Click on the above “AI Youdao“, select “Star” public account
Heavyweight content delivered first time
Author | Raimi Karim
Translator | Major
Editor | Zhao Xue
Produced by | AI Technology Camp (ID: rgznai100)
Introduction: In recent years, many Convolutional Neural Networks (CNN) have come into the spotlight, and as their depths become increasingly profound, it is difficult to have a clear understanding of the structure of a certain CNN. Therefore, this article carefully selects detailed illustrations of 10 CNN architectures for discussion.
How do you track different CNNs? In recent years, we have seen many CNNs emerge. These networks have become so deep that visualizing the entire model has become extremely difficult. We treat them as black box models.
Perhaps you don’t think this way. However, if you do encounter such problems, this article is exactly what you need to read. This article is an illustrated overview of 10 common CNN architectures, carefully selected by the author. These illustrations showcase the essence of the entire model without having to browse through those Softmax layers one by one. In addition to these diagrams, the author also provides some annotations explaining how they have evolved over time—convolutional layers from 5 to 50, from ordinary convolutional layers to convolutional modules, from 2-3 towers to 32 towers, and convolution kernels from 7×7 to 5×5.
The term “common” refers to these models whose pre-trained weights are usually shared by deep learning libraries (such as TensorFlow and PyTorch), available for developers to use, and these models are often taught in classes. Some of these models have achieved success in competitions (such as ILSVRC ImageNet Large Scale Image Recognition Challenge).
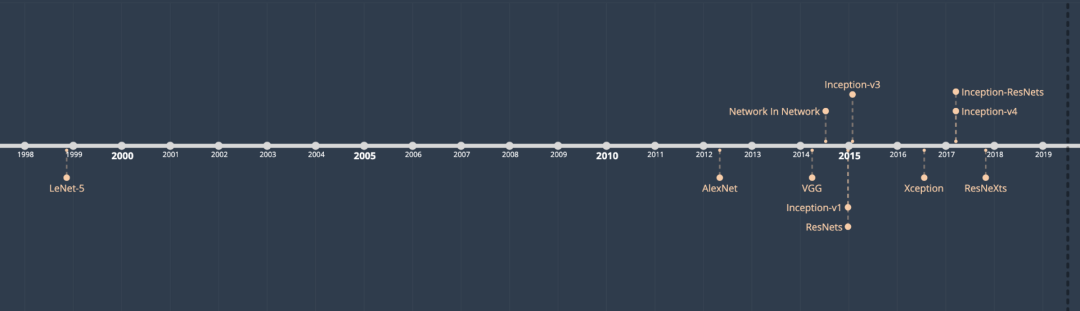
10 architectures to be discussed and the corresponding paper publication time
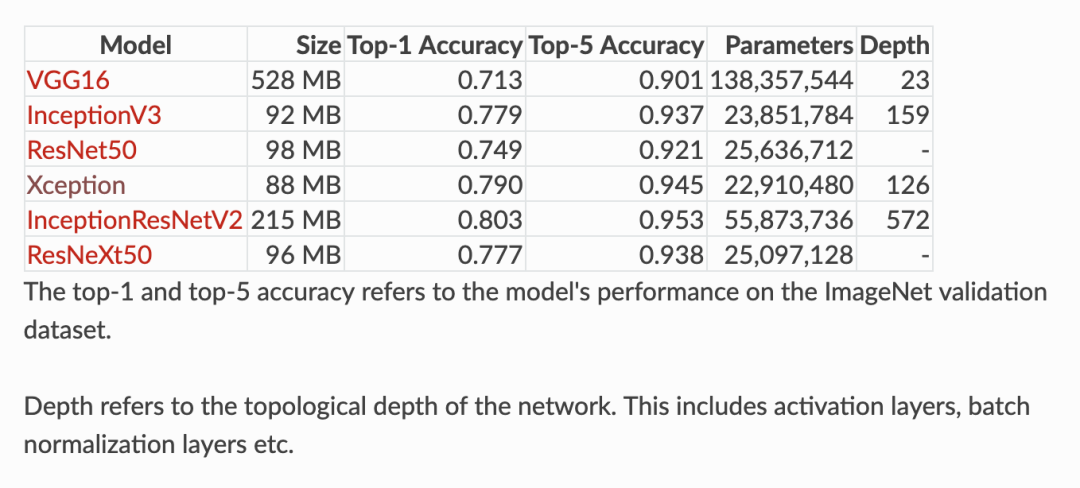 6 network architectures’ pre-trained weights can be obtained in Keras, see https://keras.io/applications/?source=post_page
6 network architectures’ pre-trained weights can be obtained in Keras, see https://keras.io/applications/?source=post_page
The reason for writing this article is that there are not many blogs and articles mentioning these compact structural illustrations. Therefore, the author decided to write one as a reference. For this purpose, the author read the papers and codes mentioned in this article (most of which are TensorFlow and Keras) and obtained these results. It should also be noted that the sources of these CNN architectures are varied—improvements in computer hardware performance, the ImageNet competition, solutions to specific problems, new ideas, etc. A researcher at Google, Christian Szegedy, once mentioned:
“This process is largely not just due to stronger hardware, larger datasets, and larger models, but a series of new ideas, algorithms, and improvements in network structures.”
