
In the previous article:
Implementing the Classic CNN VGGNet (Theoretical Part)
We detailed the network structure of VGGNet. Today, we will use PyTorch to reproduce the VGGNet network and apply the VGGNet model to solve a classic Kaggle image recognition competition problem.
Let’s get started!
1. Dataset Preparation
In the paper, the authors of AlexNet used the ILSVRC 2012 competition dataset, which is very large (138G). Downloading and training with it is time-consuming, so we will not use this dataset for reproduction. Since the images in datasets like MNIST, CIFAR10, and CIFAR100 are too small and do not meet the input size requirement of 227×227 for AlexNet, we will instead use the classic “Dogs vs. Cats” dataset from Kaggle.
This dataset contains a total of 25,000 training images, with 12,500 cats and 12,500 dogs, all labeled; the test set contains 12,500 images without labels. We will only use the 25,000 labeled images and take 2,500 images of cats and dogs each as the validation set. We will organize the dataset images according to the following directory structure.
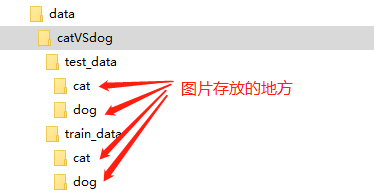
To facilitate training, we have placed the dataset on Baidu Cloud Drive, download link:
Link: https://pan.baidu.com/s/1UEOzxWWMLCUoLTxdWUkB4A
Extraction code: cdue
1.1 Creating Image Data Index
After preparing the dataset, we need to use PyTorch to read and create indices for training and testing datasets. For the training and testing sets, we first need to create corresponding image data indices, namely train.txt and test.txt files, where each txt file contains the directory of each image and its corresponding class (cat corresponds to label=0, dog corresponds to label=1). The schematic is as follows:
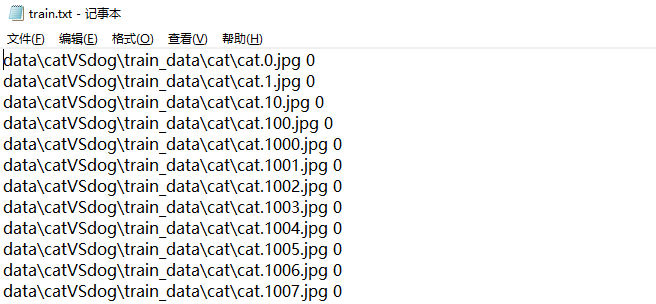
The Python script to create the image data index files train.txt and test.txt is as follows:
import os
train_txt_path = os.path.join("data", "catVSdog", "train.txt")
train_dir = os.path.join("data", "catVSdog", "train_data")
valid_txt_path = os.path.join("data", "catVSdog", "test.txt")
valid_dir = os.path.join("data", "catVSdog", "test_data")
def gen_txt(txt_path, img_dir):
f = open(txt_path, 'w')
for root, s_dirs, _ in os.walk(img_dir, topdown=True): # Get folder names under train
for sub_dir in s_dirs:
i_dir = os.path.join(root, sub_dir) # Get absolute path of each class folder
img_list = os.listdir(i_dir) # Get paths of all png images in the category folder
for i in range(len(img_list)):
if not img_list[i].endswith('jpg'): # Skip if not a png file
continue
#label = (img_list[i].split('.')[0] == 'cat')? 0 : 1
label = img_list[i].split('.')[0]
# Convert character category to integer type
if label == 'cat':
label = '0'
else:
label = '1'
img_path = os.path.join(i_dir, img_list[i])
line = img_path + ' ' + label + '\n'
f.write(line)
f.close()
if __name__ == '__main__':
gen_txt(train_txt_path, train_dir)
gen_txt(valid_txt_path, valid_dir)
After running the script, the train.txt and test.txt index files will be generated in the ./data/catVSdog/ directory.
