
Source: Machine Vision Knowledge Recommender
This article is approximately 11,000 words long and is recommended for a reading time of 10+ minutes.
This article will introduce deep learning technology, neural networks, convolutional neural networks, and their applications in related fields.
In today’s internet era, the intricate big data and network environment pose significant challenges to traditional information processing theories, artificial intelligence, and artificial neural networks. In recent years, deep learning has gradually come into the public eye, with an increasing number of cases where deep learning solves various problems. Some traditional image processing techniques can also achieve superior results through deep learning, such as denoising, super-resolution, and tracking algorithms. To keep pace with the times, it is essential to learn and research deep learning and neural network technologies. This article will introduce deep learning technology, neural networks, convolutional neural networks, and their applications in related fields.
1. What is Deep Learning?
Deep learning (DL) is a new research direction in the field of machine learning (ML). Deep learning involves learning the intrinsic patterns and representational hierarchies of sample data, and the information obtained during these learning processes significantly aids in interpreting data such as text, images, and sound. Its ultimate goal is to enable machines to possess analytical learning capabilities akin to those of humans, allowing them to recognize data such as text, images, and sound. Deep learning is a complex machine learning algorithm that has achieved results far exceeding those of previous related technologies in speech and image recognition.
 Deep learning has achieved numerous results in various fields, including search technology, data mining, machine learning, image recognition and processing, machine translation, speech recognition, human-computer interaction, medical image analysis, disease diagnosis, financial risk assessment, and credit rating. Deep learning enables machines to mimic human auditory and visual activities and thought processes, solving many complex pattern recognition challenges and leading to significant advancements in artificial intelligence-related technologies.
Deep learning has achieved numerous results in various fields, including search technology, data mining, machine learning, image recognition and processing, machine translation, speech recognition, human-computer interaction, medical image analysis, disease diagnosis, financial risk assessment, and credit rating. Deep learning enables machines to mimic human auditory and visual activities and thought processes, solving many complex pattern recognition challenges and leading to significant advancements in artificial intelligence-related technologies.
2. The Concept of Deep Learning
Let’s assume we have a system S with n layers (S1,…Sn), where its input is I and output is O, represented as: I =>S1=>S2=>…..=>Sn => O. If the output O equals the input I, it means that there is no information loss after the input I goes through this system, and it remains unchanged. This implies that there is no information loss at each layer Si, meaning that at any layer Si, it is another representation of the original information (i.e., input I). We need to automatically learn features; let’s assume we have a set of inputs I (such as a set of images or text). We design a system S (with n layers) and adjust the parameters in the system so that its output still equals the input I. We can then automatically obtain a series of hierarchical features of the input I, namely S1, …, Sn.
For deep learning, the idea is to stack multiple layers, meaning that the output of one layer serves as the input to the next layer. This method allows for hierarchical representation of the input information. Additionally, the previous assumption that the output strictly equals the input is too strict; we can relax this restriction slightly, for example, we only need to make the difference between the input and output as small as possible.
3. Deep Learning and Neural Networks
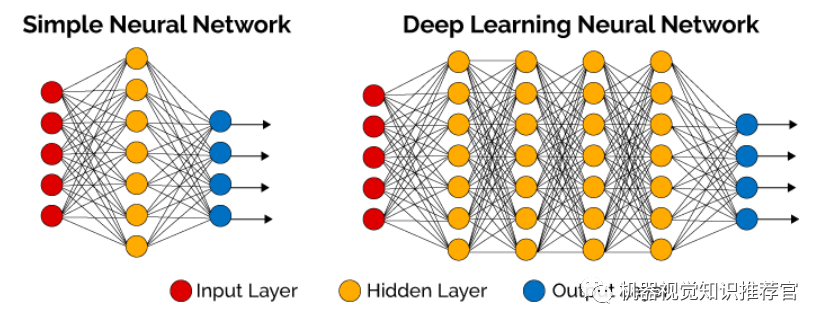
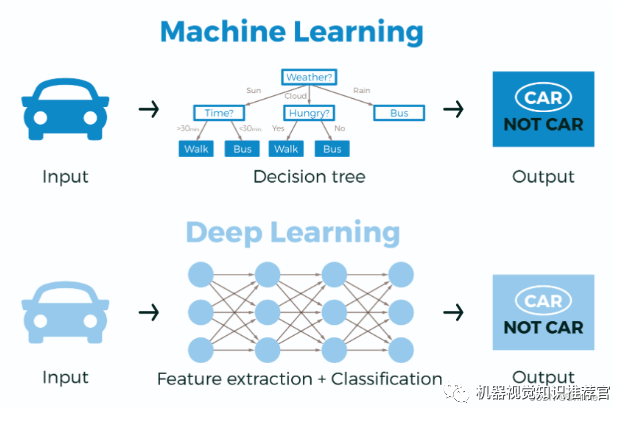
Deep learning is a new domain of research in machine learning, motivated by building and simulating neural networks that analyze and learn like the human brain. It mimics the mechanisms of the human brain to interpret data such as images, sounds, and text. Deep learning is a form of unsupervised learning. The concept of deep learning originates from the study of artificial neural networks. A multi-layer perceptron with multiple hidden layers is a structure of deep learning. Deep learning combines low-level features to form more abstract high-level representations or feature categories to discover distributed feature representations of data.
Deep learning itself is considered a branch of machine learning and can be simply understood as the evolution of neural networks. About two to three decades ago, neural networks were a particularly hot direction in the field of machine learning, but they gradually faded away due to several reasons:
1) The BP algorithm, a typical algorithm for training multi-layer networks, actually only contains a few layers, and this training method was already quite unsatisfactory. The local minima commonly found in non-convex objective cost functions involving deep structures (multiple non-linear processing unit layers) are a major source of training difficulties.