Now let’s take a look at how these “beast-like” network architectures have gradually evolved.
[Author’s Note] Note on Visualization:Please note that in these illustrations, the author has omitted some information, such as the number of convolution filters, Padding, Stride, Dropout, and flatten operations.
Table of Contents (Sorted by Publication Time)
-
LeNet-5
-
AlexNet
-
VGG-16
-
Inception-v1
-
Inception-v3
-
ResNet-50
-
Xception
-
Inception-v4
-
Inception-ResNets
-
ResNeXt-50
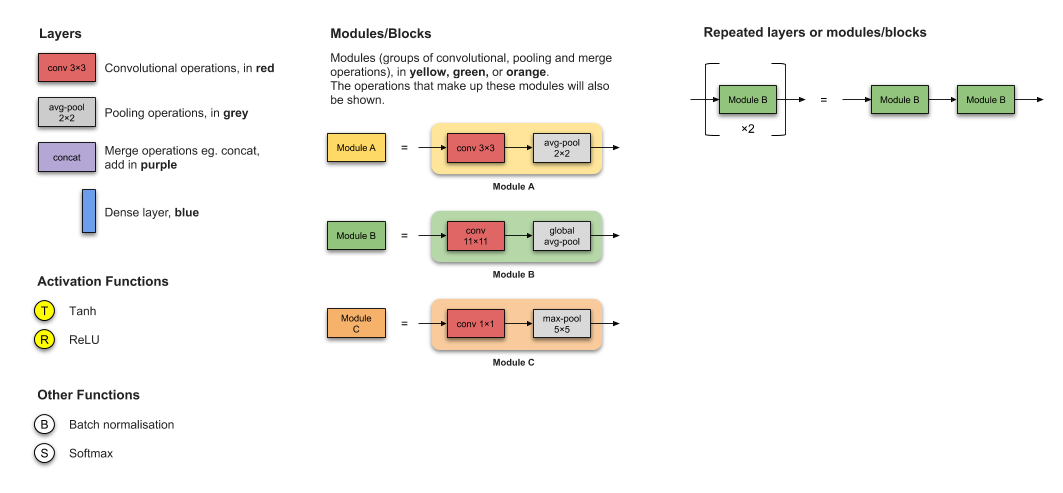
Legend
1. LeNet-5 (1998)
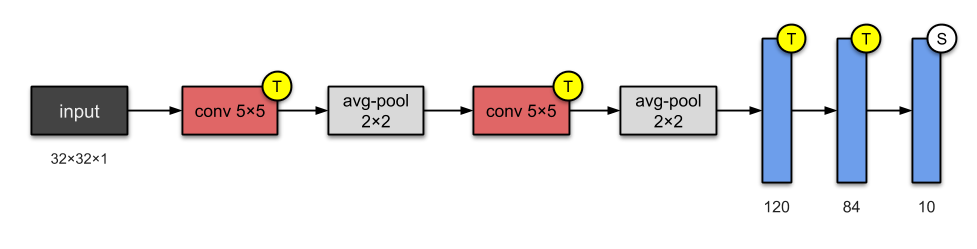 Figure 1: LeNet-5 Network Structure
Figure 1: LeNet-5 Network Structure
LeNet-5 is one of the simplest network architectures. It has 2 convolutional layers and 3 fully connected layers (a total of 5 layers, this naming convention is common in neural networks, where this number represents the total of convolutional and fully connected layers). The Average-Pooling layer, now referred to as the subsampling layer, has some trainable weights (which are now not commonly seen when designing CNN networks). This network architecture has about 60,000 parameters.
What Innovations Are There?
This network architecture has become the standard “template”: stacking convolutional and pooling layers, with one or more fully connected layers at the end of the network.
