MLNLP(Machine Learning Algorithms and Natural Language Processing) community is a well-known natural language processing community at home and abroad, covering NLP master’s and doctoral students, university teachers, and corporate researchers.The Vision of the Communityis to promote communication and progress between the academic and industrial circles of natural language processing and machine learning at home and abroad, especially for the progress of beginners.Reprinted from | Jishi PlatformAuthor | Matrix MingzaiArticle link:https://arxiv.org/abs/2202.02703
1
“Preface”
Multimodal perception fusion is a fundamental task in autonomous driving, attracting the attention of many “salt eaters”. However, due to reasons such as high noise in raw data, low information utilization, and misalignment of multimodal sensors, achieving good performance is not easy. Therefore, this survey report summarizes some conceptual methods of multimodal fusion between Lidar and camera from 50 papers. I hope that through my translation and interpretation, I can bring some new thoughts about the future of multimodal image fusion to everyone. (This sharing is more of an introduction and summary, and I try to organize and refine the content through my understanding and experience. This is a version that can serve as an entry point for beginners and also as a review for experienced practitioners. If you find the content good, please share it with your peers!)
2
“Why Multimodal Fusion is Needed”
In complex driving environments, single sensor information is insufficient to effectively process scene changes. For example, in extreme weather conditions (heavy rain, sandstorms) with low visibility, relying solely on the RGB images from the camera cannot respond to changes in the environment. Similarly, in ordinary road environments, such as traffic lights and cones, relying only on Lidar information is also ineffective; it requires the RGB information provided by the camera for effective processing. Therefore, the complementarity of different modal information becomes even more important in the perception tasks of autonomous driving.
3
“Background”
There are many usable scenarios for multimodal fusion, such as 2D/3D object detection, semantic segmentation, and tracking tasks. Among these tasks, the key focus is on the information interaction and fusion between modalities. As the efficiency and accuracy of information acquisition from sensors improve and costs decrease, the multimodal fusion methods in perception tasks of autonomous driving have gained rapid development opportunities. Therefore, the next question is, how can we make the multimodal fusion work smoother and more efficient?
4
“Types of Fusion”
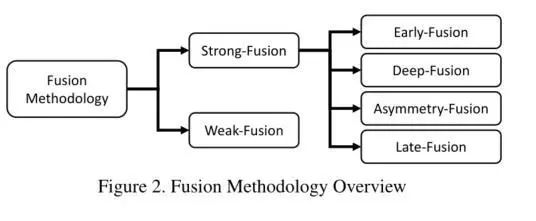
According to the statistical analysis results of 50 papers, most methods follow the traditional fusion rules, classifying them into three main categories: early (front) fusion, feature fusion, and late fusion. The focus is on the stage of fusion features in deep learning models, whether at the data level, feature level, or suggestion level. Firstly, this classification method does not clearly define the feature representation at each level. Secondly, our general approach is to open two branches for the data information from Lidar and the camera; during the model processing, the two modal branches remain symmetric, allowing the information from the two modalities to interact at the same feature level. In summary, while the traditional classification method may be intuitive, it is insufficient to cope with the increasing amount of multimodal fusion content that has recently emerged!
Two Major Categories and Four Minor Fusion Methods
The latest fusion tasks propose some innovative multimodal fusion methods for autonomous driving perception tasks. Overall, they include two major categories: strong fusion and weak fusion, as well as four minor categories under strong fusion: early (front) fusion, deep (feature) fusion, late (back) fusion, and asymmetric fusion (which indicates mutual decision-making of features from two branches).
5
“Introduction to Various Tasks and Datasets”
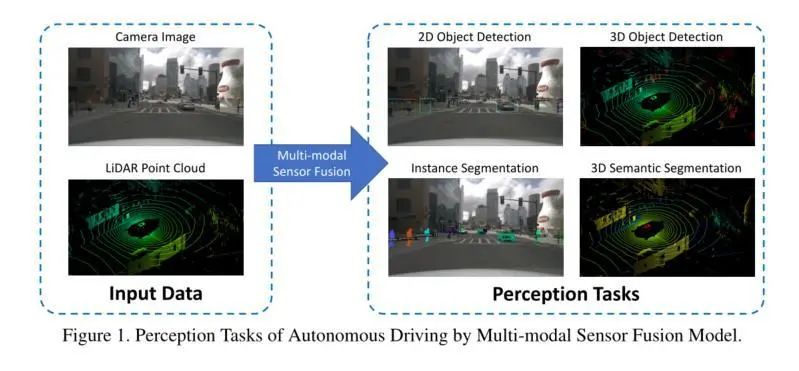
Generally speaking, the tasks of multimodal perception fusion in autonomous driving environments include classic works such as object detection, semantic segmentation, depth estimation, and depth prediction. In fact, the common tasks still mainly revolve around semantic segmentation and object detection.