2) For a deep network (more than 7 layers), the residuals propagating to the earlier layers become too small, leading to what is known as gradient diffusion.
3) Generally, we can only use labeled data for training: however, most data is unlabeled, while the brain can learn from unlabeled data;
Deep learning shares similarities and many differences with traditional neural networks.
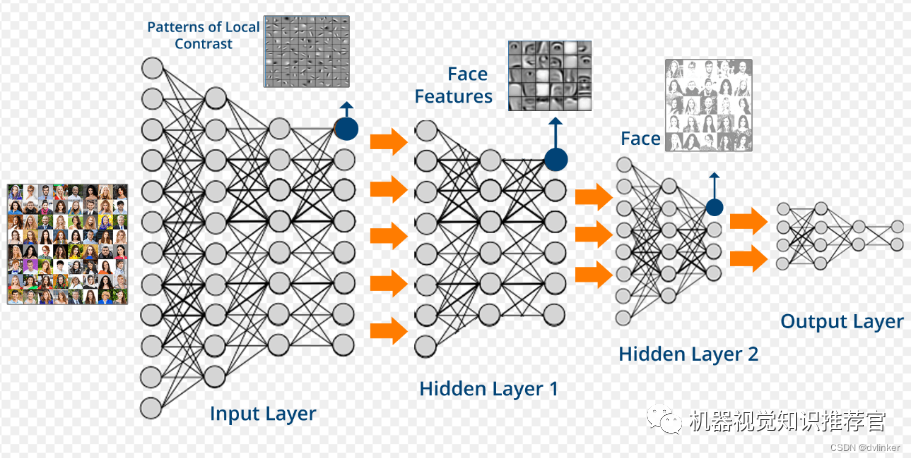
The similarities lie in that deep learning adopts a similar layered structure to neural networks, with systems composed of an input layer, hidden layers (multiple layers), and an output layer, where only adjacent layer nodes are connected, while there are no connections among nodes in the same layer or across layers. Each layer can be seen as a logistic regression model; this layered structure is quite close to the structure of the human brain.
To overcome the challenges in training neural networks, deep learning adopts a training mechanism that is quite different from that of neural networks. In 2006, Hinton proposed an effective method for building multi-layer neural networks on unsupervised data, which can be simply divided into two steps: first, train one layer of the network at a time, and second, fine-tune so that the original representation x generated into a higher-level representation r and that higher-level representation r generates x’ as consistently as possible, using the method:
2) Once all layers are trained, Hinton uses the wake-sleep algorithm for fine-tuning.
This changes the weights between all layers except the top layer to be bidirectional, so the top layer remains a single-layer neural network, while the other layers become graphical models. The upward weights are used for “cognition,” and the downward weights are used for “generation.” Then, the Wake-Sleep algorithm adjusts all weights. This ensures that cognition and generation align, meaning that the generated top-layer representation can accurately restore the lower-layer nodes as much as possible. For example, if a node in the top layer represents a face, then all images of faces should activate this node, and the image generated from this result should represent a rough image of a face. The Wake-Sleep algorithm consists of two parts: wake and sleep:
2) Sleep Phase: The generative process generates the lower layer’s states through the top-layer representation (concepts learned while awake) and downward weights, while modifying the upward weights between layers. This means, “If the scene in my dream does not correspond to the concept in my mind, adjust my cognitive weights to make that scene appear as that concept in my view.”
4. The Training Process of Deep Learning
The training process of deep learning consists of the following two steps.
4.1. First, Use Bottom-Up Unsupervised Learning (Training from the Bottom Layer Up)
Using unlabeled data (labeled data can also be used), the parameters of each layer are trained hierarchically. This step can be viewed as an unsupervised training process, which is the most significant difference from traditional neural networks (this process can be seen as a feature learning process). Specifically, the first layer is trained using unlabeled data, during which the parameters of the first layer are learned (this layer can be seen as obtaining a hidden layer of a three-layer neural network that minimizes the difference between output and input). Due to model capacity limitations and sparsity constraints, the obtained model can learn the structure of the data itself, thus obtaining features with greater representational capabilities than the input; after learning the n-1 layer, the output of the n-1 layer is used as the input for the n layer, thereby obtaining the parameters of each layer.
4.2. Then, Top-Down Supervised Learning (Training with Labeled Data, Backpropagating Errors from Top to Bottom for Fine-Tuning)
Based on the parameters obtained in the first step, further fine-tune the parameters of the entire multi-layer model, which is a supervised training process. The first step is similar to the random initialization process of neural networks; however, since the first step of DL is not random initialization but rather is obtained by learning the structure of the input data, this initial value is closer to the global optimum, leading to better results. Thus, the effectiveness of deep learning is largely attributed to the first step of the feature learning process.
5. Convolutional Neural Networks
Convolutional neural networks are a type of artificial neural network and have become a research hotspot in the fields of speech analysis and image recognition. Its weight-sharing network structure makes it more similar to biological neural networks, reducing the complexity of the network model and the number of weights. This advantage is more pronounced when the input to the network is multi-dimensional images, allowing images to be directly input into the network, avoiding the complex feature extraction and data reconstruction processes in traditional recognition algorithms. Convolutional networks are a multi-layer perceptron specifically designed for recognizing two-dimensional shapes, and this network structure exhibits high invariance to translation, scaling, skew, or other forms of deformation.
CNNs are influenced by early time-delay neural networks (TDNNs). Time-delay neural networks reduce learning complexity by sharing weights across the time dimension, making them suitable for processing speech and time-series signals.