Related Literature
-
Paper: Gradient-Based Learning Applied to Document Recognition
Link:http://yann.lecun.com/exdb/publis/index.html?source=post_page
-
Authors: Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner -
Published in: Proceedings of the IEEE (1998)
2. AlexNet (2012)

Figure 2: AlexNet Network Structure
AlexNet has 60 M parameters and a total of 8 layers: 5 convolutional layers and 3 fully connected layers. AlexNet simply stacked more layers on top of LeNet-5. When the paper was published, the authors pointed out that their network architecture was “one of the largest convolutional neural networks for the current ImageNet subset.”
What Innovations Are There?
1. Their network architecture was the first CNN to use ReLU as the activation function;
2. The use of overlapping pooling in CNN.
Related Literature
-
Paper: ImageNet Classification with Deep Convolutional Neural Networks Link:https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks?source=post_page -
Authors: Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton. University of Toronto, Canada. -
Published in: NeurIPS 2012
3. VGG-16 (2014)

Figure 3: VGG-16 Network Structure
You should have noticed that CNNs are becoming deeper and deeper. This is because the most direct way to improve the performance of deep neural networks is to increase their scale (Szegedy et al.). The Visual Geometry Group (VCG) researchers invented VGG-16, which has 13 convolutional layers and 3 fully connected layers, inheriting the ReLU tradition from AlexNet. It consists of 138 M variables and occupies 500 MB of storage space. They also designed a deeper version, VGG-19.
What Innovations Are There?
-
As they mentioned in the paper abstract, the contribution of this paper is to design deeper networks (about twice the depth of AlexNet).
-
Paper: Very Deep Convolutional Networks for Large-Scale Image Recognition Link: https://arxiv.org/abs/1409.1556?source=post_page -
Authors: Karen Simonyan, Andrew Zisserman. University of Oxford, UK. -
Published in arXiv preprint, 2014
4. Inception-v1 (2014)
-
Using parallel convolution towers with different filters, then stacking them, using 1×1, 3×3, 5×5 convolution kernels to identify different features and cluster them. This idea is inspired by the paper by Arora et al. “Provable bounds for learning some deep representations”, suggesting a layer-wise construction approach that allows for analyzing the relevant statistics of the last layer and clustering them into groups of highly correlated units. -