Object Detection
In fact, there are several types of object detection in common autonomous driving scenarios (cars, pedestrians, bicycles, traffic lights, traffic signs, cones, speed bumps). Generally speaking, object detection uses rectangles or cuboids represented by parameters to tightly bind instances of predefined categories, such as cars or pedestrians, which require excellent performance in both localization and classification. Due to the lack of depth channels, 2D object detection is usually simply represented as (x, y, h, w, c), while 3D object detection bounding boxes usually include two additional dimensions of depth and orientation compared to 2D annotations, represented as (x, y, z, h, w, l, θ, c).
Semantic Segmentation
In addition to object detection, semantic segmentation is another crucial aspect of autonomous driving perception. For example, we will detect and differentiate background and foreground targets in the environment, using semantic segmentation to understand the area where an object is located and the details of that area is also quite important in autonomous driving tasks. Furthermore, some lane line detection methods also use multi-class semantic segmentation masks to represent different lanes on the road.The essence of semantic segmentation is to cluster the basic components of input data (such as pixels and 3D points) into different regions containing specific semantic information. Specifically, semantic segmentation refers to the task of assigning k semantic labels to each pixel or point DI from a given set of data, such as image pixels DI={d1, d2,…, dn} or Lidar 3D point clouds DL={d1, d2,…, dn}, and a predefined set of candidate labels Y={y1, y2, y3,…, yk} (In fact, this explanation is somewhat complex and obscure; just consider semantic segmentation as a pixel-level classification problem, it is that simple).If you find it still somewhat abstract, you can look at the three images below, which detail the tasks of 2D/3D object detection and semantic segmentation in different scenarios.Autonomous driving perception model based on multimodal sensor fusion.
6
“Datasets”
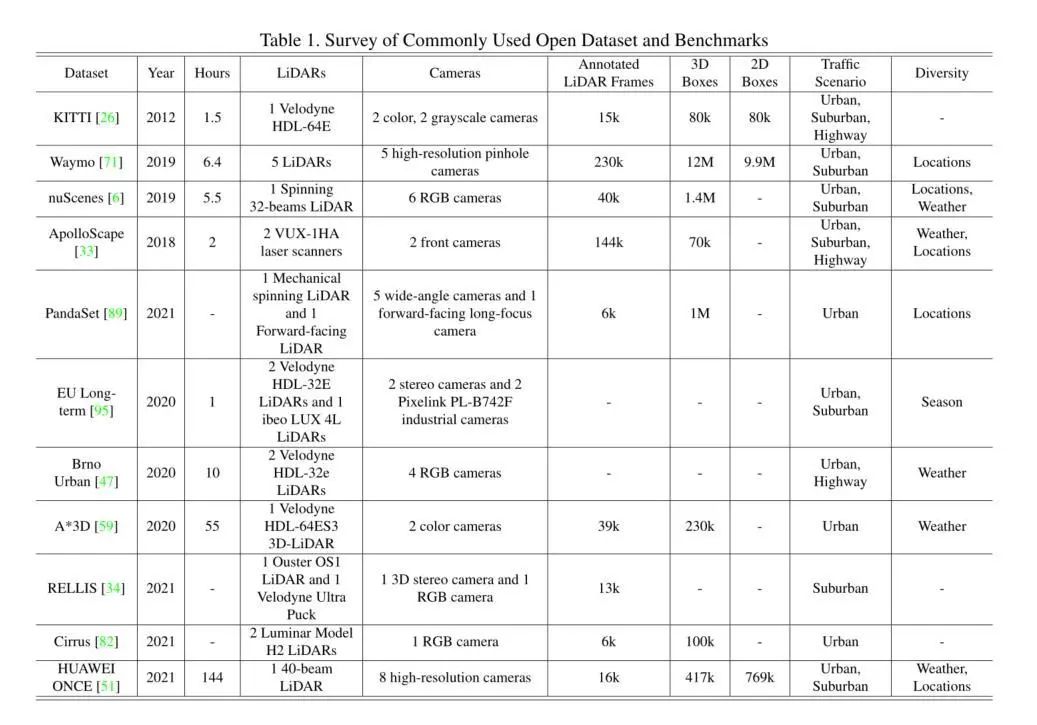
Common datasets in autonomous driving include Kitti, Waymo, NuScenes, which are well-known datasets for 3D information in autonomous driving scenes. Essentially, many of our multimodal fusion tasks revolve around these three datasets. I won’t elaborate on the specific composition of the datasets here; you can check the distribution of the datasets on the website. It is important to pay attention to the evaluation metrics, as they are crucial for the entire optimization direction, so please keep this in mind! Additionally, when understanding datasets (especially for beginners), it is important to note the format of the data because Lidar data differs from traditional RGB image data, so care should be taken in designing the Lidar branch to protect data input.Overview of datasets
7
“Fusion Modes”
This is the climax of our discussion tonight: how to fuse these two different types of data? According to the current development mode of fusion models, there are two major categories and four minor categories. What are the two major categories and what are the four minor categories? Let’s continue to look!