1.2 Building a Dataset Subclass
To load our own dataset in PyTorch, we need to create a class that inherits from torch.utils.data’s Dataset class and modify its __init__, __getitem__, and __len__ methods. The default loading is for images, and the purpose of __init__ is to obtain a list containing data and labels, where each element can find the image location and its corresponding label. Then, we use __getitem__ to get the pixel matrix of each element’s image and the label, returning img and label.
from PIL import Image
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, txt_path, transform = None, target_transform = None):
fh = open(txt_path, 'r')
imgs = []
for line in fh:
line = line.rstrip()
words = line.split()
imgs.append((words[0], int(words[1]))) # Convert category to integer int
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
fn, label = self.imgs[index]
img = Image.open(fn).convert('RGB')
#img = Image.open(fn)
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
getitem is the core function. self.imgs is a list, self.imgs[index] is a string containing the image path and label, which are read from the generated txt file; using Image.open to read the image, note whether the img is single-channel or three-channel; self.transform(img) processes the image, where this transform can implement mean subtraction, standard deviation division, random cropping, rotation, flipping, affine transformations, and other operations.
1.3 Loading the Dataset and Data Preprocessing
Once MyDataset is built, the remaining operations are handled by DataLoader to load the dataset. In DataLoader, the getitem function in MyDataset will be triggered to read the data and label of an image, and concatenate them into a batch to return as the actual input of the model.
pipline_train = transforms.Compose([
#transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(), # Randomly flip the image
# Resize the image to 224x224
transforms.Resize((224,224)),
# Convert the image to Tensor format
transforms.ToTensor(),
# Normalize (to reduce model complexity when overfitting occurs)
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
#transforms.Normalize(mean = [0.485, 0.456, 0.406],std = [0.229, 0.224, 0.225])
])
pipline_test = transforms.Compose([
# Resize the image to 224x224
transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
#transforms.Normalize(mean = [0.485, 0.456, 0.406],std = [0.229, 0.224, 0.225])
])
train_data = MyDataset('./data/catVSdog/train.txt', transform=pipline_train)
test_data = MyDataset('./data/catVSdog/test.txt', transform=pipline_test)
# train_data and test_data contain all training and testing data, call DataLoader to load in batches
trainloader = torch.utils.data.DataLoader(dataset=train_data, batch_size=64, shuffle=True)
testloader = torch.utils.data.DataLoader(dataset=test_data, batch_size=32, shuffle=False)
# Class information also needs to be given
classes = ('cat', 'dog') # Corresponding label=0, label=1
In data preprocessing, we adjust the image size to 224×224 to meet the input requirements of VGGNet. The mean = [0.5, 0.5, 0.5] and std = [0.5, 0.5, 0.5] are then used for normalization.
Let’s take a look at the final dataset images and their corresponding labels:
examples = enumerate(trainloader)
batch_idx, (example_data, example_label) = next(examples)
# Batch display images
for i in range(4):
plt.subplot(1, 4, i + 1)
plt.tight_layout() # Automatically adjust subplot parameters to fill the entire image area
img = example_data[i]
img = img.numpy() # Convert FloatTensor to ndarray
img = np.transpose(img, (1,2,0)) # Move the channel dimension to the end
img = img * [0.5, 0.5, 0.5] + [0.5, 0.5, 0.5]
#img = img * [0.229, 0.224, 0.225] + [0.485, 0.456, 0.406]
plt.imshow(img)
plt.title("label:{{}}".format(example_label[i]))
plt.xticks([])
plt.yticks([])
plt.show()

2. Building the VGGNet Neural Network Structure
class VGG(nn.Module):
def __init__(self, features, num_classes=2, init_weights=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 500),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(500, 20),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(20, num_classes)
)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_features(cfg: list):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_features(cfg), **kwargs)
return model
First, we choose four structures A, B, D, and E from the six VGG structures to build the model. The cfg dictionary contains these four structures. For example, for vgg16, [64, 64, ‘M’, 128, 128, ‘M’, 256, 256, 256, ‘M’, 512, 512, 512, ‘M’, 512, 512, 512, ‘M’] represents the structure of the convolutional layers. 64 means conv3-64, ‘M’ means maxpool, 128 means conv3-128, 256 means conv3-256, and 512 means conv3-512.
