
100 Questions on Deep Learning
Author: louwill
Machine Learning Lab
The MobileNet series, as a representative of lightweight networks, makes the lightweight deployment of CNNs on mobile devices possible. Currently, there are three versions of MobileNet: MobileNet v1, MobileNet v2, and MobileNet v3. This article focuses on elaborating the MobileNet series networks, which is essential for learning about lightweight networks.
MobileNet v1
The paper for MobileNet v1 is “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications,” proposed by Google in 2017, primarily focusing on the mobile use and deployment of CNNs.

In simple terms, MobileNet v1 replaces the conventional convolution in the VGG network with depthwise separable convolutions. The following image shows the network layers contained in a convolution block for both VGG and MobileNet v1.
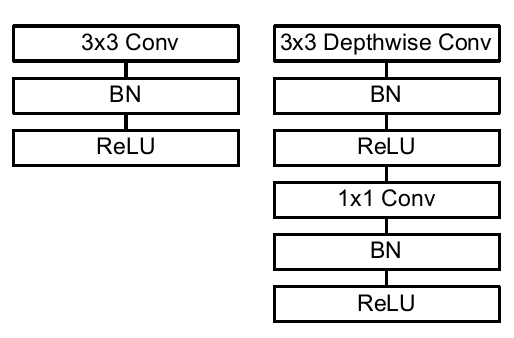
As can be seen, the convolution block of VGG consists of a conventional 3×3 convolution followed by a BN and a ReLU activation layer. MobileNet v1, on the other hand, consists of a 3×3 depthwise separable convolution and a 1×1 convolution, followed by a BN and ReLU layer respectively. The ReLU in MobileNet v1 refers to ReLU6, which differs from ReLU by clipping the activation output to ensure that the maximum output does not exceed 6. This is done to prevent significant precision loss caused by excessively large activation outputs.
So, what is depthwise separable convolution?
From a dimensional perspective, a convolution kernel can be viewed as a combination of spatial dimensions (width and height) and channel dimensions, while the convolution operation can be seen as a joint mapping of spatial and channel correlations. Looking at the 1×1 convolution in inception, the spatial and channel correlations within the convolution can be decoupled, and mapping them separately may yield better results.
Depthwise separable convolution is an innovation based on 1×1 convolutions. It mainly consists of two parts: depthwise convolution and 1×1 convolution. The purpose of depthwise convolution is to convolve each input channel separately using a convolution kernel, meaning that the channels are separated and then recombined. The purpose of the 1×1 convolution is to enhance depth. Below is an example illustrating depthwise separable convolution.
Assuming we convolve a 7x7x3 input with 128 3x3x3 filters, we can obtain a 5x5x128 output. As shown in the figure below:
The computation cost is 5x5x128x3x3x3=86400.
Now let’s see how to achieve the same result using depthwise separable convolution. The first step of depthwise separable convolution is depthwise convolution. Here, depthwise convolution means using three 3x3x1 filters to convolve each of the three input channels separately, which means performing three convolutions, each producing a 5x5x1 output, which are then combined to yield a 5x5x3 output.
Now, to expand the depth to 128, we need to execute the second step of depthwise separable convolution: the 1×1 convolution. We now convolve the 5x5x3 output with 128 1x1x3 filters, resulting in a 5x5x128 output. The complete process is illustrated in the figure below:
Now let’s look at the computational cost of depthwise separable convolution. The computational cost for the first step, depthwise convolution, is: 5x5x1x3x3x1x3=675. The computational cost for the second step, the 1×1 convolution, is: 5x5x128x1x1x3=9600, bringing the total computational cost to 10275 operations. As we can see, depthwise separable convolution saves 12 times the computational cost compared to conventional convolution for the same output. This is the key reason why MobileNet v1 is lightweight.
The complete network structure of MobileNet v1 is shown in the figure below.
The performance comparison of MobileNet v1 with GoogleNet and VGG 16 on ImageNet is shown in the table below:

It can be seen that MobileNet v1 has a parameter count 32 times smaller than VGG 16 while maintaining a precision loss of no more than one point! The advantages of MobileNet v1 in terms of speed and size are evident.