Early Fusion
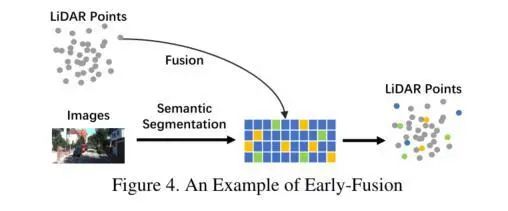
Some people might say, why not just unify the data format and merge them for input? However, early fusion is not that straightforward at this stage.Early fusion generally involves fusing Lidar data with image data or fusing Lidar data with image features in two ways. As shown in the figure below, the early information interaction process between the Lidar branch and image information occurs. This method can be used in reflectance, voxelized tensor, front-view/range-view/BEV, pseudo-point clouds, etc. Although the features of the image vary at different stages, they are highly related to the information from Lidar. Therefore, the fusion of Lidar information and image features can also be effectively performed. Since the Lidar branch has not undergone the stage of abstract feature extraction, the data at this stage still possesses interpretability, allowing for intuitive visualization of the Lidar data representation.Early fusion of LidarFrom the perspective of images, the strict definition of data-level images can only include RGB or Gray data. In fact, this definition lacks universality, reasonableness, and is somewhat limited. Therefore, we should broaden our perspective; the data level can encompass not only images but also feature maps. Compared to the traditional early fusion definition, this article does not limit the definition of camera data to just images but also incorporates feature information. By consciously selecting and fusing feature information, we obtain a more semantically connected input data, which is then fed into the network for feature extraction.Whether it is directly converting data types to unify them for concatenation, fusing Lidar information with image features, or first establishing semantic connections between the two before inputting, these are all operations of early fusion. The advantage of such unified input operations is their simplicity and ease of deployment. By facilitating semantic interactions in advance, we also address the insufficient semantic information interaction between modalities in traditional early fusion. Therefore, to some extent, choosing early fusion is also a good option.
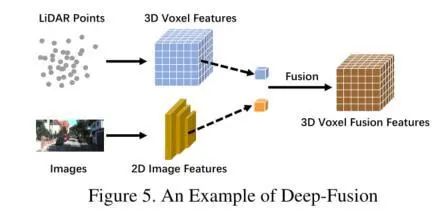
Deep Fusion
Deep feature fusion methods are also quite common. As shown in the figure below.Deep feature fusionWe can clearly see that after passing through their respective feature extractors, the Lidar point cloud branch and the image branch obtain high-dimensional feature maps, which are then fused through a series of downstream modules. Unlike other fusion methods, deep fusion sometimes also fuses high-level features with original features in a cascading manner, utilizing both high-level feature information and original features containing rich physical information.
