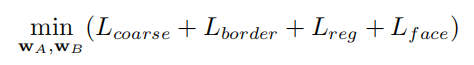

In this paper, the authors can combine any real or generated face with any generated body to create a composite. For real faces, the authors first need to encode them into the latent space using a pre-trained encoder. Similarly, a real body image can also be encoded into the latent space, but due to height differences, achieving lower reconstruction error is challenging. Therefore, the authors use the following objective function:
The figure below shows the results of combining faces generated using the pre-trained FFHQ model (top row) with bodies generated by the method in this paper (leftmost column). By slightly adjusting the latent vectors for the face and body, the authors achieve a consistent identity in the synthesized results.

Experimental Results
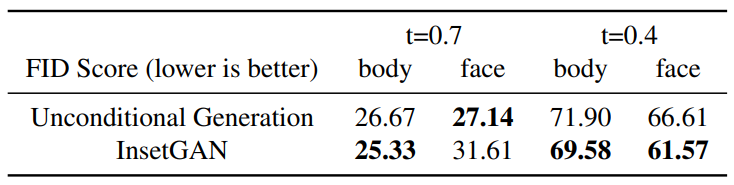
As shown in the table below, the authors used two different truncation settings and evaluated full-body images and cropped images. A smaller FID score is better. From the table below, it can be seen that the joint optimization of face refinement does not alter the distribution learned by the unconditional generator, thus not reducing the diversity of results.
The figure below shows that the method InsetGAN (top right) has better generation effects in terms of face alignment accuracy and generated detail compared to CoModGAN (bottom right).

The figure below shows the two best results obtained by using several random initializations for each input face.


END