MobileNet v2
MobileNet v2 is an improved and optimized version based on v1. The paper for MobileNet v2 is titled “MobileNetV2: Inverted Residuals and Linear Bottlenecks,” published by Google at CVPR 2018.

The characteristic of MobileNet v1 is depthwise separable convolution, but researchers found that many convolution kernels in depthwise separable convolution are zero, meaning that many convolution kernels do not participate in actual computation. What causes this? The authors of v2 discovered that it is due to the ReLU activation function, which loses a lot of information in low-dimensional space while retaining more useful information in high-dimensional space.
Given this, the solution for v2 is simple: directly replace the ReLU6 activation with a linear activation function. However, not all ReLU activations are replaced; only the last layer’s ReLU is changed to a linear function. Specifically, in the v2 network, the ReLU6 in the last Point-Wise convolution is replaced with a linear function. This operation is named linear bottleneck, which is also the first key point of the v2 network.
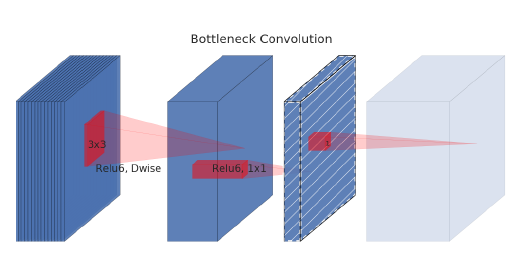
Depthwise convolution itself does not change the number of channels, for example, in the previous example of depthwise separable convolution, the input has three channels and the output still has three channels. Thus, to enable depthwise convolution to work in high dimensions, v2 proposes to add a convolution operation to expand the channel before depthwise convolution. What operation can increase the dimensionality of the channels? Of course, that is the 1×1 convolution.

This operation of expanding the channels before depthwise convolution is called the Expansion layer in v2. This is the second key point of the v2 network.
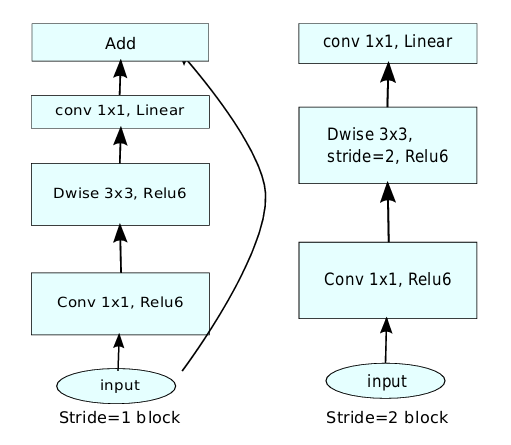
Although MobileNet v1 added depthwise separable convolution, the main structure of the network is still the straight structure of VGG. Therefore, the third major key point of the v2 network is the incorporation of skip connections based on the residual structure of ResNet. Compared to the residual block structure of ResNet, v2 names this structure the Inverted Residual Block.
