As the research directions for large models become increasingly diverse, leading companies and research institutions in the industry have successively released a series of robotic/embodied large models. In particular, the recent release of RT-2 has once again shocked the industry media, as if the day when robots take over the world is not far off. Of course, increased media attention is a good thing for the industry, and it is an opportune time to sort out the paths for implementing large models in robotics and what kind of robotic/embodied large models we need.
We know that language and image large models (LLMs & VLMs) pre-trained on Internet-scale data possess strong capabilities in semantic understanding, content reasoning, image recognition, text/image generation, and code generation. These capabilities are crucial for general-purpose robots that need to perform various tasks in the real world. However, LLMs and VLMs do not perform well in the field of robotics. The main reason is that these models lack knowledge of the real physical world, making it difficult for their reasoning outputs to apply to actual robotic scenarios. Another reason is that existing large models primarily focus on semantic reasoning and text prompts, while robots require usable robotic motion commands, such as end-effector position commands or chassis movement position commands, which cannot be directly matched.
To address these implementation issues, researchers from different institutions and companies have conducted a series of works, some directly using the Transformer Model for end-to-end training, some fine-tuning LLMs directly using robotic skill datasets, some focusing on solving high-level decision-making problems for robots, some addressing three-dimensional trajectory planning issues, and some applying large models to low-level motion planning problems, producing a series of embodied large models.
This section will briefly introduce several mainstream grounding schemes represented by PaLM-E, RT-1, RT-2, RoboCat, and VoxPoser, and explore possible directions for the combination of large models and robotics.
There are many other robotics-related works and projects such as MOO, Gato, BC-Z, VC-1, R3M, VIMA, DIAL, AdA, CLIPort, Voltron, etc. Due to space limitations, they will not be elaborated here. Interested readers can check the homepage or read the papers for many ideas to draw from:
-
PaLM-E: PaLM-E: An embodied multimodal language model
-
SayCan: Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
-
RT-1: RT-1: Robotics Transformer for real-world control at scale
-
RT-2: RT-2: New model translates vision and language into action
-
RoboCat: Stacking our way to more general robots
-
VoxPoser: VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
-
ChatGPT for Robotics: ChatGPT for Robotics: Design Principles and Model Abilities
-
MOO: Open-World Object Manipulation using Pre-Trained Vision-Language Models
-
BC-Z: BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning
-
CLIPort: CLIPort: What and Where Pathways for Robotic Manipulation
-
VC-1: Where are we in the search for an Artificial Visual Cortex for Embodied Intelligence?
-
R3M: R3M: A Universal Visual Representation for Robot Manipulation
-
VIMA: VIMA: General Robot Manipulation with Multimodal Prompts
-
EmbodiedGPT: EmbodiedGPT: Vision-Language Pre-Training via Embodied Chain of Thought
-
Voltron: Language-Driven Representation Learning for Robotics
-
DIAL: Robotic Skill Acquisition via Instruction Augmentation with Vision-Language Models
-
Gato: A Generalist Agent
-
AdA: Human-Timescale Adaptation in an Open-Ended Task Space
Several Typical Robotic Large Models
PaLM-E: An Embodied Multimodal Language Model
To better transfer the capabilities and knowledge of image and language large models to the field of robotics, researchers combined Google’s then latest large language model PaLM with the state-of-the-art visual model ViT-22B,using text and other multimodal data (mainly from the robot’s sensors, such as images, robot status, scene environment information, etc.) instead of pure text as input, and outputting robot motion commands represented in text form, conducting end-to-end training, resulting in a multimodal large model for robotic tasks called PaLM-E (Embodied).
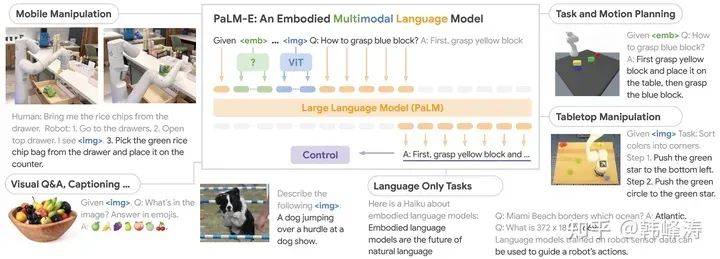
Overview of PaLM-E
The following figure succinctly illustrates the robotic operation capabilities of PaLM-E. For example, if the robot is given the text command: “Bring me the chips from the drawer,” the model will output the following robot motion commands:
-
Move to the side of the drawer;
-
Open the drawer;
-
Take the chips out of the drawer;
-
Bring the chips to the user;
-
Put down the chips;
-
Task completed;

PaLM-E has the capability to decompose and execute long-horizon tasks and demonstrates strong resilience against disturbances (such as human interference like moving or knocking over the chips).