1×1 convolution kernels are used for dimensionality reduction to avoid computational bottlenecks. -
1×1 convolution kernels add non-linearity within a convolution. -
The paper’s authors also introduced two auxiliary classifiers to expand the differences in the final stage of the classifier, increasing the backpropagation grid signal and providing additional regularization. The auxiliary networks (branches connected to the auxiliary classifiers) are discarded during inference.
Author’s Note:The naming of the modules (Stem and Inception) was not proposed in this version of the Inception network architecture and was officially used only in later versions, namely Inception-v4 and Inception-ResNet. The author included these here for easier comparison.
-
Using compact modules to build networks. Instead of stacking convolution layers, stacking modules composed of convolution layers. The name Inception comes from the sci-fi film “Inception”.
-
Paper: Going Deeper with Convolutions Link: https://arxiv.org/abs/1409.4842?source=post_page -
Authors: Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich. Google, University of Michigan, University of North Carolina -
Published in: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
5. Inception-v3 (2015)
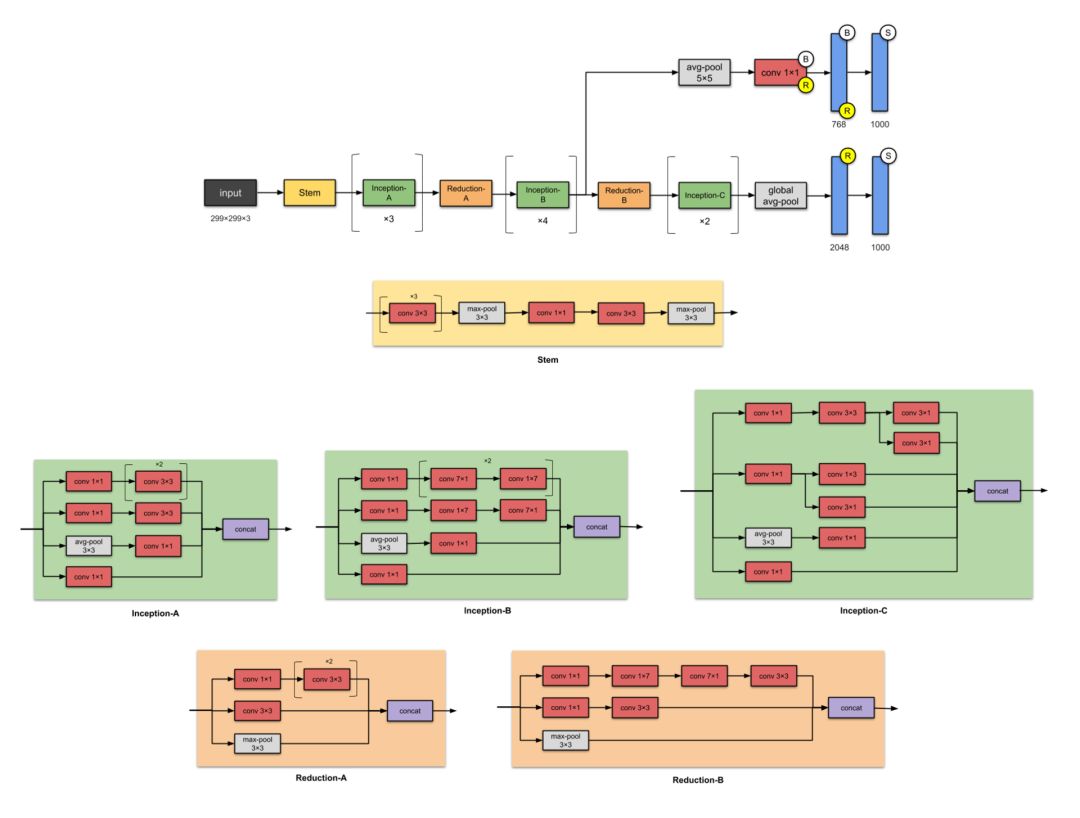
The naming of the modules (Stem and Inception) was not proposed in this version of the Inception network architecture and was officially used only in later versions, namely Inception-v4 and Inception-ResNet. The author included these here for easier comparison.
-
One of the designers of batch normalization (not reflected in the diagram for simplification).
-
Decomposing n×n convolutions into asymmetric convolutions 1×n and n×1 convolutions. -
Decomposing 5×5 convolutions into 2 3×3 convolution operations. -
Replacing 7×7 convolutions with a series of 3×3 convolutions.
-
Paper: Rethinking the Inception Architecture for Computer Vision Link: https://arxiv.org/abs/1512.00567?source=post_page -
Authors: Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, Zbigniew Wojna. Google, University College London -
Published in: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
6. ResNet-50 (2015)
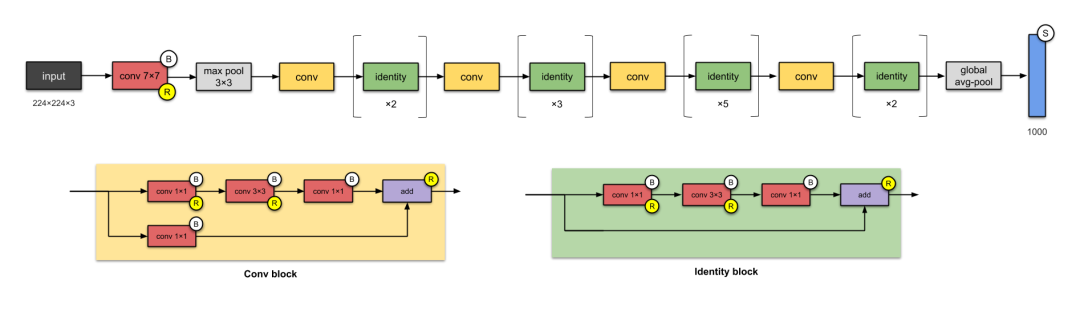
-
Avoiding the use of fully connected layers (they are not the first to do this). -
Designing deeper CNN networks (up to 152 layers) without losing the generative capability of the network. -
One of the first network architectures to adopt batch normalization.