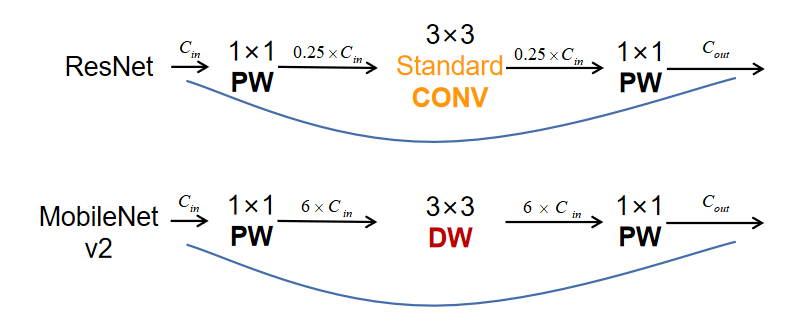
From the figure, we can see that ResNet first reduces dimensionality by 0.25 times, then applies a standard 3×3 convolution, and finally increases dimensionality. In contrast, MobileNet v2 first increases dimensionality by six times, then applies depthwise separable convolution, and finally reduces dimensionality. To illustrate further, we can visualize it as follows:
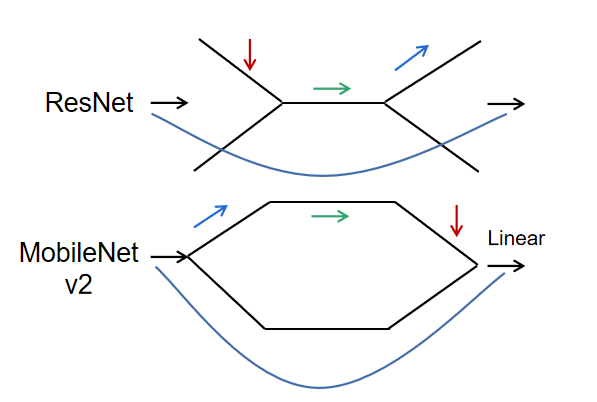
The order of dimensionality increase and decrease in MobileNet v2 is completely opposite to that of ResNet, hence the name inverted residual.
In summary, the three key points: Linear Bottlenecks, Expansion layer, and Inverted Residual combine to form the blocks of MobileNet v2, as illustrated in the figure below.
The network structure of MobileNet v2 is shown in the figure below.
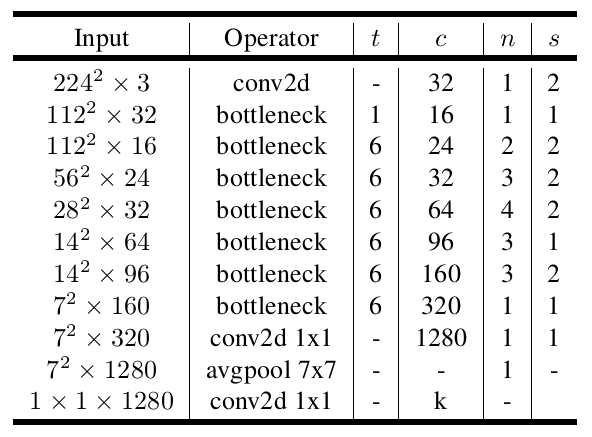
It can be seen that after a conventional convolution, the v2 network adds seven bottleneck block layers, followed by two 1×1 convolutions and a combination of a 7×7 average pooling operation.
MobileNet v3
MobileNet v3 is also a new version of MobileNet proposed by Google in 2019. Based on the v2 network, v3 introduced four major improvements.
-
Using NAS neural architecture search to determine the network structure
-
Introducing Squeeze and Excitation structure based on v2 blocks
-
Using h-swish activation function
-
Improving the tail structure of the v2 network
The paper for v3 is titled “Searching for MobileNetV3,” which clearly indicates the introduction of neural architecture search.

Regarding NAS, I am not very familiar with it and cannot elaborate further. Interested readers can directly refer to relevant NAS papers. The second improvement is the introduction of the squeeze and excitation structure based on v2. Readers familiar with SENet should know that this is an operation that models the interdependencies between channels.
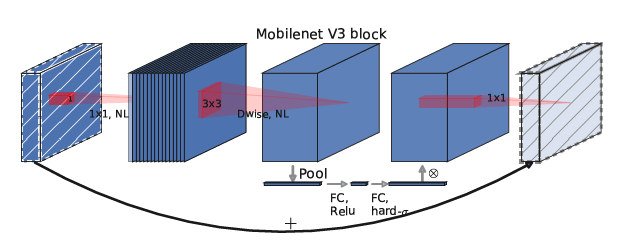
Squeeze and Excitation consists of two parts: Squeeze and Excitation. The Squeeze part obtains the global compressed feature vector of the current feature map by performing Global Average Pooling on the feature map, while the Excitation part obtains the weights of each channel in the feature map through two fully connected layers, and the weighted feature map is used as the input for the next layer of the network. Therefore, we can see that the SE block only has dependencies on the current set of feature maps, making it very easy to embed into almost all current convolutional networks. Thus, MobileNet v3 naturally adopted it.
