Click on the "Xiao Bai Learns Vision" above, select to add a "star" or "top".
Important content delivered to you first.
Guide to Extreme City
This article reviews four papers on achieving multi-task unification in data or model structure, introducing the research direction of incorporating multiple types of data in the optimization of multimodal models.
Introduction
Using more data during the training process has always been one of the important methods to improve efficiency in deep learning, and this is no exception in multimodal scenarios. For example, the classic CLIP model uses a large-scale network image-text matching dataset for pre-training, achieving excellent results in tasks like image-text matching.Subsequently, an important branch in the optimization of the CLIP multimodal model is how to use more other types of data (such as image classification data, image captioning data, etc.). Recent works, especially those published at CVPR 2022 and by Google, have focused on this aspect. The core of using multiple types of data is to achieve multi-task unification in data or model structure.This article reviews four of the most typical recent works in this direction, including two papers from CVPR 2022 and two from Google. The methods involved include: unification of multimodal model structures, unification of multimodal data formats, introduction of unimodal data, and optimization of multi-type data distribution differences.
1. Unification of Multimodal Model Structures
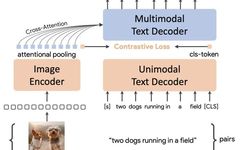
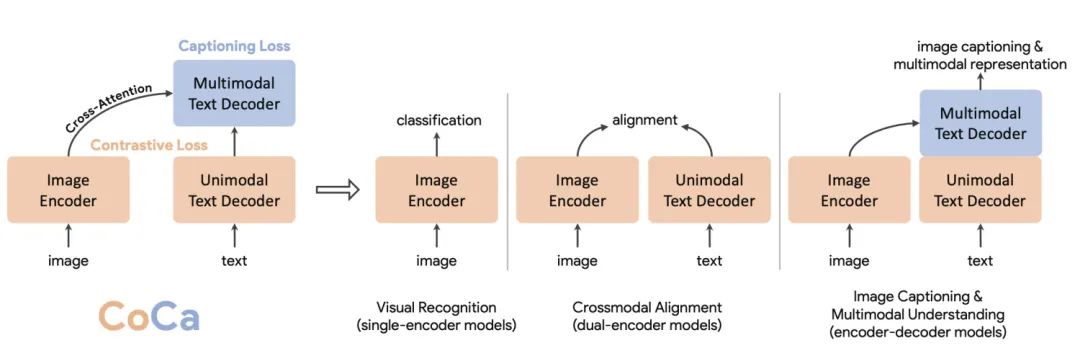
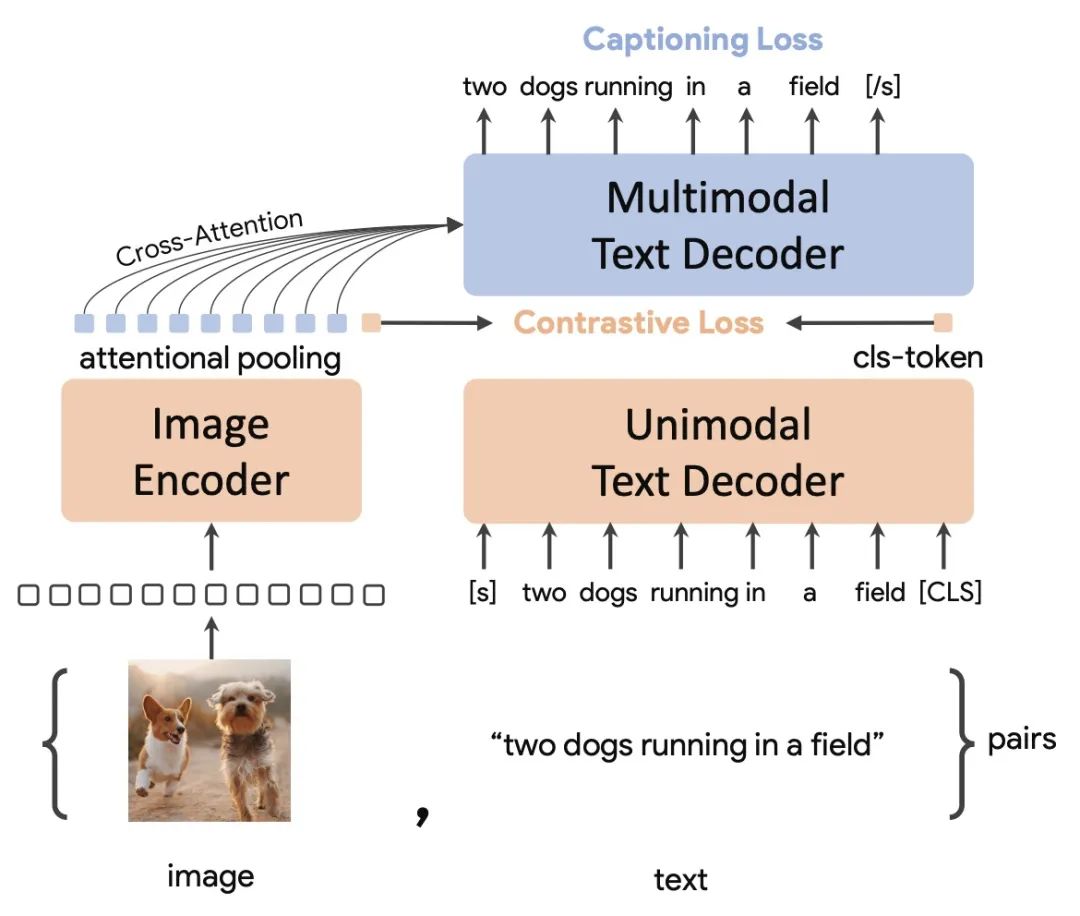
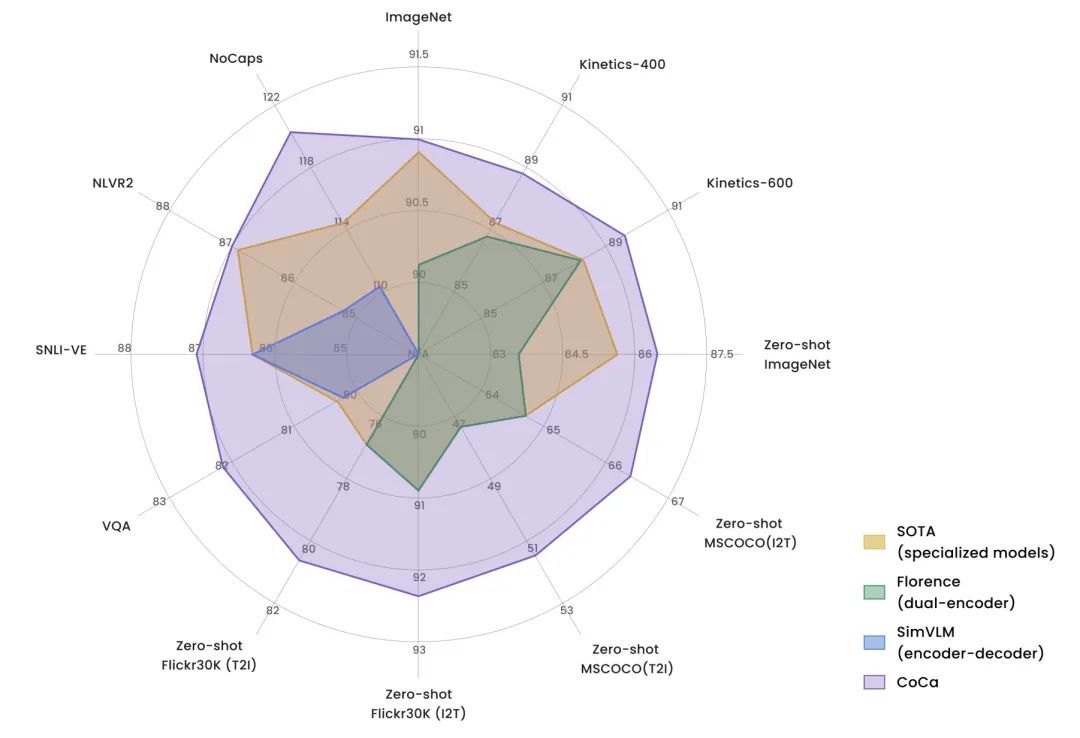
Paper Title: CoCa: Contrastive Captioners are Image-Text Foundation ModelsDownload Link: https://arxiv.org/pdf/2205.01917.pdfCoCa generalizes models that solve image or multimodal problems into three classic structures: single-encoder model, dual-encoder model, and encoder-decoder model. The single-encoder model refers to the basic image classification model, the dual-encoder model refers to a two-tower image-text matching model similar to CLIP, and the encoder-decoder model refers to a generative model used for image captioning tasks. The comparison of the three types of model structures is shown in the figure below.CoCa aims to unify these three types of model structures, allowing the model to train on all three types of data simultaneously, acquiring information from more dimensions and enabling the complementary advantages of the three model structures. CoCa’s overall structure consists of three parts: one encoder (Image Encoder) and two decoders (Unimodal Text Decoder, Multimodal Text Decoder). The Image Encoder uses an image model, such as ViT. The Unimodal Text Decoder serves as the text encoder in CLIP, functioning as a text decoder that does