
 Submitted by Tang Zhengyang | Market Manager at CreditX
Submitted by Tang Zhengyang | Market Manager at CreditX
Big Data Digest looks forward to receiving various excellent submissions
Submission email: [email protected]
“In the current more inclusive market environment, the customer base and scope of new financial services have further deepened and expanded, with business forms tending to be more small, dispersed, high-efficiency, and scalable. This poses greater challenges to traditional risk control. On one hand, the coverage of high-value financial data for such customer groups has significantly decreased, and on the other hand, business experts have many doubts about how to link risk with more unstructured data. In fact, these data, which differ from traditional strong credit data, are showing an increasingly important role in new financial risk control. Practices in many mature scenarios have proven that reasonably leveraging and utilizing their value can often bring unimaginable improvements to overall risk control effectiveness.”

◆ ◆ ◆
One Hot Vector and Distributed Representation
Let me ask you a question: if there are several words in front of you, how would you like your computer to understand each word? Of course, there are many methods, here we introduce a sparse representation method – one hot vector, which is represented as follows:

This representation solves our problem, but it also has certain drawbacks, namely, each word is a dimension. If the number of words increases sharply, it will lead to dimensional disaster, making our modeling process quite difficult. At this time, you might consider another approach, using only 4 dimensions to represent basic information such as gender, elderly, adult, and infant, which can represent all words. This representation method is called distributed representation, also known as word vectors:

