
Source | Zhihu
Address | https://www.zhihu.com/question/44832436/answer/266068967
Author | crystalajj
Editor | Machine Learning Algorithms and Natural Language Processing Public Account
This article is for academic sharing only. If there is an infringement, please contact the background for deletion.
Introduction
How does word2vec generate word vectors? This is a broad question. To explain from the beginning, first you need a text corpus, and you need to preprocess it. This processing flow depends on your corpus type and personal goals. For example, if it’s an English corpus, you may need to check for case conversion and spelling errors. If it’s a Chinese or Japanese corpus, you need to perform tokenization. The process has been detailed in other answers, so I won’t repeat it here. After obtaining the processed corpus you want, you can use their one-hot vectors as input for word2vec to train low-dimensional word vectors (word embeddings). It must be said that word2vec is a great tool. Currently, there are two training models (CBOW and Skip-gram) and two acceleration algorithms (Negative Sampling and Hierarchical Softmax). This answer aims to explain how word2vec converts the one-hot vectors of the corpus (the model’s input) into low-dimensional word vectors (the model’s intermediate product, specifically the input weight matrix), allowing you to truly feel the change in vectors, without involving acceleration algorithms. If readers have requests, I can add that later.
1 Word2Vec Models Overview
As mentioned earlier, Word2Vec includes two word training models: the CBOW model and the Skip-gram model.
The CBOW model predicts the center word W(t) based on the surrounding words, while the Skip-gram model predicts the surrounding words based on the center word W(t).
Aside from the pros and cons of the two models, their structures differ only in the input and output layers. Please see:
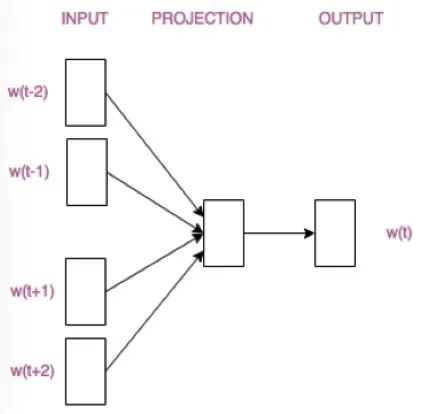
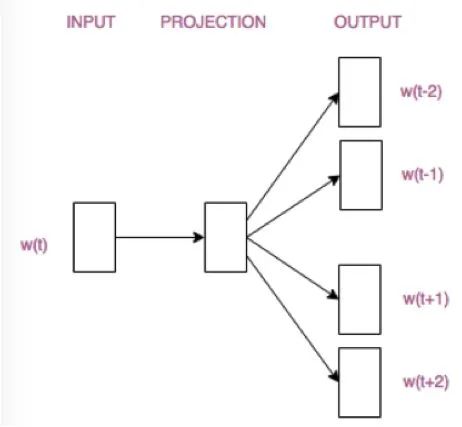
These two structural diagrams are actually simplified. Readers only need to have a rough understanding and awareness of the differences between the two models. Next, we will specifically analyze the construction of the CBOW model and how word vectors are generated. Once you understand the CBOW model, the Skip-gram model will be easy to grasp.
2 Understanding the CBOW Model
Those with a good mathematical foundation and English skills can refer to the Stanford University Deep Learning for NLP lecture notes.
Of course, those who prefer to take it easy can follow my lead.
First, let’s look at this structural diagram and describe the CBOW model’s process in natural language:
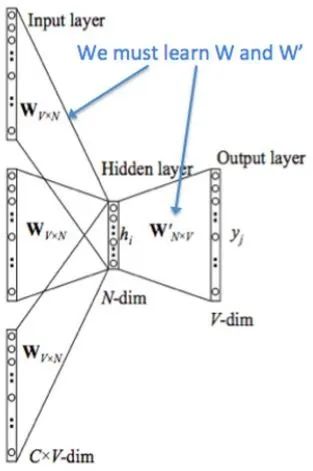
NOTE: The content within the curly brackets {} is explanatory.
