How to Set Up Your Own Local Large Model
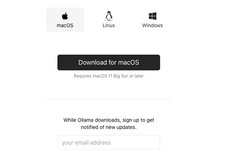
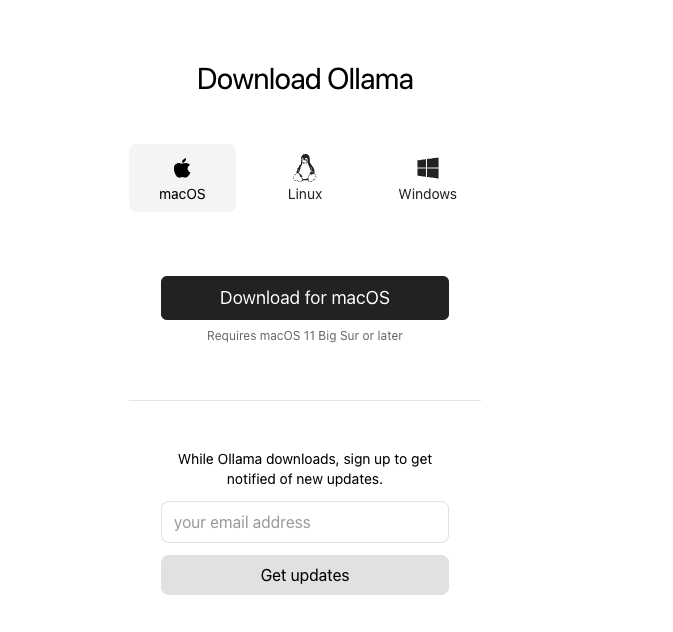
Download Ollama
Download Link
https://ollama.com/download
Ollama supports MacOS, Linux, and Windows
Extract
After downloading, you will get a file named Ollama-darwin.zip. After extraction, in the case of Mac, you will find a runnable file: Ollama.app
Usage Steps
1. Double-click the extracted runnable file: Ollama.app2. Click on Models on the Ollama official website to see a list of various large models. Here I choose llama33. Open the terminal and execute the following command: ollama run llama34. Wait for the model file to download, llama3:8b is approximately 4.7GB
5. After completion, a window will appear indicating successful installation

6. Send any message to test
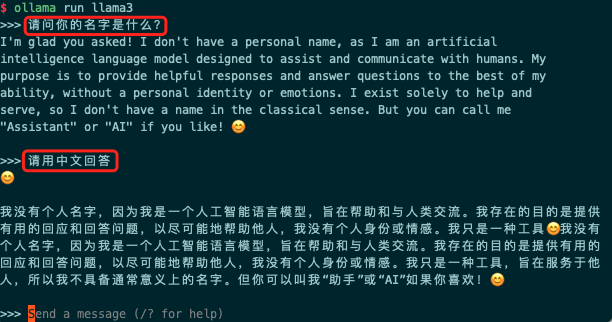
Using the Chat Page to Call the Large Model
Whether using commands or calling the large model interface, it is definitely inconvenient. The large model must be used in conjunction with a perfect page. I recommend using open-webui
GitHub Link
https://github.com/open-webui/open-webui
Installation Method
It is recommended to install using Docker (you can refer directly to the documentation in GitHub)
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Usage
After successful installation, access localhost:3000 directly in the browser, register an account, and you can use it normally.