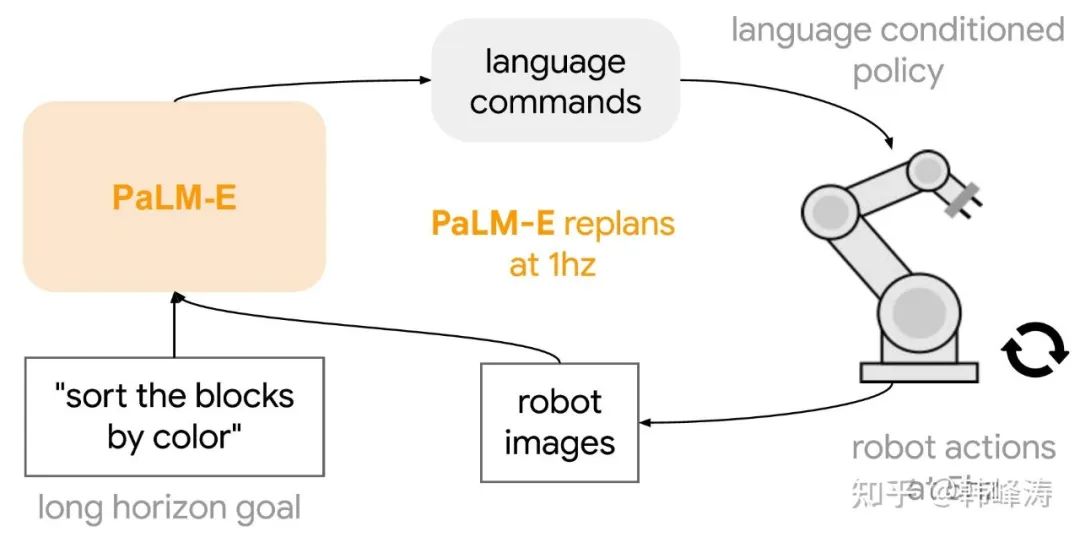
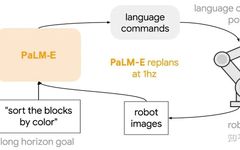
The task reasoning frequency of PaLM-E is 1Hz, while the robot executes low-level motions at a control frequency of 5Hz.
For more information about the robot execution part, you can refer to another work from Robotics@Google titled Talking to Robots in Real Time.
The greatest contribution of PaLM-E is that it demonstrates one path for transferring the knowledge of image and language large models to the field of robotics. With the general understanding and reasoning capabilities of large models, robots can better generalize their existing capabilities to new scenarios.
SayCan: Do As I Can, Not As I Say
As mentioned in the PaLM-E section above, large models can decompose high-level tasks into several semantically logical subtasks. However, due to the general lack of real-world experience in LLMs, they cannot determine what impact their outputs will have on the environment and do not know the state information of the real environment and the robot, nor whether the robot has the capability to execute these subtasks.Therefore, the seemingly logically reasonable subtask commands generated may not necessarily be executed successfully by the robot in some actual scenarios.
For example, for the task “I spilled sunflower seeds on the ground; can you help clean it up?” the large model outputs “use a vacuum cleaner” is logical, but the robot executing this task may not yet know how to use a vacuum cleaner, or even worse, there may not be a vacuum cleaner in the house at all.
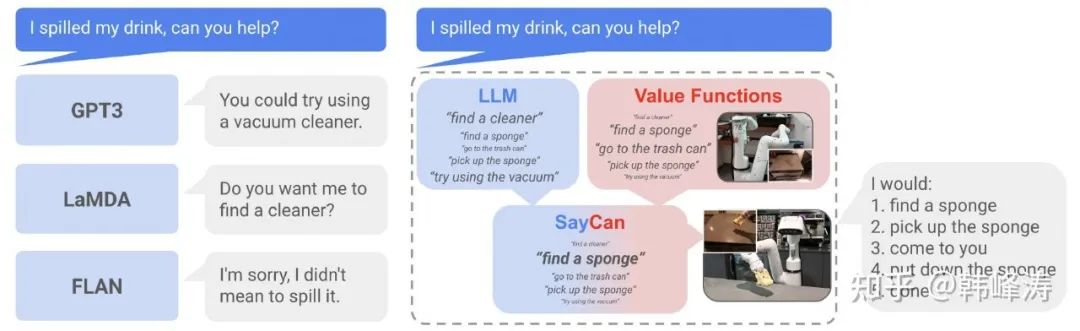
SayCan combines the task decomposition capability of large models with the actual executable tasks of robots for planning and control.
