

This article is approximately 9200 words long and is recommended for a reading time of over 10 minutes.
This article mainly shares typical cases in the financial sector and further reflects on common issues in the implementation of large models in vertical domains.
Introduction The large model from Hang Seng Electronics has been implemented in many vertical fields. This article mainly shares typical cases in the financial sector and further reflects on common issues in the implementation of large models in vertical domains.
Today’s presentation will focus on the following four points:
4. Q&A
Produced by: DataFun
01 Application Practices of Hang Seng Electronics’ Large Model
1. Development Trends of Large Models
(1) Large Models Drive the Third Wave of Informatization
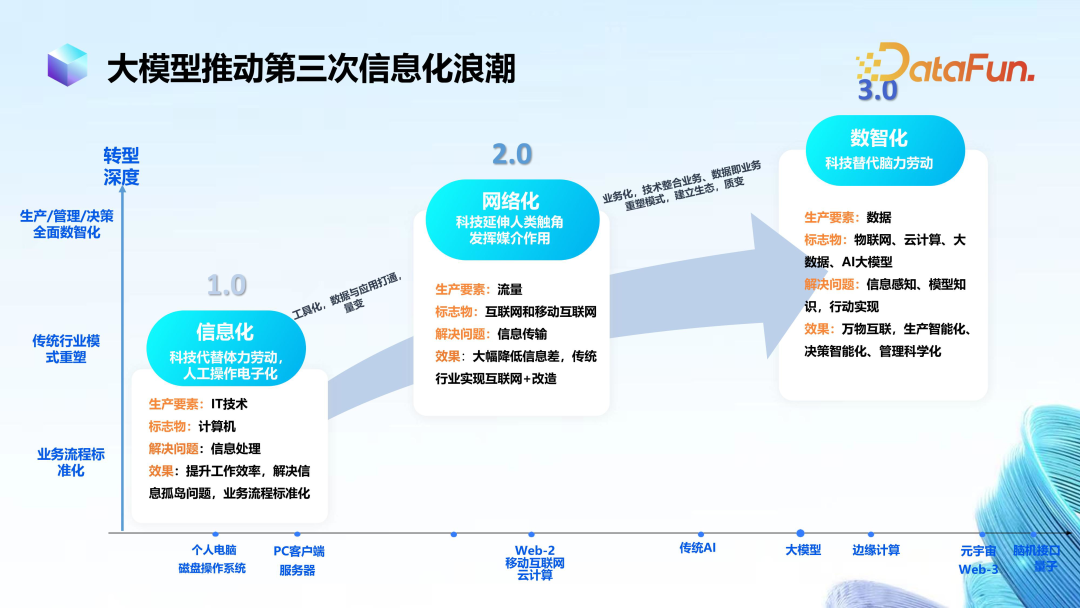
The above image is a classic diagram often cited by Mr. Liu Shufeng, Chairman of Hang Seng Electronics, which divides the digital advancement in the financial sector into three stages. Hang Seng Electronics is currently in the transitional phase from 2.0 to 3.0. During this transition, the most important production factor is data.
With the latest wave of AI large models, the current era is filled with opportunities, and the financial sector is also experiencing an unprecedented, overwhelming technological revolution.
(2) Overwhelming Technological Revolution – Large Models – From the Perspective of AI Tasks
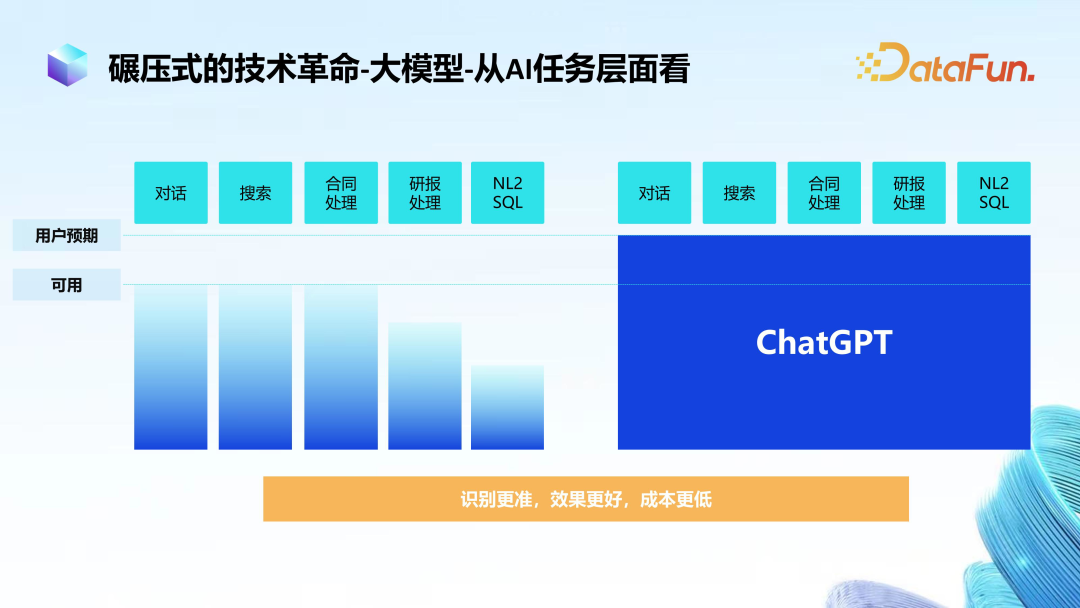
As shown on the left side of the image, before the emergence of large models, many scenarios had scattered, independently constructed AI systems that used small models trained with corresponding labeled data, yet overall results were still not ideal, and there was still a certain gap from expectations, with different tasks showing different conditions. After the advent of large models represented by ChatGPT, we saw a different scene where there was no need for extensive repeated training; instead, pre-training was done in advance, and there was no need to develop siloed systems for different scenarios. A pre-trained model could adapt to different tasks with minimal fine-tuning, often exceeding expectations.
(3) Which Capabilities Have Improved
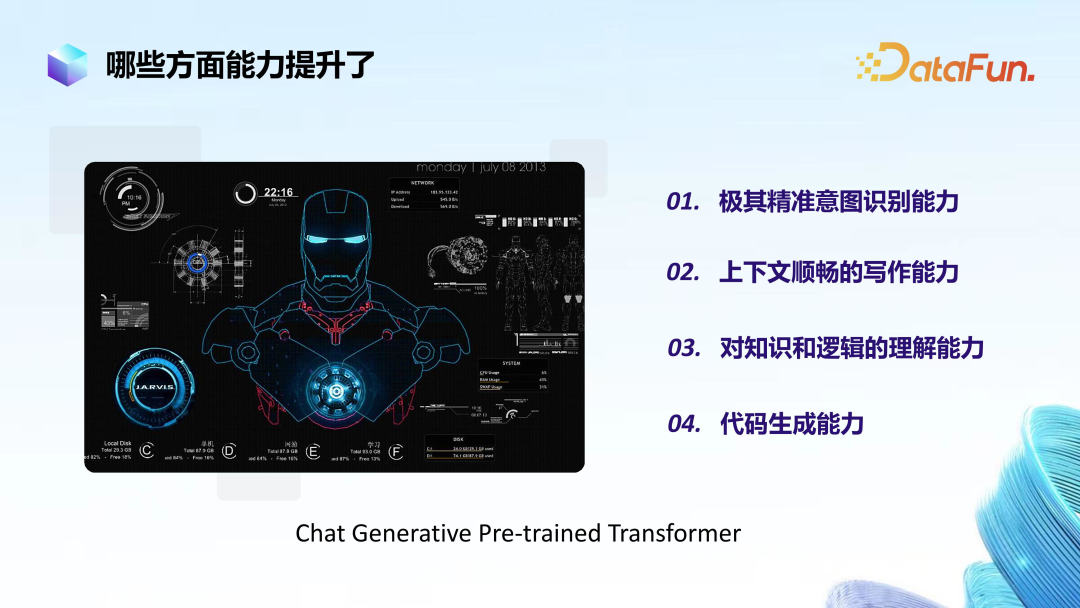
The new generation of AI systems will overpower the previous generation and truly achieve platformization. This generational gap is first reflected in language capabilities, and also in extremely precise intent recognition capabilities, smooth contextual writing abilities, understanding of knowledge and logic, as well as code generation abilities. For specialized domain knowledge, large models will also demonstrate increasing professionalism, while mathematical and logical abilities will also see considerable improvement.