not interact with image-side information. There is no cross attention between the Unimodal Text Decoder and the Image Encoder, making it effectively a unidirectional language model. Finally, the Multimodal Text Decoder interacts with the image encoder to generate image-text interaction information and decode the corresponding text. Note that both text decoders are unidirectional to prevent information leakage.CoCa has achieved outstanding results across multiple tasks. The figure below compares the performance of CoCa and three types of image-text models across various tasks, clearly showing CoCa’s advantages. It achieves SOTA across multiple tasks and datasets, reaching 91% performance on ImageNet.
2. Unification of Multimodal Data Formats
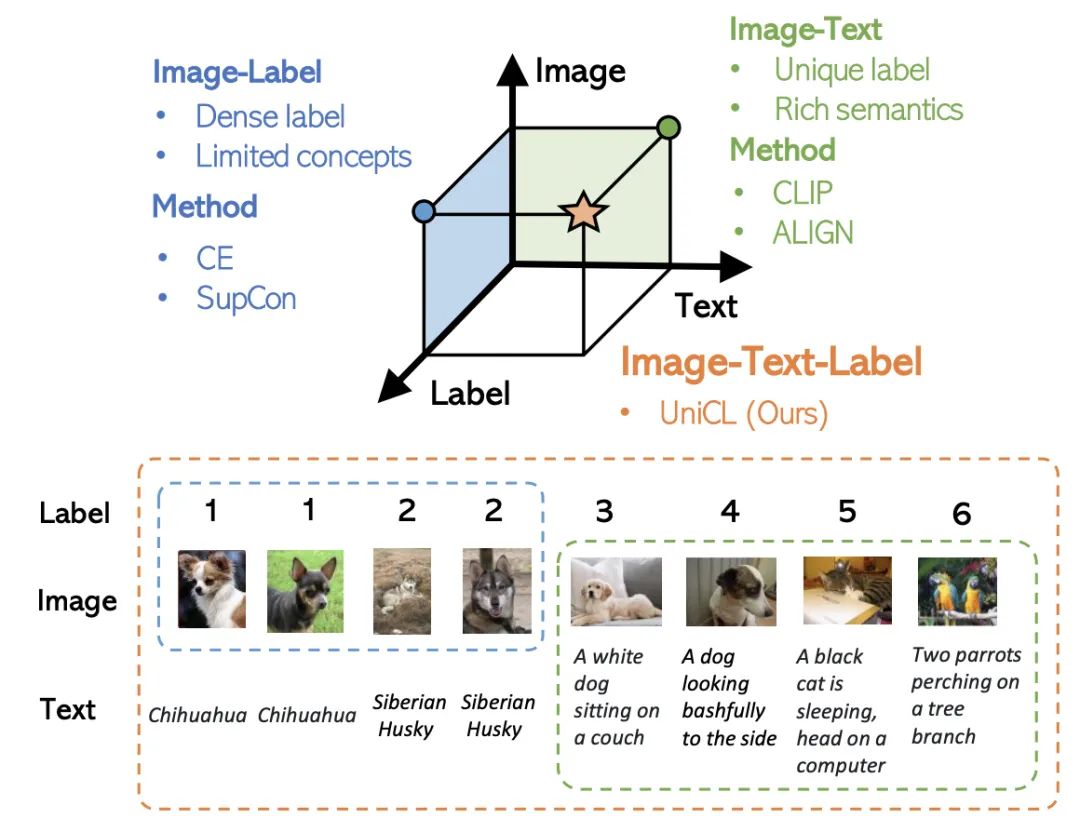
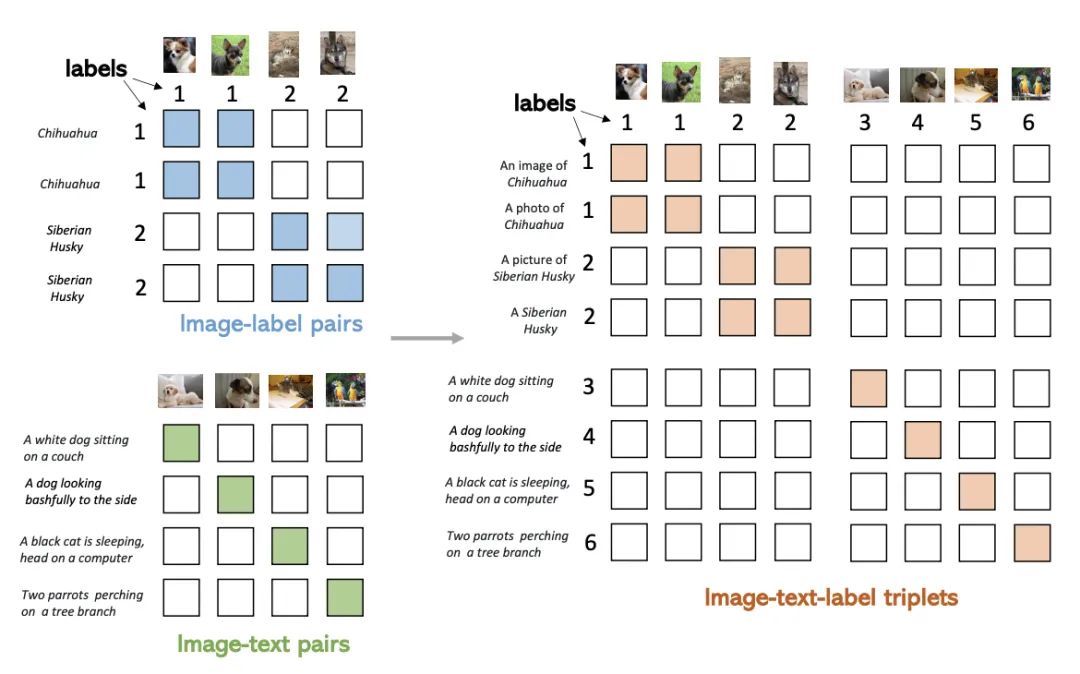
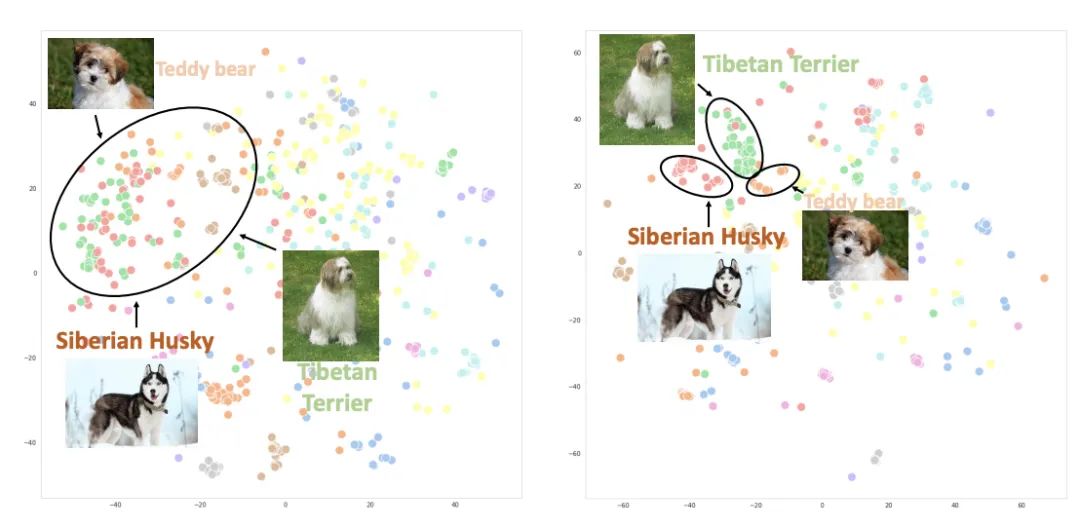
Paper Title: Unified Contrastive Learning in Image-Text-Label SpaceDownload Link: https://arxiv.org/pdf/2204.03610.pdfThe method proposed in this paper aims to utilize the information from images, texts, and labels simultaneously, constructing a unified contrastive learning framework that leverages the advantages of two training modes. The figure below reflects the differences between the two training modes: Image-Label targets discrete labels, treating images of the same concept as a group while completely ignoring text information; whereas