Therefore, the design logic of SayCan is simple: it divides the decision-making process of how the robot should execute the task into two parts. “Say” represents the large model LLM, which outputs usable high-level motion commands, while “Can” represents what the robot can do in the current environment. The two are combined through a value function to jointly determine which command to choose for actual execution.

Flowchart of SayCan’s decision-making process
As shown in the figure above, when the robot system is given the input “How do you place the apple on the table?”, for this task, the most likely motion output sequence from the large model (Say) is:
-
Pick up the apple;
-
Put down the apple;
-
Find the apple;
However, for the robot (Can), by scanning around with sensors (camera), it finds there is no apple nearby to pick up. Therefore, the first motion command output by the large model “Pick up the apple” cannot be executed. Thus the robot’s output motion sequence is:
-
Find the apple;
-
…
Combining the LLM output with the value function (VF), the final output of the SayCan system is the first command “First find the apple,” avoiding instructing the robot to pick up the apple when there is none nearby, which would result in failure to complete the task.
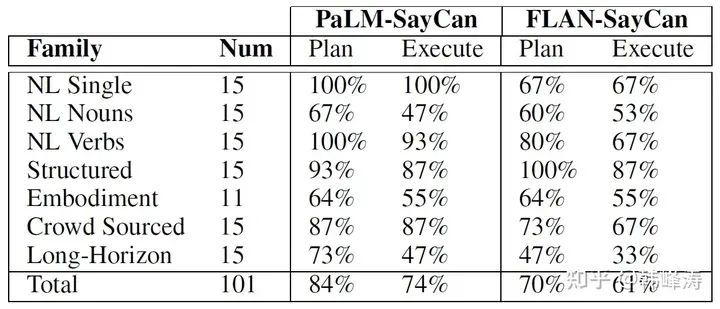
PaLM 540B vs FLAN 137B, all sub-test results of PaLM-SayCan are better than FLAN-SayCan.
Additionally, during the SayCan experimental process, researchers reached a similar conclusion, that the growth of model capabilities leads to improvements in the overall robot system capabilities.
RT-1: Robot Transform – 1
RT-1 is an end-to-end control model for robots developed by researchers from Robotics@Google and Everyday Robots in 2022, with the following main features:
-
A Transformer-based model that includes a FiLM-conditioned EfficientNet for processing image and text inputs to obtain vision-language tokens, followed by a TokenLearner to compress the number of tokens input to the Transformer model to enhance inference speed, and a Transformer model;
-
Trained using imitation learning, with natural language and images as input, outputting robot motion commands (chassis position and end-effector position);
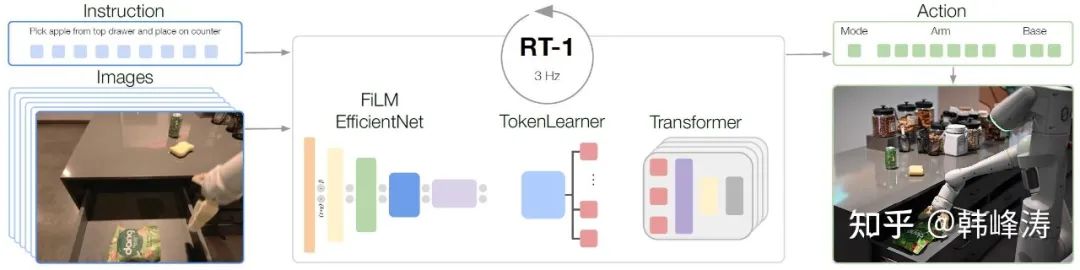
RT-1 uses natural language and images as input, outputting discrete actions for the robotic arm and chassis (position and posture).
RT-1 studies two things,first, how to learn the skills of robots through the Transformer Model, and second, how to control the robot’s movements using natural language.