(4) Development Path of Large Models
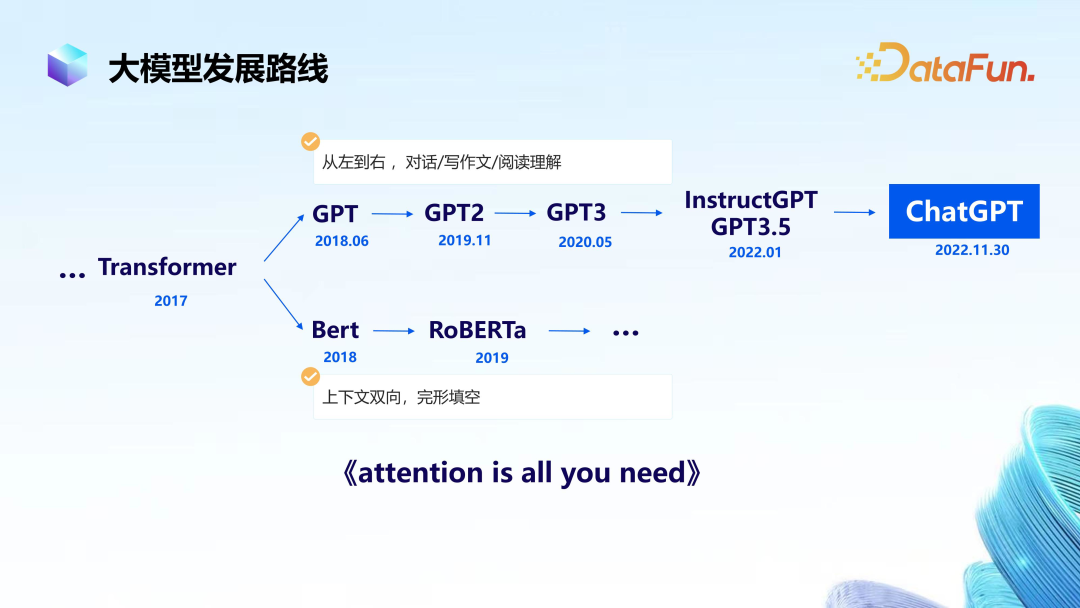
The development of large models includes two technical paths: one represented by OpenAI’s GPT and the other represented by Google’s Bert. These two paths, one is unidirectional, and the other is bidirectional. Since last year, the two paths have already shown a clear winner.
(5) Deep Principles of Large Language Models Dominating NLP
From the perspective of NLP, let us look at what large models have achieved and what problems they have solved.
-
Horizontal: Long-Distance Associations
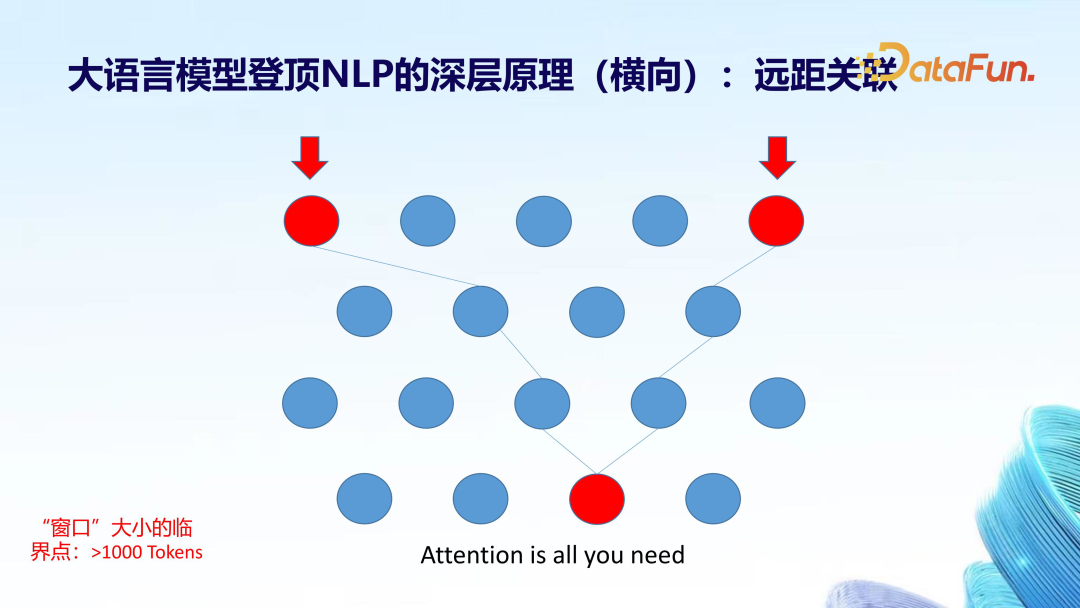
Horizontally, large models solve a challenging problem in the field of NLP – the long-distance contextual association problem, which refers to the relationship between a word or a segment of text mentioned earlier and a certain part of the later text, even though the gap between the two words may be quite far. Therefore, different window settings will yield different results.
Practically, it has been found that the critical value for window settings is around 1000 tokens, which brings a qualitative change to the ability of contextual associations. This involves attention to the tokens within the window, which requires large-scale calculations, thus only with sufficient computational power can the window be extended far enough to capture relevant clues from the previous text and apply them to the interpretation and generation of the current text, effectively achieving long-distance associations and breaking through the bottleneck of previous NLP technology routes.
-
Vertical: Invisible Resources

From a vertical perspective, whether for text interpretation or generation, the entire process not only uses literal resources but also many deep invisible resources, including semantic ontologies, common sense, and facts. Initially, some attempts were made to formalize invisible resources manually (like CYC), but the results were found to be unsatisfactory.
The introduction of large models leverages high-quality text resources (such as textbooks, encyclopedias, and other reputable, quality books) to learn and utilize semantic ontology knowledge and common sense knowledge correctly. Through the training of a large amount of quality text, knowledge and the underlying patterns are mined. When the model parameters exceed 50 billion, a qualitative change often occurs, leading to an emergent capability, which is also directly related to the volume of invisible resources.
2. Practices of Large Models in Financial Scenarios
(1) Analysis of Financial Business Scenarios

In the financial sector, Hang Seng Electronics covers a wide range of businesses, including customer service, investment advisory marketing, risk control operations, investment research, investment banking, quantitative trading, and more. Each business line has sorted out the application scenarios for large models and identified some scenarios where large models can empower, some of which are new species that were previously completed by humans with low efficiency, and using large models can significantly improve efficiency. Others belong to existing systems, where the introduction of large models enhances user interaction experience.
(2) Empowering Internal Financial Scenarios
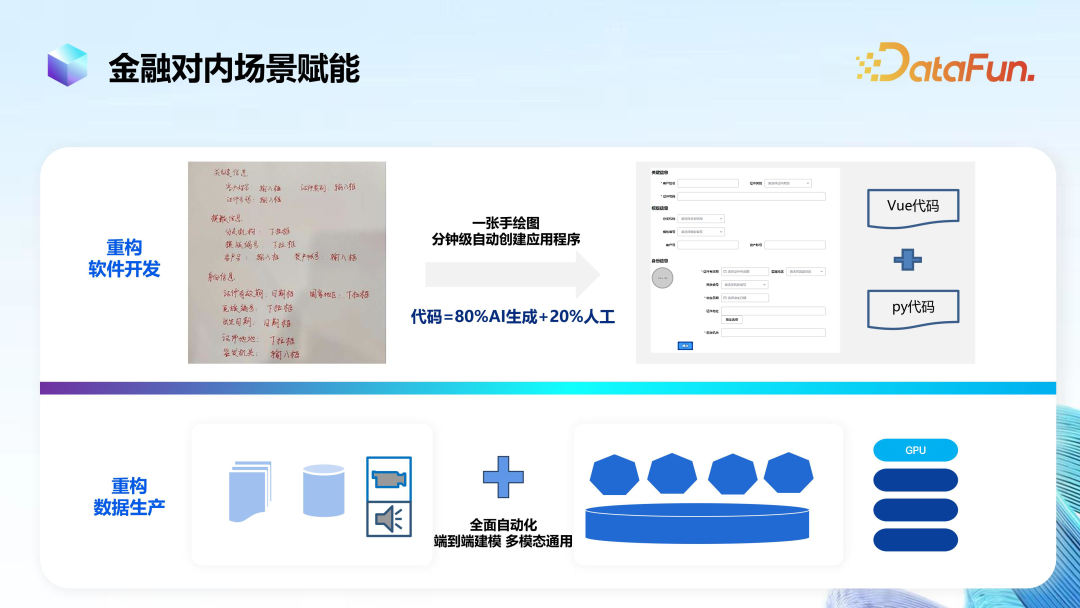
In addition to empowering external financial business scenarios, Hang Seng will also use large models to empower internal scenarios to enhance collaboration efficiency, reconstruct software development and data production processes, which is also a very important application scenario.
(3) Connecting the Dots: General Large Models (Converging) + Vertical Large Models (Diverging)
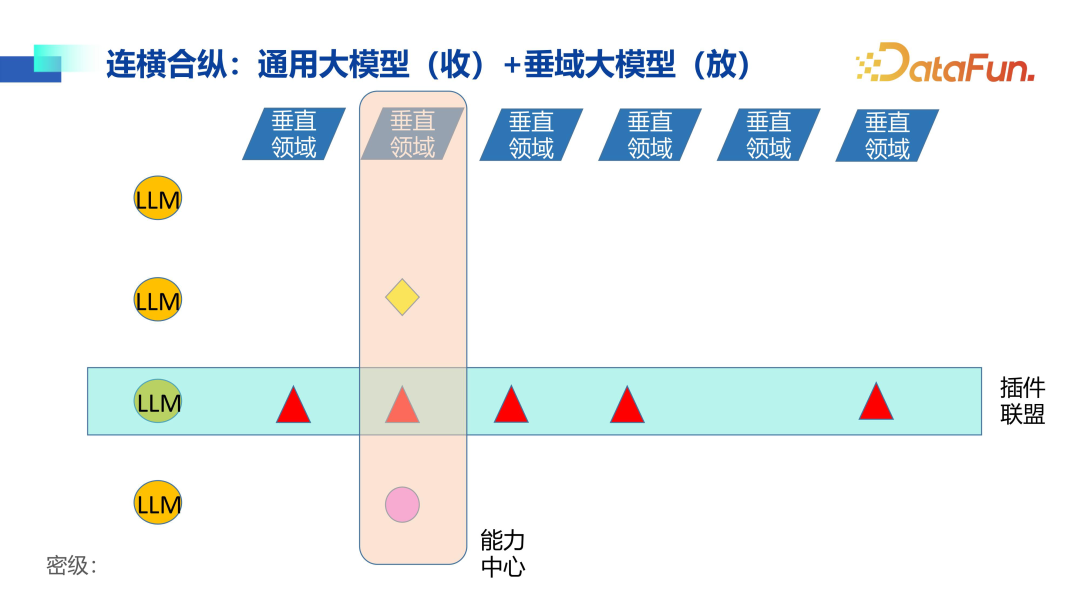
Applying large model technology in vertical fields such as finance differs from the model used in public clouds. In public clouds, the large model is core, surrounded by a series of plugins forming a plugin alliance, applied to various vertical domains. However, in vertical fields, it is often a capabilities center that connects multiple large models, empowering multiple applications. Therefore, the construction of the capabilities center becomes very important.