CNNs are the first truly successful learning algorithm to train multi-layer network structures. It reduces the number of parameters to be learned by utilizing spatial relationships, thereby improving the training performance of the general forward BP algorithm. CNNs were proposed as a deep learning architecture to minimize the preprocessing requirements of data. In CNNs, a small part of the image (local receptive field) serves as the input to the lowest layer of the hierarchy, and information is subsequently transmitted to different layers, with each layer using a numerical filter to obtain the most significant features of the observed data. This method can capture significant features of the observed data that are invariant to translation, scaling, and rotation, as the local receptive field of the image allows neurons or processing units to access the most basic features, such as oriented edges or corners.
5.1. The History of Convolutional Neural Networks
In 1962, Hubel and Wiesel proposed the concept of the receptive field through their research on the visual cortex cells of cats. In 1984, Japanese scholar Fukushima introduced the neural cognitive machine based on the concept of receptive fields, which can be seen as the first implementation of convolutional neural networks and the first application of the receptive field concept in the field of artificial neural networks. The neural cognitive machine decomposes a visual pattern into many sub-patterns (features), which then enter a hierarchically connected feature plane for processing, attempting to model the visual system so that it can recognize objects even when they are displaced or slightly deformed.
Typically, the neural cognitive machine contains two types of neurons: S-units for feature extraction and C-units for deformation resistance. The S-units involve two important parameters: receptive field and threshold parameters, where the former determines the number of input connections and the latter controls the response degree to the feature sub-patterns. Many scholars have been dedicated to improving the performance of the neural cognitive machine: in traditional neural cognitive machines, the amount of visual blur caused by the C-units in the photoreceptive area of each S-unit follows a normal distribution. If the blur effect produced by the edges of the photoreceptive area is greater than that from the center, the S-unit will accept a greater deformation tolerance caused by this non-normal blur. We hope to achieve a greater difference between the effects produced by the training pattern and the deformation stimulus pattern at the edges and center of the receptive field. To effectively form this non-normal blur, Fukushima proposed an improved neural cognitive machine with a double C-unit layer.
Van Ooyen and Niehuis introduced a new parameter to enhance the discriminative ability of the neural cognitive machine. In fact, this parameter acts as an inhibitory signal that suppresses the stimulation of neurons to repetitive excitation features. Most neural networks memorize training information in their weights. According to Hebb’s learning rule, the more frequently a feature is trained, the easier it is to detect in subsequent recognition processes. Some researchers have also combined evolutionary computation theories with the neural cognitive machine, weakening the training of repetitive excitation features to focus the network’s attention on different features, thus enhancing its discriminative ability. The above describes the development process of the neural cognitive machine, while convolutional neural networks can be seen as an extended form of the neural cognitive machine, with the neural cognitive machine being a special case of convolutional neural networks.
5.2. The Network Structure of Convolutional Neural Networks
Convolutional neural networks are multi-layer neural networks, with each layer consisting of multiple two-dimensional planes, and each plane composed of multiple independent neurons.
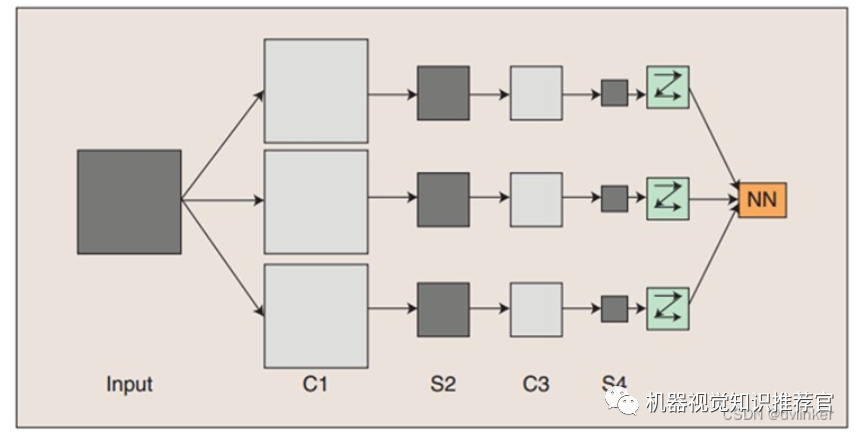
The conceptual demonstration of convolutional neural networks is shown in the above image, where the input image undergoes convolution with three trainable filters and an additive bias. The filtering process is illustrated in the first image, resulting in three feature maps at the C1 layer. Then, the four pixels in each group of the feature maps are summed, weighted, and added to a bias, passing through a Sigmoid function to obtain the feature maps at the S2 layer. These maps are then filtered to produce the C3 layer. This hierarchical structure generates S4, similar to S2. Finally, these pixel values are rasterized and connected into a vector input to the traditional neural network for output.
Generally, the C layers are feature extraction layers, where each neuron’s input is connected to the local receptive field of the previous layer, extracting the features of that locality. Once that local feature is extracted, its positional relationship with other features is also established. The S layers are feature mapping layers, where each computational layer of the network consists of multiple feature maps, with each feature map represented as a plane where all neurons have equal weights. The feature mapping structure employs the sigmoid function with a small influence function kernel as the activation function of the convolutional network, giving the feature mapping translational invariance.
Additionally, since neurons on a mapping surface share weights, the number of free parameters in the network is reduced, simplifying the complexity of parameter selection in the network. Each feature extraction layer (C-layer) in the convolutional network is followed by a computational layer (S-layer) for local averaging and secondary extraction, and this unique two-stage feature extraction structure grants the network a high tolerance for distortion when recognizing input samples.
5.3. Parameter Reduction and Weight Sharing
As mentioned earlier, one of the remarkable aspects of CNNs is that they reduce the number of parameters that need to be trained in the neural network through receptive fields and weight sharing. So what does this entail?