The research team of RT-1 articulated a meaningful point:
When it comes to robotics, usefulness is determined not just by what robots can do, but also how we tell them to do it — for example, how we instruct a helper robot to clean up a cup of spilled coffee. That’s where natural language understanding comes into play.
Especially the part about “How we tell the robot to do it” highlights the importance of the human-robot interface. A robot can have many powerful skills, but if it is difficult to use and deploy, we cannot say that this robot is useful.
RT-1 is not a large model in the traditional sense; it mainly uses the Transformer architecture, with a total parameter count of only 35M, and the parameter count of the Transformer part is only 19M. It is a multi-task robotic control model trained specifically for robotic operations.
Additionally, an important outcome of RT-1 is the 17-month data collection of robot operations. The author team used a fleet of robots for this purpose, which actually consisted of only 13 robots. The entire data collection process was conducted using manual remote operation demonstrations. Ultimately, a dataset containing over 700 tasks and more than 130,000 execution segments was obtained. This dataset has also been applied to the training of multiple embodied large models.
The previously mentioned SayCan uses large models for task understanding and decomposition (what the Google team calls High-Level), breaking down a task into several subtasks (Sub-tasks) or skills (Skill), while RT-2 uses large models for skill learning (Skill, Low-level), with the learned skills supporting SayCan’s task execution.
RT-2: Robot Transform – 2
After the release of RT-1, the team found that it had poor generalization capabilities and was stumped when encountering unseen tasks (including objects and environments). However, if they continued to rely on manual demonstrations to create more datasets to retrain RT-1’s model, it would be a time-consuming and inefficient task. So, is there a better way for robots to quickly acquire better generalization capabilities for common-sense tasks?
By using large models!
VLM + RT-1 Dataset = RT2
https://www.zhihu.com/video/1670585001732251648
Thus:
We study how vision-language models trained on Internet-scale data can be incorporated directly into end-to-end robotic control to boost generalization and enable emergent semantic reasoning.
The purpose of RT-2 is to explore how to directly use VLM large models trained on Internet-scale data for end-to-end robotic control, enhancing the robot’s operational generalization and semantic reasoning capabilities.
RT-2 abandons the method of training a Transformer model from scratch and instead directly adopts an existing VLM model as the main model, followed by fine-tuning it with methods more suitable for robotic tasks. In simple terms,RT-2 uses robotic datasets for fine-tuning and its output text is designed in the form of robot position commands (PaLM-E, PaLI-X).
Furthermore, to better fit robotic applications, RT-2 primarily studies how to leverage the advantages of large models to directly generate low-level robot motion command content.
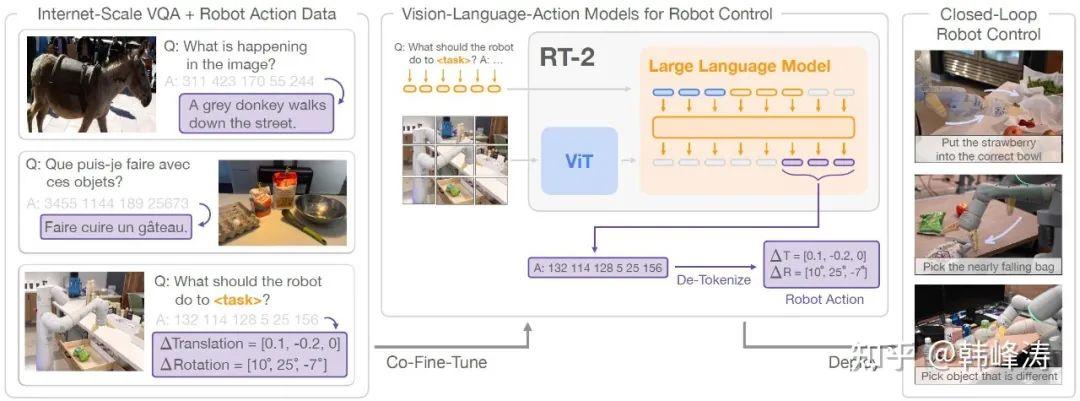
Using web data and robotic datasets for co-fine-tuning of existing VLM large models, and designing the model’s output in the format of robot target positions.
Of course, to prevent the performance of the original VLM model from degrading, the fine-tuning phase simultaneously used both the original web data and the robotic operation dataset for training, which the authors referred to as co-fine-tuning (this point is personally believed to be not particularly critical and relatively easy to think of and implement).