◆ ◆ ◆
Word Vectors
After deep learning emerged, the concept of word vectors became popular due to breakthroughs in computational bottlenecks. First, there is a common understanding that similar words have similar contexts in text, meaning that similar words have similar contexts. Therefore, we can use the context of a word, such as the frequency of co-occurrence with other words, to represent this word as a vector formed by these frequencies. Of course, if the sentence is particularly long, we can limit the window to only take the co-occurrence frequency of n words before and after the target word.
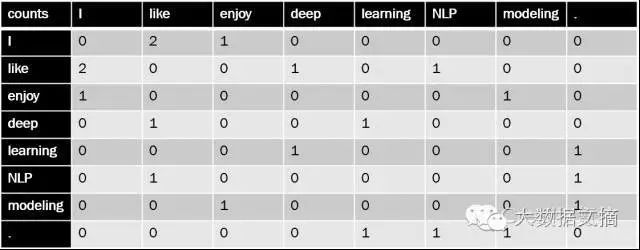
For example, given the following three sentences as a corpus:
I like deep learning.
I like NLP.
I enjoy modeling.
Taking a window length of n=1, the following figure shows that each column is the word vector of the respective word.
◆ ◆ ◆
Word2vec
Now, our main character word2vec makes its appearance. Unlike traditional co-occurrence counting, word2vec, as the current mainstream word embedding algorithm, mainly predicts the probabilities of surrounding words for each word in a window of length c, which serves as the word vector for that word. This way, words are mapped to a high-dimensional vector space, allowing us to calculate the distance between words, i.e., to calculate semantic similarity.
In word2vec, the two most important models are CBOW and Skip-gram models. The former predicts the current word based on the context of words, while the latter uses the current word to predict the context.
Let’s take CBOW as an example. CBOW stands for Continuous Bag-of-Words Model, as it uses continuous space to represent words, and the order of these words is not important. Its neural network structure is designed as follows:
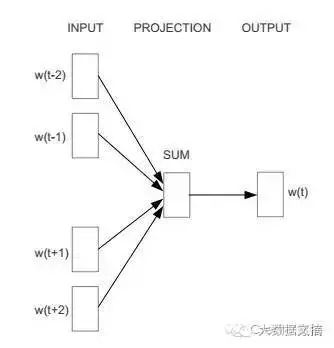
Input layer: The context of word w consists of 2c words’ vectors
Projection layer: Sum the 2c vectors from the input layer
Output layer: A Huffman tree, where the leaf nodes are the words that appeared in the corpus, and the weights are the frequencies of their occurrences
Why is the output layer of CBOW structured as a Huffman tree? Because we need to obtain the probability of each possible w based on the training corpus. How do we obtain this? Let’s first look at this example of a Huffman tree. For example, the sentence is: I, like, watching, Brazil, football, World Cup; W=football.
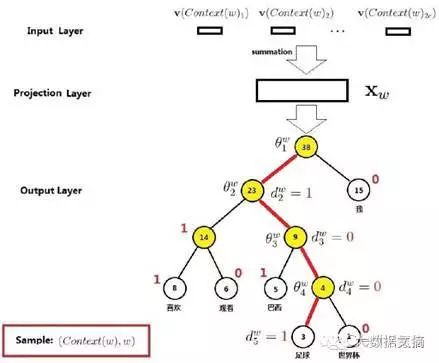
In this Huffman tree, the path taken by the word “football” is easily seen, where the θ on the non-root nodes represents the parameter vectors to be trained, aiming to achieve the following effect: when a new vector x is produced in the projection layer, I can derive the probabilities of being assigned to the left node (1) or right node (0) at each layer using the logistic regression formula (the following formula can be skipped if not of interest):
σ(xTθ) = 1/(1+e^(-xTθ))
This leads to:
p(d|x,θ) = 1-σ(xTθ)
and
p(d|x,θ) = σ(xTθ)
Thus, we have:
p(football|Context(football)) = ∏ p(d|x,θ)
Now that the model is established, we can train v(Context(w)), x, and θ using the corpus to adjust and optimize. Due to space limitations, the specific formulas will not be elaborated on here.
Similarly, for the Skip-gram model, i.e., Continuous Skip-gram Model, the reasoning process using the known current word to predict the context is quite similar to that of CBOW.
◆ ◆ ◆
Practical Effect Examples
Having discussed so much, how magical is word2vec? Using the Chinese Wikipedia as the training corpus, let me show you some intuitive examples: for instance, if we want to see the words with the highest semantic similarity to “linguistics” and their probabilities, we get the following results:
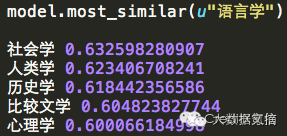
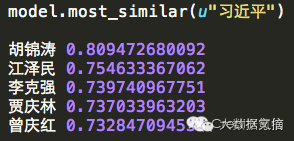
Moreover, if we want to see the words with the highest semantic similarity to Xi Jinping and their probabilities, we get the following results:
Interestingly, as shown in the following figure, X(KING) – X(QUEEN) ≈ X(MAN) – X(WOMAN), where X(w) represents the word vector of word w learned using word2vec. This means that word vectors can capture a certain implicit semantic relationship between KING and QUEEN, as well as between MAN and WOMAN.
◆ ◆ ◆
Mature Application Cases in New Financial Risk Control Scenarios
In fact, in new financial risk control scenarios, data such as text often contain deep meanings that are closely related to default risk. Traditional statistical, labeling, or even regular methods for manually defining ways often struggle to fully exploit their risk value. Currently, CreditX has collaborated with several leading financial institutions to deeply explore the mature and cutting-edge applications of word embedding algorithms in the risk control field. As shown in the figure below, by using complex word vector models to transform text into word vector representations that computers can “understand” and compute, and based on deep learning technology to extract features, we can use mature classifier networks to achieve a high degree of risk linkage between text data and default risk.
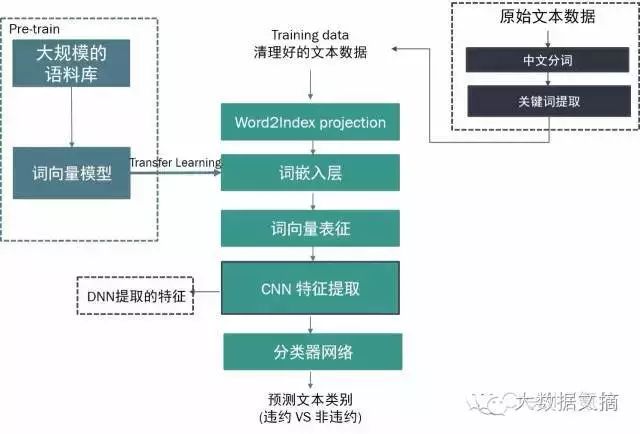
CreditX’s practice in large mature risk control scenarios has also found that for an increasing amount of unstructured data such as text, time series, and images under new financial business forms, thorough value extraction is showing an unimaginable enhancement in risk control effectiveness. Currently, CreditX continuously helps financial clients integrate, utilize, and optimize data usage through cutting-edge deep learning and complex ensemble learning technologies. The deeply customized non-accidental engine for financial risk control is also comprehensively upgrading the data processing capabilities from traditional feature engineering to human-machine feature integration, achieving rapid formation of new financial risk control business and continuous iterative optimization of risk control decision systems.
This article is copyrighted by the submitting author and represents only personal views.
—-【Advertisement】—-
This course group has exceeded400 people,
Only1 day left to register!
Scan to join and build the mathematics section of machine learning with more people

About Reprinting
If you need to reprint, please prominently indicate the author and source at the beginning of the article (reprinted from: Big Data Digest | bigdatadigest), and place the Big Data Digest QR code at the end of the article. Articles without original labels can be edited according to reprinting requirements and can be directly reprinted. After reprinting, please send us the reprint link; for articles with original labels, please send us the [article name - the authorized public account name and ID] to apply for whitelist authorization. Unauthorized reprints and adaptations will be legally pursued. Contact email: [email protected].
◆ ◆ ◆
Previous exciting articles recommended, click the image to read
Oculus Connect conference site | On Mars with my wife, Zuckerberg directly hits FB's VR ambitions