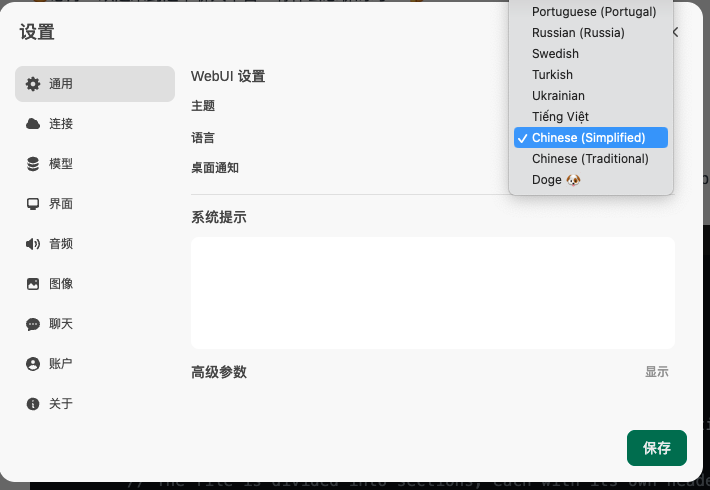
In the UI page, you can set the system language, supporting Chinese
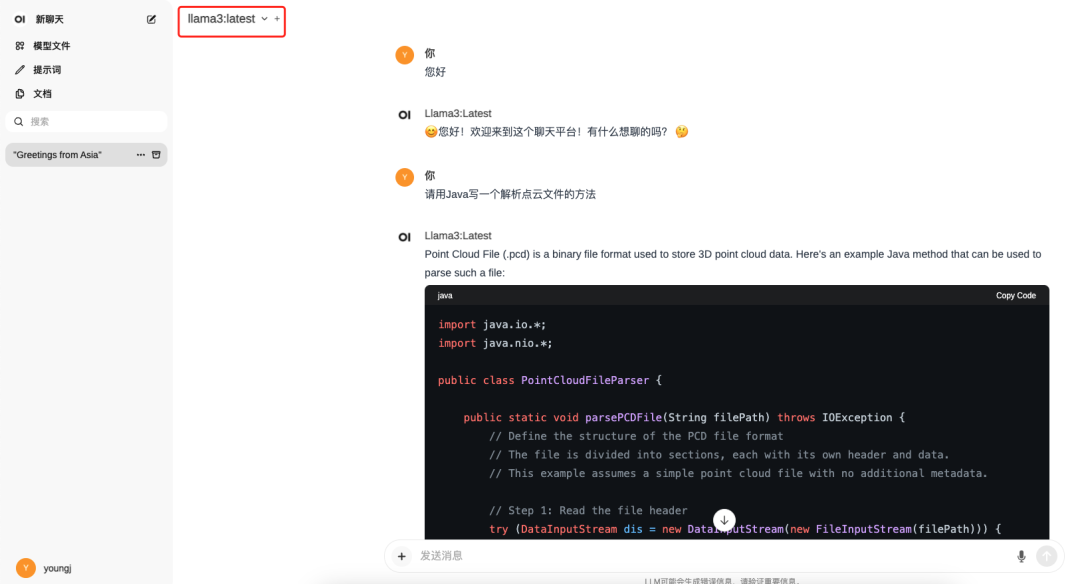
Using Development Tool Plugins with Local Large Models
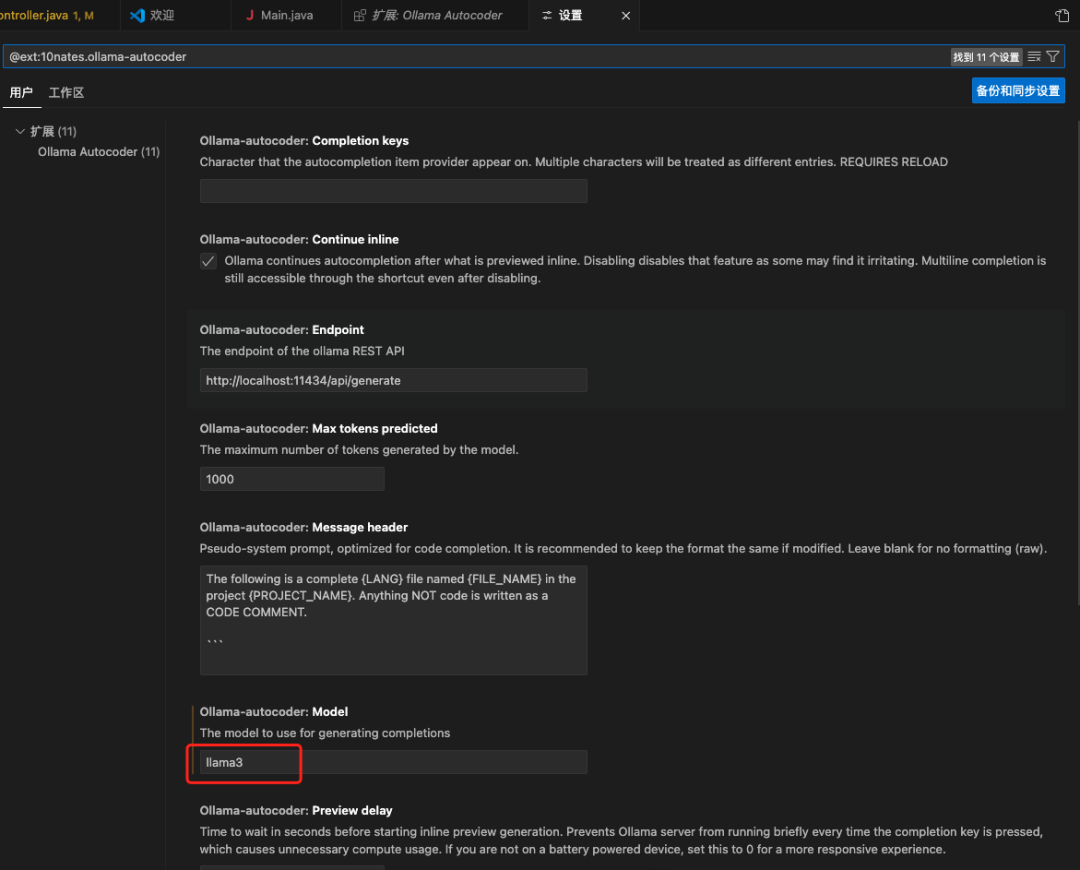
Many plugins support Ollama. For instance, in the VSCode development tool, there is a plugin called Ollama Autocoder