-
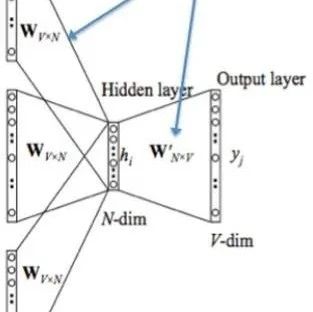
Input Layer: One-hot of context words. {Assuming the dimensionality of the word vector space is V, and the number of context words is C}
-
All one-hot vectors are multiplied by the shared input weight matrix W. {V*N matrix, where N is a number you set, initializing the weight matrix W}
-
The resulting vector {since it’s one-hot, it’s a vector} is summed and averaged to form the hidden layer vector, size 1*N.
-
Multiply by the output weight matrix W’ {N*V}
-
The resulting vector {1*V} is processed by an activation function to obtain a V-dimensional probability distribution {PS: since it’s one-hot, each dimension represents a word}, and the index with the highest probability indicates the predicted center word (target word).
-
Compare with the true label’s one-hot, the smaller the error, the better.
Therefore, it is necessary to define a loss function (generally the cross-entropy cost function) and use gradient descent to update W and W’. After training, the vector obtained by multiplying each word in the input layer by matrix W is the word vector (word embedding) we want, and this matrix (the word embeddings of all words) is also called a lookup table (actually, you have already realized that this lookup table is the matrix W itself). This means that the one-hot representation of any word multiplied by this matrix will yield its word vector. With the lookup table, you can directly look up the word vector without going through the training process.