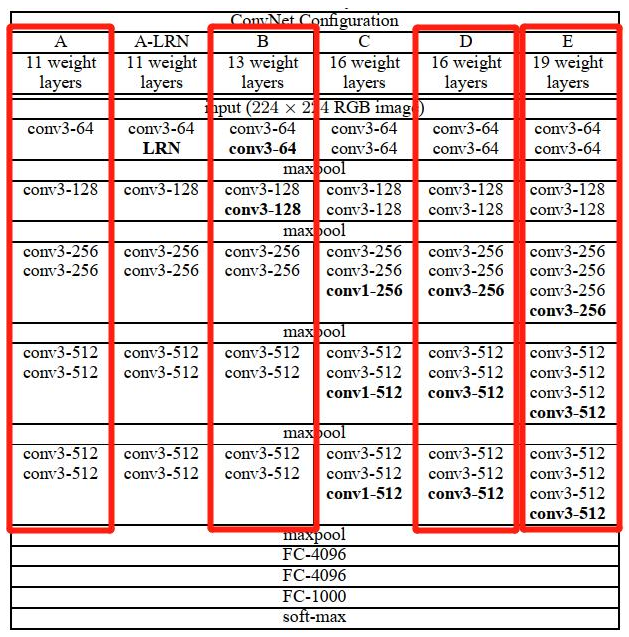
Once the VGG structure is determined, we pass this list to the make_features() function to construct the convolutional layers of VGG, which returns an instantiated model. For example, let’s construct the convolutional layer structure of vgg16 and print it:
cfg = cfgs['vgg16']
make_features(cfg)

When defining the VGG class, the parameter num_classes refers to the number of classes. Since our dataset only has two classes, cats and dogs, the number of neurons in the fully connected layer has been slightly adjusted. num_classes=2, and the output layer has two neurons instead of the original 1000 neurons. The FC4096 has been adjusted from the original 4096 neurons to 500 and 20 neurons respectively. Please note this adjustment based on the actual number of classes in the dataset. The rest of the network structure is exactly the same as in the paper.
The function initialize_weights() is used to initialize the network parameters, and we choose to turn off the initialization operation by default.
The forward() function defines the complete structure of the VGG network. Note that the output feature map of the last convolutional layer is N x 512 x 7 x 7, where N represents the batch size, and it needs to be flattened into a one-dimensional vector for connection with the fully connected layer.
3. Deploying the Defined Network Structure on GPU/CPU and Defining the Optimizer
# Create model and deploy to GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_name = "vgg16"
model = vgg(model_name=model_name, num_classes=2, init_weights=True)
model.to(device)
# Define optimizer
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.0001)4. Defining the Training Process
def train_runner(model, device, trainloader, loss_function, optimizer, epoch):
# Train the model, enable BatchNormalization and Dropout, set BatchNormalization and Dropout to True
model.train()
total = 0
correct =0.0
# Enumerate through the loaded dataset, getting data and indices
for i, data in enumerate(trainloader, 0):
inputs, labels = data
# Deploy the model to the device
inputs, labels = inputs.to(device), labels.to(device)
# Initialize gradients
optimizer.zero_grad()
# Save training results
outputs = model(inputs)
# Calculate loss
#loss = F.cross_entropy(outputs, labels)
loss = loss_function(outputs, labels)
# Get the prediction with the highest probability
# dim=1 means returning the index of the maximum value for each row
predict = outputs.argmax(dim=1)
total += labels.size(0)
correct += (predict == labels).sum().item()
# Backpropagation
loss.backward()
# Update parameters
optimizer.step()
if i % 100 == 0:
# loss.item() gives the current loss value
print("Train Epoch{} \t Loss: {:.6f}, accuracy: {:.6f}%".format(epoch, loss.item(), 100*(correct/total)))
Loss.append(loss.item())
Accuracy.append(correct/total)
return loss.item(), correct/total5. Defining the Testing Process
def test_runner(model, device, testloader):
# Model validation, must be written, otherwise the weights will change even without training when input data is present
# Calling eval() will disable BatchNormalization and Dropout, set BatchNormalization and Dropout to False
model.eval()
# Initialize the model's accuracy, set initial values
correct = 0.0
test_loss = 0.0
total = 0
# torch.no_grad will not calculate gradients or perform backpropagation
with torch.no_grad():
for data, label in testloader:
data, label = data.to(device), label.to(device)
output = model(data)
test_loss += F.cross_entropy(output, label).item()
