
Produced by Machine Learning Algorithms and Natural Language Processing
Original Column Author on WeChat @ Yi Zhen
School | PhD Student at Harbin Institute of Technology SCIR
1. Why RNN Needs to Handle Variable Length Inputs
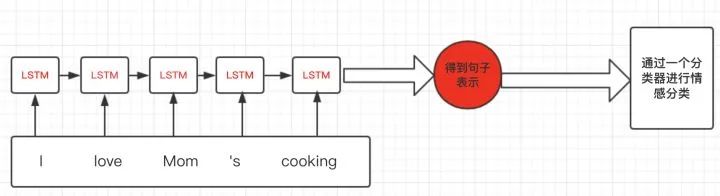
Assuming we have an example of sentiment analysis, where each sentence undergoes classification for sentiment level, the main process is roughly shown in the figure below:
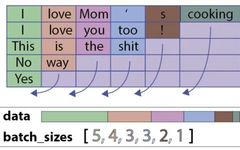
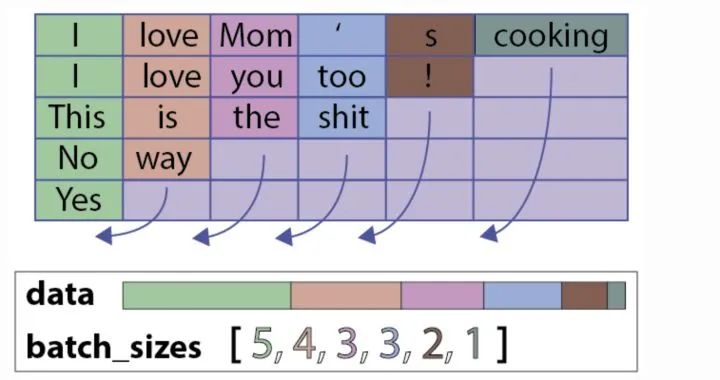
The idea is quite simple, but when we compute multiple training data in a batch, we encounter situations where training samples have different lengths. Thus, we naturally perform padding to make shorter sentences match the length of the longest sentence.
For example, as shown in the figure below:
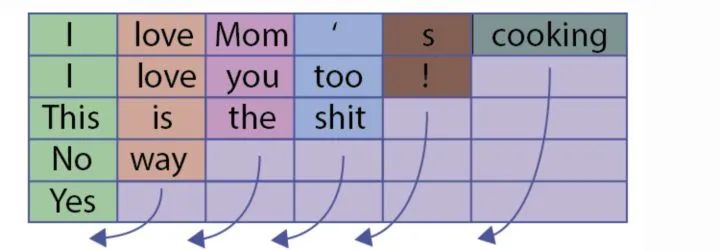
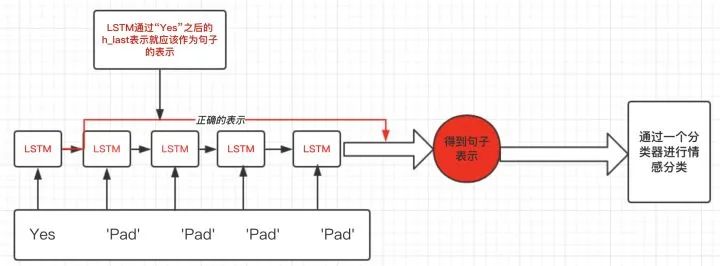
However, there is a problem with this approach. What is the issue? For instance, in the above figure, the sentence “Yes” consists of only one word, but it is padded with five pad symbols. This causes the LSTM to process a significant number of useless characters, leading to inaccuracies in the sentence representation. More intuitively, as shown in the figure below:
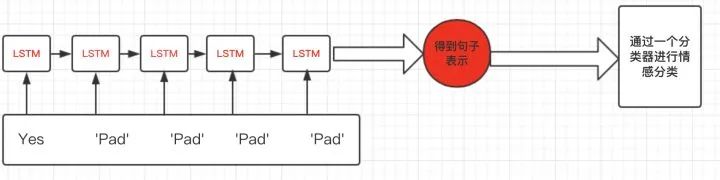
So what should we do correctly?