This should clarify the question! If you still feel I haven’t explained it clearly, don’t worry! Follow me as we go through the process of the CBOW model with an example!
3 Example of CBOW Model Process
Assume our corpus is a simple document with only four words: {I drink coffee everyday}. We choose coffee as the center word, and set the window size to 2, meaning we will predict a word based on the words “I”, “drink”, and “everyday”, and we hope this word is coffee.
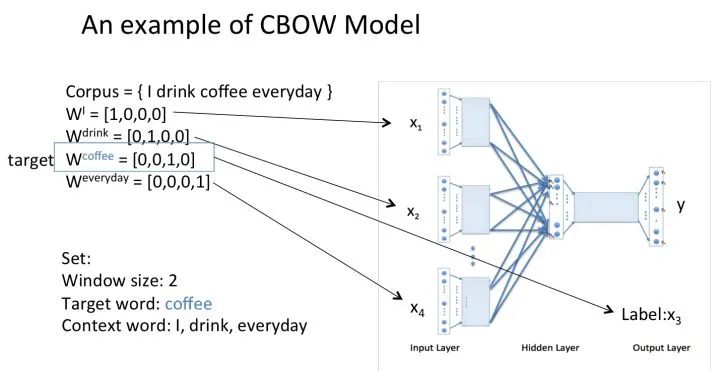
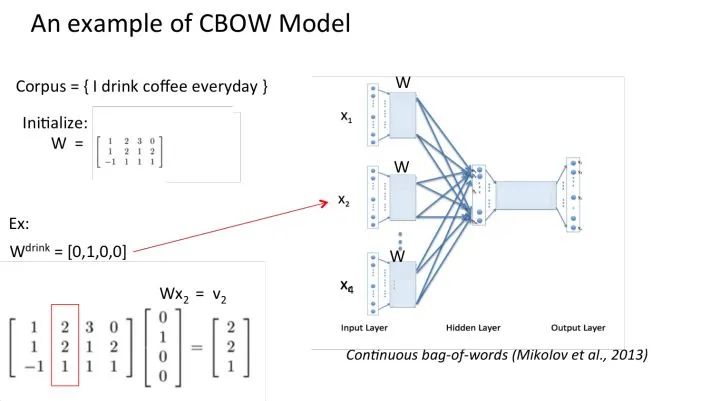
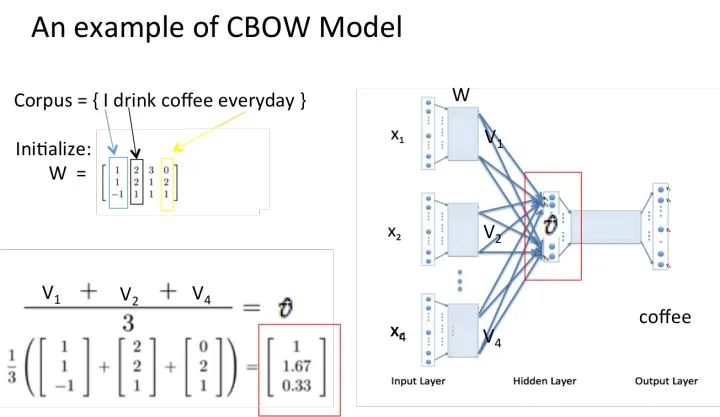
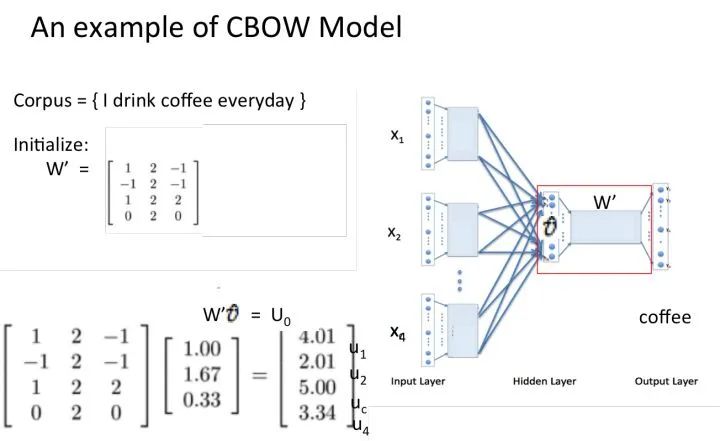
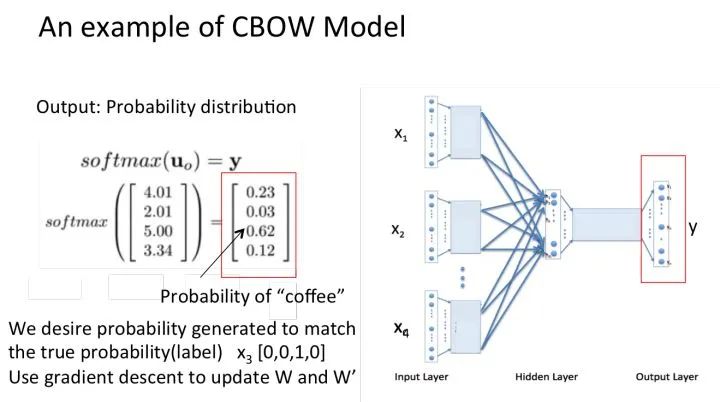
Assuming that we have reached the set number of iterations for the probability distribution, the lookup table we trained should be matrix W. That is, any one-hot representation of a word multiplied by this matrix will yield its own word embedding.
If you have any questions, feel free to ask.
Important! The Yizhen Natural Language Processing – Academic WeChat Group has been established.
You can scan the QR code below, and the assistant will invite you to join the group for discussion.
Note: Please modify the remarks when adding as [School/Company + Name + Field]
For example – Harbin Institute of Technology + Zhang San + Dialogue System.
Account owner, please avoid commercial solicitation. Thank you!

Recommended Reading:
The Differences and Connections Between Fully Connected Graph Convolutional Networks (GCN) and Self-Attention Mechanisms
A Complete Guide for Beginners on Graph Convolutional Networks (GCN)
Paper Review [ACL18] Based on Self-Attentive Syntactic Analysis