predict = output.argmax(dim=1)
# Calculate the correct count
total += label.size(0)
correct += (predict == label).sum().item()
# Calculate loss value
print("test_average_loss: {:.6f}, accuracy: {:.6f}%".format(test_loss/total, 100*(correct/total)))6. Running the Model
# Calling
epoch = 20
Loss = []
Accuracy = []
for epoch in range(1, epoch+1):
print("start_time",time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
loss, acc = train_runner(model, device, trainloader, loss_function, optimizer, epoch)
Loss.append(loss)
Accuracy.append(acc)
test_runner(model, device, testloader)
print("end_time: ",time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())),'\n')
print('Finished Training')
plt.subplot(2,1,1)
plt.plot(Loss)
plt.title('Loss')
plt.show()
plt.subplot(2,1,2)
plt.plot(Accuracy)
plt.title('Accuracy')
plt.show()
After 20 epochs, the accuracy reached 94.68%.
Note that since the VGGNet network is quite large, running it on a CPU can be very slow or even freeze, so it is recommended to train using a GPU.
7. Saving the Model
print(model)
torch.save(model, './models/vgg-catvsdog.pth') # Save the model
The VGGNet model will be printed out and saved with the name vgg-catvsdog.pth in a fixed directory.

8. Model Testing
Next, we will test the model using an image from the Dogs vs. Cats test set.
from PIL import Image
import numpy as np
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = torch.load('./models/vgg-catvsdog.pth') # Load the model
model = model.to(device)
model.eval() # Set the model to test mode
# Read the image to be predicted
img = Image.open("./images/test_dog.jpg") # Read the image
#img.show()
plt.imshow(img) # Show the image
plt.axis('off') # Hide the axis
plt.show()
# Import the image, the image is expanded to [1,1,32,32]
trans = transforms.Compose(
[
transforms.Resize((227,227)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
#transforms.Normalize(mean = [0.485, 0.456, 0.406],std = [0.229, 0.224, 0.225])
])
img = trans(img)
img = img.to(device)
img = img.unsqueeze(0) # Expand the image to an additional dimension, as the input to the saved model is 4D [batch_size, channel, height, width], while a normal image is only 3D [channel, height, width]
# Prediction
# Prediction
classes = ('cat', 'dog')
output = model(img)
prob = F.softmax(output,dim=1) # prob is the probability of the two categories
print("Probability:",prob)
value, predicted = torch.max(output.data, 1)
predict = output.argmax(dim=1)
pred_class = classes[predicted.item()]
print("Predicted class:",pred_class)

Output:
Probability: tensor([[7.6922e-08, 1.0000e+00]], device=’cuda:0′, grad_fn=<SoftmaxBackward>)
Predicted class: dog
The model prediction result is correct!
That’s all for the core code to reproduce the VGGNet network using PyTorch. I recommend that everyone code the complete content based on the article, and you can use your own dataset and adjust the network structure according to your actual situation.
The complete code is available on GitHub at:
https://github.com/RedstoneWill/CNN_PyTorch_Beginner/blob/main/VGGNet/VGGNet.ipynb
Previous Highlights
Resources and Downloads for Beginners in AI
(Images + Videos) Machine Learning Introduction Series Download
Chinese University MOOC "Machine Learning" (Lectured by Huang Haiguang)
Machine Learning and Deep Learning Notes and Other Materials
"Statistical Learning Methods" Code Reproduction Collection
AI Basics Download
Join the Machine Learning Exchange QQ Group 955171419, scan the QR code to join the WeChat group: