Reprinted from WeChat Official Account | Blue’s Little Firefly
In this article, I would like to accurately introduce the application areas of Knowledge Graphs (KG) in the RAG pipeline.
We will explore the different types of questions that arise in the RAG pipeline and how to address these issues by applying knowledge graphs at various stages throughout the pipeline. We will discuss a practical example of a RAG pipeline that is enhanced by knowledge graphs at different stages and precisely explain how each stage improves answers and queries. Another key point I hope to convey is that the deployment of graph technology is more akin to structured data storage, used strategically to inject human reasoning into the RAG system, rather than simply querying a generic storage of structured data for all purposes.
For background on complex RAG and multi-hop data retrieval, please refer to this non-technical introduction and a more technical in-depth discussion.
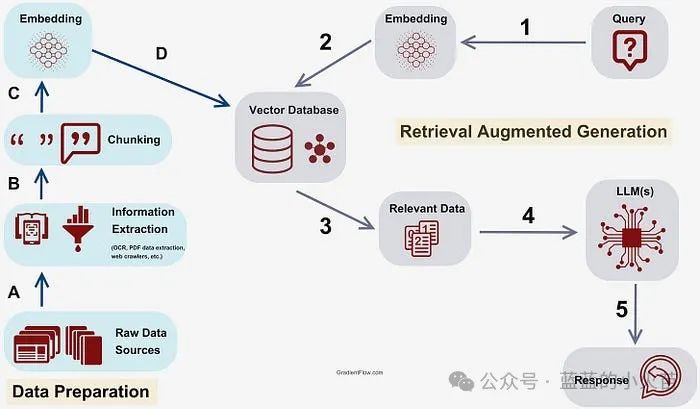
Let us introduce the terms of the different steps in the KG-enabled RAG process using the stages shown in the image above:
First Stage: Preprocessing: This refers to the processing conducted before extracting chunks from the vector database using queries.
Second Stage: Chunk Extraction: This refers to retrieving the most relevant chunks of information from the database.
Third to Fifth Stages: Postprocessing: This refers to the processes you perform to prepare the retrieved information for generating answers.
We will first showcase which technologies should be used at different stages and provide a practical example at the end of the article.
Preprocessing
In many cases, companies may have their own worldview regarding specific terms. For example, a travel tech company may want to ensure that GPT-4’s out-of-the-box law degree can understand that “beachfront” homes and “near beach” homes represent very different types of properties and cannot be used interchangeably. Injecting this context during the preprocessing stage helps ensure that this distinction in the RAG pipeline can provide accurate responses.
Historically, a common application of knowledge graphs in enterprise search systems is to help build acronyms dictionaries so that search engines can effectively identify acronyms presented in questions or documents/data storage.
As we elaborated in our previous article, this can be used for multi-hop reasoning.
Time: First Stage
Further Reading: https://www.seobythesea.com/2019/08/augmented-search-queries/
Chunk Extraction
The first knowledge graph can be a hierarchy of document descriptions referencing the chunks stored within the vector database.
The second knowledge graph can be rules for navigating the document hierarchy. For example, consider a RAG system for a venture fund. You could write a natural language rule that applies deterministically to the query planning agent: “To answer questions about investor obligations, first check what the investor has invested in the investor portfolio list, then check the legal documents of the said portfolio.”
Time: Second Stage
Further Reading:
https://docs.llamaindex.ai/en/stable/examples/query_engine/multi_doc_auto_retrieval/multi_doc_auto_retrieval.html
https://medium.com/enterprise-rag/a-first-intro-to-complex-rag-retrieval-augmented-Generation-a8624d70090f

The context dictionary is essentially a knowledge graph of metadata.
This dictionary can be used to maintain the rules for navigating chunks. You can include a natural language rule, “For any question related to the concept of happiness, you must conduct an exhaustive search of all relevant chunks according to the definitions in the context dictionary.” The LLM agent in the query planning agent will convert this into a Cypher query to increase the chunks to be extracted. Establishing such rules can also ensure consistency in chunk extraction.