In the left diagram below: if we have a 1000×1000 pixel image with 1 million hidden layer neurons, if they are fully connected (each hidden layer neuron connects to every pixel of the image), there would be 1000x1000x1000000=10^12 connections, which amounts to 10^12 weight parameters. However, the spatial relationships of images are local; just as humans use a local receptive field to perceive external images, each neuron does not need to sense the entire image. Each neuron only senses a local area of the image, and then in higher layers, the information from these different local neurons can be aggregated to obtain global information. This way, we can reduce the number of connections, thus reducing the number of weight parameters that the neural network needs to train. In the right diagram: if the local receptive field is 10×10, then each hidden layer neuron only needs to connect to this 10×10 local image, resulting in 1 million hidden layer neurons having only 100 million connections, i.e., 10^8 parameters. This reduces the original number by four zeros (in magnitude), making training less labor-intensive, but it still seems like a lot. Is there any other way?
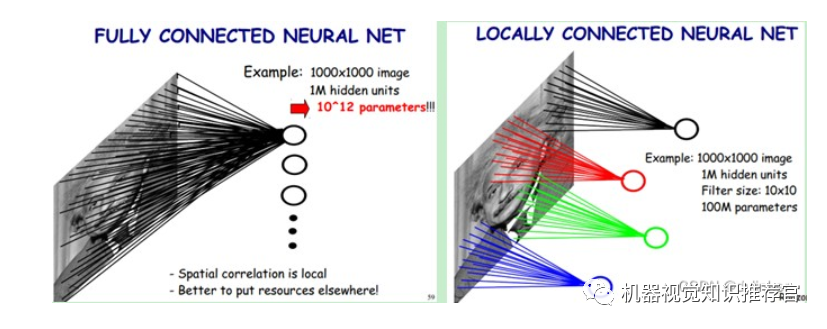
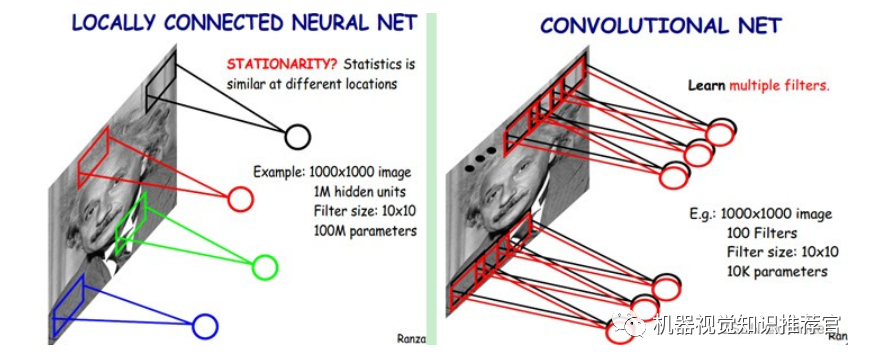
We know that each neuron in the hidden layer connects to 10×10 image regions, meaning each neuron has 10×10=100 connection weight parameters. What if we use the same 100 parameters for each neuron? This means each neuron uses the same convolution kernel to convolve the image. So how many parameters do we have then? Only 100 parameters! Regardless of how many neurons are in the hidden layer, there are only 100 parameters for the connections between the two layers! This is weight sharing.
If a filter, meaning a convolution kernel, represents a feature of the image, such as an edge in a certain direction, how do we extract different features? By adding more filters, of course! So, if we assume we add 100 types of filters, each with different parameters representing different features of the input image, such as different edges, then convolving the image with these filters yields different feature representations, which we call Feature Maps. Thus, 100 types of convolution kernels yield 100 Feature Maps. These 100 Feature Maps constitute a layer of neurons. How many parameters do we have for this layer? 100 types of convolution kernels x each convolution kernel sharing 100 parameters = 100×100 = 10K, which means 10,000 parameters. The different colors in the following diagram represent different filters.
As previously stated, the number of parameters in the hidden layer is independent of the number of neurons in the hidden layer and only depends on the size of the filter and how many types of filters there are! So how is the number of neurons in the hidden layer determined? It is related to the size of the original image (the number of neurons), the size of the filter, and the sliding step of the filter in the image! For example, if my image is 1000×1000 pixels, and the filter size is 10×10, assuming there is no overlap of filters, meaning a step size of 10, then the number of neurons in the hidden layer would be (1000×1000)/(10×10)=100×100 neurons. Note that this is only for one filter, i.e., the number of neurons for one Feature Map; if there are 100 Feature Maps, it would be 100 times that. Thus, as the image size increases, the disparity between the number of neurons and the number of weight parameters that need to be trained grows.
It is important to note that the above discussion did not consider the bias part of each neuron. Therefore, the number of weights needs to be increased by 1. This also applies to the same type of filter that is shared.
In summary, the core idea of convolutional networks is to combine local receptive fields, weight sharing (or weight replication), and temporal or spatial subsampling to achieve a certain degree of invariance to translation, scale, and deformation.