This introduces the need for handling variable length inputs in RNNs in PyTorch. In the example above, what we want to obtain is the representation after the LSTM processes the word “Yes”, rather than the representation obtained through multiple useless “Pad” characters, as shown in the figure below:
2. How to Handle Variable Length Padding in PyTorch RNN
This is mainly done using the functions torch.nn.utils.rnn.pack_padded_sequence() and torch.nn.utils.rnn.pad_packed_sequence(). Let’s take a look at how these two functions work.
Here, “pack” is better understood as compressing. It compresses a padded variable length sequence. (During padding, there is redundancy, so we compress it a bit.)
The input shape can be (T×B×*). T is the longest sequence length, B is the batch size, and * represents any dimension (can be 0). If batch_first=True, the corresponding input size is (B×T×*).
Sequences stored in the Variable should be sorted by their lengths, with longer sequences first and shorter ones later (it is crucial to sort them). This means input[:,0] represents the longest sequence, and input[:, B-1] holds the shortest sequence.
Parameter descriptions:
input (Variable) – The padded batch of variable length sequences.
lengths (list[int]) – The lengths of each sequence in the Variable. (Knowing the length of each sequence is essential to determine how far to process each sequence.)
batch_first (bool, optional) – If True, the input shape should be B*T*size.
Return Value:
A PackedSequence object. A PackedSequence is represented as shown below:
The specific code is as follows:
embed_input_x_packed = pack_padded_sequence(embed_input_x, sentence_lens, batch_first=True)
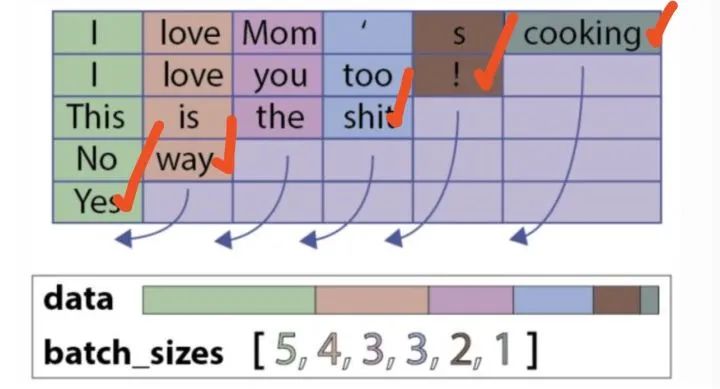
encoder_outputs_packed, (h_last, c_last) = self.lstm(embed_input_x_packed)At this point, the returned h_last and c_last are the hidden state and cell state after removing the padding characters, both of which are of Variable type. Their meanings are as follows (the representation of each sentence, the LSTM will only act on the actual length of the sentence, not through useless padding characters, as indicated by the red checkmarks in the figure below):
However, the returned output is of PackedSequence type, which can be used as follows:
encoder_outputs, _ = pad_packed_sequence(encoder_outputs_packed, batch_first=True)This converts encoder_outputs to Variable type, where _ represents the lengths of each sentence.
3. Conclusion
In summary, when RNN processes variable length sentence sequences, we can use torch.nn.utils.rnn.pack_padded_sequence() and torch.nn.utils.rnn.pad_packed_sequence() to mitigate the impact of padding on sentence representation.
References:
Handling Variable Length Sequences in PyTorch – Deep Learning 1 – Blog Gardenwww.cnblogs.com Zhao Pu: PyTorch RNN Variable Length Input Paddingzhuanlan.zhihu.com
Zhao Pu: PyTorch RNN Variable Length Input Paddingzhuanlan.zhihu.com
Important! The WeChat group for Natural Language Processing TensorFlow has been established to facilitate the exchange of TensorFlow experiences. You can scan the QR code below to join the group. Please note: when adding, modify the remark to [School/Company + Name + Direction], e.g., Harbin Institute of Technology + Zhang San + Dialogue System. The group owner, please avoid adding if you are a sales account. Thank you!
Recommended Reading:
【Detailed Explanation】From Transformer to BERT Model
Sailor's Translation | Understanding Transformer from Scratch
A picture is worth a thousand words! Hands-on guide to building a Transformer with Python