Image-Text targets matching between image-text pairs, where each pair can be viewed as a separate label, introducing rich semantic information from the text side.The core method of this paper is to unify the data formats to achieve the goal of simultaneously using Image-Text and Image-Label data. These two types of data can be represented in a unified form: (image, text, label) triplet. For Image-Label data, the text corresponds to the category name for each label, and the label corresponds to each discrete label for the category; for Image-Text data, the text is the description for each image, and the label is different for each matching image-text pair. By merging these two types of data, as shown in the right side of the figure below, a matrix can be formed where the filled portions are positive samples and the others are negative samples. In the Image-Label data, the corresponding categories of image-text are positive samples; in Image-Text, the diagonal represents positive samples. By unifying the format of the data in this way, the original contrastive learning method in CLIP can be directly used for training, achieving the goal of using multiple types of data simultaneously.The figure below illustrates the t-SNE plots of image embeddings trained using CLIP (left) and UniCL (right). It can be seen that the model trained with CLIP has mixed representations of images from different categories, while the model trained with UniCL can better distinguish representations of images from different categories.
3. Introduction of Unimodal Data
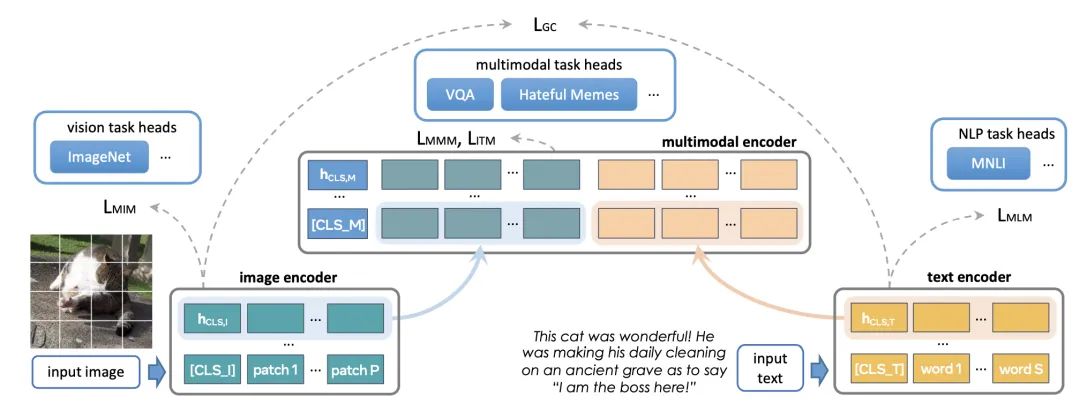
Paper Title: FLAVA: A Foundational Language And Vision Alignment ModelDownload Link: https://arxiv.org/pdf/2112.04482.pdfThe starting point of the FLAVA method is that a well-trained multimodal model should perform well not only in cross-modal tasks but also in unimodal tasks involving images or texts. Therefore, FLAVA proposes to simultaneously introduce unimodal tasks from the image and NLP domains when training multimodal models to enhance the performance of unimodal models, which aids in the subsequent training of multimodal models.The specific model structure of FLAVA is shown in the figure below. At the bottom are two independent Image Encoder and Text Encoder, while the upper layer uses a cross-modal Multimodal Encoder to achieve the crossover of information from the image and text sides. The input to the Multimodal Encoder is the concatenation of the outputs from the Image Encoder and Text Encoder. The pre-training tasks, in addition to the image-text contrastive learning in CLIP, include three additional losses:
Masked multimodal modeling (MMM): Masks parts of tokens in the text and patches in the image for the model to predict, which can be seen as an extension of masking single-modal tokens.