5.4. A Typical Example for Illustration
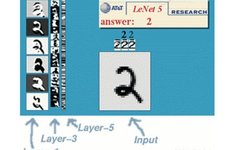
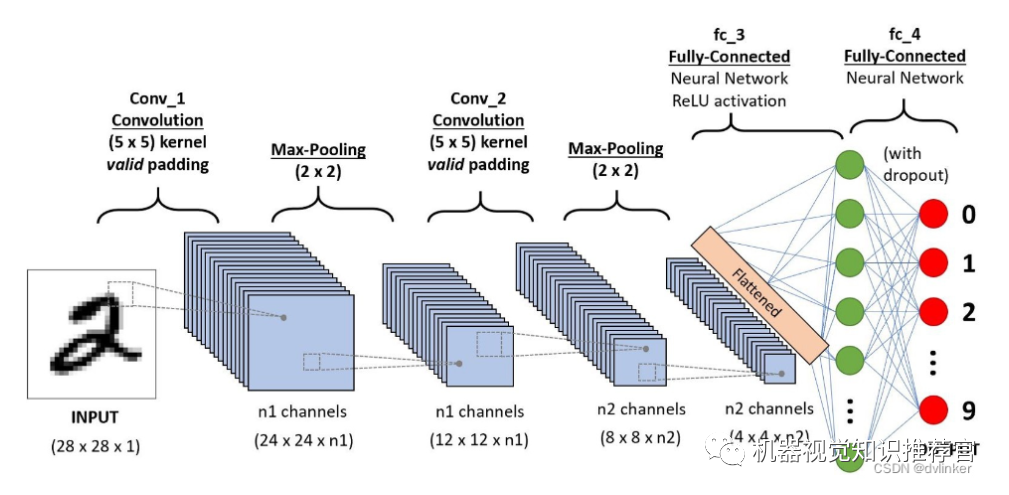
A typical convolutional network used for digit recognition is LeNet-5. Many banks in the United States have used it to recognize handwritten digits on checks. Given its commercial viability, its accuracy is certainly noteworthy. After all, the integration of academia and industry is the most debated topic.
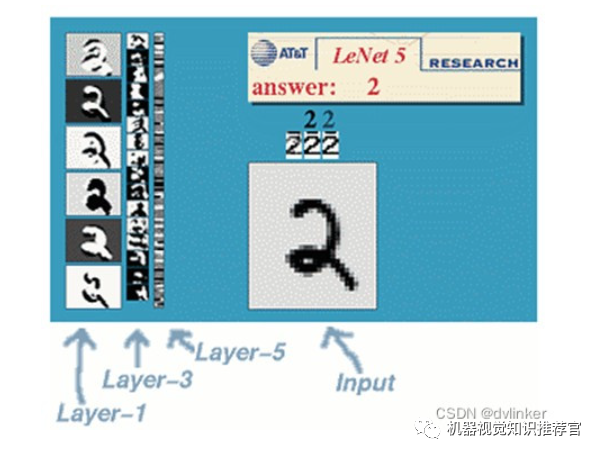
Now, let’s use this example for explanation.

LeNet-5 consists of 7 layers, excluding the input, with each layer containing trainable parameters (connection weights). The input image is 32*32 in size. This is larger than the largest characters in the MNIST database (a recognized handwritten database). The reason for this is to ensure that potential obvious features, such as stroke breaks or corners, can appear at the center of the highest layer feature monitoring sub-receptive field.
We first need to clarify: each layer has multiple Feature Maps, with each Feature Map extracting a feature of the input through a convolution filter, and each Feature Map has multiple neurons.
The C1 layer is a convolution layer (why convolution? One important characteristic of convolution operations is that they enhance the original signal features while reducing noise), consisting of 6 feature maps. Each neuron in the feature map is connected to a 5*5 neighborhood in the input. The feature map size is 28*28, which prevents the input connections from falling beyond the boundary (to avoid gradient loss during BP feedback, personal insight). C1 has 156 trainable parameters (each filter has 5*5=25 unit parameters and one bias parameter, totaling 6 filters, leading to (5*5+1)*6=156 parameters), with a total of 156*(28*28)=122,304 connections.
The S2 layer is a downsampling layer (why downsampling? Utilizing the principle of local correlation in images to subsample reduces processing volume while retaining useful information), consisting of 6 feature maps of size 14*14. Each unit in the feature map is connected to a corresponding 2*2 neighborhood in C1. Each unit in the S2 layer sums its 4 inputs, multiplies by a trainable parameter, adds a trainable bias, and the result is passed through a sigmoid function. The trainable coefficients and biases control the degree of non-linearity of the sigmoid function. If the coefficients are small, the operation approximates a linear operation, and the subsampling is equivalent to blurring the image. If the coefficients are large, depending on the bias, the subsampling can be viewed as a noisy “or” operation or a noisy “and” operation. Each unit’s 2*2 receptive field does not overlap, so the feature map size in S2 is 1/4 of that in C1 (1/2 in both rows and columns). The S2 layer has 12 trainable parameters and 5880 connections.
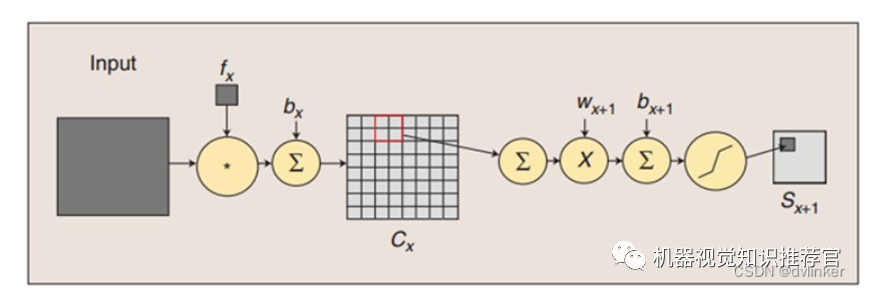
The convolution and subsampling processes are illustrated above, where the convolution process involves using a trainable filter fx to convolve an input image (the first stage is the input image, and the subsequent stages are the convolution feature maps), then adding a bias bx to obtain the convolution layer Cx. The subsampling process involves summing four neighboring pixels into one pixel, then weighting it with a scalar Wx+1, adding a bias bx+1, and passing it through a sigmoid activation function to produce a feature map Sx+1 that is roughly four times smaller.