-
Paper: Deep Residual Learning for Image Recognition Link: https://arxiv.org/abs/1512.03385?source=post_page -
Authors: Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Microsoft -
Published in: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
7. Xception (2016)
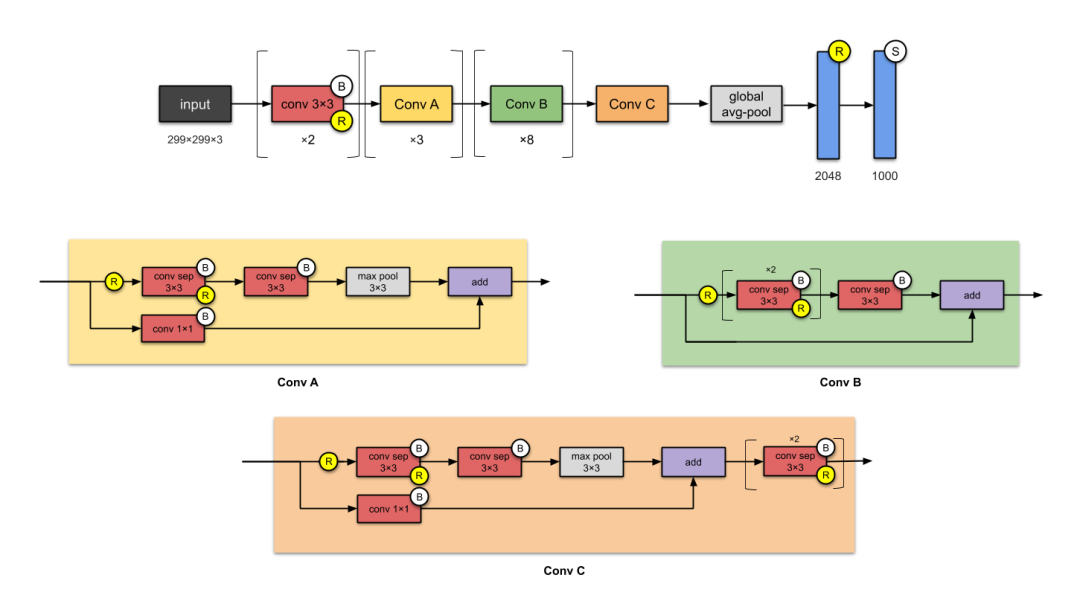
Figure 7: Xception Network Structure. Note: Depthwise separable convolution is referred to as conv sep.
Xception is an application of the Inception network structure, where the Inception modules are replaced with depthwise separable convolutions. It has a roughly equivalent number of parameters to Inception-v1 (23M).
Xception adopts the eXtreme Inception hypothesis:
-
First, cross-channel (or cross-feature map) correlations can be detected by 1×1 convolutions.
-
Therefore, the spatial correlations of each channel can be detected by regular 3×3 or 5×5 convolutions.
Pushing this idea to the extreme means performing 1×1 convolutions for each channel and 3×3 convolutions for each output. This is equivalent to replacing the Inception modules with depthwise separable convolutions.
What Innovations Are There?
-
Fully based on depthwise separable convolution layers, introducing CNN.
Related Literature
-
Paper: Xception: Deep Learning with Depthwise Separable Convolutions
Link: https://arxiv.org/abs/1610.02357?source=post_page
-
Authors: François Chollet. Google.
-
Published in: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
8. Inception-v4 (2016)
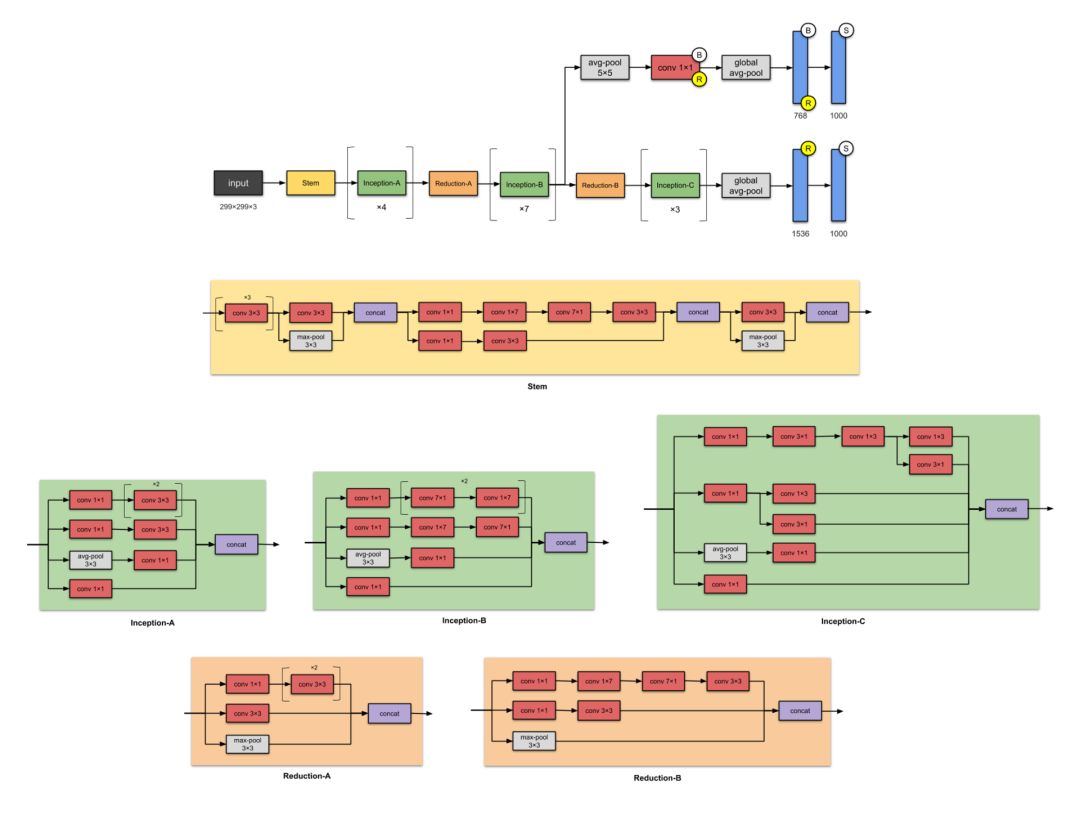
Figure 8: Inception-v4 Network Structure. This CNN has two auxiliary networks (which are discarded during inference). Note: Batch norm and ReLU activation are used after all convolution layers.