How is this different from simple metadata searches? Aside from improving speed, it may not work if the document is simple. However, in some cases, you may want to ensure that specific chunks of information are marked as related to a certain concept, even if that chunk may not mention or imply that concept. This may happen when discussing orthogonal information (i.e., information that is controversial or inconsistent with a specific concept). The context dictionary can easily establish clear associations with non-obvious chunks of information.
Time: Second Stage
Further Reading: https://medium.com/data-science-at-microsoft/creating-a-metadata-graph-struct-for-in-memory-optimization-2902e1b9b254
Postprocessing
1. Recursive Knowledge Graph Queries. Reason: This is used to combine extracted information and store cohesive joint answers. LLM queries the graph for answers. This is functionally similar to a thought tree or thought chain process, where external information is stored in the knowledge graph to help determine the next step of inquiry.
You essentially run chunk extraction repeatedly, retrieve the extracted information, and store it in the knowledge graph to force connections to reveal relationships. After establishing relationships and storing information in the knowledge graph, run the query again using the full context extracted from the knowledge graph. If the context is insufficient, again save the extracted answers in the same KG to enforce more connections and rinse/repeat.
This is particularly useful if data continuously flows into your system and you want to ensure answers are updated over time according to new contexts.
Time: Third Stage
Further Reading: https://neo4j.com/developer-blog/knowledge-graphs-llms-multi-hop-question-answering/
An interesting avenue to explore may also include using answer augmentation as a way for consumer-facing RAG systems to include personalized ads in answers when certain products are mentioned.
Time: Fourth Stage
Llamaindex has an interesting example using Wikipedia’s knowledge graph to carefully check whether LLM’s answers are factual: https://medium.com/@haiyangli_38602/make-meaningful-knowledge-graph-from-opensource-rebel-model-6f9729a55527. This is an interesting example because, although Wikipedia cannot serve as a foundational source of facts for an internal RAG system, you can use objective industry or common knowledge graphs to prevent LLM hallucinations.
Time: Fifth Stage
For example, suppose a healthcare company is building a RAG system that includes access to sensitive clinical trial data. They only want privileged staff to be able to retrieve sensitive data from the vector storage. By storing these access rules as attributes of the knowledge graph data, they can instruct the RAG system to retrieve privileged chunks only when the user is allowed.
Time: Sixth Stage (see below)
1 / 4 / 6. Chunk Personalization: Reason: Knowledge graphs can be used to personalize every response to users.
For instance, consider an enterprise RAG system where you want to customize responses for each employee, team, or department in each office. When generating answers, the RAG system can consult the KG to understand which chunks contain the most relevant information based on the user’s role and location.
You need to include context as well as what that context means for each answer.
Then, you may want to include that context as prompts or answer augmentations.
This strategy can build upon chunk access control. Once the RAG system determines the most relevant data for that specific user, it can also ensure that the user indeed has access to that data.
When: This functionality can be included in stages 1, 4, or 6.
Practical Example Combining All Discussed Use Cases
Let us deconstruct this with an example from the medical field. In this article, Wisecube posed the following question: “What are the latest studies on Alzheimer’s disease treatments?” Transforming the RAG system to leverage the strategies mentioned above can adopt the following steps. Specifically, we do not believe that every RAG system necessarily needs to follow all or even any of the steps below. We believe these technologies can be useful for specific use cases and that they are relatively common in complex RAG use cases and may also apply to some simpler use cases.
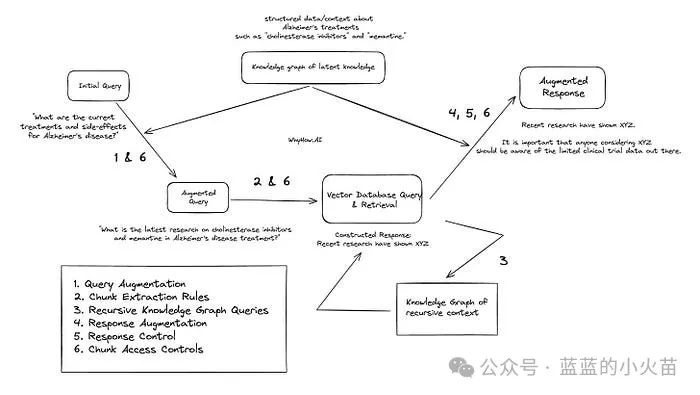
Here, I map the same initial stages from the initial image at the top of the article to this image so that the numbered stages in the RAG process are aligned, along with several additional stages. We then combine all the discussed technologies (chunk augmentation, chunk extraction rules, recursive knowledge graph queries, response augmentation, response control, chunk access control) — corresponding to stages 1 to 6.