The block of the v3 network based on v2 is illustrated in the figure below.
The third improvement point is the use of the h-swish activation function. The h-swish activation function is an improvement based on swish, with the swish activation function expressed as follows:
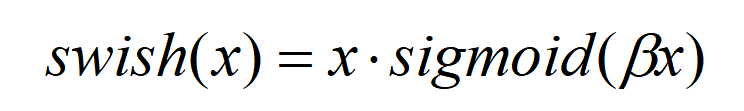
The swish activation function graph is shown below for β values of 0.1, 1.0, and 10.0:
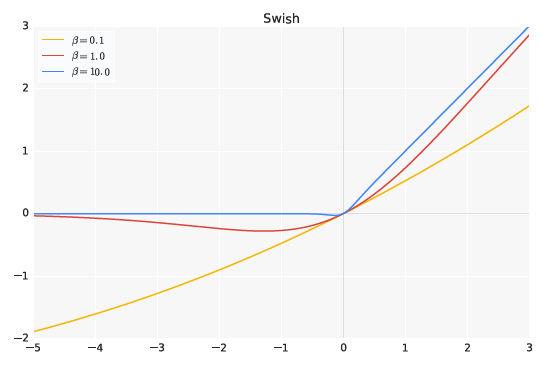
The swish activation function has shown significant improvements in performance across a series of deep convolutional networks, and MobileNet is no exception. However, v3 believes that as a lightweight network, while swish can improve accuracy, it incurs speed losses on mobile devices. Therefore, based on the swish function, v3 improved it and proposed the h-swish activation function.
The basic idea of h-swish is to use an approximate function to approximate the swish function, making it less smooth (hard). Based on the experiences from MobileNet v1 and v2, v3 still chooses ReLU6. The transformation logic is illustrated in the figure below.
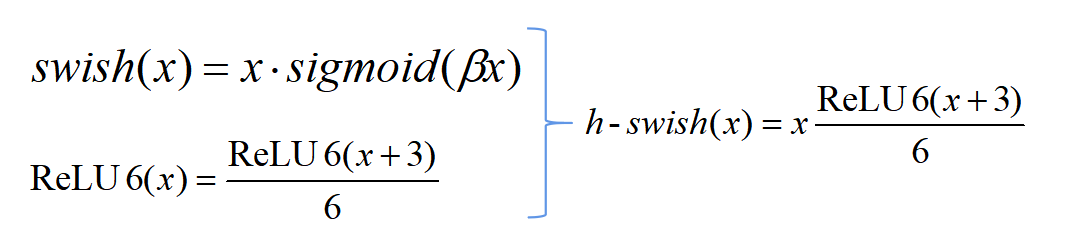
Comparison of swish and h-swish functions:
h-swish can be viewed as a low-precision mode of swish, which reduces time and computational costs while maintaining the same level of accuracy compared to swish. The modifications to the tail structure of the v2 network will not be described in detail here; interested readers can directly read the original v3 paper for further learning.
Conclusion
In conclusion, MobileNet v1 is essentially the VGG network with depthwise separable convolutions added; MobileNet v2 is based on v1 with three key operations added: Linear activation, Expansion layer, and Inverted residual; and v3 introduces NAS, Squeeze and Excitation structure, h-swish activation, and optimizations to the tail structure based on v2.
References:
Previous Highlights:
[Original Release] 30 Lectures on Machine Learning Formula Derivation and Code Implementation.pdf
[Original Release] A Practical Guide to Deep Learning Semantic Segmentation Theory and Practice.pdf
Discussion on Algorithm Positions in SMEs
Algorithm Engineer Development Skills List
Those who truly want to work in algorithms should not fear the competition
Technical learning should not be superficial
Technicians should learn self-marketing
One should not overfit in life
Click to view