Google researchers proposed Inception-v4 again (43M parameters). This is an improvement over Inception-v3, with the main differences being the Stem group and minor modifications to the Inception-C module. The authors of the paper also mentioned that “adding Uniform selection to the Inception blocks of each grid size can significantly speed up training.”
In summary, it is noteworthy that the paper mentions Inception-v4 performs better due to the increase in model size.
What Improvements Are There Compared to the Previous Inception-v3 Version?
-
Changed the Stem module.
-
Added more Inception modules.
-
Adopted the Uniform selection in Inception-v3, meaning the same number of filters were used in each module.
Related Literature
-
Paper: Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
Link: https://arxiv.org/abs/1602.07261?source=post_page
-
Authors: Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi. Google.
-
Published in: Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence
9. Inception-ResNet-V2 (2016)
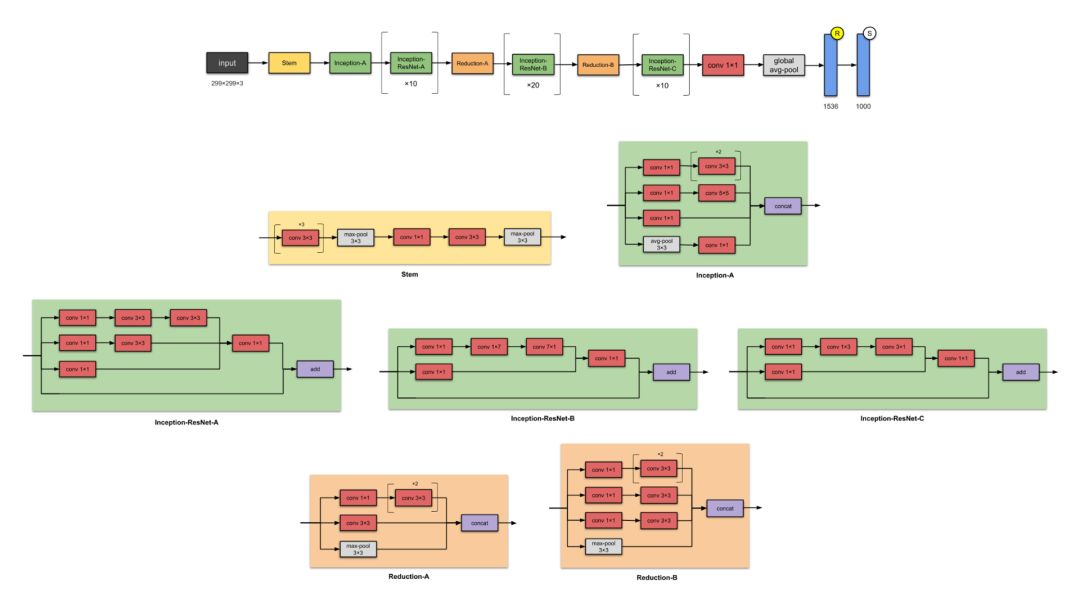
Figure 9: Inception-ResNet-V2 Network Structure. Note: Batch norm and ReLU activation are used after all convolution layers.
In the same paper proposing Inception-v4, the authors also proposed Inception-ResNet: the Inception-ResNet-v1 and Inception-ResNet-v2 network series, with the v2 series having 56M parameters.