1. Query Augmentation: For the question “What are the latest studies on Alzheimer’s disease treatments?” By accessing the knowledge graph, the law degree agent can consistently retrieve structured data regarding the latest Alzheimer’s disease treatments, such as “cholinesterase inhibitors” and “memantine.”
Then, the RAG system makes the question more specific: “What are the latest studies on cholinesterase inhibitors and memantine in Alzheimer’s disease treatment?”
The relevant chunk extraction rules regarding “cholinesterase inhibitors” help guide the query engine in extracting the most useful chunks. The document hierarchy helps the query engine quickly identify documents related to side effects and start extracting chunks from the documents.
The context dictionary helps the query engine quickly identify chunks related to “cholinesterase inhibitors” and start extracting chunks relevant to that topic. Established rules regarding “cholinesterase inhibitors” stipulate that queries about the side effects of cholinesterase inhibitors should also check chunks related to enzyme X. This is because enzyme X is a well-known side effect that should not be missed, and relevant chunks are included as well.
3. Recursive Knowledge Graph Queries: Using recursive knowledge graph queries, the initial query returns the side effects of “memantine,” termed the “XYZ effect.”
The “XYZ effect” is stored as context in a separate knowledge graph of recursive context.
The law degree agent is requested to check the enhanced query using the additional context of the XYZ effect. Based on the previously formatted answers to measure the answers, it determines that more information regarding the XYZ effect is needed to constitute a satisfactory answer. It then performs a deeper search within the XYZ effect node in the knowledge graph, executing a multi-hop query.
Within the XYZ effect node, it discovers information regarding clinical trial A and clinical trial B and includes it in the answer.
Only information regarding clinical trial A will be returned to the law degree agent to assist in formulating its returned answer.
5. Answer Augmentation: As a post-processing step, you can also choose to enhance post-processing outputs using healthcare industry-specific knowledge graphs.For example, you could include a default health warning specific to memantine treatment or any other information related to clinical trial A.
6. Chunk Personalization: Since the user is a junior employee in the stored R&D department and cannot access information regarding clinical trial B, the answer will include a note stating that they are prohibited from accessing information on clinical trial B and are advised to consult a senior manager for more information.
The advantage of using knowledge graphs for query augmentation over vector databases is that knowledge graphs can enforce consistent retrieval of certain key topics and concepts with known relationships. At WhyHow.AI, we are simplifying the creation and management of knowledge graphs in the RAG pipeline.
Interesting Idea: Monetizing Company/Industry Ontology
If everyone building complex RAG systems needs some form of knowledge graph, then the market for knowledge graphs could grow exponentially, and the number of small ontologies created and needed could also grow exponentially. If true, the market dynamics of ontology buyers and sellers would become more decentralized, and the ontology market could become interesting.
Personalization: Digital Twin
While we define personalization as controlling the flow of information between users and vector databases, personalization can also be understood as encapsulating the characteristics that identify the user.
As a knowledge graph as a digital twin can reflect a broader set of user characteristics stored, these characteristics can be used for a range of personalized work. In terms of knowledge graphs as external data storage (i.e., external to the LLM model), it is easier to extract in a coherent form (i.e., knowledge graph data can be inserted, played, and removed in a more modular way). Theoretically, additional personal context can be extracted and maintained as a personal digital twin/data storage. If in the future there exists a modular digital twin that allows users to transplant personal preferences between models, then knowledge graphs are likely to represent the best means of inter-model personalization between systems and models.
English Link: https://medium.com/enterprise-rag/injecting-knowledge-graphs-in-different-rag-stages-a3cd1221f57b
OpenKG
OpenKG (Open Knowledge Graph in Chinese) aims to promote the openness, interconnectivity, and crowdsourcing of knowledge graph data centered on the Chinese language, and to facilitate the open-source of knowledge graph algorithms, tools, and platforms.

ClickRead Original Article to visit the OpenKG website.