Thus, the mapping from one plane to the next can be seen as performing convolution operations, while the S-layer can be regarded as a blurring filter, serving the role of secondary feature extraction. The spatial resolution decreases between hidden layers, while the number of planes contained in each layer increases, allowing for the detection of more feature information.
The C3 layer is also a convolution layer, which similarly convolves the S2 layer using a 5×5 convolution kernel, resulting in feature maps with only 10×10 neurons, but it has 16 different convolution kernels, thus resulting in 16 feature maps. It is important to note that each feature map in C3 is connected to all or several feature maps in S2, indicating that this layer’s feature maps are different combinations of the feature maps extracted from the previous layer.
As mentioned earlier, each feature map in C3 is composed of combinations of all or several feature maps from S2. Why not connect each feature map in S2 to each feature map in C3? There are two reasons: first, the incomplete connection mechanism keeps the number of connections within a reasonable range. Second, and more importantly, it disrupts the symmetry of the network. Since different feature maps have different inputs, they are forced to extract different features.
For example, one way to do this is for the first 6 feature maps in C3 to use subsets of 3 adjacent feature maps from S2 as input. The next 6 feature maps use subsets of 4 adjacent feature maps from S2. The subsequent 3 feature maps use subsets of 4 non-adjacent feature maps from S2. The final one uses all feature maps from S2 as input. This results in C3 having 1516 trainable parameters and 151600 connections.
The S4 layer is a downsampling layer consisting of 16 feature maps of size 5*5. Each unit in the feature map is connected to the corresponding 2*2 neighborhood in C3, similar to the connections between C1 and S2. The S4 layer has 32 trainable parameters (one factor and one bias per feature map) and 2000 connections.
The C5 layer is a convolution layer with 120 feature maps. Each unit is connected to the 5*5 neighborhood of all 16 units in the S4 layer. Since the feature map size of the S4 layer is also 5*5 (same as the filter), the size of the C5 feature maps is 1*1: this constitutes a full connection between S4 and C5. The reason for still labeling C5 as a convolution layer rather than a fully connected layer is that if the input to LeNet-5 increases in size while keeping everything else constant, the dimensions of the feature maps would become larger than 1*1. The C5 layer has 48120 trainable connections.
The F6 layer has 84 units (the choice of this number comes from the design of the output layer), fully connected to the C5 layer. It has 10164 trainable parameters. Like classic neural networks, the F6 layer computes the dot product between the input vector and the weight vector, then adds a bias. The result is passed to the sigmoid function to produce a state for unit i.
Finally, the output layer consists of Euclidean radial basis function (RBF) units, with one unit per class, each having 84 inputs. In other words, each output RBF unit calculates the Euclidean distance between the input vector and the parameter vector. The farther the input is from the parameter vector, the greater the output of the RBF. An RBF output can be understood as a penalty term measuring the degree of match between the input pattern and the model associated with the RBF for that class. In probabilistic terms, the RBF output can be viewed as the negative log-likelihood of the Gaussian distribution of the F6 configuration space. Given an input pattern, the loss function should ensure that the F6 configuration is sufficiently close to the RBF parameter vector (i.e., the expected classification of the pattern). The parameters of these units are manually selected and kept fixed (at least initially). The components of these parameter vectors are set to -1 or 1. Although these parameters can be randomly selected with probabilities of -1 and 1, or form an error-correcting code, they are designed to format an image of size 7*12 (i.e., 84) associated with the corresponding character class. This representation is not very useful for recognizing individual digits but is quite effective for recognizing strings in the printable ASCII set.
The choice of this distributed encoding instead of the more commonly used “1 of N” encoding for generating outputs is due to the poor performance of non-distributed encoding when the number of classes is large. This is because most of the time, the output of non-distributed encoding must be 0. This makes it difficult to achieve with sigmoid units. Another reason is that the classifier is not only used for recognizing letters but also for rejecting non-letters. The distributed encoding RBF is more suitable for this goal, as opposed to sigmoid units, which excite well within the well-constrained areas of the input space, while atypical patterns are more likely to fall outside.
The RBF parameter vector plays the role of the target vector for the F6 layer. It should be noted that the components of these vectors are +1 or -1, which is precisely within the range of the sigmoid function, thus preventing the saturation of the sigmoid function. In fact, +1 and -1 are the points where the sigmoid function has maximum curvature. This ensures that F6 units operate within the maximum nonlinear range. Saturation of the sigmoid function must be avoided, as it leads to slow convergence of the loss function and pathological issues.
5.5. The Training Process
Neural networks used for pattern recognition primarily involve supervised learning networks, while unsupervised learning networks are more often used for clustering analysis. For supervised pattern recognition, since the category of any sample is known, the distribution of samples in space is no longer divided based on their natural distribution tendencies, but rather seeks a suitable spatial partitioning method based on the distribution of similar samples in space and the degree of separation between different classes of samples, or finds a classification boundary that places different classes of samples in different regions. This requires a long and complex learning process, continuously adjusting the positions of the classification boundaries used to partition the sample space, so that as few samples as possible are classified into non-similar regions.
Convolutional networks are essentially a mapping from input to output, capable of learning the mapping relationships between a large number of inputs and outputs without requiring any precise mathematical expressions between inputs and outputs. As long as the convolutional network is trained with known patterns, it possesses the ability to map between input and output pairs. The convolutional network operates under supervised training, so its sample set consists of vector pairs of the form: (input vector, ideal output vector). All these vector pairs should originate from the actual “operating” results of the system that the network is about to simulate. They can be collected from the actual operating system. Before training begins, all weights should be initialized with some different small random numbers. The “small random numbers” are used to ensure that the network does not enter a saturated state due to excessively large weights, which would lead to training failure; “different” ensures that the network can learn normally. In fact, if the same number is used to initialize the weight matrix, the network will have no ability to learn.