What Improvements Are There Compared to the Previous Inception-v3 Version?
-
Converted Inception modules to residual Inception modules.
-
Added more Inception modules.
-
Added a new type of Inception module (Inception-A) behind the Stem module.
Related Literature
-
Paper: Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
Link: https://arxiv.org/abs/1602.07261?source=post_page
-
Authors: Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi. Google
-
Published in: Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence
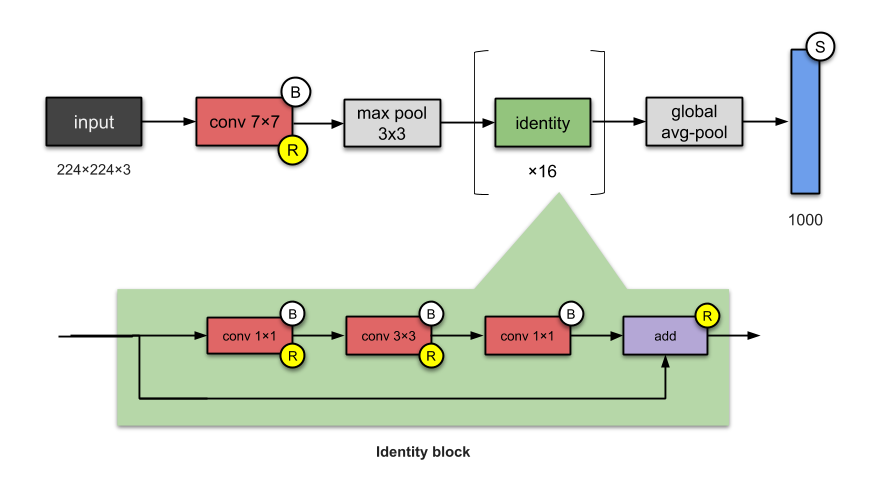
10. ResNeXt-50 (2017)
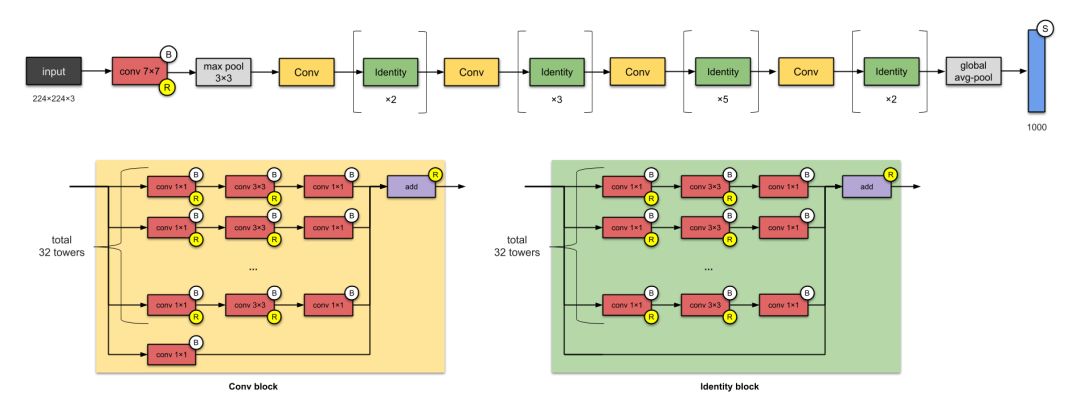
Figure 10: ResNeXt Network Structure
If you think of ResNet, yes, they are related. ResNeXt has 25 M parameters (ResNet-50 has 25.5M). The difference between them is that ResNeXt increases the number of parallel towers/branches in each module. The above diagram totals 32 towers.
What Innovations Are There?
-
Increased the number of parallel towers (cardinality) in a module.
Related Literature
-
Paper: Aggregated Residual Transformations for Deep Neural Networks
Link: https://arxiv.org/abs/1611.05431?source=post_page
-
Authors: Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, Kaiming He. University of California San Diego, Facebook Research
-
Published in: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Appendix: Network In Network (2014)
We note that in a convolution, the pixel values are linear combinations of the weights in the filter and the current sliding window. Consider a mini neural network with only 1 hidden layer. This is why they called it Mlpconv. The network we are dealing with is a (convolutional neural) network with only 1 hidden layer.
The idea of Mlpconv is closely related to 1×1 convolution kernels, which became a major feature of the Inception network architecture.
What Innovations Are There?
-
MLP convolution layer, 1×1 convolution.