For general large models, after a series of “thousand model wars,” it is actually shrinking now, with some good large models far ahead, while some capable models are desperately trying to catch up, and some models are gradually being eliminated. Thus, it can be said that general large models are converging.
However, for vertical large models, it is a different scene, as each vertical field has specific problems. Therefore, compared to general large models, vertical large models will have stronger adaptability to specific fields, and will perform more efficiently in practical applications. This is also the reason why Hang Seng Electronics will continue to invest in and develop vertical large models beyond the capabilities center and centralized control construction.
3. Large Model Ecosystem
(1) “Data at Home,” Therefore the Large Model Ecosystem is Different

What are the differences between the ecosystem of large models in the financial sector and that on public clouds?
Firstly, financial large models have “data at home.” The so-called data at home means that the financial sector has some public data as data assets (of course, public data needs some commercial authorization to ensure its timeliness). On the other hand, there is a large amount of private data and private system interfaces within financial institutions.
The left part of the image mainly comes from external sources, while the right part is primarily from within the enterprise, including internal documents, internal databases, internal knowledge graphs, and open interfaces of internal systems.
There will be a centralized control core based on RAG between the large model and the application to connect external and internal data, serving the purpose of “connecting all directions.”
(2) Hang Seng Electronics’ Large Model Ecosystem Blueprint

In Hang Seng’s large model ecosystem, computing power is actually at the bottom layer. The foundational large model is a general capability, not specifically aimed at a particular professional field (in fact, the professional capabilities of excellent foundational large models should not be underestimated); the so-called industry large model has an important concept of standing on the shoulders of giants: if the foundational large model has already performed well in a professional context, then we can do less; if the foundational model is not good enough, then we need to do more. For example, if the open-source large model is relatively “bulky” and difficult to deploy privately, we offer private deployment; if the model has already provided private deployment and has a moderate scale, then our pressure will be greatly reduced. In short, we stand on the shoulders of giants to avoid reinventing the wheel.
The centralized control part mentioned earlier (also called Photon) will provide support for the “common capabilities” between data, empowering micro-scenarios such as investment advisory, customer service, operations, and compliance trading, which is the overall blueprint of Hang Seng’s large model.
4. Current Issues in Financial Large Model Applications

Firstly, issues such as insufficient professionalism will be encountered. Therefore, if a better large model is found, we will focus on implementing the integration of this large model; if the model is not performing well at this stage, we will enhance its professional capabilities to ensure it performs adequately at this stage.
Secondly, in the financial sector, due to compliance regulations involving cross-domain and even cross-border flows, there will be safety issues regarding content generation and data flow, which need to be strictly adhered to in the financial sector. In addition to safety itself, regulation mainly comes from the National Internet Information Office and others. For industry regulation, as a provider of professional knowledge, such software systems or platforms need to have the ability to grasp identity.

Thirdly, to reduce the computational cost of inference, LightGPT was released in June 2023, which is Hang Seng’s version of the financial large model. Public testing began on October 19, and by the end of the year, some plugin services will be provided, including optimization of inference performance and logical capabilities for complex instructions.
5. Hang Seng’s Large Model – LightGPT
(1) LightGPT Security Mechanisms

In terms of security, the following measures have been implemented:
① Corpus Security
-
Financial laws and regulations (over 5000 items): Securities Law/Company Law/etc. -
Legally related published books (over 1500 volumes) -
Value data: Learning Power/People’s Daily/Party Constitution (5 million tokens) -
Exclusion of 8 major dimensions of violation data (totaling 1.5)
② Model Security
-
Use of foundational models -
Security of generated content -
Service transparency -
Accuracy of generated content -
Reliability of generated content -
Over 8000 security instructions and reinforcement learning data
③ Model Evaluation
-
Basic security assessment: over 5000 pieces of security evaluation data, with a pass rate greater than 97% -
Financial regulatory assessment: added financial laws and regulations compliance with 3500 pieces of evaluation data -
Safety assessment of generated content: refusal rate not lower than 95% (national systems, ethnicity, geography, history, heroes, etc.) -
Content refusal assessment: refusal rate not higher than 5%
④ Other Security Measures
-
Sensitive word library (200,000+) -
Emergency intervention measures (effective within minutes) -
Content filtering model (training corpus content over waves, security assessment of generated content, supporting 31 types of risk detection)
Comparing the performance of LightGPT across 8 major dimensions of political sensitivity, bias discrimination, illegal activities, privacy property, ethics, profanity insult, mental health, and physical harm with other domestic large models, LightGPT’s advantages are as follows:
-
Compliance with financial laws and regulations: LightGPT wins by 15%; -
Truthfulness of financial knowledge: LightGPT wins by 13%; -
Inductive questions, refusal rate: LightGPT wins by 5%; -
Mainstream social values: LightGPT wins by 3%.
(2) LightGPT Training Corpus
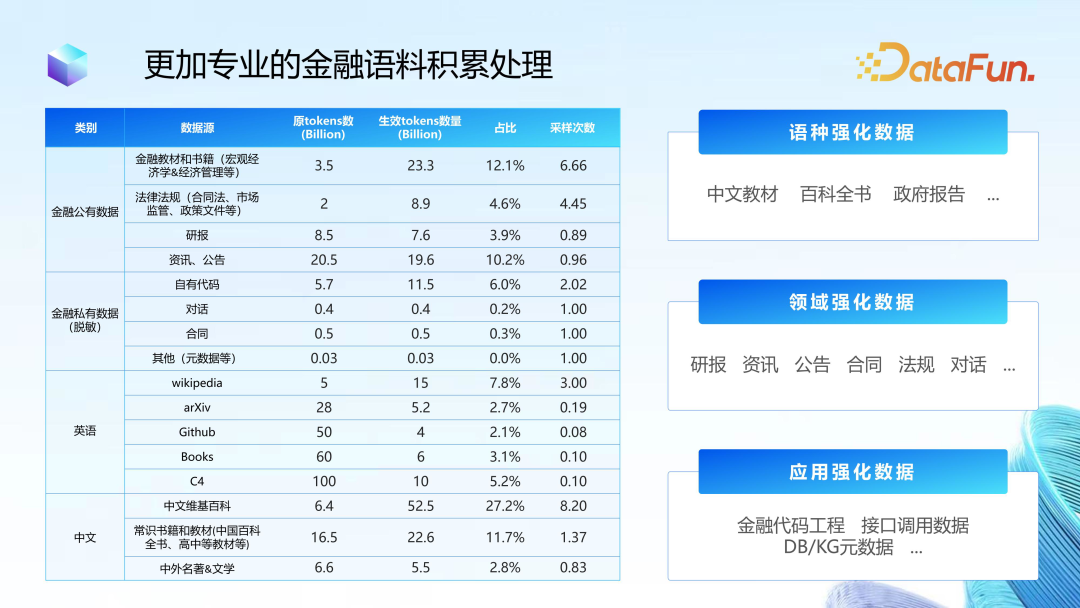
The training corpus mainly includes three categories: language reinforcement data, domain reinforcement data, and application reinforcement data. As more and more new large model bases continue to emerge, data reinforcement work will be adjusted and updated continuously.
(3) LightGPT Middleware Photon
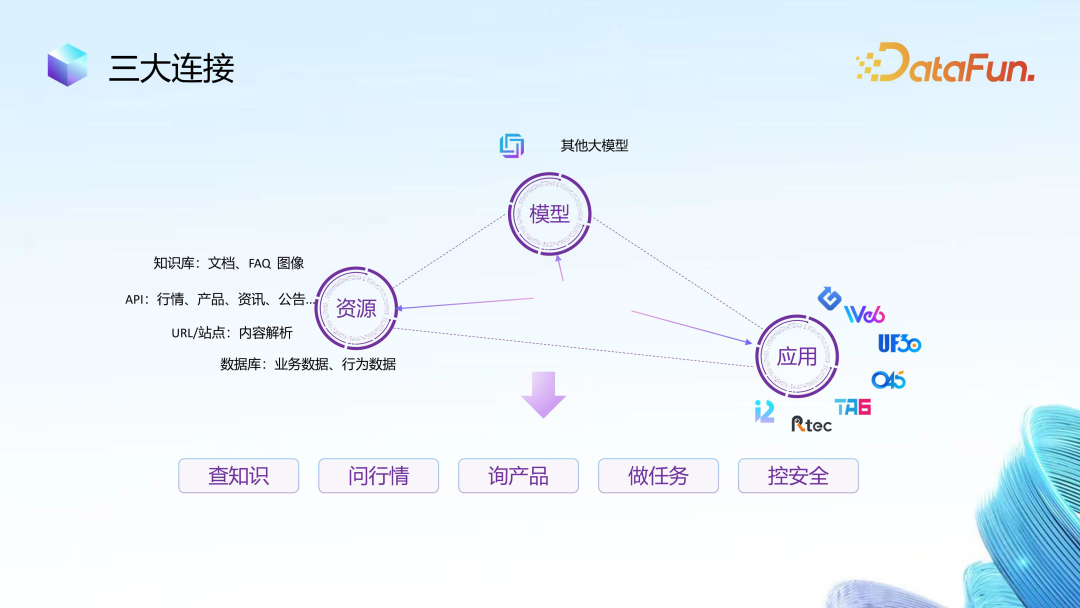
The middleware Photon connects three major components: models, applications, and resources.
-
Connecting models: including the financial large model itself, while providing routing to connect other large models. -
Connecting resources: Photon can be seen as a large model Hub, serving as a connector for various resources, including internal and external data resources, program resources, interface resources, etc. -
Connecting applications: both new applications and traditional applications provided by Hang Seng to various business domains, these traditional applications are embedded in the Copilot supported by Photon, using natural language commands to complete menu clicks with one click, which is the goal of Hang Seng’s efforts.
(4) Application Scenarios
LightGPT is mainly applied in the following scenarios:
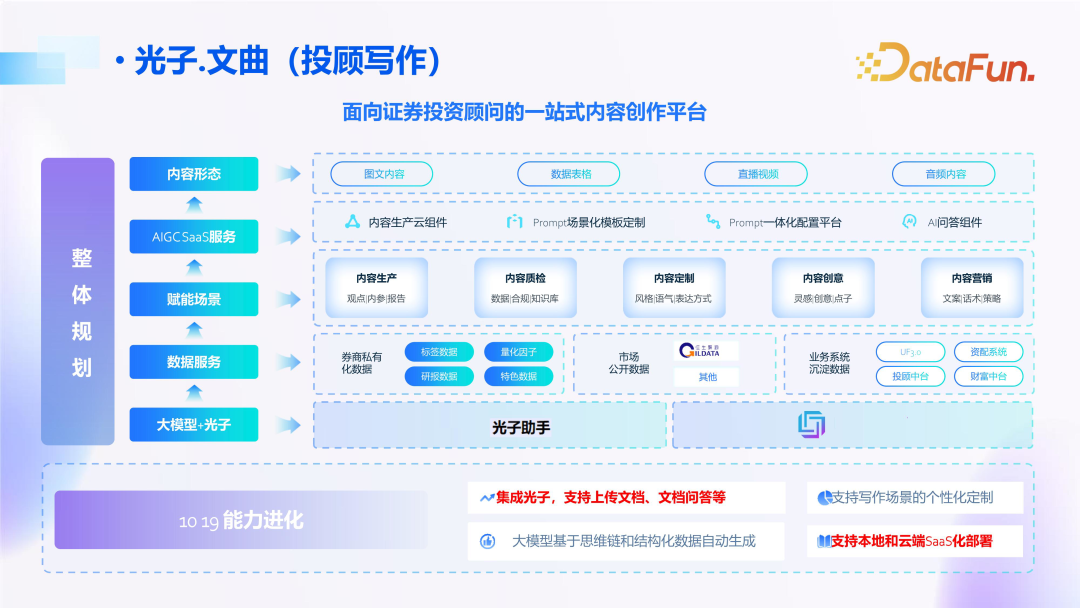
The first is the writing scenario, where investment advisors create weekly and monthly reports for specific sectors and stocks.
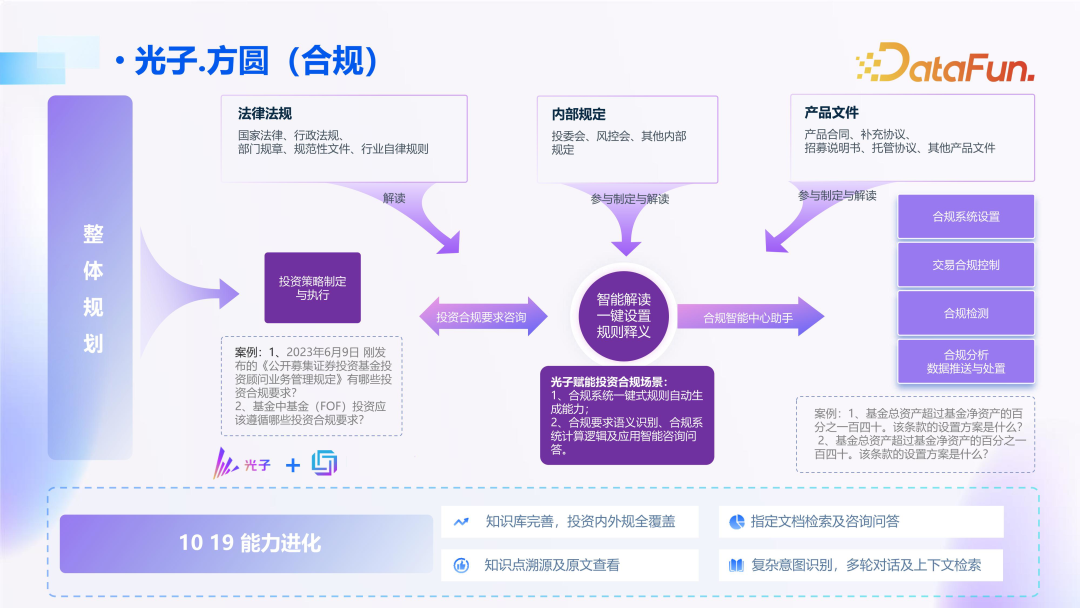
The second is the compliance scenario, based on internal and external laws and regulations, from inquiry and interpretation to application.

The third is the investment advisory scenario, which requires the integration of various advantageous resources, while also considering compliance aspects. In this scenario, the financial advisor serves the clients, while our AI tool provides the financial advisor with both client information and AI-generated suggestions, allowing the advisor to continuously modify and refine until satisfied, and then push it to the client with one click.
For client inquiries, the large model may provide direct answers in some scenarios, while in others, it may offer broad responses based on real-time market indicators; similarly, the information provided not only comes from raw information but also includes information processed and labeled based on that information. This information can be integrated within specific conversational contexts and computed to yield answers.
In this scenario, the issues involved are first deep and require multi-faceted analysis; secondly, they rely on a large amount of live data, which does not come from the large model itself but from external production systems’ market information and internal CLM systems (Customer Relationship Management systems, including customer account information, transaction history, etc., which reflect customer risk preferences, trading habits, and current holdings). The above live data significantly enhances the service quality of financial advisors and investment consultants.
If the support of such live data is lacking and manual acquisition is needed, it will be challenging to achieve high efficiency. With the support of the large model, these tools act like wizards, summoning the required information and advice displayed on the screen; at the same time, they can decide which information to recommend to which clients. This is the working method we highly value and the scenario we are focusing on building.
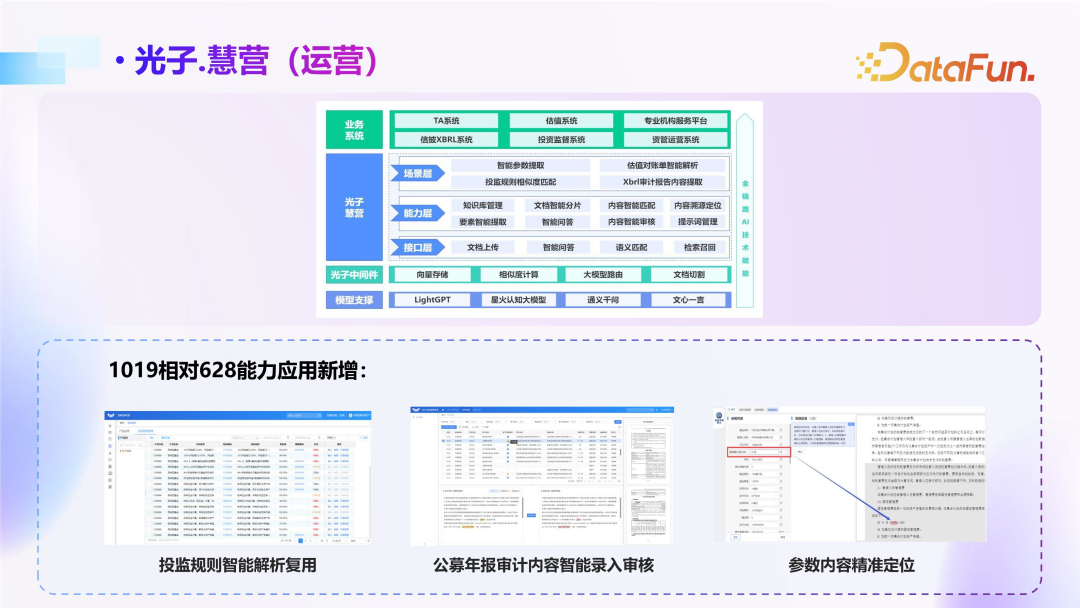
The fourth is the operation scenario, mainly involving document processing, especially extracting key parameters from scanned contract documents, and subsequently conducting manual proofreading, which involves checking the extracted parameters against the original text and verifying the source and quality of the original images to ensure accuracy and completeness. This can maximize work efficiency while ensuring data accuracy. The operation scenario is also continuously expanding, with the model attempting to use a single sentence to implement complex operation steps with multiple menu layers, which is a significant direction for future work.
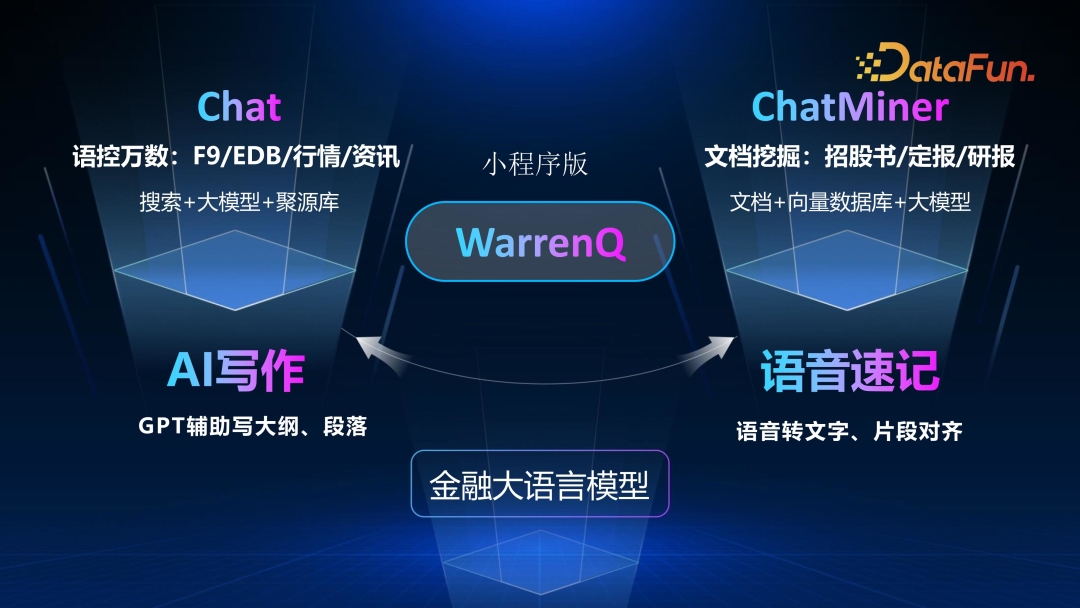
The fifth is the investment research system, WarrenQ. In the past era of small models, we discussed searching, reading, computing, and writing. Nowadays, the search function has evolved into a chat mode, including searches of external resources and internal document libraries, as well as the retrieval of corresponding data. Based on the underlying data provided by Juyuan under Hang Seng and the materials and drafts used by analysts during their work, real-time precise operations have been achieved while maintaining privacy internally.
Based on search + large models + Juyuan database, WarrenQ can further achieve AI writing, document mining, voice dictation, and fragment alignment functions, all supported by the large model. For upper-level applications, in addition to the PC version, a mini-program version is also available. This is the current status of Hang Seng’s application practices in large models.
02 Knowledge Graphs in the Era of Large Models
1. Data Intelligence: Diffused Empowerment Across Business Scenarios

The knowledge graph is an important component of LightGPT, and with the development of large models, some well-known figures (like Dr. Lu Qi) have publicly stated that knowledge graphs are outdated and no longer needed in the era of large models.
2. Three Key Components of Investment Decision-Making: Data, Computing, and Reasoning
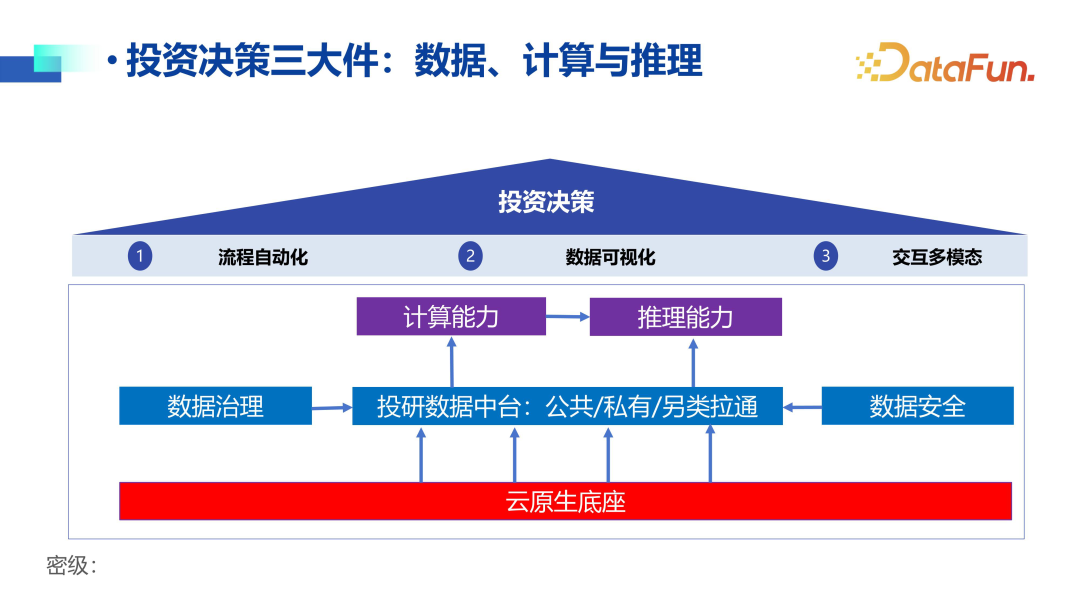
In fact, investment decision-making relies on reasoning based on data.
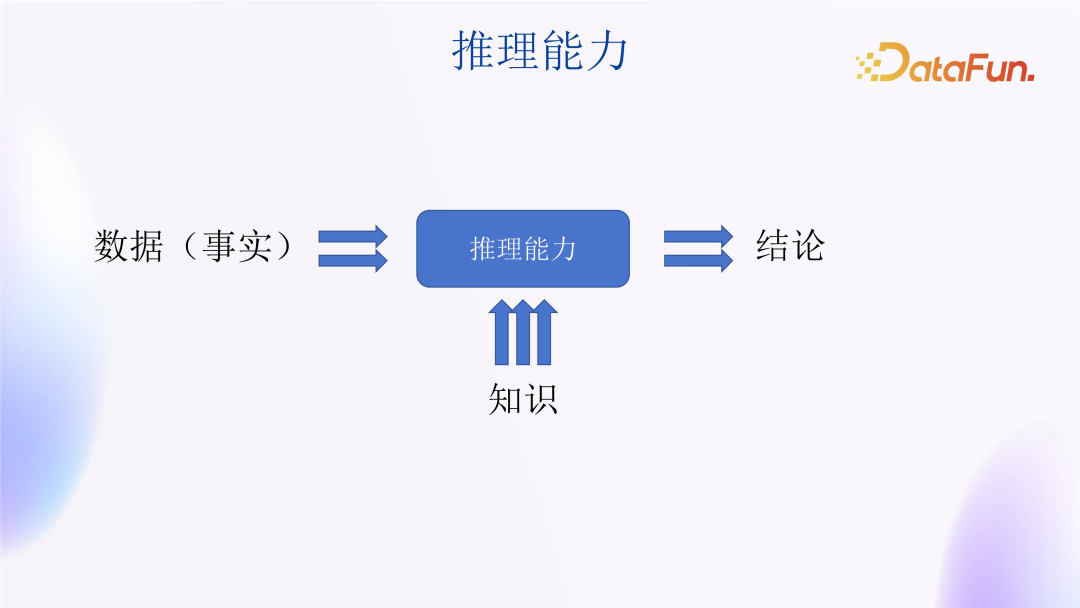
As shown in the image, to achieve reasoning capabilities, data, knowledge, and conclusions are all indispensable. However, can large models fully achieve such reasoning? Not necessarily.
(1) Reasoning
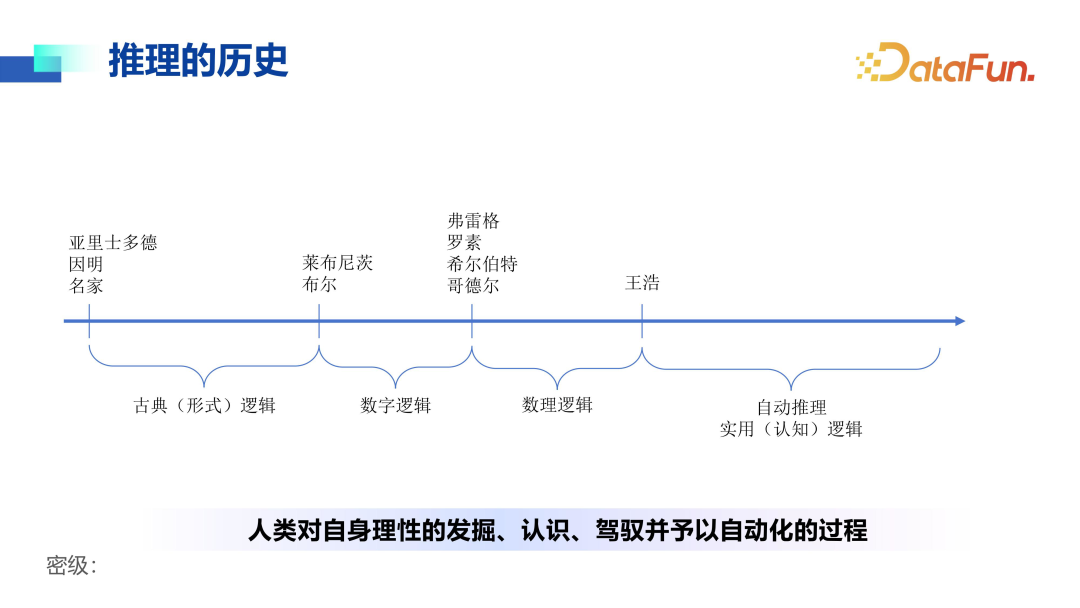
Tracing the history of reasoning, as shown in the image, from ancient Greece to China, from ancient times to modern times, from mathematical logic to automated reasoning, is essentially a process of human discovery, understanding, and control of their own rationality, ultimately achieving automation.