RT-2 demonstrates that fine-tuning existing LLMs or VLMs with robotic skill datasets can quickly leverage the vast general knowledge of VLMs, significantly improving the success rate and generalization capability of robotic task execution.
Other so-called actions in VLA are more about innovative points in terms of publication, one reason being that directly generating robot actions is not exclusive to RT-2; RT-1 is also an Action-Generation Model, and its model output format is also robot position commands (The RT-1 Robotics Transformer is a simple and scalable action-generation model for real-world robotics tasks.);
Secondly, the actions generated by RT-2 only represent the expected positions (Position) and postures (Orientation) of the end of the robotic arm. In traditional robotic control, this is at most an application-level API, and it doesn’t even count as a typical Low-Level API (for detailed explanations, refer to the third section of this article regarding High-Level and Low-Level content).
Additionally, since the backbone model of RT-2 is PaLM-E 540B, it cannot run on the robot’s hardware and can only be deployed in the cloud, while RT-1 can run directly on the robot.
RoboCat: Robotic Cat?
One of the main challenges currently facing the training of large robotic models/embodied large models is the severe lack of high-quality training data.Most of the data used in RT-1, RT-2, and PaLM-E was collected through manual demonstrations and remote operations, which is time-consuming and inefficient. If some method could automatically generate training data for robots, it would undoubtedly save a lot of time and labor costs.
RoboCat is based on DeepMind’s latest multimodal general large model Gato (which means “cat” in Spanish) and can achieve scene recognition, task reasoning decomposition, and robot control functions similar to the previously mentioned robotic large models/embodied large models. One significant innovation is that instead of requiring extensive manual remote operation demonstrations to provide the robotic dataset,RoboCat can enhance its capabilities more quickly by generating its own robotic training datasets.
The entire process begins with a series of robotic datasets to train the Gato model in the first round, followed by what the authors refer to as a self-improvement training phase, which includes a series of tasks that the robot has not encountered before. The entire learning process involves five steps:
-
For each new task or new robotic arm, manually control the robotic arm to collect 100-1000 demonstration processes;
-
Fine-tune RoboCat for the new task/robot to generate a new branch;
-
The newly generated branch practices the new task/robot for 10,000 times, generating more training data;
-
Merge the manually demonstrated data with the data generated by the robot into RoboCat’s existing dataset;
-
Use the latest dataset to train a new version of RoboCat;
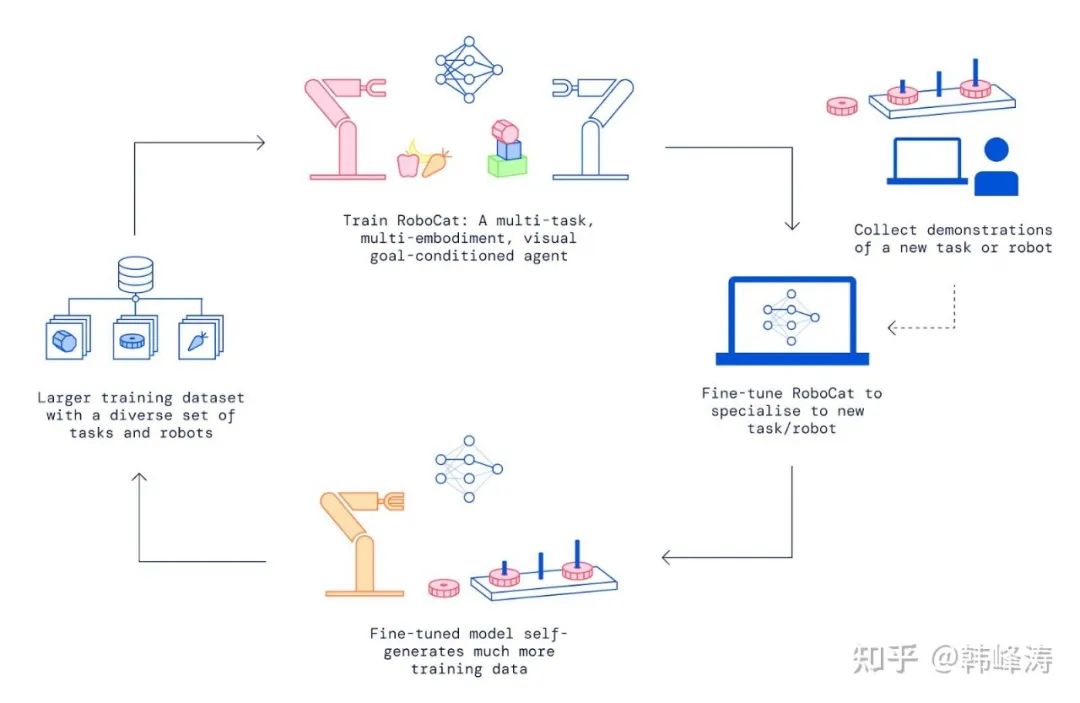
First, establish the basic capability for new tasks through hundreds of manual demonstrations, and then accelerate skill learning speed through robot-generated training data.