-
Global average pooling (averaging each feature map and feeding the resulting vector to the Softmax layer).
Related Literature
-
Paper: Network In Network
Link: https://arxiv.org/abs/1312.4400?source=post_page
-
Authors: Min Lin, Qiang Chen, Shuicheng Yan. National University of Singapore
-
Published in: arXiv preprint, 2013
The following resources can help you visualize neural networks:
-
Netron
-
TensorBoard API by TensorFlow
-
plot_model API by Keras
-
pytorchviz package
References
The author used the papers proposing these CNN architectures as references in the text. In addition to these papers, the author listed some other references in this article:
-
https://github.com/tensorflow/models/tree/master/research/slim/nets(github.com/tensorflow)
-
Implementation of deep learning models from the Keras team(github.com/keras-team)
-
Lecture Notes on Convolutional Neural Network Architectures: from LeNet to ResNet (slazebni.cs.illinois.edu)
-
Review: NIN — Network In Network (Image Classification)(towardsdatascience.com)
Original link:
https://towardsdatascience.com/illustrated-10-cnn-architectures-95d78ace614d
Recommended Reading
(Click the title to jump to read)
Comprehensive AI Learning Path, Most Detailed Resource Compilation!
Heavy Content | Selected Historical Articles from Public Account
My Deep Learning Entry Path
My Machine Learning Entry Roadmap
-
First, cross-channel (or cross-feature map) correlations can be detected by 1×1 convolutions. -
Therefore, the spatial correlations of each channel can be detected by regular 3×3 or 5×5 convolutions.
-
Fully based on depthwise separable convolution layers, introducing CNN.
-
Paper: Xception: Deep Learning with Depthwise Separable Convolutions Link: https://arxiv.org/abs/1610.02357?source=post_page -
Authors: François Chollet. Google. -
Published in: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
8. Inception-v4 (2016)
-
Changed the Stem module. -
Added more Inception modules. -
Adopted the Uniform selection in Inception-v3, meaning the same number of filters were used in each module.
-
Paper: Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning Link: https://arxiv.org/abs/1602.07261?source=post_page -
Authors: Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi. Google. -
Published in: Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence
9. Inception-ResNet-V2 (2016)
-
Converted Inception modules to residual Inception modules. -
Added more Inception modules. -
Added a new type of Inception module (Inception-A) behind the Stem module.
-
Paper: Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning Link: https://arxiv.org/abs/1602.07261?source=post_page -
Authors: Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi. Google -
Published in: Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence
10. ResNeXt-50 (2017)
-
Increased the number of parallel towers (cardinality) in a module.
-
Paper: Aggregated Residual Transformations for Deep Neural Networks Link: https://arxiv.org/abs/1611.05431?source=post_page -
Authors: Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, Kaiming He. University of California San Diego, Facebook Research -
Published in: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Appendix: Network In Network (2014)
-
MLP convolution layer, 1×1 convolution. -
Global average pooling (averaging each feature map and feeding the resulting vector to the Softmax layer).
-
Paper: Network In Network Link: https://arxiv.org/abs/1312.4400?source=post_page -
Authors: Min Lin, Qiang Chen, Shuicheng Yan. National University of Singapore -
Published in: arXiv preprint, 2013
-
Netron -
TensorBoard API by TensorFlow -
plot_model API by Keras -
pytorchviz package
-
https://github.com/tensorflow/models/tree/master/research/slim/nets(github.com/tensorflow)
-
Implementation of deep learning models from the Keras team(github.com/keras-team)
-
Lecture Notes on Convolutional Neural Network Architectures: from LeNet to ResNet (slazebni.cs.illinois.edu)
-
Review: NIN — Network In Network (Image Classification)(towardsdatascience.com)
Recommended Reading
(Click the title to jump to read)
Comprehensive AI Learning Path, Most Detailed Resource Compilation!
Heavy Content | Selected Historical Articles from Public Account
My Deep Learning Entry Path
My Machine Learning Entry Roadmap
Heavyweight! AI Youdao Academic Exchange Group has been established!
Scan the QR code below, add AI Youdao Assistant WeChat, you can apply to join the Lin Xuantian Machine Learning Group (Number 1), Wu Enda deeplearning.ai Learning Group (Number 2). Be sure to note: Join which group (1 or 2 or 1+2) + Location + School/Company + Nickname. For example:1+Shanghai+Fudan+Little Cow.

Long press to scan the code and apply to join the group
(Due to the large number of people adding, please be patient)
Latest AI Heavyweight Content, IAm Watching 