The training algorithm is similar to the traditional BP algorithm, mainly comprising four steps divided into two phases:
The first phase, the forward propagation phase:
a) Take a sample (X,Yp) from the sample set and input X into the network;
b) Calculate the corresponding actual output Op.
In this phase, information is transmitted from the input layer through successive transformations to the output layer. This process is also executed when the network operates normally after training. During this process, the network performs calculations (essentially, it involves multiplying the input with the weight matrices of each layer to obtain the final output result):
Op=Fn(…(F2(F1(XpW(1))W(2))…W(n))
The second phase, the backward propagation phase:
a) Calculate the difference between the actual output Op and the corresponding ideal output Yp;
b) Adjust the weight matrix in reverse according to the method of minimizing error.
5.6. Advantages of Convolutional Neural Networks
Convolutional neural networks (CNNs) are primarily used to recognize two-dimensional patterns that are invariant to translation, scaling, and other forms of distortion. Since the feature detection layers of CNNs learn from training data, they avoid explicit feature extraction, instead learning implicitly from the training data. Furthermore, since the weights of neurons on the same feature mapping surface are identical, the network can learn in parallel, which is a significant advantage of convolutional networks compared to networks where neurons are interconnected. Convolutional neural networks have unique advantages in speech recognition and image processing due to their special structure of local weight sharing, and their layout is closer to actual biological neural networks. Weight sharing reduces the complexity of the network, especially since multi-dimensional input vectors (images) can be directly input into the network, avoiding the complexity of data reconstruction during feature extraction and classification.
Most classification methods are based on statistical features, meaning that certain features must be extracted before discrimination. However, explicit feature extraction is not easy and may not always be reliable in some application problems. Convolutional neural networks avoid explicit feature sampling, learning implicitly from training data. This makes convolutional neural networks distinctly different from other neural network-based classifiers, integrating feature extraction functions into multi-layer perceptrons through structural reorganization and reduced weights. They can directly process grayscale images and are capable of directly handling image-based classification.
Compared to general neural networks, convolutional networks have the following advantages in image processing: a) The input image and the topology of the network match well; b) Feature extraction and pattern classification occur simultaneously and are generated during training; c) Weight sharing can reduce the training parameters of the network, simplifying the neural network structure and enhancing adaptability.
6. Applications of Deep Learning
Deep learning is one of the important fields of artificial intelligence, with a wide range of applications, including but not limited to the following areas:
1) Image Recognition and Processing: Deep learning has many applications in image recognition, object detection, image segmentation, and facial recognition. Among them, deep learning models can identify objects, scenes, and faces in images through learning from large amounts of data, such as facial recognition technology, autonomous driving technology, and security monitoring.
2) Natural Language Processing: Deep learning has many applications in natural language processing, such as speech recognition, machine translation, text classification, and sentiment analysis. Through deep learning technology, models can automatically understand the meaning and semantics of natural language based on the input natural language information, with great application potential.
3) Human-Computer Interaction: Deep learning has many applications in human-computer interaction, such as intelligent customer service, smart question answering, and virtual characters. Through deep learning technology, models can intelligently judge and respond based on user inputs, significantly helping people improve work and life efficiency.
4) Medical Health: Deep learning has many applications in medical health, such as medical image analysis, disease diagnosis, and drug development. By using deep learning technology, it is possible to quickly diagnose diseases, assist doctors in assessing conditions, and discover new drugs.
5) Finance: Deep learning has many applications in finance, such as risk assessment, credit rating, and fraud detection. By using deep learning technology, it is possible to better identify and analyze changes and trends in the financial market, enhancing financial risk control capabilities.
7. Achievements of Deep Learning Applications
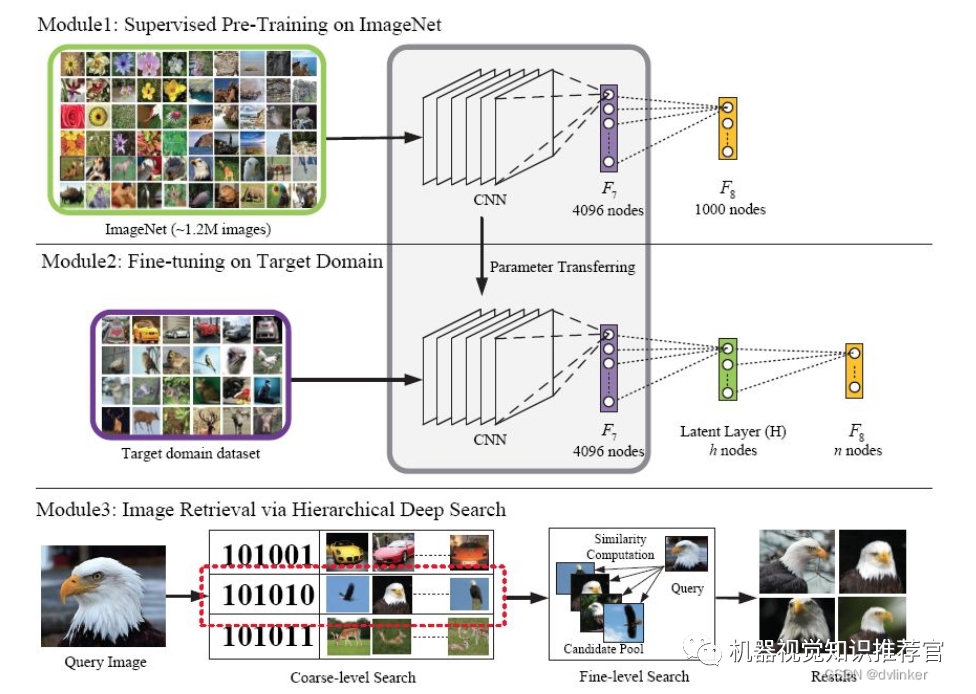
Deep learning has been widely applied in fields such as search, data mining, computer vision, machine learning, machine translation, natural language processing, multimedia learning, speech, and personalized recommendations, achieving numerous application results.