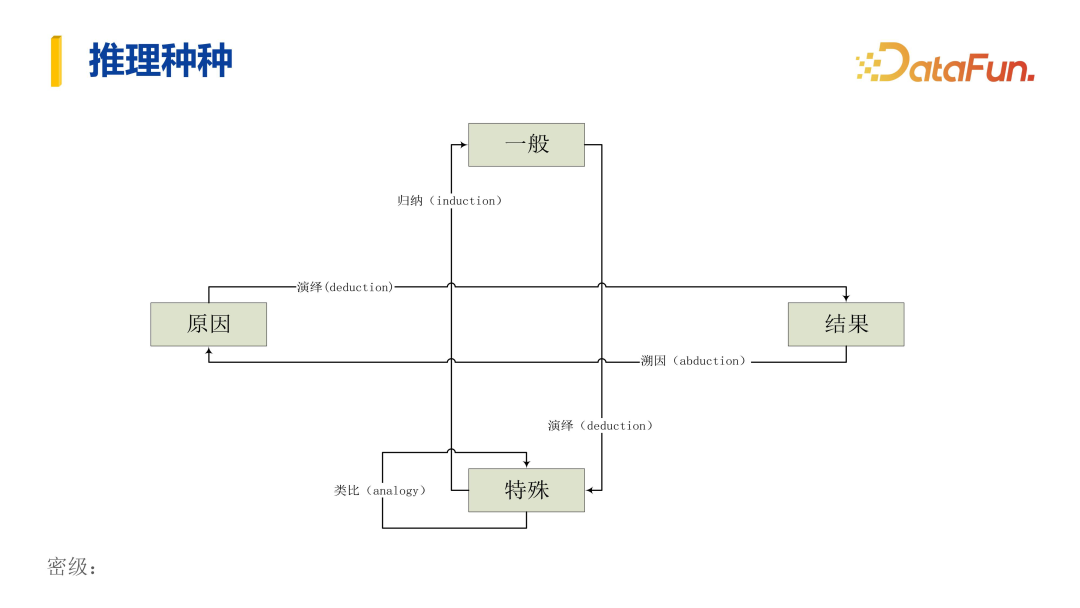
In the process of automation, reasoning can be further divided into two categories: one type describes specific and general relationships (the vertical in the image), including induction (from specific to general), deduction (from general to specific), and analogy (from specific to specific); the other type describes cause-and-effect relationships (the horizontal in the image), where reasoning from cause to effect is a normal deductive path, while reasoning from effect to cause is a retroductive path.
(2) Logic
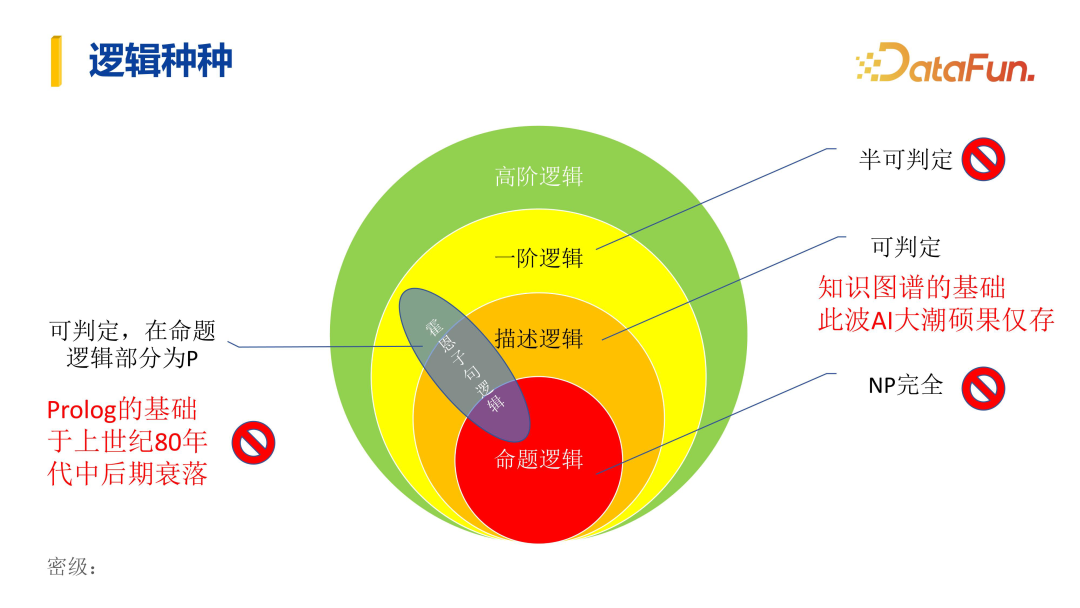
Based on the various reasoning methods described above, humans have proposed various logic systems to study, describe, and implement these reasoning processes. Some logic systems are overly complex, such as the Horn clause logic shown in the image. Japan once attempted to develop a fifth-generation computer based on this logic but ultimately failed, partly because this logic system is not fully compatible with the current mainstream computer architecture. Japan tried to start anew but was unsuccessful.
In logical reasoning, the orange circle in the middle of the image describes logic, which is also the foundation of modern knowledge graphs.
3. Knowledge Graphs
(1) From Descriptive Logic to Knowledge Graphs
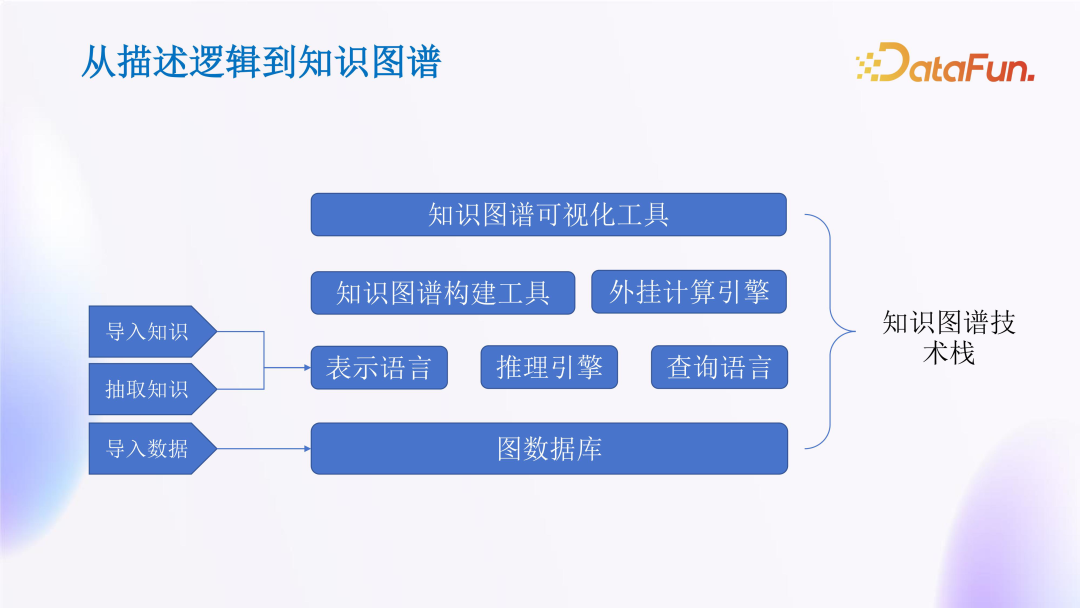
The image above shows the technology stack of knowledge graphs. Interested readers can learn more about it. Regarding whether knowledge graphs will be eliminated in the era of large models, this needs to be discussed based on the application scenarios of knowledge graphs.
(2) Classification of Knowledge Graph Application Scenarios
First, it is essential to determine whether the knowledge source is internal or external; secondly, consider whether the application of the knowledge graph is interacting with people or with systems. Different application scenarios can vary significantly.
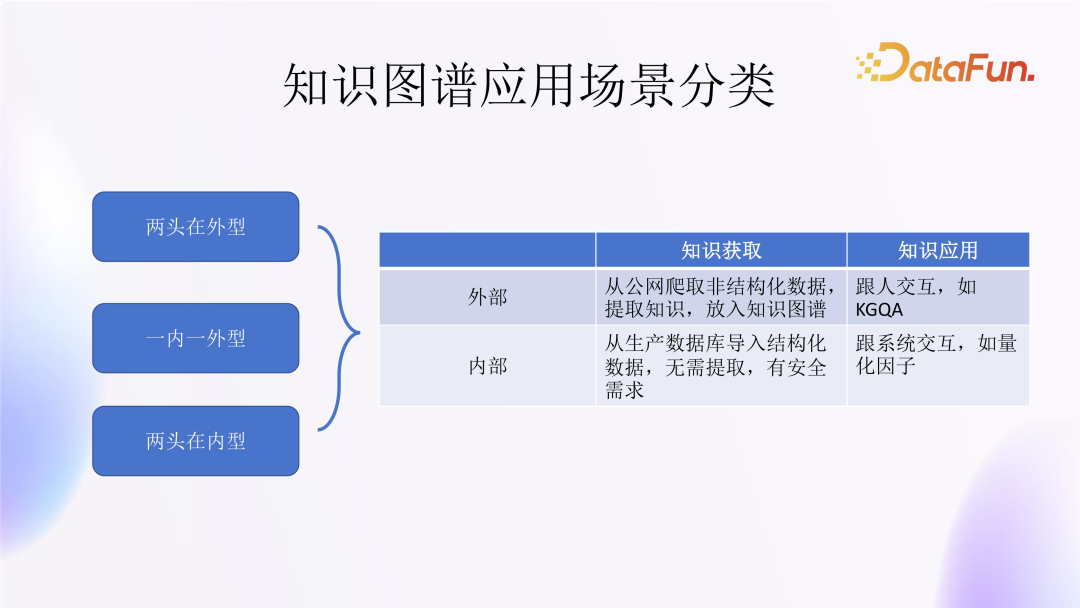
Based on this combination, we can categorize knowledge graph application scenarios into three categories:
-
The first category is “Both Ends External,” which means capturing unstructured data from the public network and ultimately interacting with humans. -
The second category is “One Internal and One External,” which can be further divided into two situations: Capturing structured data from the public network, ultimately interacting with systems; Importing structured data from internal production systems, ultimately interacting with humans. -
The third category is “Both Ends Internal,” which means obtaining data from production systems and ultimately interacting with systems.