Masked image modeling (MIM): MIM is the unimodal optimization objective within the image Encoder, masking parts of patches in the image and then using the image Encoder for prediction.
Masked language modeling (MLM): MLM is the basic method in BERT, masking parts of tokens for restoration.
Image-text matching (ITM): The matching loss between images and texts, similar to contrastive learning loss, used to learn the global representation of samples.
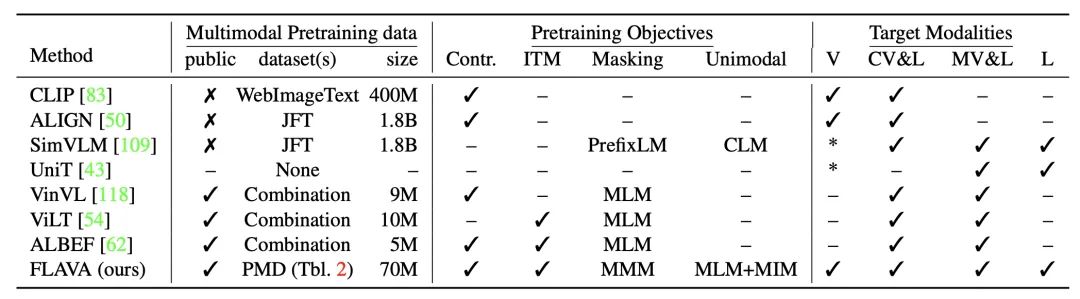
During the training process, single-modal tasks (MIM, MLM) are first used for pre-training the unimodal models, followed by continued training using both unimodal and multimodal tasks.The table below compares FLAVA with other multimodal models in terms of training data, pre-training tasks, and the modalities they can handle. FLAVA uses various unimodal data, enabling the model to handle both unimodal and multimodal tasks simultaneously.
4. Optimization of Multi-Type Data Distribution Differences
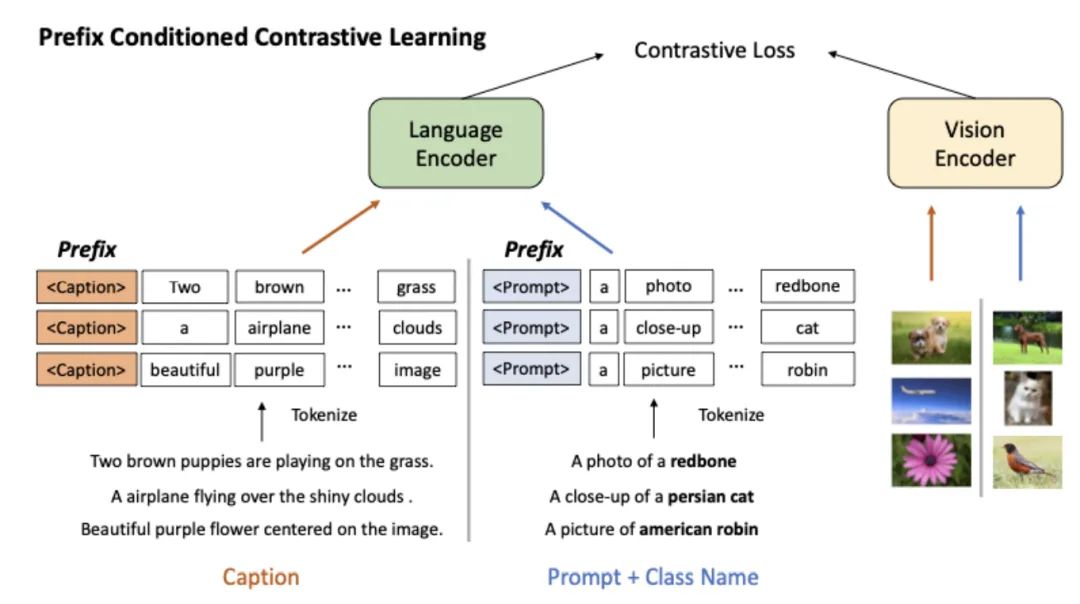
Paper Title: Prefix Conditioning Unifies Language and Label SupervisionDownload Link: https://arxiv.org/pdf/2206.01125.pdfThis paper also aims to simultaneously introduce image-text pair data and image label data. Unlike the approach of Unified Contrastive Learning in Image-Text-Label Space, the main issue addressed in this paper is how to solve the distribution differences between the two types of data, primarily the distribution differences on the text side. For the text descriptions of images, they are generally longer and contain more content. In contrast, the image-text pairs derived from Image-Label conversion typically have cleaner category information, such as “A photo of a cat.” The differences between the two data types lead to different focuses and interaction methods during multimodal matching.This paper adopts the prefix prompt approach to address the significant differences in text side data distribution between the two types of data. The prefix prompt is originally used for lightweight fine-tuning, where task-specific prompt prefix vectors are added during the fine-tuning of large models, only fine-tuning this prefix vector. The principle is to use the prompt as contextual information to influence the representation generation process of other elements. **For those interested in prefix prompts, you can refer to this article: NLP Prompt Series – Detailed Overview of Prompt Engineering Methods (https://mp.weixin.qq.com/s/nrJE4GjiYQNfYGs-EfYK1A)**. This paper concatenates two different prefix vectors in front of the two types of data, corresponding to the text description data and the data derived from Image-Label conversion, respectively. By introducing prefix prompts during the pre-training phase, the