In a lengthy 50-page paper, the RoboCat team studied how to support multiple robots within a single model, the effects of skill transfer between multiple tasks, the effects of skill transfer across robots, the effects of sim-to-real transfer, how model architecture and parameter scaling affect model performance, etc. If you have time, I recommend reading it carefully.
This method of automatically generating large amounts of training data through robots is somewhat reminiscent of Doraemon pulling out many treasures from his pocket dimension.
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
Several robotic large models from Google tend to focus on task understanding, decomposition, and logical reasoning, while involving less on the actual motion control itself, especially planning issues, only generating simple and discretely distributed commands for the end-effector position and chassis movement through end-to-end training, without considering continuous path and trajectory planning, which are more related to the field of robotics.
VoxPoser significantly differs from the previous methods in that it does not use LLMs and VLMs for the common input text + image output robot motion end-to-end control method, but rather utilizes the capabilities of VLMs to convert the robot’s observation space (generally three-dimensional space and the objects to be manipulated) into a 3D value map, which can then use mature path search algorithms (VoxPoser uses the Probabilistic RoadMap) to search for and generate usable robot motion paths.With a usable path, trajectory planning and controlling robot movements become relatively well-solved problems in the current robotics field (though VoxPoser does not delve into more high-performance trajectory planning discussions).
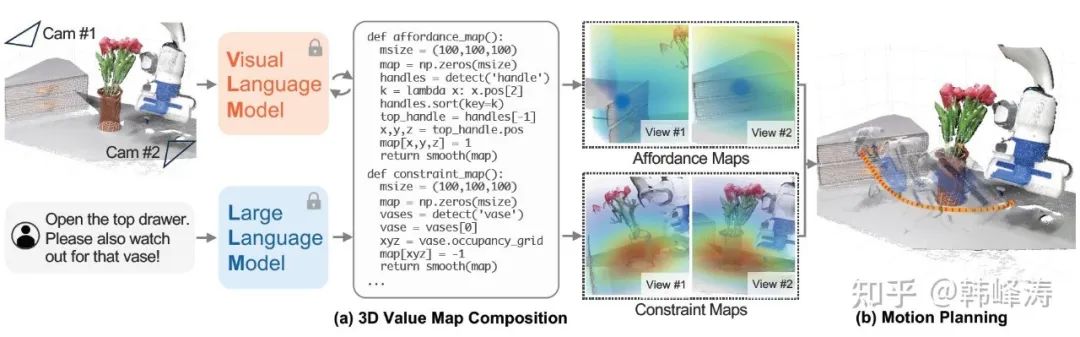
Overview of VoxPoser
As shown in the above figure, given the RGB-D information of the work environment and language instructions, the code generation capabilities of LLMs are utilized to interact with VLMs to generate a series of 3D affordance maps and constraint maps (collectively referred to as value maps) for the robot’s observation space, and the combined value maps are then used for robot path planning. The entire process does not introduce any additional training.
Overall, VoxPoser’s approach is closer to traditional robotic thinking, i.e., given a usable working and configuration space, using relatively mature and controllable path planning methods based on random sampling for planning, rather than leaving almost all tasks to the large model.
I believe that this combination of various technological advantages is currently a relatively good research direction and is likely to be the most suitable and feasible direction for implementation.
How Robotic Are Robotic Large Models?
This section discusses how robotic the current embodied large models/robotic large models are.
Is It All About Grasping?
The current state of large models in the field of robotics can be summarized as follows:
-
Understanding what things are, their size, shape, temperature, color, and basic operations on these objects such as picking up/throwing/moving (not considering precision and performance metrics), and performing simple mathematics and logic reasoning to advance tasks.