7.1. In the Field of Computer Vision
The Multimedia Laboratory of the Chinese University of Hong Kong is one of the earliest Chinese teams to apply deep learning in computer vision research. In the world-class artificial intelligence competition LFW (Large-Scale Face Recognition Competition), this laboratory outperformed Facebook to win the championship, marking the first time that artificial intelligence surpassed human capabilities in this field.
7.2. In the Field of Speech Recognition
Microsoft researchers, in collaboration with Hinton, were the first to introduce RBM and DBN into the training of speech recognition acoustic models, achieving significant success in large vocabulary speech recognition systems, reducing the error rate of speech recognition by approximately 30%. However, DNN still lacks effective parallel fast algorithms, and many research institutions are enhancing the training efficiency of DNN acoustic models using large-scale data corpora through GPU platforms.
Internationally, companies like IBM and Google have rapidly conducted research on DNN speech recognition, making swift progress.
Domestically, companies and research institutions such as Alibaba, iFlytek, Baidu, and the Institute of Automation of the Chinese Academy of Sciences are also conducting research on deep learning in speech recognition.
7.3. In Natural Language Processing and Other Fields
Many institutions are conducting research in this area. In 2013, Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean published a paper titled Efficient Estimation of Word Representations in Vector Space, establishing the word2vector model. Compared to the traditional bag-of-words model, word2vector can better express grammatical information. Deep learning is mainly applied in natural language processing for machine translation and semantic mining.
In 2020, deep learning can accelerate innovation in semiconductor packaging and testing. By reducing repetitive manual tasks, improving yield, controlling precision and efficiency, and lowering inspection costs, AI deep learning-driven AOI has a broad market prospect, although it is not straightforward to master.
On April 13, 2020, a study on medicine and artificial intelligence published in the journal Nature Machine Intelligence introduced an AI system that can scan cardiovascular blood flow in seconds. This deep learning model is expected to allow clinical physicians to observe blood flow changes in real-time while patients undergo MRI scans, thus optimizing diagnostic workflows.
8. Summary of Deep Learning
Deep learning algorithms automatically extract the low-level or high-level features needed for classification. High-level features refer to those that can hierarchically depend on other features. For instance, in machine vision, deep learning algorithms learn from raw images to obtain a low-level representation, such as edge detectors or wavelet filters, and then build expressions based on these low-level representations, either through linear or non-linear combinations, repeating this process until a high-level expression is achieved.
Deep learning can achieve better representation of data features, and due to the model’s layers and numerous parameters, it has sufficient capacity to represent large-scale data. Therefore, for problems where features are not obvious (requiring manual design and often lacking intuitive physical meanings), deep learning can achieve better results on large-scale training data. Additionally, from the perspective of pattern recognition features and classifiers, the deep learning framework combines features and classifiers into a single framework, allowing data to learn features, thus reducing the enormous workload of manually designing features (which is currently the most effort-intensive aspect for engineers in the industry). Therefore, not only can the results be better, but it is also much more convenient to use, making it a framework worthy of attention, and everyone involved in ML should pay attention to it.
Of course, deep learning itself is not perfect and is not a panacea for all ML problems; it should not be exaggerated to an omnipotent degree.
9. The Future of Deep Learning
Deep learning still has a lot of work to research. Current focus points include borrowing methods from the field of machine learning that can be used in deep learning, particularly in dimensionality reduction. For example, one ongoing effort is sparse coding, which uses compressed sensing theory to reduce the dimensionality of high-dimensional data, allowing very few elements of a vector to accurately represent the original high-dimensional signal. Another example is semi-supervised popular learning, which projects the similarity of training samples into low-dimensional space by measuring it. Another promising direction is evolutionary programming approaches, which can achieve conceptual adaptive learning and change core architectures by minimizing engineering energy.
Deep learning has already achieved significant success in many fields, such as image recognition, natural language processing, and artificial intelligence. In the future, deep learning will continue to drive the development of artificial intelligence technology, bringing more convenience and innovation to humanity. Below are several trends for the future of deep learning:
1) Self-Learning and Self-Optimization: As the complexity of deep learning models increases, how to enable models to learn and optimize themselves better will become an important research area. Future deep learning models will be able to self-learn and adjust based on data, thereby improving accuracy and efficiency.
2) Integration of Deep Learning with Sensor Technology: With the development of the Internet of Things and sensor technology, deep learning will integrate with sensor technology to realize more intelligent applications. For example, deep learning can be used to address issues such as traffic congestion, autonomous driving, and environmental monitoring.
3) Applications of Deep Learning in the Medical Field: Deep learning will become one of the important technologies in the medical field. Future deep learning models will be able to analyze and diagnose medical images, electronic medical records, and physiological data, helping doctors diagnose and treat diseases more quickly.
4) Integration of Deep Learning with Natural Language Processing: Deep learning will combine with natural language processing technology to achieve more efficient natural language processing and intelligent dialogue. Future deep learning models will be able to better understand language context and semantics, enabling more human-like interactions.
In summary, as deep learning technology continues to develop and advance, we can expect it to bring more innovation and change across various fields.
Copyright Statement: This article is an original work by CSDN blogger “dvlinker,” following the CC 4.0 BY-SA copyright agreement. Please include the original source link and this statement when reprinting.
Original link: https://blog.csdn.net/chenlycly/article/details/134043297
Editor: Huang Jiyan