model can distinguish between the two types of data during pre-training.The following Attention Map shows that for different prefix prompts and data types, the model exhibits noticeable differences in attention distribution on the text side, even when the other texts are identical. The attention map corresponding to the prefix prompt for text description (Caption) shows a relatively uniform distribution, paying attention to multiple tokens; while the attention map corresponding to the prefix prompt for Image-Label focuses more on key words related to categories. This indicates that the model has learned how to distinguish between different types of data and stores this information in the prefix prompt vector to influence the representation generation of the entire sentence.
Conclusion
This article introduces the research direction of incorporating multiple types of data in the optimization of multimodal models. Recent papers in this area are numerous, representing a current hot topic in the industry, and are methods that can significantly improve the performance of multimodal models.
Good news!
Xiao Bai Learns Vision Knowledge Circle
is now open to the public👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Tutorial
Reply "Extension Module Chinese Tutorial" in the "Xiao Bai Learns Vision" public account backend to download the first OpenCV extension module tutorial in Chinese available online, covering installation of extension modules, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing, and over twenty chapters of content.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the "Xiao Bai Learns Vision" public account backend to download 31 practical vision projects including image segmentation, mask detection, lane line detection, vehicle counting, adding eyeliner, license plate recognition, character recognition, emotion detection, text content extraction, and face recognition, to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the "Xiao Bai Learns Vision" public account backend to download 20 practical projects based on OpenCV, achieving advanced learning in OpenCV.
Group Chat
Welcome to join the public account reader group to exchange with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GANs, algorithm competitions, etc. (these will be gradually subdivided). Please scan the WeChat ID below to join the group and note: "Nickname + School/Company + Research Direction," for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM." Please follow the format, otherwise, access will not be granted. Once added successfully, invitations will be sent to join relevant WeChat groups based on research direction. Please do not send advertisements in the group, or you will be removed from the group. Thank you for your understanding~