-
Although they are classified as manipulation in papers, they are still very primitive and far from conventional operational understanding (from screwing screws to assembling IKEA furniture). For example, RT-2 demonstrated some failure cases, such as when moving a pen, it did not consider that a round pen would roll and that the control cycle was too slow to respond quickly to the pen’s motion; when moving a banana, it did not consider the center of gravity of the elongated object, resulting in the robot being unable to achieve the desired motion when pushing the banana.

Two unsuccessful cases of RT-2, mainly due to a lack of consideration for physical information during operations.
In summary, large models perform very poorly in the following scenarios:
-
Grasping objects by specific parts, such as door handles, which involves general grasping issues;
-
New actions not seen in the robotic dataset, or learning how to use new tools, involving generalization and zero-shot issues;
-
Scenarios requiring dexterity and precision, most skilled actions fall into this category;
-
Scenarios requiring multi-layer indirect reasoning, which is limited by the capabilities of large models;
Regarding the third issue, an important factor is that simply providing robots with text and images is insufficient for them to learn many specialized skills, including simple actions like writing with a brush on a two-dimensional plane or carving, to more complex actions and force interactions.
Recently, while learning to swim, I realized the importance of practice. Despite watching swimming tutorials and videos on Bilibili, I deeply understand that without diving in and training hard, you cannot learn to swim, no matter how many swimming materials and videos you watch. Only by actually getting into the water and experiencing the coach’s advice on “feeling the interaction between water and body” can one gradually learn.
Similarly, robots can learn actions through text, images, and videos, but they cannot become carving masters through images alone, as much of the experiential knowledge related to physical interactions cannot be expressed through text and images.
High-Level and Low-Level
There are many classifications of control levels in robotics, and to avoid confusion, I will provide a brief explanation here regarding the differences between the low-level control interfaces mentioned in many large model papers and the traditional low-level interfaces in robotic control.
For ease of understanding the intersections of large model papers and robotics, I will categorize control levels into five levels:
-
Task Level: Can you help me with my spilled coffee?
-
Skill Level: Find the cloth, pick up the cloth, move the cloth, put down the cloth;
-
Motion Level: Linear motion, arc motion, spline curve motion, hand opening and closing;
-
Primitive Level: Control commands generated after trajectory planning based on actions and physical constraints of the robot, including target positions, posture, feedforward velocities, and torque, typically requiring at least a 500Hz cycle, with common control cycles now exceeding 1000Hz. For force control, this cycle generally returns to 2000-4000Hz;
-
Servo Level: Position, velocity, and current three-loop control running in servo drivers;
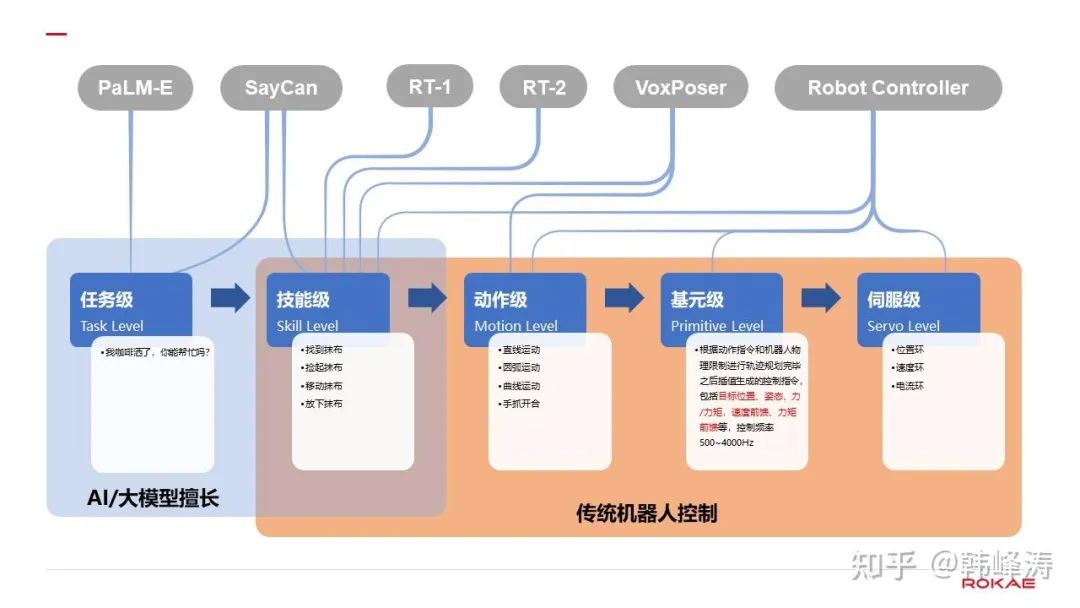
Control levels of mainstream robotic large models
In a series of articles from Google, the High-Level refers to the task level, while the Low-Level refers to the skill level. In traditional robotic control, the definition of Low-level is generally at the motion level, often at the primitive level.