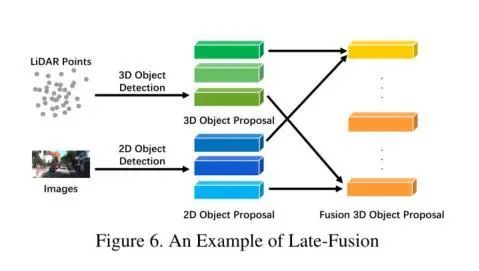
Late Fusion
Late fusion, also known as object-level fusion, refers to the method of merging results within each modality. Some late fusion methods utilize the outputs of both the Lidar point cloud branch and the camera image branch simultaneously and make the final prediction based on the results of the two modalities. Late fusion can be viewed as an ensemble method that optimizes the final solution using multimodal information.Late fusion
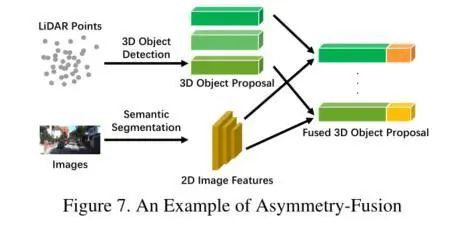
Asymmetry Fusion
In addition to early fusion, deep fusion, and late fusion, there are also methods that assign different privileges to different branches, thus defining the method of fusing object-level information from one branch while using data-level or functional-level information from other branches as asymmetric fusion. Unlike other strong fusion methods that treat both branches equally, asymmetric fusion methods have at least one dominant branch, while other branches provide auxiliary information to complete the final task. The diagram below illustrates a classic example. Although the feature extraction processes are similar to those in late fusion, asymmetric fusion only proposes from one branch, while late fusion merges information from all branches.Asymmetric fusionClearly, this type of fusion method is also reasonable, as convolutional neural networks perform well on camera data, effectively filtering out useless points in the point cloud data that lack actual semantic information, thus reducing the interference of noise points during fusion. Moreover, some works attempt to break conventions by using Lidar backbones to guide 2D multi-view data fusion, achieving higher accuracy through information interactions.
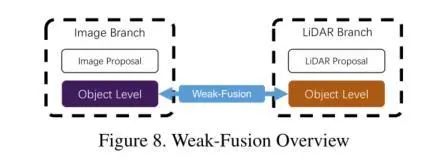
Weak Fusion
Unlike strong fusion, weak fusion methods do not directly merge from multimodal branches (data/feature/object) but operate on data in other ways. Weak fusion methods typically employ rule-based approaches, using data from one modality as supervisory signals to guide interactions in another modality. The diagram below illustrates the basic framework of weak fusion. Unlike the aforementioned asymmetric fusion that merges image features, weak fusion directly inputs selected raw Lidar information into the Lidar backbone, without directly interacting with the features of the image branch, instead relying on weak connections (such as loss functions) to achieve final information fusion. Compared to the previous strong fusion methods, the information interaction between branches is minimal, but it also avoids information interference caused by asymmetric information during interactions, or prevents poor quality from a single branch from affecting overall fusion inference.Weak fusion
Other Fusion
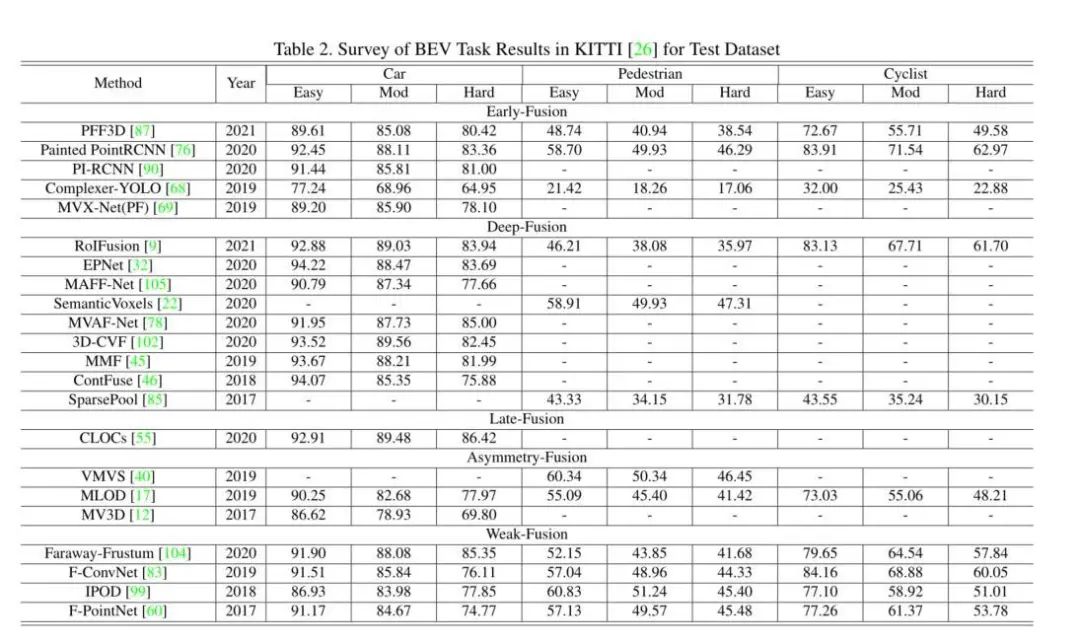
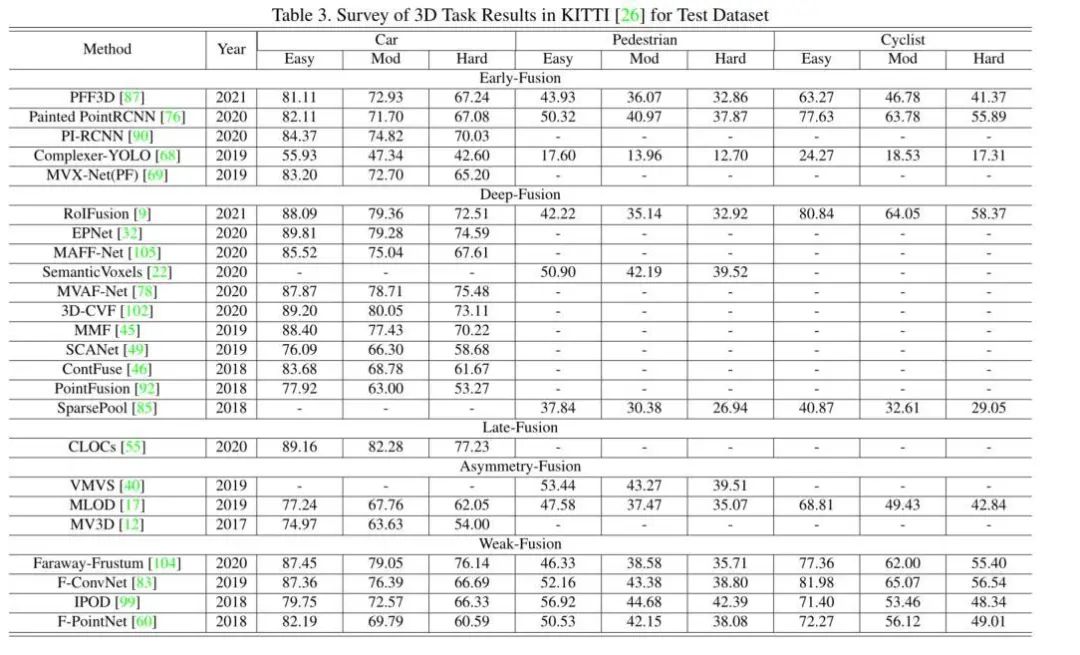