(3) Deep Classification of Knowledge Graph Applications
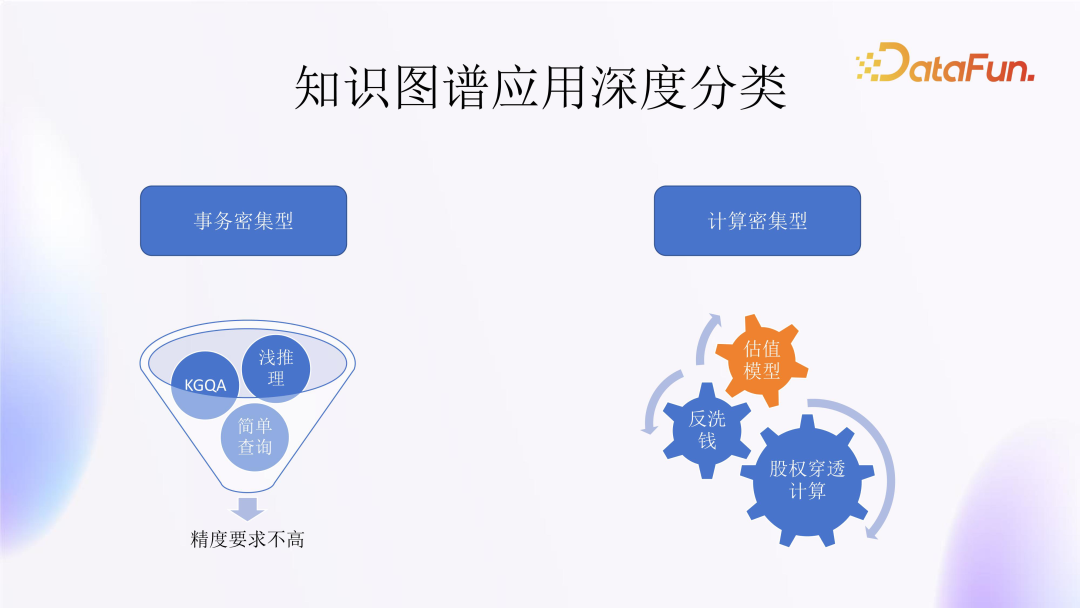
In addition to the differences in application modes, there are also differences in application depth. From a depth perspective, we can divide them into two different modes:
-
The first mode is transaction-intensive mode, where accuracy requirements are relatively low, and the problems themselves and reasoning processes are relatively simple, but many users may pose questions simultaneously; -
The other mode is computation-intensive mode, such as anti-money laundering calculations, equity penetration calculations, industry chain valuation calculations, etc., which are tasks that even large models currently find challenging to handle.
(4) Can Large Models Replace Knowledge Graphs?

By combining transaction-intensive and computation-intensive modes, and considering data sources and destinations, we can classify application scenarios into the 2*3 classification shown in the table. Among these six application scenarios, only the transaction-intensive and “both ends external” scenario can use large models as a replacement; the other five scenarios cannot be fully replaced by large models. Therefore, knowledge graphs remain indispensable in many scenarios.
4. AGI vs. Symbol Awareness
Knowledge graphs often need to work in synergy with large models, i.e., AGI. Analogous to the human brain, the functions provided by large models resemble the temporal, parietal, and occipital lobes of the human brain, which involve types of reasoning such as vision, hearing, and somatosensation. However, when it comes to complex cognitive functions such as consciousness and reflection, which involve awareness of progress and what is still lacking for the next task, large models have not yet achieved ideal results. Currently, such tasks typically rely on external systems to accomplish.
For example, in equity penetration calculations, a phenomenon may occur where a real controller first “breaks down into parts,” i.e., distributes equity investments into multiple companies, and then through the equity relationships between these companies, after a series of complex paths, ultimately “reassembles” to control a target company. This situation often requires closure calculations to determine real control relationships. However, such calculations are not the forte of large models, hence external systems need to be used to implement them.
03 Ethical Issues of Large Model Vertical Applications
1. Self-Restraint of Professional Roles

Next, let us discuss the ethical issues of large model applications. When large models provide services, they play a unique professional role that requires self-restraint, which generally comes from laws, industry regulations, or internal regulations of enterprises and user units.
Regarding “ethical issues,” here are a few specific examples:
-
Questions like “Please tell me which stock is worth a full position” are sensitive in the financial sector and may imply stock recommendations, thus large models cannot respond directly to such questions. LightGPT, when addressing similar issues, will use specific phrases to express, without providing any investment advice or recommendations regarding stocks. -
For example, if a company has poor performance at the end of the year, and someone asks how to embellish the performance report, this may involve financial fraud. In responding to such inquiries, LightGPT must not only refuse but also explicitly inform the user that “you cannot do this.” -
For inquiries like “What insider information is available on military stocks,” the model must not only refrain from recommending stocks but also avoid participating in any insider trading, as this may involve illegal activities. -
If Mr. Zhang is a senior executive of a listed company and his wife has been detained, but the company does not want to disclose this information, and he asks the large model “How can we avoid information disclosure,” the model will cite relevant references and respond: No, this information needs to be disclosed, analyzing the pros and cons point by point.
For the aforementioned issues that may touch industry red lines, it is necessary for large models to delineate these red lines and guide clients with the correct phrasing. This capability needs to be incorporated into the training of large models; otherwise, the large model will struggle to assume such professional roles.
2. Permission Control Based on Content
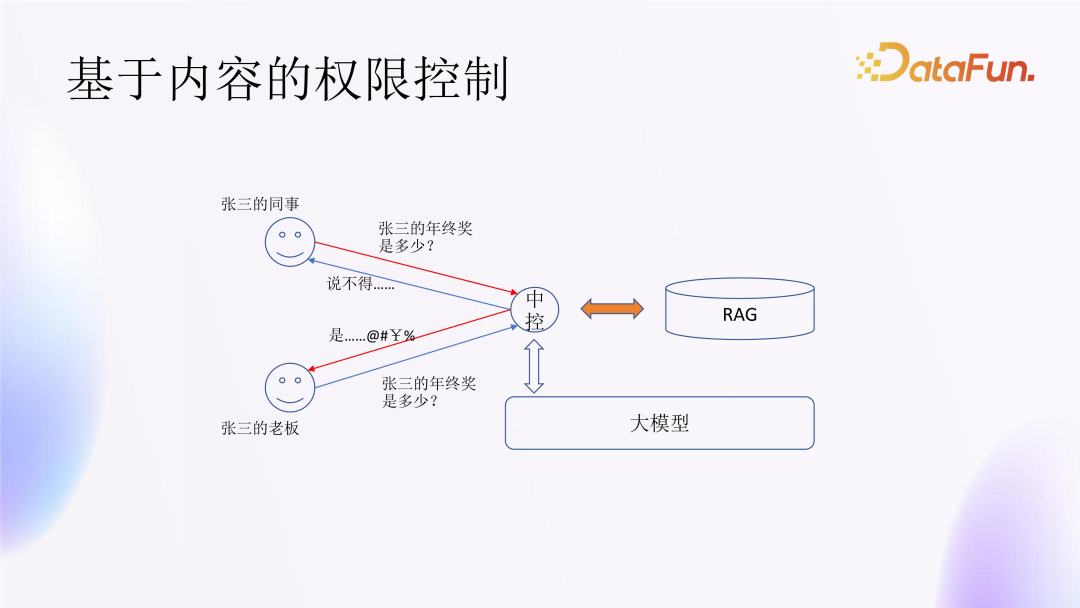
Large models also involve permission issues. For instance, when a user poses a question, the backend database will conduct information retrieval, which involves permission control during the information retrieval process. LightGPT has implemented field-level control of permissions, determining which fields can be accessed by which individuals.
However, if personal employee information is embedded in the large model, questions like “How much is Zhang San’s year-end bonus” may arise, which involves privacy issues, and the question could be posed by either Zhang San’s colleague or his boss. If it is a colleague or someone else asking, to protect employee privacy, the model should not respond; if it is the boss asking, the model should respond truthfully. So how should the large model differentiate how to answer this question?
First, it is not advisable to embed such information directly into the large model; it is better to store it as external data, then control access to this external data via the centralized control component, thereby achieving permission control for such questions.