Large models are not suitable for precise low-level motion control; in fact, there are mature model-based methods available, and there is no urgent need to introduce new methods. Furthermore, from the actual published results, it is evident that large models are not suitable for precise motion control. Currently, almost all embodied large models output discrete target position points, without considering additional factors such as the smoothness of continuous motion trajectories, time optimization, or energy consumption. Although VoxPoser considers the concept of path generation, it does not delve deeply into subsequent trajectory planning (the trajectory part can be addressed by replacing the underlying interface with a more complete and higher-performing robot). If one observes these models’ generated control trajectories, they will notice that the robots move intermittently, reminiscent of the lag experienced in online gaming.

I’m lagging!
Real-time
Another point of difference is the definition of real-time.
RT-1 and RT-2’s so-called real-time can only achieve an inference and control command generation rate of 1-5Hz; here, real-time is more suitable for the online planning concept of robots, that is, generating new control commands based on feedback in real-time.
In contrast, real-time in robotic control is not related to frequency and control cycles. The strict definition of a real-time system is “a system that can complete its functions within a specified or determined time and respond to external or internal, synchronous or asynchronous events,” where the correctness of the system depends not only on the logical results of the system’s computation but also on the time at which this result is produced. The so-called “Later answer is wrong answer” indicates that real-time in motion control is a concept of high determinism within a time range, not a concept of high frequency.
Of course, from the perspective of control accuracy and smoothness requirements, the control frequency for robotic low-level real-time control is indeed high, generally requiring position control frequencies to exceed 500Hz, with force control typically exceeding 2000Hz.
To God What Is God’s, To Caesar What Is Caesar’s
From the current research content, we can observe an interesting phenomenon: engineers with an AI background and those with a robotics background differ in their approach to large models. Engineers with an AI background attempt to create a universal robotic AI system with super generalization capabilities, completing the entire process of perception-decision-planning-control required for robots; while those with a robotics background tend to view large models more as tools, hoping to use systems with certain general intelligence to help robots quickly learn specific skills.
Can large models significantly enhance robots’ understanding of the world and skill generalization capabilities? Yes.
Can large models solve mainstream robotics professional skill learning issues? It’s difficult.
From the perspective of specific robotic skill learning, training a small model based on a mathematical model or for specific applications (which must involve manual demonstrations and active interventions) is likely to be more suitable, efficient, and effective than using a pre-trained large model plus fine-tuning.
For example, generating robot movements based on images is most commonly directed in the field of robotics through visual servoing. Compared to the Parkinsonian movements generated by the large models mentioned earlier, traditional AI and model-based methods can achieve much smoother and usable motion control effects with significantly less computational load:
GuideNOW from inbolthttps://www.zhihu.com/video/1671686448007868416
Therefore, the role of large models in robotics remains primarily in decision-making, task decomposition, and common-sense understanding. Large models do not possess, nor are they suitable for, planning and control tasks that require real-time and precision.Large models are responsible for common sense, decision-making, and reasoning, while model control + expert knowledge is responsible for professional skills. Each takes charge of what they are best at, and combining them is currently seen as a relatively quick path to implementation.
Additionally, large models are very suitable for handling corner cases, as small models trained on specific scenarios cannot cover all situations exhaustively. This work can be handled by the general understanding and strong generalization and reasoning capabilities of large models.
From the perspective of robotic applications, large models are accelerators and tools, not the end goal.
Currently, the combination of large models and robotics is still in a stage of competitive upgrading, where introducing a new method or applying an old method to a new scenario yields impressive results and influential papers. However, we must return to the essence, to the most important role of large models in robotics: large models are responsible for common-sense abilities, while traditional robotic control methods are responsible for professional skills. This is also the most promising direction for large models in robotics. For detailed content, refer to the previous article on robotics and large models in the “Task-level Interaction” section, which will not be elaborated on here.
Original link:https://zhuanlan.zhihu.com/p/647519538?utm_medium=social&utm_oi=604410560939560960&utm_psn=1671977362429431808&utm_source=wechat_session&wechatShare=1&s_r=0
Source: Zhihu ID @Han Fengtao