Some works cannot be simply defined as any of the aforementioned fusion methods because they employ more than one fusion method within the entire model framework. Creating fusion hybrids is a natural skill for us salt researchers; you might say A has xxx benefits and B has xxx benefits, so A+B should be a direct win, right? However, in reality, many situations cannot effectively stitch methods together. For instance, the combination of deep fusion and late fusion schemes, or the combination of early fusion and deep fusion. These methods face redundancy issues in model design and are not mainstream methods of fusion modules, failing to achieve the A+B effect while significantly sacrificing inference time and increasing algorithm complexity. Some experimental results.Results on 2D KittiResults on 3D KittiLooking at the experimental results above, you can take a quick look.
7
“The Future of Multimodal Perception Fusion”
In recent years, multimodal fusion methods for autonomous driving perception tasks have made rapid progress, from more advanced feature representations to more complex deep learning models. However, there are still some open questions that need to be addressed. Here, we summarize some key and necessary work that needs to be done in the future.
How to Develop More Advanced Fusion Methods
In fact, the two biggest roadblocks hindering modal fusion are:A: Misalignment of fusion modelsB: Information lossThe intrinsic and extrinsic characteristics of cameras and Lidar are completely different. Data from both modalities need to be reorganized in a new coordinate system.Traditional early and deep fusion methods utilize external calibration matrices to directly project all Lidar points onto corresponding pixels or vice versa. Due to noise in the data samples, this alignment method cannot achieve precise alignment under interference from noise. Regardless, relying solely on mechanical means to eliminate errors introduced by machines is not only difficult but also costly. Therefore, we can see that current methods, in addition to strict transformations and one-to-one correspondences, can also utilize surrounding information as supplements to improve fusion performance.Moreover, during the transformation process between input and feature space, certain information loss is inevitable. This is because the dimensionality reduction during feature extraction will inevitably lead to significant information loss.Thus, by mapping the data from the two modalities to another specialized high-dimensional representation for fusion, future work can effectively utilize the original data and reduce information loss. Some methods adopt direct concatenation of data, performing fusion through weighting. However, current solutions are still immature; simply using pixel-level weighting may not effectively merge data with significantly different distributions, making it difficult to bridge the semantic gap between the two modalities. Some works attempt to use more refined cascading structures for data fusion and performance enhancement. Future research may explore mechanisms like bilinear mapping to fuse features of different modalities.