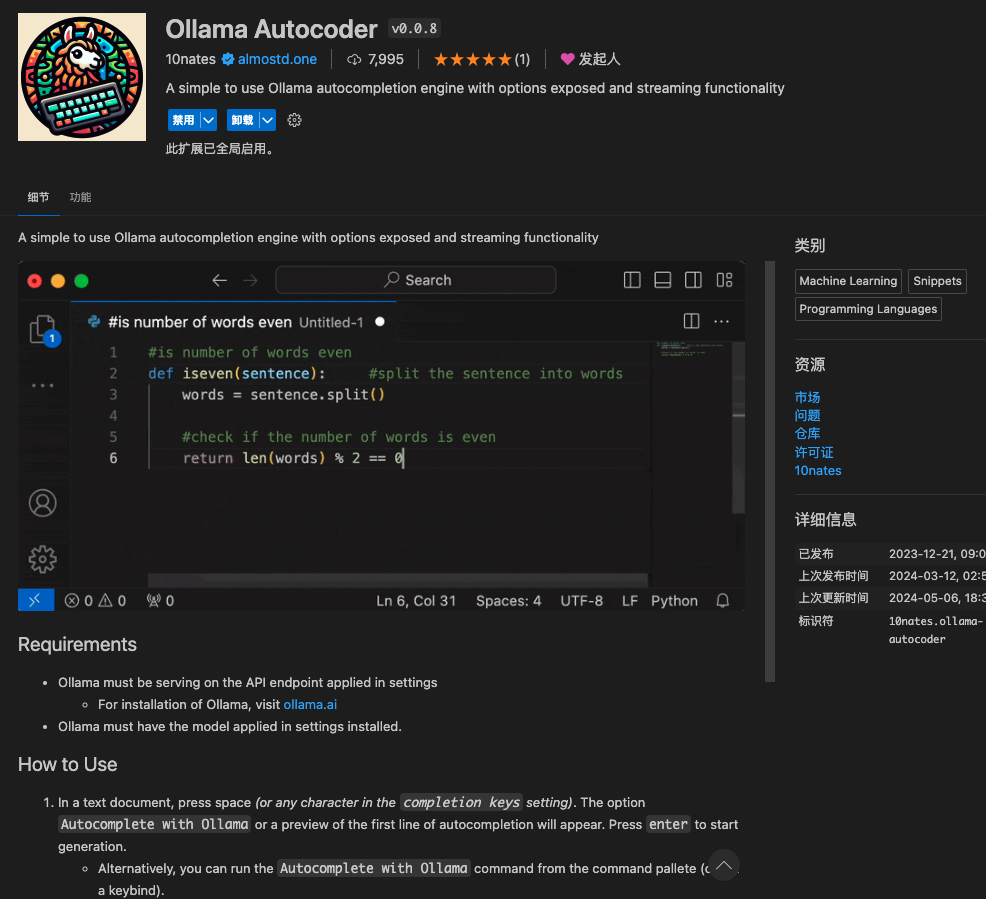
In the settings, manually change the model to: llama3
In VSCode, press the spacebar to get plugin suggestions:

Press the Tab key to use the large model’s inference to generate contextual code. I won’t elaborate on this; many excellent plugins do this well. Here, I focus on demonstrating the use of the local large model.