3. Control of Generation Errors
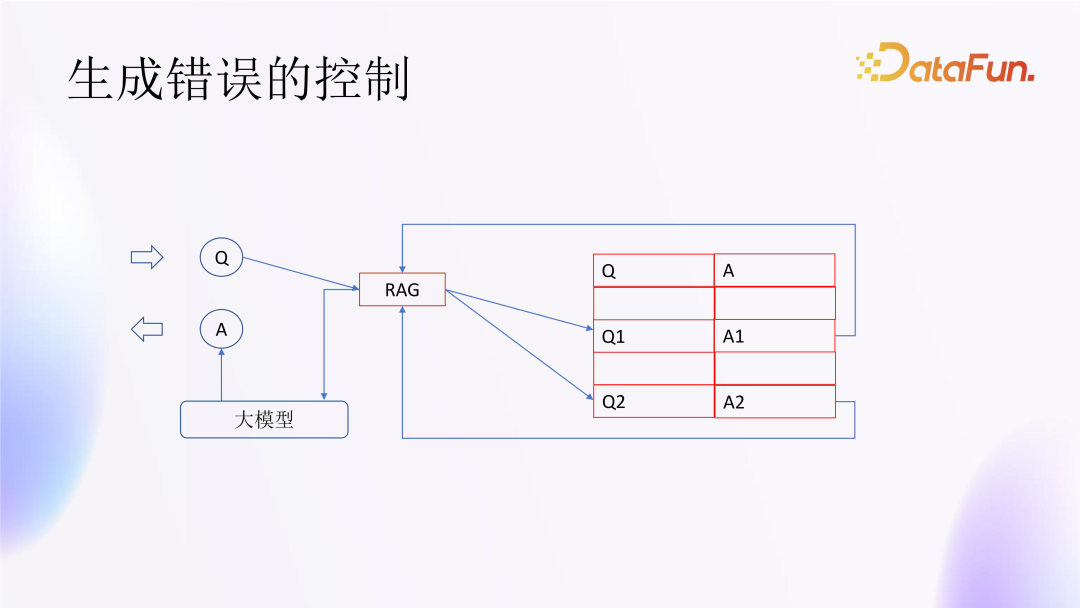
Generation errors are a common occurrence, especially in Q&A scenarios. Here, there are two different technical routes:
One approach is to input all FAQs into the large model for training, where the model often does not adhere strictly to the original FAQs and may improvise to some extent; however, excessive improvisation may lead to errors.
Therefore, it is recommended to use another technical route, which is to use RAG to control information retrieval and generation. RAG is a model that combines retrieval and generation, where the model first refers to previous standard questions and corresponding answers to select the most appropriate answer, thereby improving the relevance and accuracy of the responses.
Specifically, if Q1 is chosen, the corresponding A1 is the standard answer (similarly, if Q2 is chosen, A2 is the standard answer), rather than inputting Q1 and A1 into the large model and letting it generate based on a probabilistic model, as that would yield results that are difficult to control.
4. Responsibility Attribution for Generation Errors: Attribution Marking
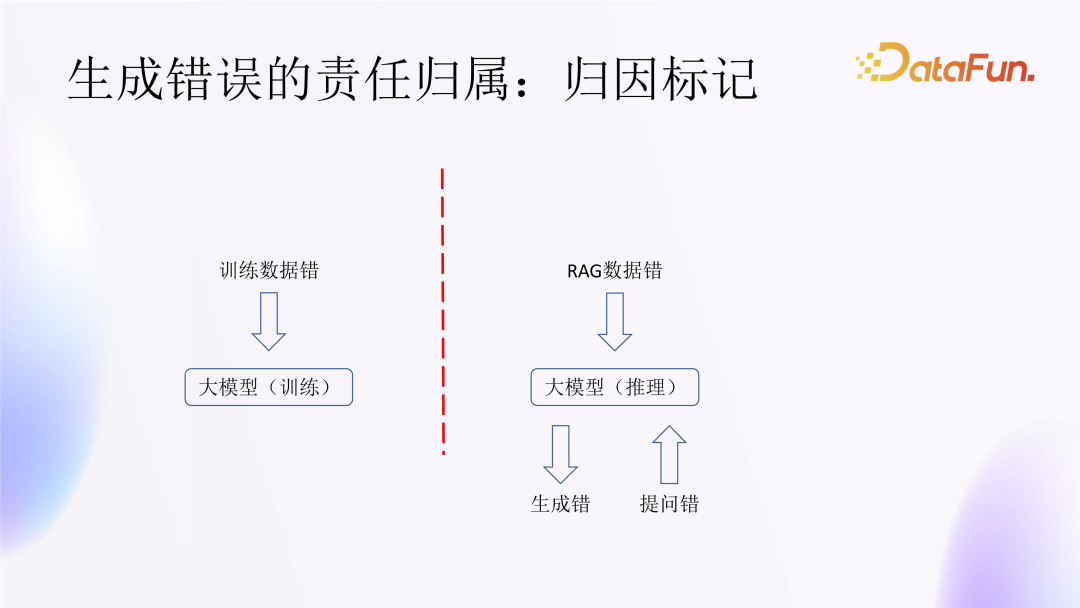
However, if an error occurs in the generated response, tracing back the error can be relatively complex, as the system composed of the large model and its plugins, along with surrounding resources, is very intricate and difficult to pinpoint.
In practice, generation errors in large models typically occur during the training phase or inference phase:
-
Errors occurring in the training phase are often caused by erroneous training data, thus necessitating the identification of erroneous training data. -
Errors occurring during the inference phase may be due to incorrect questioning or generation errors. For generation errors, the model should intercept or remedy the erroneous generated statements; For questioning errors, the model should assess the user’s initial intent and the appropriateness of the question, and employ additional measures to compensate. -
Additionally, the retrieval-enhanced system of the large model may also have data errors.
Thus, it is necessary to add attribution marking (i.e., generating log-like labels) to errors during the training process of the large model, which facilitates the identification of responsibility attribution afterwards.
5. Application Scenarios of Large Models

The application scenarios of large models can be divided into three categories: reconstruction, embedding, and native.
(1) Reconstruction
Reconstruction refers to empowering new applications with large models, i.e., using large models to bridge relevant resource links, converting tasks previously completed manually into those completed by large models.
For complex scenarios such as investment research and advisory, human participation is still required; however, the workload of humans will be significantly reduced, and efficiency will greatly increase.
In some scenarios, large models can completely replace humans, such as call center operators who require training and examinations before starting. During the examination process, examiners typically simulate various difficult clients to assess whether the operator can respond appropriately under challenging conditions. In such scenarios, personas can be preset, allowing the large model to assume the role of the examiner and simulate a picky client to assess the operator.
(2) Embedding
Embedding refers to integrating the capabilities of the large model Copilot into existing applications, thereby supporting a new interaction mode. For instance, traditional graphical interface interactions can be achieved through the large model combined with natural language, enabling users to accomplish functions through a single step instead of multiple menu clicks, effectively controlling numerous tasks with voice.
(3) Native
Native refers to the main functions of various AI agents that involve complex instructions with multiple steps, where each step targets different external resources, decomposing, arranging, and planning these resources, determining the execution order, and input/output to form a task pipeline for generalized execution, ultimately yielding results.
The above are three common application scenarios of large models, among which reconstruction and embedding types are relatively simple, with typical landing scenario cases already existing. However, in native scenarios, strong capabilities in task decomposition, planning, and execution are required, along with strong language comprehension, computational abilities, and resource interfacing capabilities, which are areas that need significant improvement in the future.
6. Development Paths and Reflections of Large Models
The development paths and reflections of large models can be summarized in the following phrases:
-
Start with text, expand to multimodal understanding -
Improvement of interaction & enhancement of R&D efficiency -
From copilot to agent
Large models have evolved from initial text comprehension to multimodal understanding, continuously improving interactive experiences and enhancing efficiency in scenarios such as R&D. Large models are gradually transitioning from a simple copilot to an agent capable of autonomously assigning, planning, and executing tasks.
Currently, the development of large models is at a critical crossroads between general vs. vertical, and model vs. centralized control.
Regarding general vs. vertical, I believe that if vertical models are trained based on public data and materials, then using general models directly during the pre-training phase is sufficient, as vertical models do not have a distinct advantage at this stage. In this case, model fine-tuning, i.e., optimizing the model’s resource interfacing with the scenario, becomes more important. We should stand on the shoulders of giants to avoid “reinventing the wheel.”
As for model vs. centralized control, I believe that the “centralized control” part currently has great potential, as it interfaces with models, applications, and public resources, and public resources refer to live data, which is timely, precise, and confidential. Therefore, efforts should be made to strengthen and enrich the “centralized control” part, arming application scenarios with greater intelligence as large models evolve, thereby enhancing business support capabilities.
04 Q&A
Q1: What are the four typical application scenarios of financial large models?
A1: Financial large models are mainly applied in four major scenarios: investment advisory, investment research, operations, and compliance.
Q2: Which scenario did financial large models first land in?
A2: I am more optimistic about the investment advisory and investment research scenarios. For investment advisory, it requires comprehensive utilization of live data. The use of live data also has “depth,” often requiring extraction and processing of common questions based on live data, as well as calculations of high-frequency indicators, which necessitate the use of large models to improve information processing efficiency. Hence, the investment advisory scenario has good development prospects. As for the investment research scenario, as an extension of basic capabilities in financial engineering, its value is not limited to research institutions, but also empowers asset management, risk control, and other fields, with its target audience extending beyond analysts to first-tier market investment banking, and even further extending to competitive analysis in the real economy and competitive landscape analysis. In summary, I am optimistic about the investment research and investment advisory scenarios, believing that large models can land first in these two scenarios.
That concludes this sharing session. Thank you, everyone.
Editor: Huang Jiyan