Rational Use of Information from Multiple Modalities
Most frameworks may only utilize limited information and have not carefully designed further auxiliary tasks to better understand driving scenes.What we currently do is to discuss tasks such as semantic segmentation, object detection, and lane line detection separately, isolating these tasks. Then, we combine different models to provide services, which is clearly redundant. So why not create a multi-task framework that covers various tasks at once? In autonomous driving scenarios, many downstream tasks with explicit semantic information can significantly enhance the performance of object detection tasks. For instance, lane detection can intuitively provide additional assistance for detecting vehicles between lanes, while semantic segmentation results can improve object detection performance.Therefore, future research can focus on simultaneously detecting lanes, traffic lights, signs, etc., to construct a unified autonomous driving task that aids in executing perception tasks.Meanwhile, temporal information is also crucial in autonomous driving perception tasks. For example, BEVFormer uses RNNs to integrate temporal information, ultimately enabling effective generation of BEV views for overall tasks. Temporal sequence information contains serialized supervisory signals, which can provide more stable results than single-frame methods, making it more adaptable to the overall task requirements of autonomous driving.Future research can concentrate on how to utilize multimodal data for self-supervised learning (including pre-training, fine-tuning, or contrastive learning). By implementing these advanced mechanisms, fusion models will lead to a deeper understanding of the data and achieve better results. If our perception tasks also adopt this approach for experimentation, I believe we will achieve even more gratifying results.
Intrinsic Issues of Perception Sensors
Regional deviations or inconsistencies in resolution are closely related to sensor devices. These unforeseen issues severely hinder the large-scale training and implementation of deep learning models for autonomous driving, and the quality of data and data collection schemes are significant obstacles to further development of autonomous driving perception tasks.In autonomous driving perception scenarios, the raw data extracted from different sensors often possesses severe domain-related characteristics. Different camera systems have distinct optical characteristics, and imaging principles are inconsistent. More importantly, the data itself may have domain differences, such as weather, season, or location; even if captured by the same sensor, the images presented can vary greatly. Due to these variations, detection models may not adapt well to new scenarios. This discrepancy can lead to generalization failures, resulting in decreased reusability of large-scale datasets and original training data. Therefore, how to eliminate domain bias and achieve adaptive integration of different data sources will be a key focus of future research.Different sensors from various modalities often have different resolutions. For instance, the spatial density of Lidar is significantly lower than that of images. Regardless of the projection method used, it is impossible to find a one-to-one correspondence, so conventional operations may discard some information. Whether due to different resolutions of feature vectors or imbalances in original information, it may weaken the information volume or presence of one modality branch, leading to dominance of a specific modality’s data. Thus, future work can explore a data approach compatible with sensors of different spatial resolutions.
8
“Conclusion”
The article provides a detailed overview of current work on multimodal fusion and some future development directions. I believe we need a rational decision-making framework for multimodal fusion that is cost-effective, requiring us to understand our data better. Moreover, we need more data and a greater investment in analysis costs. Approaches like self-supervised learning, contrastive learning, and large-scale pre-training can yield excellent results, but this nuclear strike approach is not the core of optimization work. Regardless of whether it is early, deep, late, or asymmetric strong fusion methods, each has its drawbacks. We need to further optimize and improve them according to the characteristics of the data we need to fuse. Current fusion may involve only the interaction of two modalities, but in reality, future work will go far beyond the simple interaction of two modalities and two sensors. So how can we proceed with our current work? This story still needs further exploration! Technical Communication Group Invitation
△ Long press to add assistant
Scan the QR code to add the assistant on WeChat
Please note: Name-School/Company-Research Direction(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue Systems)Then you can apply to join the Natural Language Processing/Pytorch and other technical communication groups
About Us
MLNLP Community is a grassroots academic community jointly established by scholars in the field of natural language processing at home and abroad. It has developed into a well-known natural language processing community, including well-known brands such as Ten Thousand People Top Conference Communication Group, AI Elite Selection, MLNLP Talent Exchange, and AI Academic Exchange, aiming to promote progress between the academic and industrial circles of machine learning and natural language processing.The community can provide an open communication platform for related practitioners in terms of further study, employment, and research. Everyone is welcome to pay attention to and join us.